 夜雨聆风
夜雨聆风





Qwen3.5系列模型上新、多模态文档检索方案总结及一点鸡汤
今天是2026年2月25日,星期三,江西,天气晴
今天是大年初九,昨日Qwen3.5更新,包括Qwen3.5-397B-A17B、Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B,开源地址:https://huggingface.co/collections/Qwen/qwen35,https://modelscope.cn/collections/Qwen/Qwen35
模型更新的很多,但还是要回到应用上去讲,所以,看看多模态文档检索方案总结,看看技术趋势。
一、多模态文档检索方案总结
先看技术总结,其实还是应用型技术,RAG方案,围绕多模态大模型视觉文档检索(VDR,从大规模视觉文档库中检索相关内容的多模态检索任务),如下∶

而针对这类的综述已经有很多,如下:

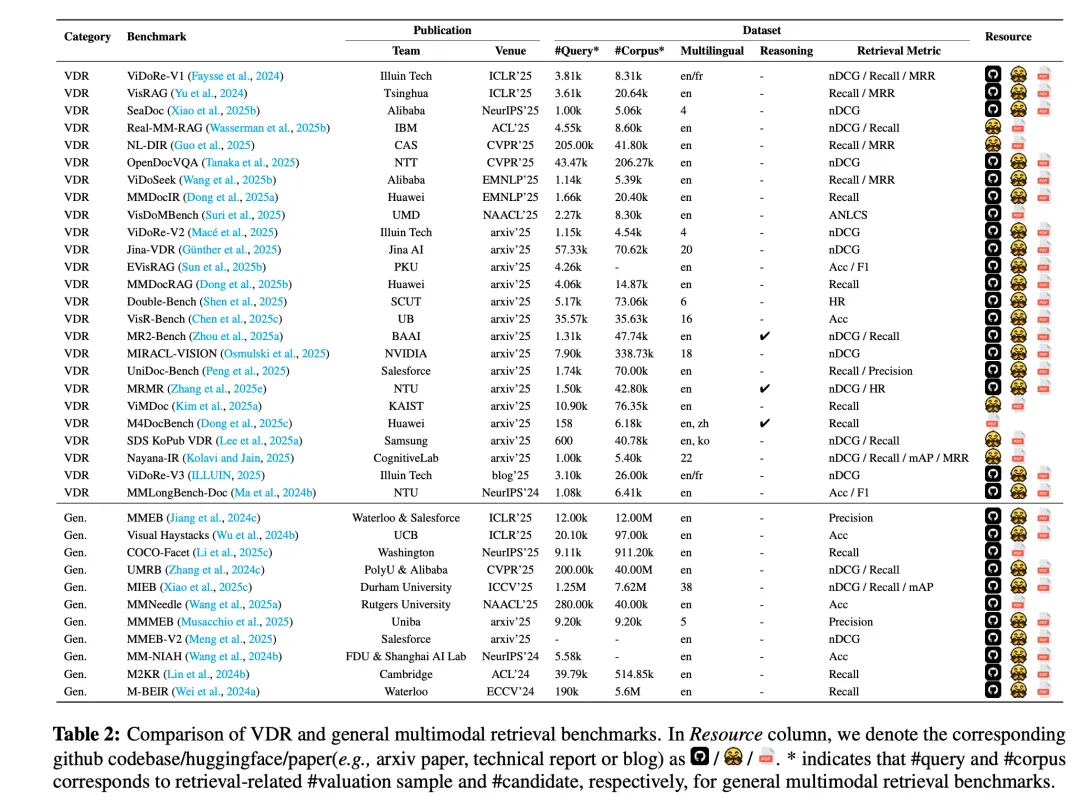
对应的benchmark也有许多,如下,梳理的挺全面的:
这里,来看一个新的技术总结,工作在《Unlocking Multimodal Document Intelligence: From Current Triumphs to Future Frontiers of Visual Document Retrieval》,https://arxiv.org/pdf/2602.19961,核心看几个点:
