 夜雨聆风
夜雨聆风





我给Claude搭了一个野生的东财插件:从此它也能像分析师一样拉数据
导读我给Claude搭了一个东方财富Choice的数据插件——不是官方合作,纯靠逆向工程。爬了130万条指标建索引,让大模型也能像人类分析师一样,一句话就从金融终端拉数据、画图、写报告。下面是完整的搭建过程和实战Demo。
一、大模型的“数据盲区”
这两天我一直在琢磨一件事:怎么让大模型拥有和人类分析师一样的工具。
我们前几期测试过,大模型可以直接读年报PDF、抓取网页数据——这个能力非常重要,金融终端没有收录的数据(比如用Claude秒读4000+份PDF:银登中心不良贷款数据的首次系统化挖掘),只能靠大模型去设计方案从PDF里提取,这条路我们已经跑通了。
但反过来,金融终端里有的数据——社融、信贷、M1/M2、银行营收净利润这些标准指标——如果还让大模型去啃PDF,就完全走错了方向。一份PDF几十页,喂进去消耗大量Token,而且你不可能从一个PDF里凑出完整的历史时间序列。
打个比方:你不会为了查个M2同比去翻央行的PDF统计报告——打开终端,敲个指标代码,几毫秒就出来了,还带完整的历史数据。大模型也应该这样工作。
人类分析师的日常就是这样:大部分时候直接在金融终端(万得、同花顺、东方财富)里拉数据,指定一个指标代码和时间范围,几毫秒就返回完整的时间序列,拿来直接画图。金融终端就是分析师最核心的生产工具,每天打开电脑第一件事就是登录终端。
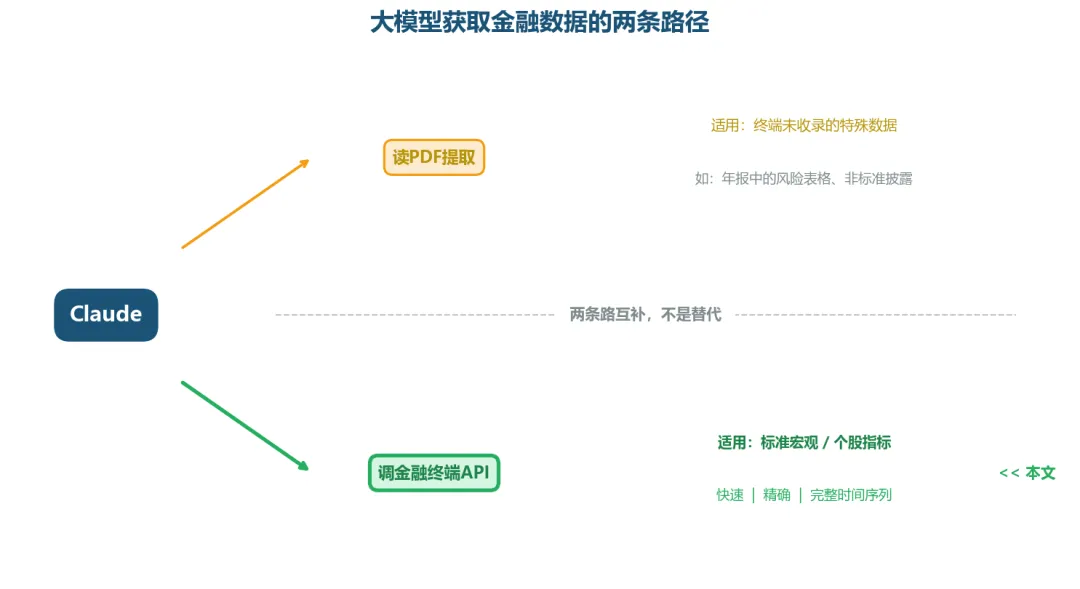
大模型获取金融数据的两条互补路径
所以思路很清楚:终端有的数据走终端API,终端没有的数据走PDF提取,两条路互补。本文讲的是第一条路——怎么让大模型直接调金融终端。
|
|
|
|
|---|---|---|
|
|
|
标准宏观/个股指标 |
|
|
|
~10分钟 |
|
|
|
|
|
|
|
|
|
|
|
|
二、130万条指标,没有一本目录
想法很简单,做起来发现远比想象中复杂。
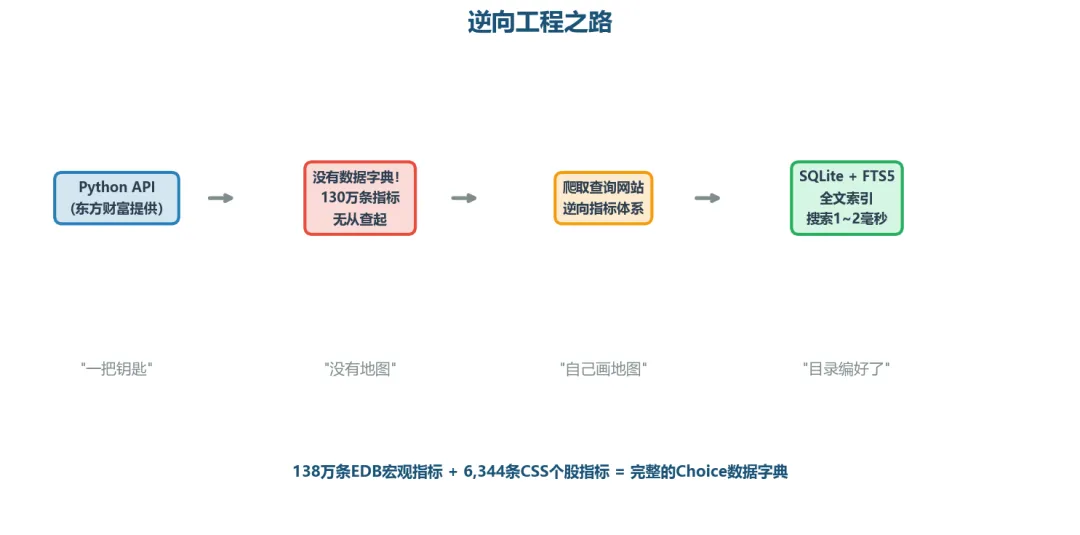
