 夜雨聆风
夜雨聆风





10分钟读懂陌生源码:用 Claude & OpenClaw Skill实现项目架构分析工作流
在 GitHub 上发现一个有趣的项目,想搞明白它的架构,但光是看 README 根本不够,去读源码又需要花好几天。
最近做了一个Skill:让 Claude Code 和 OpenClaw 代替我读源码,然后输出一份架构分析报告。整个过程大概 10-15 分钟。
本文就来分享这个方法,让 Claude Code 和 OpenClaw 都能用同一套流程分析项目架构。
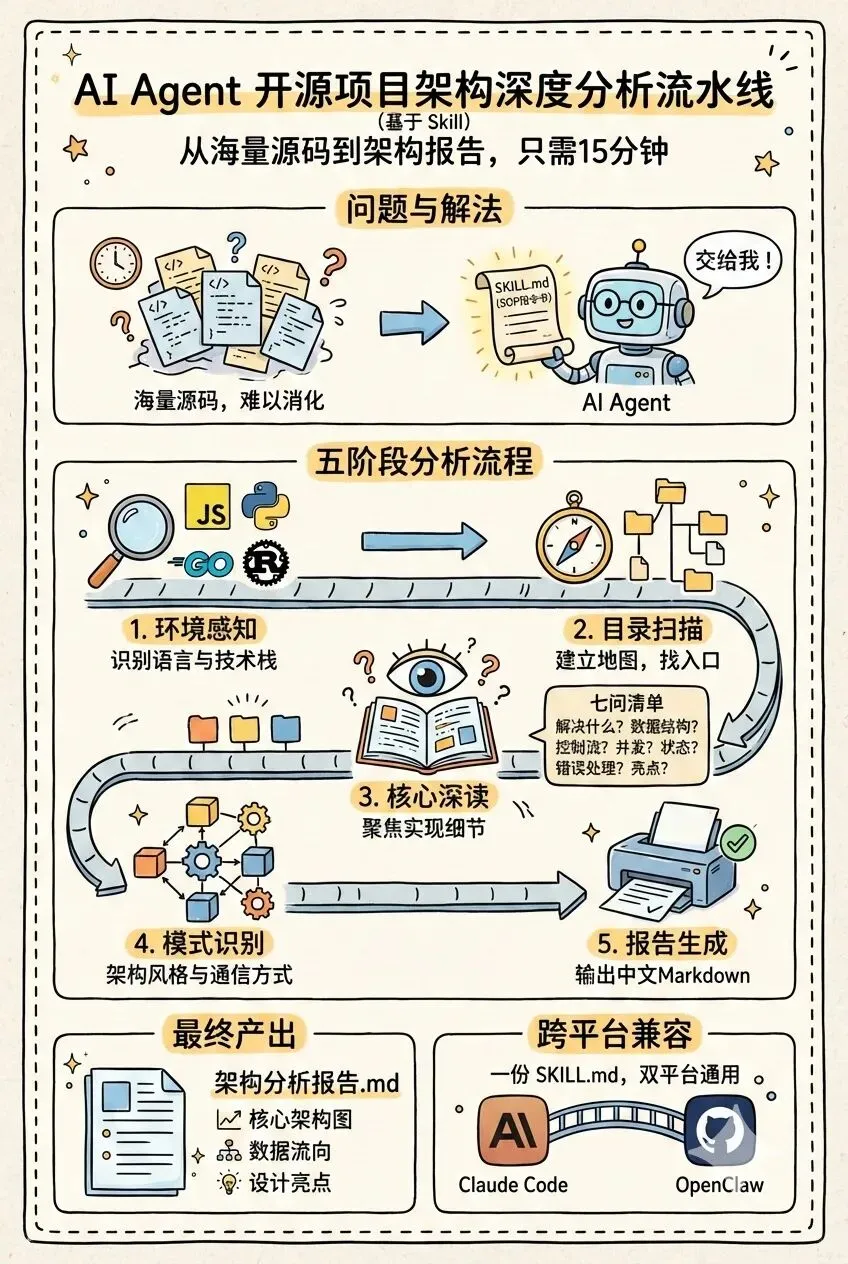
什么是 Skill?