1、前沿方向
包括多语言支持【从英语中心向多语言拓展,覆盖语种数最多达22种,代表包括Jina-VDR(20种)、Nayana-IR(22种】;
推理密集型【从语义匹配向抽象/空间/逻辑推理、多跳/多文档合成演进,代表为MR2-Bench、MRMR、M4DocBench】;
2、技术范式
技术范式主要包括三个。
一个是多模态嵌入模型,如下∶
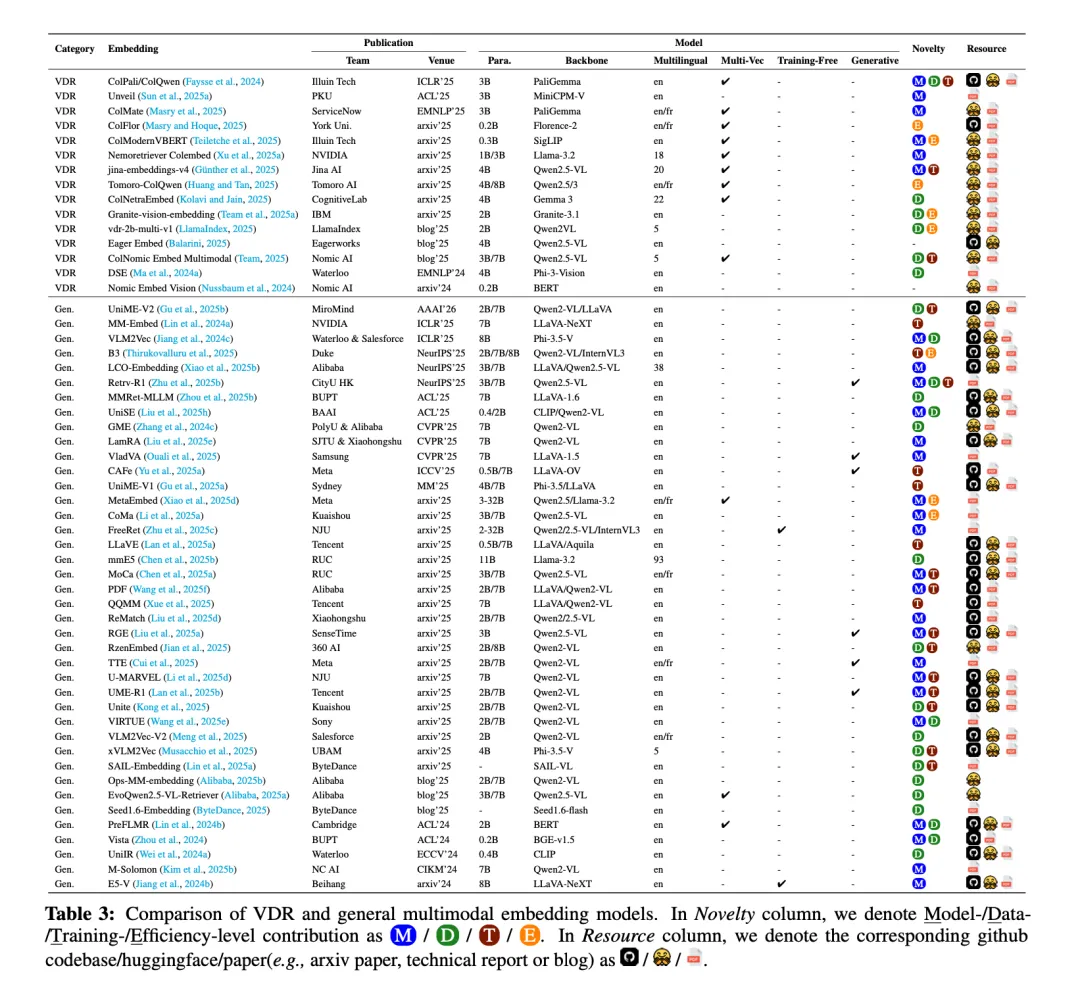
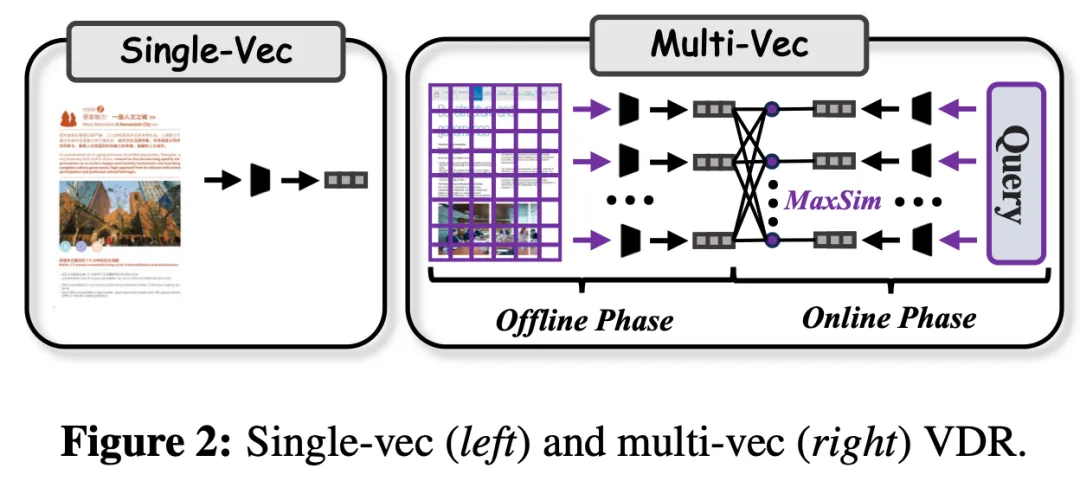
多向量表征+Late-interaction(由ColPali开创),替代传统单向量表征,实现查询与文档视觉/文本区域的精准对齐,核心通过MaxSim计算相关性,模型骨干从BERT等小模型转向PaliGemma、Qwen-VL等MLLM,参数量集中在20亿-80亿,趋势为模型层(ColPali的Late-interaction适配)、数据层(大尺度数据集+MLLM作为评判者的难负样本挖掘)、训练层(多任务学习、模态感知训练)、效率层(小模型设计如ColModernVBERT等)
一个是模态重排模型,这个常用于二次排序提升相关性。对比如下图∶
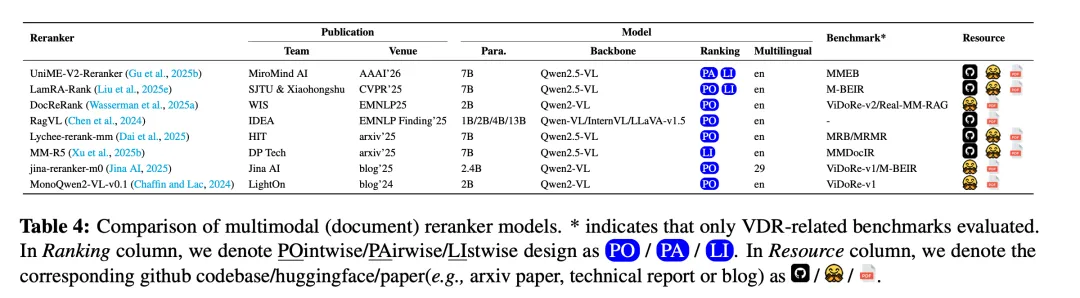
从技术原理上看,其基于交叉编码器的架构,联合处理查询与候选文档,通过深度跨注意力捕捉细粒度跨模态依赖,输出标量相关性得分优化排序。
模型backbone常采用Qwen2.5-VL等MLLM,参数量达70亿;
训练方式包括点式Pointwise(独立评估查询-文档对,BCE损失)、成对Pairwise(对比文档对相对相关性,边际损失)、列表式Listwise(优化整体排序列表,适配nDCG等指标),多范式融合成为主流(如LamRA-Rank结合列表式+点式)
一个是RAG与智能体系统融合,这个是标准范式了。
是核心发展趋势为从静态RAG到动态迭代的智能体系统;交互模态从文本拓展至语音(TextlessRAG);多智能体协作(如MDocAgent的五个智能体)、主动视觉感知(如VRAG-RL的裁剪/缩放操作)
二、允许万物穿过
这是在朋友圈某个朋友发的一张图,感觉不错,做个保存分享∶
Life Flows Through You,Not to You,生命流经你,而非流向你。
Life isn’t something you own. lt’s something you experience,生活不是你拥有的东西,而是你经历的东西。
参考文献
1、https://arxiv.org/pdf/2602.19961
关于我们
老刘,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解感兴趣,并对每日早报、老刘说NLP历史线上分享、心得交流等感兴趣的,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。