东方财富给了一个Python API(EMQuant),你可以调函数拉任意指标数据。但问题是——它没有写数据字典。你知道社融增量、PPI这些指标一定在系统里,但它们的指标代码是什么?在互联网上搜索不到。只能我人工去终端里一个一个找。
打个比方:这就像拿到了一座130万册藏书的图书馆钥匙,推门进去发现——没有目录,没有索引,书架上也没有标签。你知道书就在某个架子上,但不知道该往哪找。
我们做了一件笨功夫:把东方财富的在线查询页面整个爬了下来——逐页解析指标名称、代码、频率、单位,一条一条录入。相当于给这座没有目录的图书馆,自己手写了一份完整的索引卡片。
逆向工程之路:从API黑箱到可搜索字典
最终成果
138万条EDB宏观指标(GDP、CPI、M2、社融、利率、汇率……全覆盖)6,344条CSS个股指标(营收、净利润、不良率、净息差……银行业全覆盖)SQLite + FTS5全文索引,任意关键词搜索耗时1-2毫秒41个已验证指标经人工逐一确认,LLM可直接使用,无需重复验证
但光有字典还不够。138万条指标里,名字相似但含义完全不同的比比皆是。
真实教训:INCOMESTATEMENT_48 是“营业利润”,INCOMESTATEMENT_61 才是“归属于母公司股东的净利润”。如果LLM自动选错,数值差出几倍,报告结论完全错误。所以我们在工作流里加了一个人工确认卡点:LLM搜索完候选指标后,必须汇总清单给人确认,确认过的指标进入已验证清单,下次直接跳过。
三、一个“野生”的东财插件
2025-2026年,海外金融数据商陆续官方接入LLM生态:FactSet通过MCP连接器接入Claude,S&P Global Capital IQ和LSEG通过合作插件提供数据服务,Thomson Reuters用Claude Agent SDK重构法律AI助手CoCounsel。
FactSet走的是正门——官方合作、标准API、完整文档。我们走的是后门——逆向工程、自建字典、野生插件。但推开门之后,Claude看到的数据是一样的。Anthropic进军金融核心业务,Claude Agent接入投行工具链。