如果你用过 Claude Code 或者 OpenClaw,你可能听说过 Skill 这个概念。简单来说:
Skill 就是一份 Markdown 文件,告诉 AI “遇到这类任务该怎么做”。
就像你给一个新同事写了一份 SOP(标准操作流程),AI 读完就知道该先做什么、再做什么、最后输出什么格式。
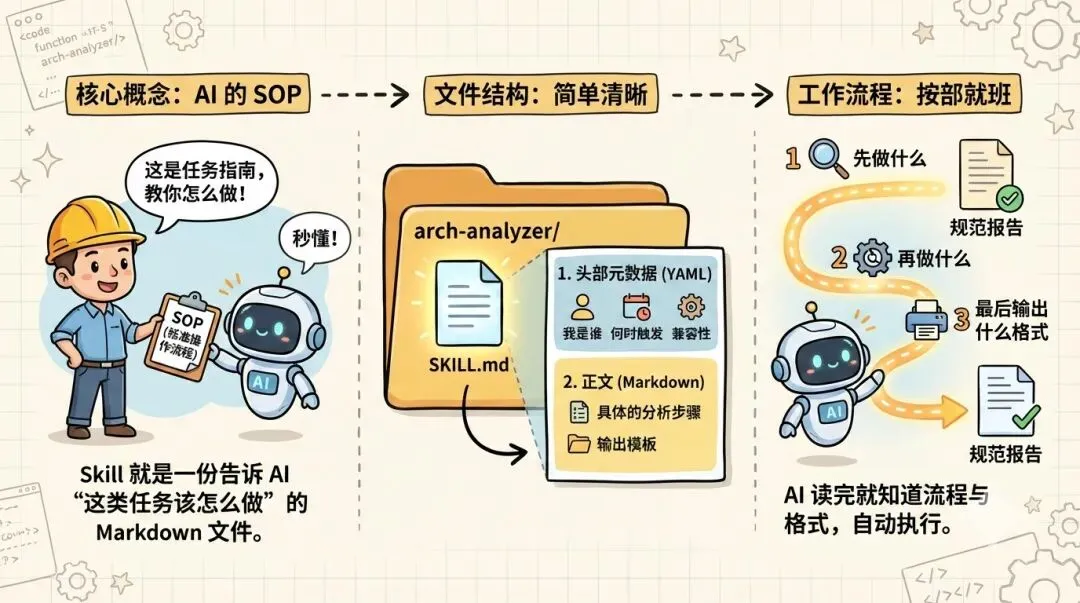
Skill 文件的结构很简单:
arch-analyzer/
└── SKILL.md ← 就这一个文件
SKILL.md 里面有两部分:
头部元数据(YAML frontmatter):告诉系统”我是谁、什么时候该用我”
正文(Markdown):具体的分析步骤和输出模板
Anthropic 是首个提出并在 Claude 实现 Skills 的公司,像MCP那样,成为了 Agent 的事实标准。官方出了一份 Skills 指南,需要深入了解请看:
Anthropic首个Skills构建指南:将专业知识和操作规范固化为自动化执行引擎
完整 Skill 源码
下面是完整的arch-analyzer/SKILL.md,我会在后文解释。
---
name: arch-analyzer
description: >
Analyze open-source project architecture and generate a detailed Chinese technical report.
深度分析开源项目技术架构,生成中文架构拆解报告。
Triggers: "分析架构" "拆解项目" "analyze architecture" "dissect repo"
"帮我看看这个项目怎么实现的" "分析一下这个 repo" "analyze this codebase"
"项目架构分析" "源码分析" "code walkthrough" "technical deep dive"
Supports: TypeScript/JavaScript, Python, Go, Rust, Java, C/C++, Swift,
Kotlin, Bash/Shell, HTML/CSS, and config-only projects (Markdown/JSON/YAML/XML).
