当前时间: 2026-02-26 10:51:49
分类:软件教程
评论(0)
用大白话讲透Word2Vec
别再AI的网络技话术忽悠了!Word2Vec根本不是什么高深莫测的黑科技,本质就是教电脑“猜邻居”。今天我用大白话给你扒得明明白白,全程不玩套路、不说教,听完直接拿捏NLP最基础的逻辑,新手也能拿捏。
先问大家一个最实在的问题:电脑根本不认识汉字,它怎么知道“地铁”和“公交”是一类词,为啥也知道“地铁”和“唐僧”八竿子打不着?答案很简单,就是Word2Vec,全程就5步,待老衲一步步叙来,一看就懂。
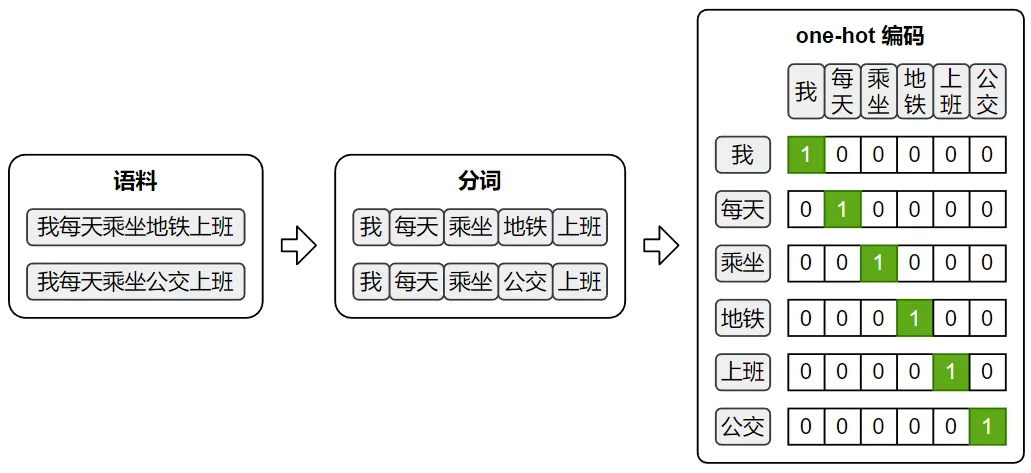
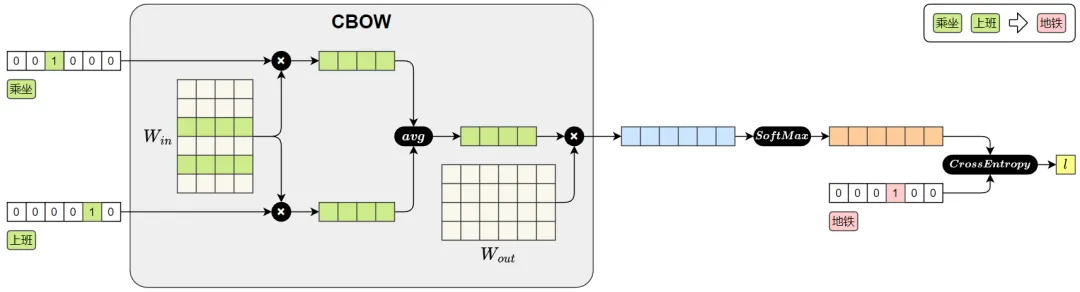
第一步,确定主角,给它标上唯一身份。我们就以“地铁”为核心,也就是输入中心词。电脑不认识“地铁”这两个字,就用最直接的方式——给它一个专属标识,这就是one-hot向量。说白了,这个向量只有两个状态:是地铁,或者不是地铁,没有中间地带,目的就是精准锁定我们要分析的词,没有任何复杂含义。
第二步,通过Win,取出“地铁”的“含义密码”。很多人把Win吹得神乎其神,其实它就是一个词向量矩阵,本质就是电脑里存着的一本“词意对照表”,每一行对应一个词的词向量,也就是这个词的“含义密码”。这里要明确一点:刚开始这本“对照表”全是随机数字,相当于一本乱码本,电脑自己也不懂,后续都是靠不断学习慢慢修正的。我们用刚才给“地铁”标的one-hot身份,和Win相乘,本质就是查这本“乱码本”,精准抽出“地铁”对应的那行数字,也就是它的词向量,和我们查字典找解释,逻辑完全一样,就是这么easy!