本质上,我们做的和FactSet、汤森路透做的是同一件事:把金融终端的结构化数据接入LLM,让它从“只会读文档的学者”变成“能用工具的分析师”。区别只是他们有官方支持,我们靠逆向工程。
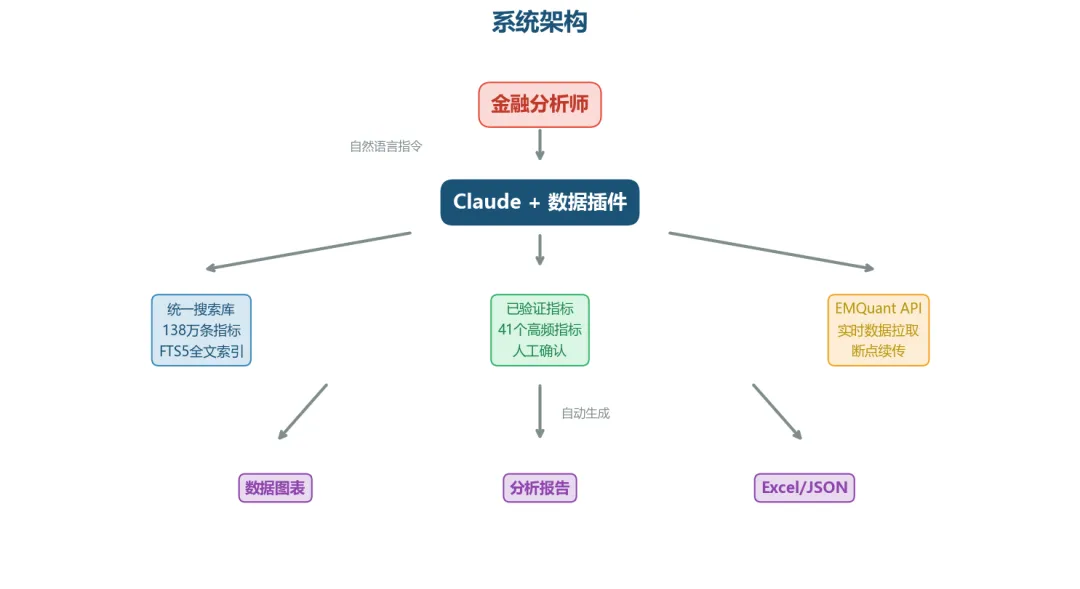
系统架构:自然语言 → 搜索库 → 人工确认 → 数据拉取 → 报告生成
核心组件
1. 统一指标搜索库 — 138万条指标,SQLite FTS5全文索引,搜索1-2毫秒2. 已验证指标清单 — 41个经人工确认的高频指标,LLM可直接使用3. 人工确认工作流 — 新指标必须经人确认后才能用于拉数据,杜绝选错指标的风险
四、实战Demo
以下是一次真实的使用过程。我对Claude说:“帮我分析一下2026年1月金融数据,再看一下六大行最近几年的经营趋势。” 从发出这句话到生成完整报告(含下面所有图表),全程约10分钟。所有数据均通过EMQuant API实时拉取。
4.1 社融总量与结构
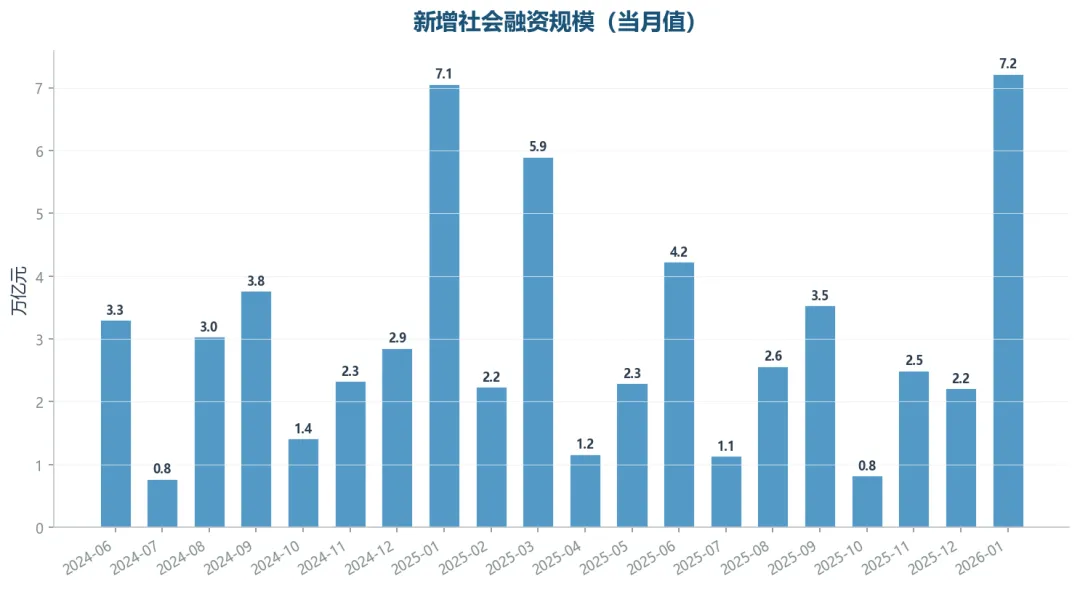
近期月度新增社融(单位:万亿元)