Output: structured Chinese Markdown report covering architecture overview,
core subsystem analysis, design pattern identification, and data flow.
version: "1.1"
# —— OpenClaw-compatible metadata ——
tools:
- read
- write
- exec
env: {}
---
# 开源项目架构深度分析 Skill
> **一句话定位**:对任意语言的开源项目做系统性源码级架构分析,产出一份聚焦
> **HOW(怎么实现)** 而非 WHAT(有什么功能)的中文技术拆解报告。
---
## 总览:五阶段分析流水线
```
阶段 1 阶段 2 阶段 3 阶段 4 阶段 5
获取代码 ──→ 目录扫描 ──→ 子系统深度阅读 ──→ 模式识别 ──→ 报告生成
clone 建地图 逐模块源码阅读 架构风格 Markdown
环境感知 入口识别 七问清单 数据流 中文输出
```
---
## 阶段 1:项目获取与环境感知
### 1.1 获取代码
```bash
# 远程仓库
git clone --depth 1 /tmp/target-repo && cd /tmp/target-repo
# 本地项目——直接 cd 进去即可
```
### 1.2 环境感知矩阵
依次检查下表中的文件,**命中即标记该语言/框架**。一个项目可能命中多行(多语言混合项目)。
| 探针文件 | 语言 / 生态 | 重点关注 |
|---------|------------|---------|
| `package.json` | **TypeScript / JavaScript** | dependencies · scripts · `"type":"module"` |
| `tsconfig.json` | TypeScript | target · paths · composite |
| `pyproject.toml` / `setup.py` / `requirements.txt` | **Python** | 依赖 · 入口 · build-backend |
| `go.mod` | **Go** | module path · Go 版本 · 依赖 |
| `Cargo.toml` | **Rust** | workspace members · features · edition |
| `pom.xml` / `build.gradle` / `build.gradle.kts` | **Java / Kotlin** | 多模块 · plugins · Spring/Ktor |
| `CMakeLists.txt` / `Makefile` (含 `.c`/`.cpp`/`.h`) | **C / C++** | 编译目标 · 库链接 · 子目录 |
| `Package.swift` / `*.xcodeproj` | **Swift** | targets · dependencies · platforms |
| `*.sh` / `justfile` / `Taskfile.yml` | **Bash / Shell** | 入口脚本 · 构建流程 |
| `index.html` / `vite.config.*` / `next.config.*` | **HTML / 前端** | 框架 · 路由 · 构建 |
| 仅 `*.md` / `*.json` / `*.yaml` / `*.xml` | **纯配置项目** | schema · 用途 · 关联工具 |
| `Dockerfile` / `docker-compose.yml` | 容器化 | 服务拓扑 · 端口映射 · volume |
| `.github/workflows/` / `.gitlab-ci.yml` | CI/CD | 构建步骤 · 测试 · 部署目标 |
```bash
# 快速探针(一行命令判断语言)
ls package.json tsconfig.json pyproject.toml go.mod Cargo.toml \
pom.xml build.gradle CMakeLists.txt Package.swift 2>/dev/null
```
---
## 阶段 2:目录结构扫描
**目标:建立项目的"地图",识别入口和模块边界。**
```bash
# 通用目录树(排除噪音目录)
find . -type f \
-not -path '*/node_modules/*' \
-not -path '*/.git/*' \
-not -path '*/dist/*' -not -path '*/build/*' \
-not -path '*/__pycache__/*' \
-not -path '*/vendor/*' -not -path '*/.next/*' \
-not -path '*/target/*' -not -path '*/.build/*' \
-not -path '*/Pods/*' -not -path '*/.gradle/*' \
-not -name '*.lock' -not -name '*.map' \
-not -name '*.o' -not -name '*.a' -not -name '*.so' \
-not -name '*.class' -not -name '*.jar' \
| head -300
# 按扩展名统计文件数量
find . -type f | sed 's/.*\.//' | sort | uniq -c | sort -rn | head -20
# 代码行数概览(需要 cloc 或 wc 替代)
find . -name '*.ts' -o -name '*.py' -o -name '*.go' -o -name '*.rs' \
-o -name '*.java' -o -name '*.kt' -o -name '*.c' -o -name '*.cpp' \
-o -name '*.swift' -o -name '*.sh' | xargs wc -l 2>/dev/null | tail -1
```
**从目录树中识别(通用清单):**
| 要素 | 常见路径 |
|------|---------|
| 入口点 | `main.*` · `index.*` · `cmd/` · `bin/` · `src/main.*` · `app/` |
| 核心模块 | `src/` · `lib/` · `pkg/` · `internal/` · `core/` · `modules/` |
