夜雨聆风
夜雨聆风





Browser-Use 源码解析:AI 是怎么"看懂"并操控网页的
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
你有没有想过,AI Agent 到底是怎么操作浏览器的?
不是那种用 Selenium 写死 XPath 的”假自动化”,而是你给它一句话——”帮我去 Amazon 上找一台 4K 显示器,加入购物车”——它就能自己打开浏览器、搜索、筛选、点击、填表,完成整个流程。
这背后的关键问题是:「AI 根本看不懂网页。」 网页是给人看的——有颜色、有布局、有交互。但对 AI 来说,它拿到的只是一堆 HTML 标签和一张截图。它怎么知道哪个是搜索框?哪个是”加入购物车”按钮?点击坐标应该是多少?
「Browser-Use」 就是解决这个问题的。它在 GitHub 上有 「78k+ Star」,是目前最火的 AI 浏览器自动化开源项目。它的核心思路简单又巧妙:「把复杂的网页”翻译”成 AI 能理解的编号列表,让 AI 像人一样”看到”页面,做出决策,执行操作。」
今天这篇文章,我就带你从源码层面拆解 Browser-Use,搞清楚 AI 到底是怎么”看懂”并操控网页的。
先看看 Browser-Use 能干啥
在拆源码之前,先体感一下它的能力。用法非常简单:
from browser_use import Agent, Browser
import asyncio
asyncdefmain():
agent = Agent(
task="去 GitHub 上搜索 browser-use,告诉我它有多少 Star",
llm=ChatOpenAI(model="gpt-4o"),
browser=Browser(),
)
await agent.run()
asyncio.run(main())
就这么几行代码,AI 就会:
-
打开 Chrome 浏览器 -
导航到 GitHub -
找到搜索框并输入关键词 -
在搜索结果中找到目标仓库 -
提取 Star 数量 -
返回结果
它还能做更复杂的事情:
- 「填写求职表单」
:把你的简历信息自动填进招聘网站的申请表 - 「在线购物」
:按购物清单在电商网站一个个加入购物车 - 「数据采集」
:浏览多个页面,提取和整理信息 - 「多标签页操作」
:同时开多个页面对比信息
听起来很神奇,但原理并不复杂。我们从架构开始看。
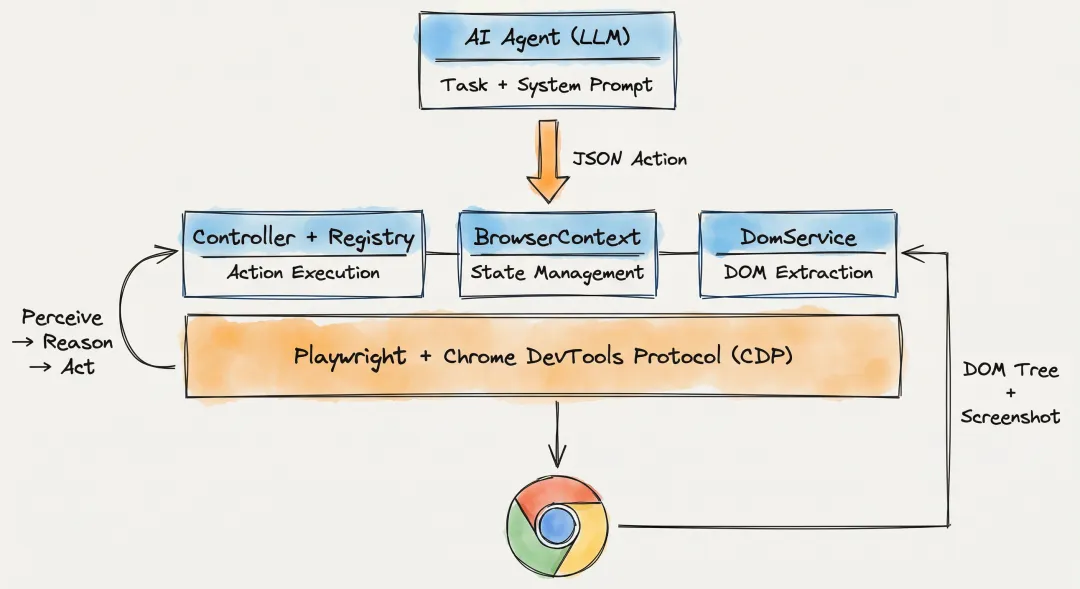
整体架构:五大核心组件
Browser-Use 的技术栈是 「Python + Playwright + LLM」,整体架构可以分成五个核心组件:
|
|
|
|---|---|
| 「Agent」 |
|
| 「BrowserContext」 |
|
| 「DomService」 |
|
| 「Controller + Registry」 |
|
| 「MessageManager」 |
|
底层通过 「Playwright」 操控浏览器,Playwright 则通过 「Chrome DevTools Protocol (CDP)」 与 Chrome 通信。为什么不用更高层的 API?因为 CDP 能做到更精细的控制——DOM 检查、JS 执行、网络拦截、输入模拟,这些都是做浏览器自动化必须的能力。
核心机制一:AI 怎么”看到”网页——DomService
这是 Browser-Use 最核心的设计,也是它区别于传统浏览器自动化工具的关键。