2026年1月新增社融7.22万亿元。分项来看,新增人民币贷款4.90万亿元,政府债券净融资9,764亿元,企业债券融资5,033亿元。
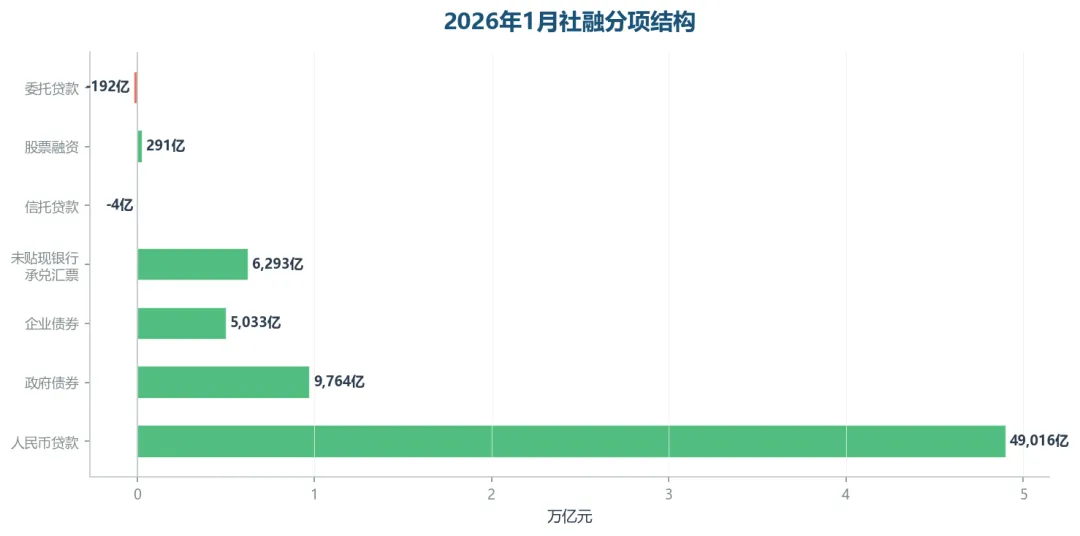
2026年1月社融分项结构
4.2 信贷结构
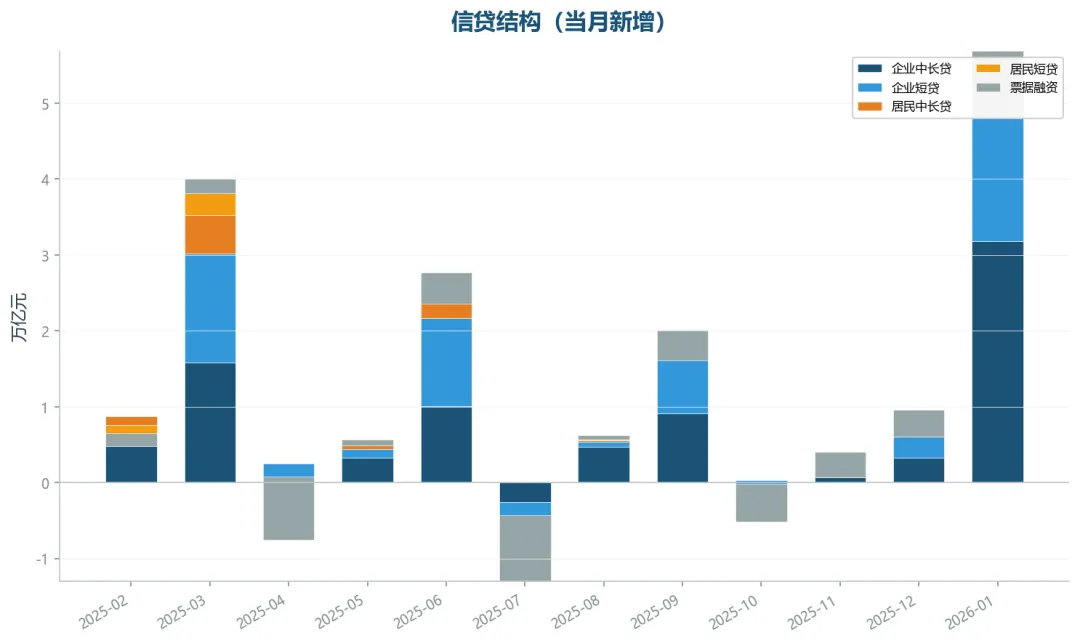
信贷结构堆积图
企业中长期贷款新增3.18万亿元,企业短期贷款新增20,500亿元,票据融资-0.87万亿元。
居民中长期贷款新增3,469亿元,居民短期贷款新增1,097亿元。
4.3 货币供应:M1与M2
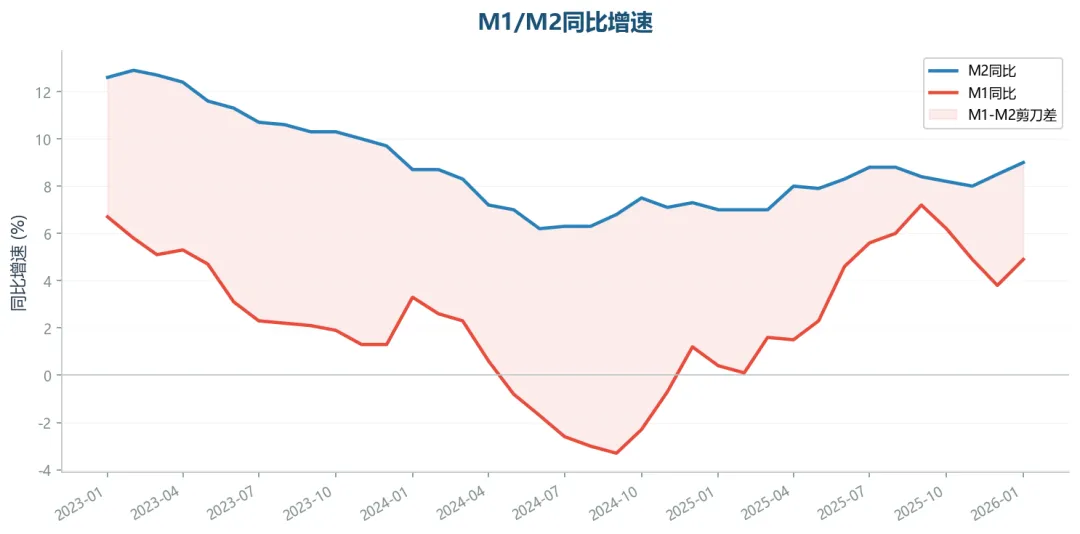
M1/M2同比走势
2026年1月M2同比9.0%,M1同比4.9%。
新口径M1提示:2025年起央行将个人活期存款和非银行支付机构备付金纳入M1统计口径,新旧口径下M1走势可能有较大差异,分析时需注意数据口径。
4.4 社融存量与广义货币
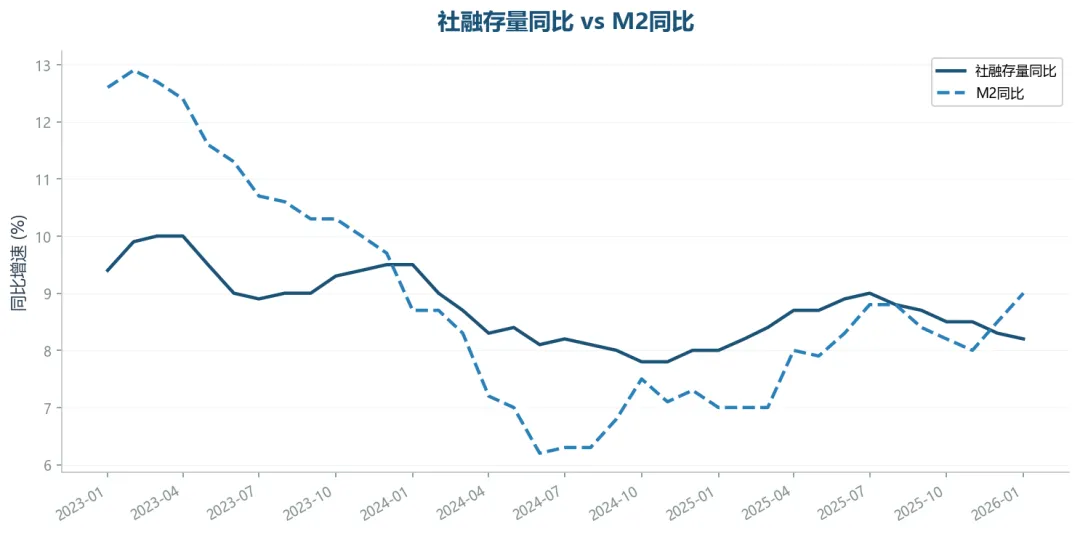