| 配置 | `config/` · `.env*` · `settings/` · `resources/` |
| 测试 | `tests/` · `__tests__/` · `*_test.*` · `spec/` · `test/` |
| 文档 | `docs/` · `ARCHITECTURE.md` · `DESIGN.md` · `ADR/` |
> **优先阅读**:如果存在 `ARCHITECTURE.md`、`DESIGN.md` 或 `docs/architecture/`,先读它们——作者自己写的架构说明比 AI 猜的准。
---
## 阶段 3:核心子系统深度阅读
### 3.1 入口点追踪(所有语言通用)
```
读入口文件 → 找 import / require / use / include → 追踪核心模块 → 理解初始化顺序
```
### 3.2 按语言选择分析命令
根据阶段 1 识别的语言,选择对应的 grep 策略。**混合语言项目需要组合使用多组命令。**
#### TypeScript / JavaScript
```bash
grep -rn "export " src/ --include="*.ts" --include="*.tsx" --include="*.js" | head -50
grep -rn "class \|interface \|type " src/ --include="*.ts" | head -50
grep -rn "emit\|\.on(\|subscribe\|addEventListener" src/ --include="*.ts" | head -30
grep -rn "async \|await \|Promise" src/ --include="*.ts" | head -30
```
#### Python
```bash
grep -rn "^class " --include="*.py" | grep -v __pycache__ | head -50
grep -rn "^def \|^async def " --include="*.py" | head -50
grep -rn "@.*\ndef \|@.*\nclass " --include="*.py" | head -30
grep -rn "if __name__" --include="*.py" | head -10
grep -rn "app\.\|router\.\|blueprint" --include="*.py" | head -20 # Web 框架
```
#### Go
```bash
grep -rn "type.*interface {" --include="*.go" | head -50
grep -rn "type.*struct {" --include="*.go" | head -50
grep -rn "func main\|func init" --include="*.go" | head -20
grep -rn "go func\|make(chan\|<-\|select {" --include="*.go" | head -30
grep -rn "http\.Handle\|grpc\.\|mux\." --include="*.go" | head -20
```
#### Rust
```bash
grep -rn "^pub struct \|^pub enum \|^pub trait " --include="*.rs" | head -50
grep -rn "^pub fn \|^pub async fn " --include="*.rs" | head -50
grep -rn "impl " --include="*.rs" | head -50
grep -rn "tokio\|async_std\|#\[tokio::main\]" --include="*.rs" | head -20
grep -rn "mod \|use " src/ --include="*.rs" | head -30
```
#### Java / Kotlin
```bash
grep -rn "^public class \|^public interface \|^abstract class " --include="*.java" | head -50
grep -rn "@RestController\|@Service\|@Repository\|@Component" --include="*.java" | head -30
grep -rn "^class \|^interface \|^object \|^data class " --include="*.kt" | head -50
grep -rn "@Route\|@Get\|@Post\|fun main" --include="*.kt" | head -20
```
#### C / C++
```bash
grep -rn "^struct \|^class \|^typedef " --include="*.h" --include="*.hpp" | head -50
grep -rn "^int main\|^void main" --include="*.c" --include="*.cpp" | head -10
grep -rn "#include " --include="*.c" --include="*.cpp" | sort -u | head -30
grep -rn "pthread_\|std::thread\|std::async\|fork(" --include="*.c" --include="*.cpp" | head -20
```
#### Swift
```bash
grep -rn "^class \|^struct \|^protocol \|^enum " --include="*.swift" | head -50
grep -rn "^func \|^@main\|@objc " --include="*.swift" | head -30
grep -rn "async \|await \|Task {" --include="*.swift" | head -20
```
#### Kotlin (Android / Multiplatform)
```bash
grep -rn "^class \|^data class \|^sealed \|^interface " --include="*.kt" | head -50