「问题」:一个普通网页的 DOM 树可能有几千个节点,绝大部分对 AI 来说都是噪音(样式容器、隐藏元素、装饰性标签……)。如果把完整 HTML 丢给 LLM,不仅浪费 token,还会让 AI 迷失在信息洪流里。
「Browser-Use 的解法」:用 DomService 把复杂的 DOM 树”提纯”成一份「只包含可交互元素的编号地图」。
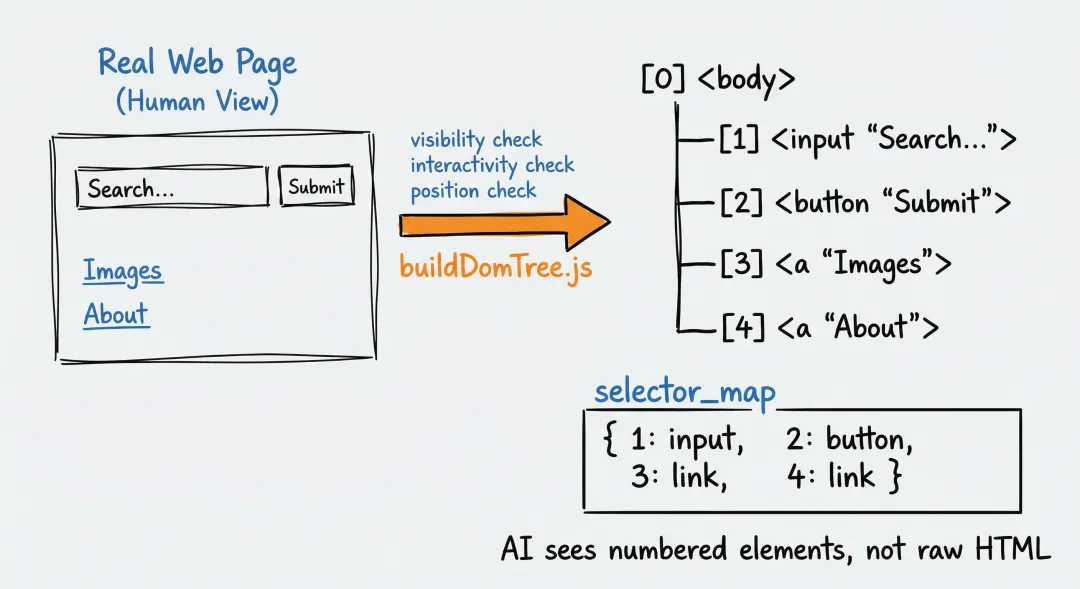
buildDomTree.js:在浏览器里”扫描”页面
DomService 的核心是一个叫 buildDomTree.js 的 JavaScript 脚本。它会被注入到浏览器页面中执行,对每个 DOM 元素做三重检查:
- 「可见性检查」
: display: none?visibility: hidden?opacity: 0?在视口外面?——不可见的元素直接跳过 - 「可交互性检查」
:是不是按钮、链接、输入框?有没有 onclick事件?ARIA 角色是否表明可交互?——只保留用户能操作的元素 - 「位置检查」
:元素的坐标是什么?有没有被其他元素遮挡?——确保 AI 点击时能点到
对于通过检查的元素,分配一个递增的 「highlight_index」(高亮索引号),最终生成两个关键产物:
「element_tree」:一棵精简后的 DOM 树
<body> [noindex]
|-- <section> [noindex]
| |-- <input aria-label="Search"> [highlight_index: 5]
| +-- <button> [highlight_index: 6]
| +-- "Google Search" (TextNode)
+-- <a href="/images"> [highlight_index: 7]
+-- "Images" (TextNode)
「selector_map」:索引号到元素节点的映射字典
{
5: DOMElementNode(tag_name='input', attributes={'aria-label': 'Search'}, ...),
6: DOMElementNode(tag_name='button', ...),
7: DOMElementNode(tag_name='a', attributes={'href': '/images'}, ...),
}
从 Python 端看调用链路
整个流程的调用链是这样的:
Agent.step()
→ BrowserContext.get_state()
→ DomService.get_clickable_elements()
→ page.evaluate(buildDomTree.js) // 注入 JS 到浏览器执行
→ _construct_dom_tree(result) // 把 JS 返回的数据转成 Python 对象
→ 拼装 BrowserState(DOM树 + 截图 + URL + 标题)
→ 把 BrowserState 发给 LLM
核心代码简化后长这样:
classDomService:
def__init__(self, page):
self.page = page
self.js_code = resources.read_text('browser_use.dom', 'buildDomTree.js')
asyncdef_build_dom_tree(self, highlight_elements, viewport_expansion, ...):