第三步,用Wout,给“地铁”的邻居打分。拿到“地铁”的含义密码后,下一步就是让电脑猜,“地铁”旁边最可能出现哪些词。这时候就用到Wout,它也是一个参数矩阵,但和Win的分工完全不同,别搞混了。Wout的唯一作用就是“打分”,我们把“地铁”的词向量和Wout相乘,就能给词表里所有的词都打一个分。分数高低,就代表这个词出现在“地铁”旁边的可能性大小,这就是预测上下文。比如“上班”跟“乘坐”这类和“地铁”相关的词,分数会很高,而“唐僧”和“地铁”则基本是无关的词,分数几乎为0,这就是Wout。
第四步,用Softmax,把分数变成能看懂的概率。刚才的打分是纯数字,电脑看着也似懂非懂,Softmax的作用就把这些杂乱无章的分数,转换成0到1之间的概率分布,而且所有词的概率加起来刚好是1。比如“上班”的概率是30%,“乘坐”是25%,意思很直白:“地铁”旁边出现“上班”的可能性是30%,出现“乘坐”的可能性是25%,不用懂公式,一听是否就明白。
第五步,算损失,看电脑猜得准不准,不能凭感觉,得有明确的评判标准。我们拿电脑预测出来的概率,和真实的上下文词——“乘坐”和“上班”做对比,看两者之间的差距,这个差距就是“损失”。具体来说,就是计算交叉熵损失,再把这些差距加起来,得到总损失。损失越大,说明电脑猜得越差;损失越小,说明电脑猜得越准,后续只要根据这个损失,慢慢调整Win和Wout,就能让电脑越学越精准。
这里必须吐槽一句:很多博主把Win和Wout吹得很高深,其实大可不必!Win和Wout看似都是表格,但他们分工完全不同,别搞混了!Win是“核心干货”,训练到最后,原本的乱码会变成有实际意义的词向量,是我们最终要的东西,后续做任何NLP任务都能用;而Wout只是“临时工具”,纯属就是对Win做辅助作用,用完就可以丢 弃。
还有人问,Win刚开始为啥都是随机生成的一串串数字?很简单,电脑一开始就是“小白”,什么都不懂,必须从“无知”开始,随机生成一个起点,再根据每次猜错的差距(也就是总损失),一点点微调Win和Wout里的内容,猜得越多,调得越准,到最后,Win里的“地铁”,就真的懂了“通勤”、“地下”这些跟它相关词的“真实含义”。
总结一下,Word2Vec的核心逻辑,全程就5步,没有复杂公式,没有花哨套路:输入中心词(地铁)→ 用one-hot标身份 → 查Win拿词向量 → 用Wout猜邻居打分 → Softmax转概率 → 对比真实词算总损失。说白了,就是让电脑从“无知”开始,通过“猜邻居”不断修正自己,慢慢读懂每个词的含义。看透了其实特别简单。
想知道Win和Wout的维度怎么定?为啥看到有博主提到的Win不是随机生成的?交叉熵损失具体怎么算?反向传播怎么微调更高效?评论区备注,老僧,按备注高低后续分别一一拆解,新手也能一看就明白,关注我,技术不绕弯,干货不掺水,下期继续分享更多AI知识点。
本站文章均为手工撰写未经允许谢绝转载:
夜雨聆风 »
用大白话讲透Word2Vec
 夜雨聆风
夜雨聆风