社融存量同比 vs M2同比
2026年1月社融存量同比8.2%,M2同比9.0%。
4.5 国有大行经营趋势
上面是宏观EDB指标(社融、信贷、M1/M2),接下来演示另一类数据:个股CSS指标。我们拉取了六大国有银行(工农中建交邮储)最近15个季度的营收和归母净利润,计算合计的累计同比增速。
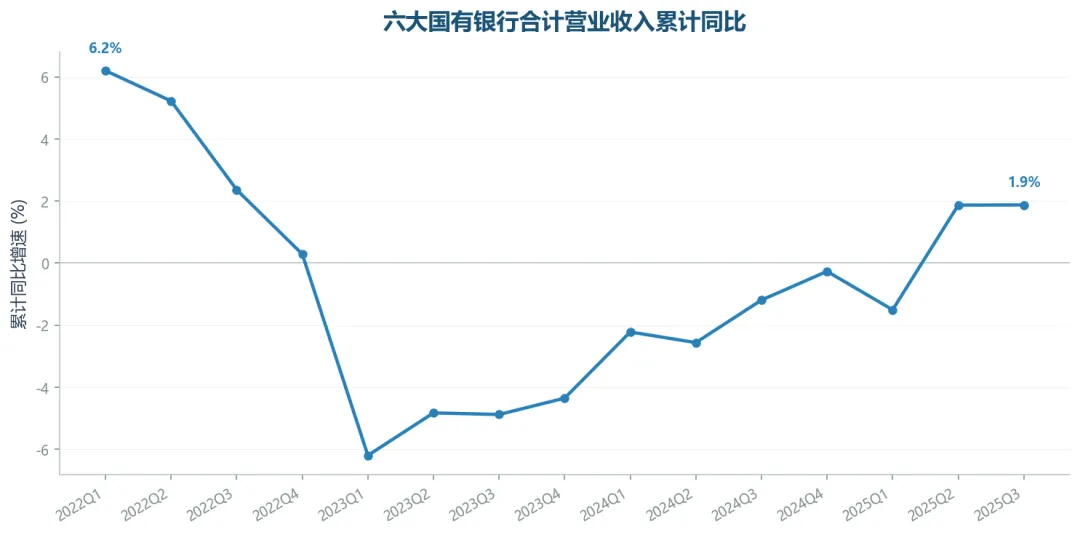
六大国有银行合计营业收入累计同比
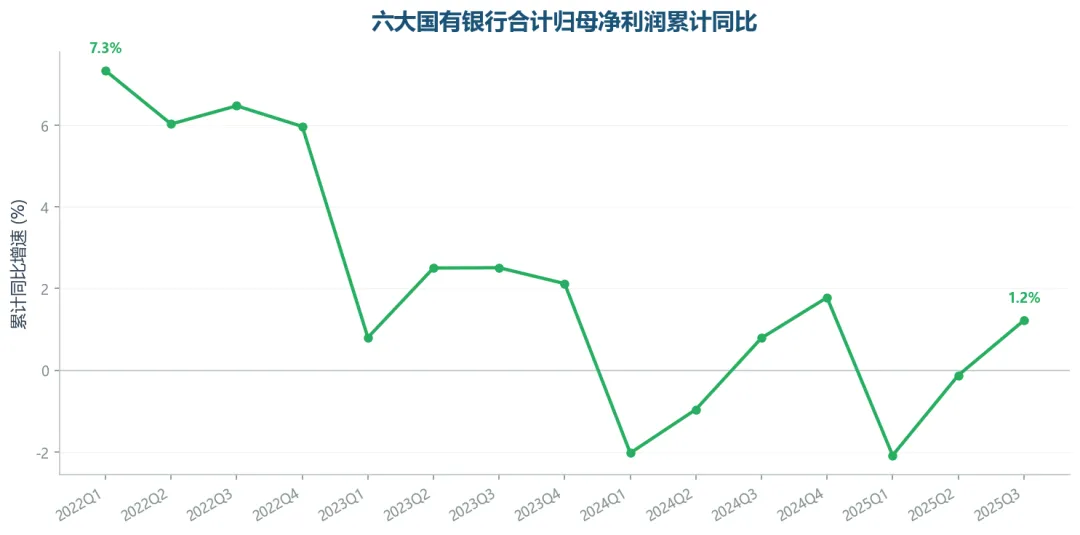
六大国有银行合计归母净利润累计同比
2025Q3,六大行合计营业收入累计同比+1.9%,归母净利润累计同比+1.2%。
从宏观指标到个股财务数据,同一套插件、同一个工作流。这就是金融终端API的价值——138万条指标,想拉什么拉什么。构建方式已经推送到github(https://github.com/lxistired/eastmoney-choice-plugin),可以让你的LLM去读取,人就没必要去读啦。