args = {
'doHighlightElements': highlight_elements,
'viewportExpansion': viewport_expansion,
}
# 关键一步:把 JS 注入浏览器执行,拿回结构化数据
eval_page = awaitself.page.evaluate(self.js_code, args)
returnawaitself._construct_dom_tree(eval_page)
「为什么要注入 JS 而不是用 Python 直接分析 HTML?」 因为很多信息只有在浏览器环境里才能拿到——计算后的样式、元素的实际渲染位置、是否被遮挡、事件监听器等等。这些信息光看 HTML 源码是看不出来的。
AI 最终”看到”的是什么
经过 DomService 处理后,AI 收到的页面描述大概长这样:
[5]<inputaria-label='Search'>
[6]<button>Google Search</button>
[7]<a>Images</a>
[8]<a>Gmail</a>
加上一张页面截图。「编号文本给精度,截图给直觉」——这就是 Browser-Use 的”双通道感知”策略。
这个设计相当聪明。对 AI 来说,它不需要理解 CSS 选择器、XPath 或者 DOM 层级关系,只需要说”点击 [6]”就能点到”Google Search”按钮。
核心机制二:AI 怎么”思考”——System Prompt 与 Agent 循环
有了”视觉”,还需要”大脑”。Agent 的核心是一个 「Perceive → Reason → Act」 循环:
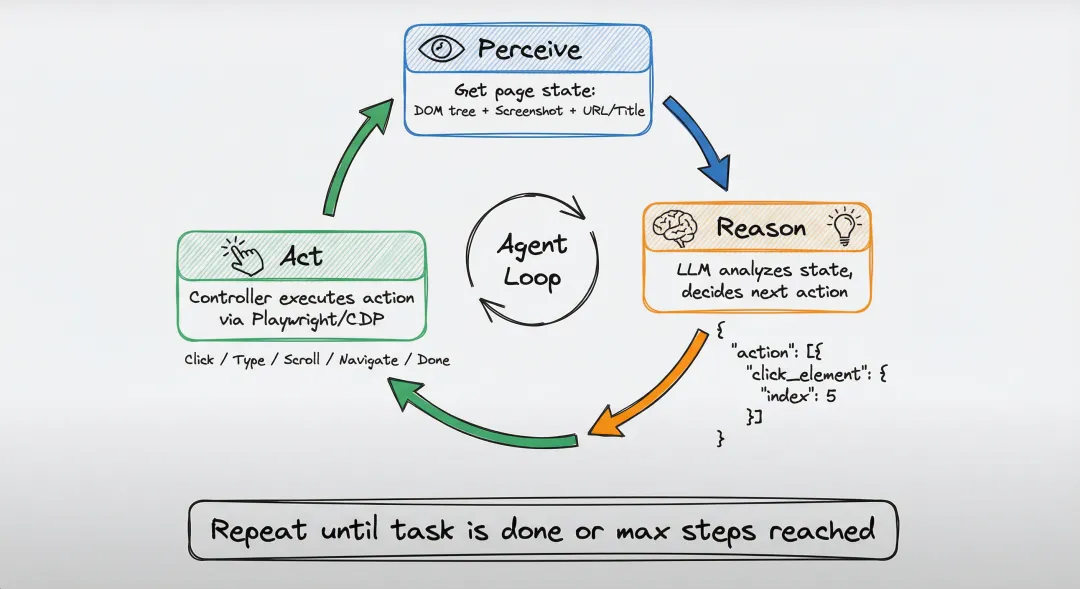
System Prompt:AI 的”操作手册”
在对话开始前,Agent 会给 LLM 发一段 System Prompt,相当于一本操作手册,告诉 AI:
- 「你是谁」
:你是一个浏览器自动化 Agent,你的目标是完成用户给的任务 - 「你能看到什么」
:你会收到页面的 DOM 编号列表和截图 - 「你能做什么」
:click_element、input_text、scroll_down、go_to_url、done…… - 「你必须怎么回答」
:严格返回 JSON 格式
这个 JSON 格式是整个系统能运转的关键:
{
"current_state":{
"evaluation_previous_goal":"Success - 找到了搜索框",
"memory":"我在 Google 首页,需要搜索 cute cats",
"next_goal":"在搜索框 [5] 里输入 cute cats"
},
"action":[
{
"input_text":{
"index":5,
"text":"cute cats"
}
},
{
"press_keys":{
"keys":"Enter"
}
}
]
}
注意这里面有三个值得学的设计:
- 「
current_state里有”记忆”」
: memory字段让 AI 在多步操作中记住自己做过什么,不会”失忆” - 「
evaluation_previous_goal提供自我评估」
:AI 会判断上一步有没有成功,如果失败会调整策略 - 「
action是一个数组」
:支持一步执行多个操作(比如先输入再按回车),减少来回次数
Agent 循环:一步一步推进任务