grep -rn "@Composable\|@AndroidEntryPoint\|@HiltViewModel" --include="*.kt" | head -20
```
#### Bash / Shell
```bash
find . -name "*.sh" -exec head -5 {} \; | head -40 # 查看 shebang 和说明
grep -rn "function \|^[a-z_]*() " --include="*.sh" | head -30
```
#### HTML / 前端 (React / Vue / Svelte 等)
```bash
grep -rn "export default\|export function\|defineComponent" --include="*.vue" --include="*.svelte" --include="*.jsx" --include="*.tsx" | head -30
grep -rn "createRouter\|createApp\|ReactDOM.render\|hydrateRoot" --include="*.ts" --include="*.js" | head -10
```
#### 纯配置项目 (Markdown / JSON / YAML / XML)
```bash
# 统计文件类型分布
find . -name '*.md' -o -name '*.json' -o -name '*.yaml' -o -name '*.yml' -o -name '*.xml' | wc -l
# 查看 JSON/YAML schema
find . -name '*.schema.json' -o -name '*.json' | head -10 | xargs head -20 2>/dev/null
# 查看核心 Markdown 文件结构
find . -name '*.md' | head -20
```
### 3.3 每个子系统的"七问清单"
对每个识别出的子系统,回答以下 7 个问题:
| # | 问题 | 回答要点 |
|---|------|---------|
| 1 | **它解决什么问题?** | 一句话概括 |
| 2 | **核心数据结构?** | 关键 type / interface / struct / class |
| 3 | **控制流?** | 入口 → 中间处理 → 输出,画箭头 |
| 4 | **并发模型?** | 单线程 / 线程池 / goroutine / async-await / Actor |
| 5 | **状态存储?** | 内存 / 磁盘文件 / SQLite / PostgreSQL / Redis |
| 6 | **错误处理?** | 重试 / 降级 / 熔断 / panic-recover / Result |
| 7 | **精巧设计?** | 值得专门讲的亮点或创新 |
---
## 阶段 4:关系与模式识别
阅读完各子系统后,从全局视角识别以下模式:
**架构风格清单:**
- 整体风格:单体 / 微服务 / Monorepo 多包 / 插件式 / Hub-and-Spoke / 管道-过滤器 / 分层
- 通信方式:同步 RPC / REST / gRPC / 事件驱动 / WebSocket / 消息队列 / Channel
- 数据流:单向 / 双向 / 发布-订阅 / CQRS / Event Sourcing
- 持久化:文件系统 / SQLite / PostgreSQL / MySQL / Redis / S3 / 自定义
- 扩展机制:插件 / Hook / 中间件 / 装饰器 / SPI / Protocol Extension
- 安全边界:沙箱 / 权限层 / OAuth / RBAC / 加密通道
**模块关系速写格式(ASCII 即可):**
```
模块A ──→ 模块B ──→ 模块C
│ ↑
└──→ 模块D ────────┘
```
---
## 阶段 5:报告生成
### 报告模板
```markdown
# [项目名] 技术架构深度拆解:[N] 个核心子系统源码解析
[作者名]
[日期]
## 关于本文
这篇文章由 AI 自动分析 [项目名] 开源代码库后生成,聚焦 HOW(实现细节)
而非 WHAT(功能介绍)。[作者名] 对结构和关键判断做了审校,
但主体内容来自 AI 的源码阅读。
这本身就是"AI 辅助深度研究"的一个实际案例。
## 1. 整体架构概览
[一段话:项目是什么、语言/框架/运行时、核心设计模式]
[ASCII 架构图]
## 2. [子系统A]:[一句话定位]
### 2.1 [子模块]
[实现细节 + 源码路径引用]
### 2.2 [子模块]
...
## 3. [子系统B]
...
(按重要性排序,逐个拆解所有核心子系统)
## N. 关键设计理念总结
### N.1 [理念/模式名]
[解释设计选择的原因、权衡和效果]
### N.2 [理念/模式名]
...
```
### 报告质量标准(6 条红线)
| # | 标准 | 说明 |
|---|------|------|
| 1 | **源码路径** | 关键实现必须引用文件路径,如 `src/gateway/router.ts:42` |
| 2 | **具体数字** | 端口、超时、队列深度、默认值——不说"一个数字",要给出实际值 |
| 3 | **类比解释** | 用已知系统做类比,如"类似 Nginx upstream" |
| 4 | **ASCII 图表** | 架构关系用文字图表,不依赖外部绘图工具 |
| 5 | **设计权衡** | 解释"为什么选 A 不选 B",不只描述 A |
| 6 | **中文 + 术语** | 正文用通俗中文,技术术语保留英文原文 |
### 注意事项
- **不要猜测**——源码里看不到的就写"未在源码中发现"
- **区分意图和实现**——README 写的功能可能尚未实现,以源码为准
- **关注注释**——TODO / FIXME / HACK / XXX 揭示技术债务
- **聚焦关键路径**——大型项目不必分析每个文件
- **优先读架构文档**——ARCHITECTURE.md / DESIGN.md / ADR/ 比猜测可靠
- **注意 monorepo**——先理清包的边界和依赖关系,再逐包分析
Skill 设计拆解:为什么这样写
头部元数据:一份文件兼容两个平台
---
name: arch-analyzer
description: >
Analyze open-source project architecture and generate a detailed Chinese
technical report.
深度分析开源项目技术架构,生成中文架构拆解报告。
Triggers: "分析架构" "拆解项目" "analyze architecture" "dissect repo"
"帮我看看这个项目怎么实现的" "分析一下这个 repo" ...
version: "1.1"
tools:
- read
- write
- exec
env: {}
---
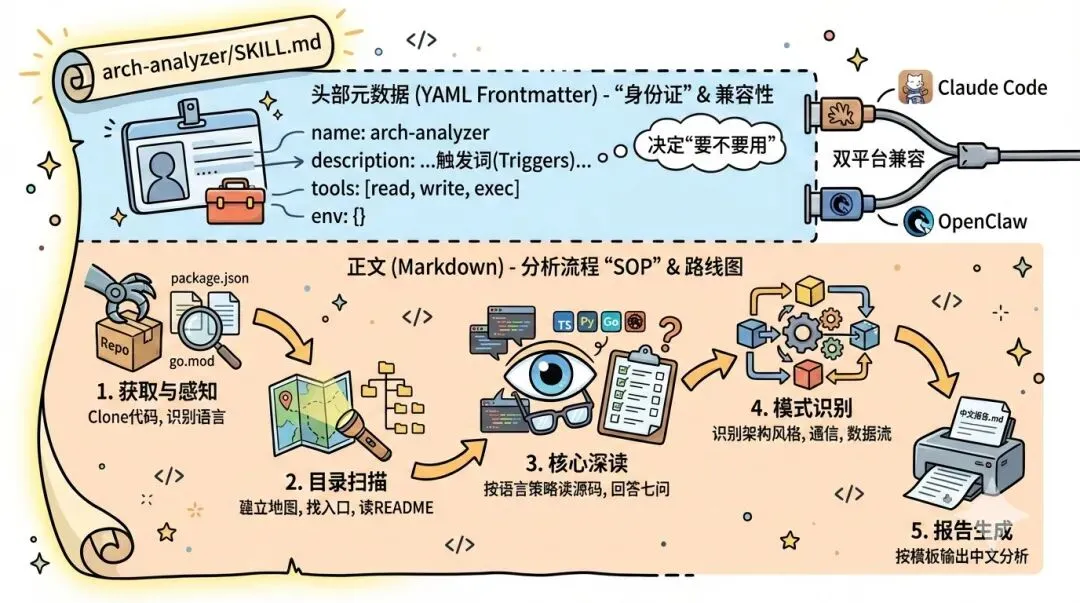
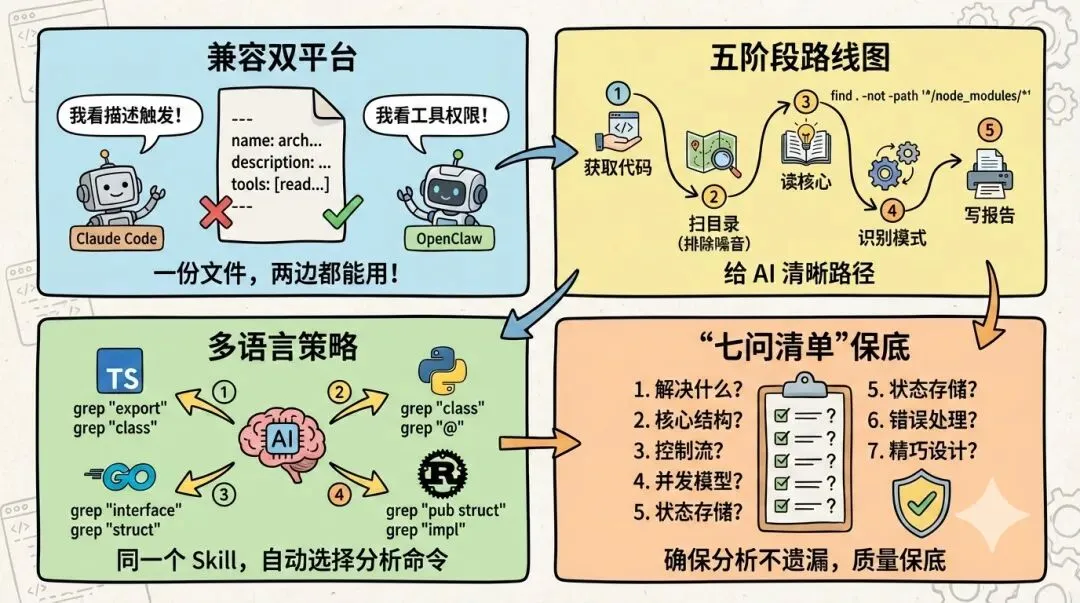
这段 YAML frontmatter 是整个 Skill 的”身份证”。这里有一个关键设计——同时兼容两个平台:
Claude Code 关心的字段:
name:Skill 的标识符,在 available_skills列表中展示
description:最重要的字段。Claude Code 靠这段文字决定”要不要用这个 Skill”。所以我把触发词写得很丰富——”分析架构”、”拆解项目”、”看看怎么实现的”这些口语化的表达都包含进去了
OpenClaw 关心的字段:
tools:声明这个 Skill 需要用到哪些工具(read 读文件、write 写文件、exec 执行命令)
env:声明需要注入的环境变量(这里不需要)
两边都能读name和description,而各自独有的字段会被对方忽略,互不干扰。这就是”兼容”的秘密,不是做两份文件,而是在同一份文件里塞进两边都能理解的信息。
五步分析法:模拟架构师的读码路径
Skill 正文把分析流程拆成 5 步,模拟一个有经验的架构师拿到陌生代码库的自然思维流:
第 1 步"这是什么?" → 第 2 步"有哪些东西?" → 第 3 步"每块怎么实现?"
→ 第 4 步"它们之间什么关系?" → 第 5 步"写成文档"
每一步之间有明确的输入和输出,形成流水线:
| 阶段 | 输入 | 输出 |
|---|---|---|
| 1. 环境感知 | URL 或路径 | 语言标记 + 项目类型 |
| 2. 目录扫描 | 文件系统 | 模块列表 + 入口点 |
| 3. 深度阅读 | 模块列表 | 每个子系统的七问答案 |
| 4. 模式识别 | 所有七问答案 | 全局架构画像 |
| 5. 报告生成 | 架构画像 + 七问 | Markdown 报告 |
环境感知矩阵:让 AI 自动识别 10+ 种语言