Agent 的主循环逻辑(agent/service.py)简化后是这样的:
classAgent:
asyncdefrun(self, max_steps=100):
for step inrange(max_steps):
result = awaitself.step()
if result.is_done:
break
asyncdefstep(self):
# 1. Perceive:获取当前页面状态
state = awaitself.browser_context.get_state()
# 2. 把状态加入消息历史
self._message_manager.add_state_message(state)
# 3. Reason:问 LLM 下一步怎么做
messages = self._message_manager.get_messages()
llm_response = awaitself.llm.invoke(messages)
# 4. Act:执行 LLM 决定的动作
for action in llm_response.actions:
result = awaitself.controller.act(action, self.browser_context)
return result
每一步都是:「看一下当前状态 → 问 AI 该干啥 → 执行 → 重复」。这个循环会一直跑,直到 AI 返回 done 动作表示任务完成,或者达到最大步数限制。
核心机制三:AI 怎么”动手”——Controller 与 Action Registry
AI 说”点击元素 [5]”,怎么变成真正的鼠标点击?靠的是 「Controller(控制器)」 和 「Registry(动作注册表)」。
Registry:动作注册表(工具箱)
Registry 就是一个动作目录,定义了 AI 能做的所有操作。内置动作包括:
|
|
|
|
|---|---|---|
click_element |
|
index
|
input_text |
|
index
text: 内容 |
go_to_url |
|
url
|
scroll_down
scroll_up |
|
amount
|
press_keys |
|
keys
|
switch_tab |
|
tab_id
|
extract_content |
|
goal
|
done |
|
text
success: 是否成功 |
每个动作用 Pydantic 模型定义参数,确保类型安全:
classClickElementAction(BaseModel):
index: int
xpath: Optional[str] = None
classInputTextAction(BaseModel):
index: int
text: str
Controller:动作执行器(技工)
Controller 负责接收 AI 的动作指令,从 Registry 中找到对应的处理函数,校验参数,然后执行:
classController:
def__init__(self):
self.registry = Registry()
@self.registry.action("Click element", param_model=ClickElementAction)
asyncdefclick_element(params, browser):
# 1. 通过 index 从 selector_map 中找到 DOM 节点
element_node = await browser.get_dom_element_by_index(params.index)