阶段 1 的”环境感知矩阵”是整个 Skill 的关键创新。它是一张探针表:
看到 package.json → 标记为 TypeScript/JavaScript
看到 go.mod → 标记为 Go
看到 Cargo.toml → 标记为 Rust
看到 CMakeLists.txt → 标记为 C/C++
...
AI 只需要跑一行命令:
ls package.json tsconfig.json pyproject.toml go.mod Cargo.toml \
pom.xml build.gradle CMakeLists.txt Package.swift 2>/dev/null
就能在 1 秒内判断项目的主要语言。而且一个项目可以命中多行(比如前端 TypeScript + 后端 Go 的混合项目),AI 会在后续阶段组合使用多套分析命令。
多语言 grep 策略:同一个问题,不同语言不同问法
第三步是 Skill 最有价值的部分——它给每种语言提供了不同的 grep 命令来定位关键代码。
为什么不用一套通用命令?因为不同语言表达”核心抽象”的方式完全不同:
| 语言 | “核心抽象”的表达方式 | grep 目标 |
|---|---|---|
| TypeScript | export interface,export class |
导出声明 |
| Python | class,@decorator |
类定义和装饰器 |
| Go | type X interface,type Y struct |
接口和结构体 |
| Rust | pub trait,pub struct,impl T for S |
trait 系统 |
| Java | public interface,@Service |
接口和 Spring 注解 |
| C/C++ | typedef struct,.h头文件 |
头文件公共 API |
AI 在第一步判断完语言后,第三步自动选择对应的命令集。你不需要告诉它”这是一个 Go 项目”,它看到go.mod就知道了。
每种语言还有”重点关注”提示,比如 Go 的internal/包意味着不对外暴露,Rust 的Cargo.toml workspace表明是多 crate 项目,Python 的@app.route暗示这是一个 Web 应用。这些是帮 AI 理解项目结构的上下文线索。
“七问清单”:确保分析不遗漏
每个子系统必须回答 7 个固定问题:
1. 它解决什么问题?