# 2. 通过 Playwright 执行点击
await browser._click_element_node(element_node)
return ActionResult(extracted_content=f"Clicked element {params.index}")
@self.registry.action("Input text", param_model=InputTextAction)
asyncdefinput_text(params, browser):
element_node = await browser.get_dom_element_by_index(params.index)
await browser._input_text_element_node(element_node, params.text)
return ActionResult(extracted_content=f"Typed into element {params.index}")
整个执行流程:
AI 说 {"click_element": {"index": 5}}
→ Controller.act() 解析出动作名和参数
→ Registry 查找 "click_element" 对应的函数
→ Pydantic 校验参数 {"index": 5}
→ 从 selector_map[5] 拿到 DOM 节点
→ Playwright 执行 click()
→ 返回 ActionResult
自定义工具:给 AI 加”外挂”
Browser-Use 支持用装饰器注册自定义工具,让 AI 在浏览网页的同时调用你的自定义逻辑:
from browser_use import Tools
tools = Tools()
@tools.action(description='保存商品价格到数据库')
defsave_price(product_name: str, price: float) -> str:
db.save(product_name, price)
returnf"Saved {product_name}: ${price}"
agent = Agent(
task="找到最便宜的 4K 显示器并保存价格",
llm=llm,
browser=browser,
tools=tools,
)
这个设计跟 Open WebUI 的插件系统思路一样——「动作注册表驱动」。新增一个工具不需要改框架代码,只需要用装饰器注册就行。LLM 会在 System Prompt 里看到所有可用工具的描述,自动判断什么时候该调用。
核心机制四:状态管理——MessageManager
AI Agent 的一个关键挑战是「上下文管理」。每一步操作后,AI 需要知道之前发生了什么、当前页面长什么样、任务进行到哪了。这就是 MessageManager 的活。
MessageManager 维护着一个消息列表,按照 LLM 的对话格式组织:
[SystemMessage] → SystemPrompt(AI 的操作手册)
[HumanMessage] → 用户任务 + 当前页面状态(DOM + 截图)
[AIMessage] → AI 的推理和动作决策
[HumanMessage] → 动作执行结果 + 新的页面状态
[AIMessage] → AI 的下一步决策
...循环...
有几个实现细节值得注意:
「截图管理」:每张截图都是几千 token 的开销。MessageManager 只保留最近几步的截图,历史步骤的截图会被移除,只保留文本描述。
「消息裁剪」:当对话历史太长快要超出上下文窗口时,会裁剪掉最早的消息,但始终保留 System Prompt 和最近的状态。
「错误恢复」:如果某一步操作失败(比如元素没找到、页面没加载完),错误信息会作为下一条 HumanMessage 告诉 AI,让它自己判断怎么调整策略。
坐标处理:看似简单实则巧妙
当 AI 说”点击元素 [5]”时,系统需要计算出精确的鼠标点击坐标。这里面藏着几个容易踩的坑:
「视口偏移」:元素的坐标是相对于整个页面的绝对坐标,但鼠标点击用的是视口相对坐标。如果页面滚动了 1000px,一个在页面坐标 1200px 处的元素,在视口里的 Y 坐标应该是 200px。
「iframe 嵌套」:iframe 里的元素坐标是相对于 iframe 内部的,需要逐层换算到主页面坐标系。
「截图缩放」:为了省 token,截图通常会被缩小(比如从 1920×1080 缩到 1400×850)。如果 AI 通过视觉模型点击截图上的某个位置,需要把缩放后的坐标反向换算回真实坐标。
「遮挡检测」:一个元素可能在 DOM 中存在且可见,但被另一个元素(比如弹窗)遮住了。buildDomTree.js 会用 document.elementFromPoint() 检测遮挡情况,被完全遮挡的元素不会分配 index。
事件驱动的 Watchdog 系统
Browser-Use 还有一套后台监控系统——「Watchdog」,用事件驱动的方式处理各种异步场景:
|
|
|
|---|---|
| 「Downloads Watchdog」 |
|
| 「Screenshot Watchdog」 |
|
| 「DOM Watchdog」 |
|
| 「Popup Watchdog」 |
alert()、confirm() 等弹窗,防止自动化流程被卡住 |
| 「Crash Watchdog」 |
|
这些 Watchdog 通过事件总线(Event Bus)异步运行,不会阻塞主循环。比如 AI 点了一个下载链接,Downloads Watchdog 会在后台跟踪下载进度,等下载完成后把文件路径塞进下一步的状态里。
性能优化:实际落地要注意什么
如果你要基于 Browser-Use 做产品,有几个性能问题需要关注:
1. Token 消耗控制
每一步操作都要给 LLM 发送当前页面状态(DOM + 截图),这是很大的 token 开销。几个优化方向:
- 「DOM 裁剪」
:只发送视口内的可交互元素,视口外的跳过 - 「截图缩放」
:适当缩小截图尺寸,平衡 token 消耗和视觉精度 - 「历史裁剪」
:及时清理历史消息中的截图,只保留文本摘要 - 「关闭视觉」
:如果任务不需要视觉理解(比如纯表单填写),可以关掉截图只用 DOM
2. DOM 缓存
完整的 DOM 提取需要多次 CDP 往返,开销不小。Browser-Use 在同一个 Agent step 内会缓存 DOM 结果,避免重复提取。操作后自动失效缓存,确保下一步拿到最新状态。
3. 选择合适的 LLM
Browser-Use 官方推荐用他们优化过的 ChatBrowserUse() 模型,据说完成任务速度是其他模型的 3-5 倍。当然你也可以用 GPT-4o、Claude、Gemini 等主流模型。关键是模型要支持 「结构化输出」(structured output),这样返回的 JSON 才不容易出错。
跟同类项目对比一下
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Browser-Use 的核心优势在于「把 DOM 提取和 AI 决策做了深度整合」。不是简单地把 HTML 丢给 AI,而是做了大量预处理——可见性过滤、交互性检测、编号索引——让 AI 用最少的 token 获取最有用的信息。
如果你要自己做浏览器 AI Agent
看完 Browser-Use 的源码,我总结几个值得带走的设计思路:
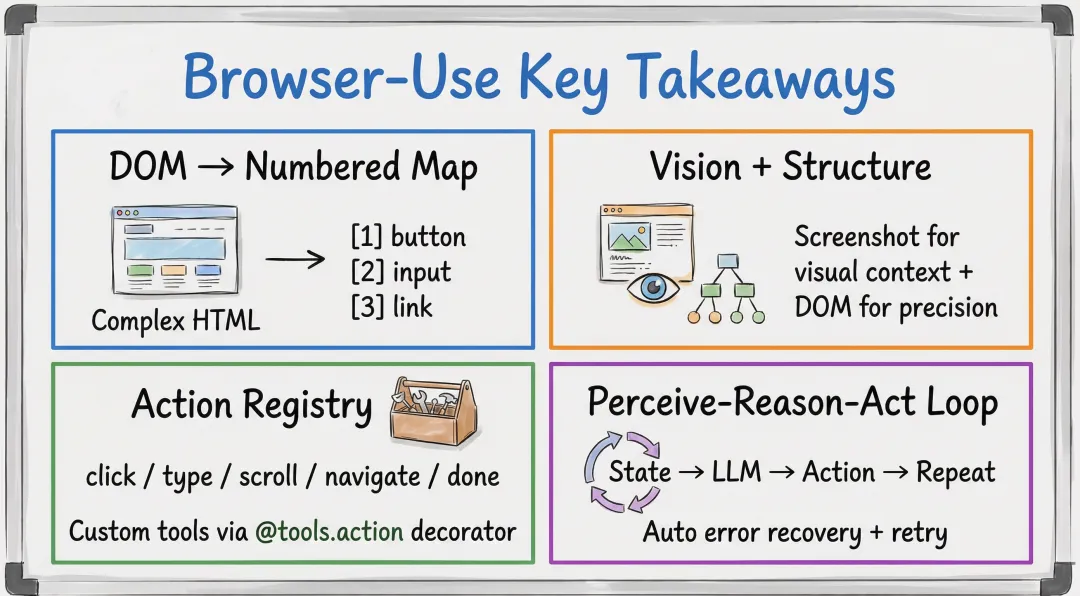
值得学的
- 「DOM → 编号地图」
:把复杂 DOM 精简成编号列表,是目前最实用的”让 AI 看懂网页”的方案。核心代码就一个 JS 文件( buildDomTree.js),可以直接参考 - 「截图 + DOM 双通道」
:截图给 AI 视觉直觉(布局、颜色、位置感),DOM 给操作精度(精确到哪个元素)。两者结合效果远好于单用 - 「Action Registry 模式」
:用装饰器注册动作,LLM 自动发现和调用。这个模式可以用在任何 AI Agent 项目里 - 「Perceive-Reason-Act 循环」
:简洁有效的 Agent 架构,每步都有自我评估和记忆,不会”失忆” - 「Watchdog 事件驱动监控」
:异步处理下载、弹窗、崩溃等边缘场景,不阻塞主循环
需要注意的
- 「Token 成本」
:每步操作都要发 DOM + 截图,长任务的 token 消耗可能很高。上线前要做好成本预算 - 「动态页面」
:SPA 应用、大量异步加载的页面,DOM 提取的时机很关键。提取太早可能拿到不完整的页面 - 「反爬机制」
:很多网站会检测自动化操作。生产环境需要考虑浏览器指纹、代理、验证码处理 - 「错误恢复」
:网页环境不确定性很高,健壮的错误处理和重试机制必不可少
总结
拆解完 Browser-Use,我最大的感受是:「让 AI 操控浏览器的核心难点不在于”操控”,而在于”看懂”。」
Playwright 解决了”操控”问题——你可以点击、输入、滚动、导航。但”看懂”是全新的挑战:怎么从几千个 DOM 节点中提取出有用的信息?怎么用最少的 token 让 AI 理解当前页面?怎么把 AI 的文本指令精确映射到具体的页面元素?
Browser-Use 给出了一套完整的解法:
- 「DomService + buildDomTree.js」
:智能提取可交互元素,生成编号地图 - 「截图 + DOM 双通道」
:视觉理解和结构化操作双管齐下 - 「Action Registry」
:把浏览器操作封装成 AI 可调用的工具库 - 「Perceive-Reason-Act 循环」
:让 AI 一步步推进任务,支持自我评估和错误恢复
这套架构不仅适用于浏览器自动化,也为我们做任何”AI 操控复杂界面”的产品提供了很好的参考。
推荐资源:
- 「Browser-Use GitHub」
:https://github.com/browser-use/browser-use - 「Browser-Use 文档」
:https://docs.browser-use.com - 「Playwright 文档」
:https://playwright.dev - 「Chrome DevTools Protocol」
:https://chromedevtools.github.io/devtools-protocol

往期推荐



-
欢迎加我微信,拉你进技术群,长期交流学习…
-
欢迎关注「前端Q」,认真学前端,做个专业的技术人…