2. 核心数据结构?
3. 控制流?
4. 并发模型?
5. 状态存储?
6. 错误处理?
7. 精巧设计?
这 7 个问题的设计逻辑是从外到内、从静态到动态。
没有这个清单,AI 分析代码时容易出两个问题:
泛泛而谈:只说”这个模块负责处理消息”,不说怎么处理的。
钻牛角尖:盯着某个函数的 10 行代码聊半天,忽略了整体。
七问迫使 AI 在每个子系统上均匀用力,产出的报告信息密度高且结构一致。
报告模板 + 质量检查清单:双重保底
报告模板规定了输出格式——标题、关于本文、架构概览、子系统逐个拆解、设计理念总结。这样每次分析产出的报告结构一致,方便横向对比不同项目。
最后的质量检查清单是 AI 的”自审”环节:有没有引用源码路径?有没有给具体数字?有没有画架构图?这 6 条红线与注意事项让 AI 在”交稿”前再过一遍,显著减少遗漏。
在 Claude Code 中使用
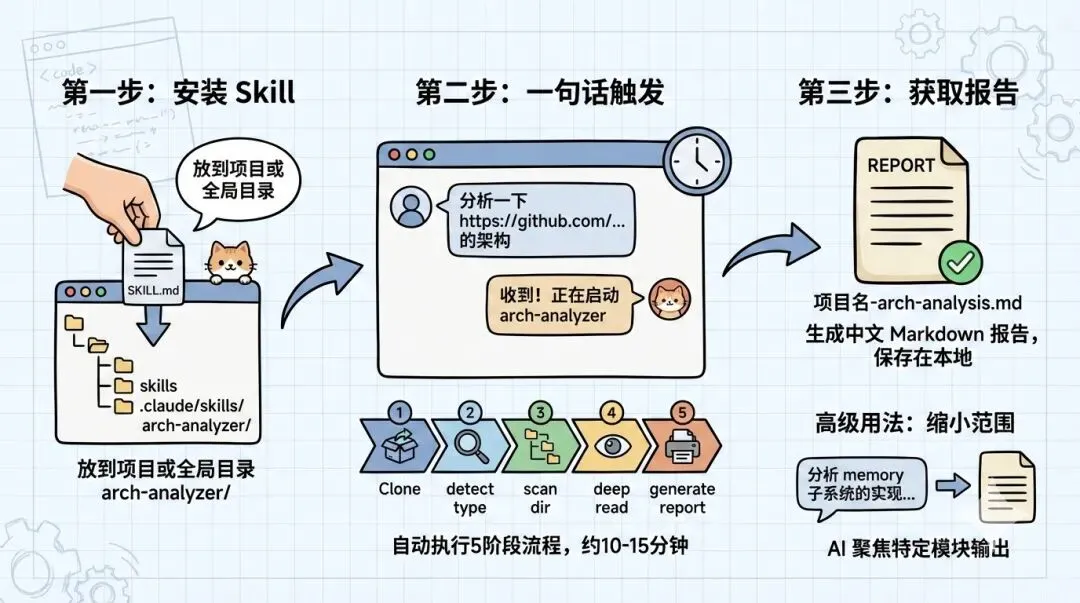
第一步:安装 Skill
把arch-analyzer/SKILL.md放到你项目的.claude/skills/目录下:
# 项目级安装(仅当前项目可用)
mkdir -p .claude/skills/arch-analyzer
cp SKILL.md .claude/skills/arch-analyzer/SKILL.md
或者放到全局目录,让所有项目都能用:
# 全局安装(macOS / Linux)
mkdir -p ~/.claude/skills/arch-analyzer
cp SKILL.md ~/.claude/skills/arch-analyzer/SKILL.md第二步:一句话触发分析
安装好之后,在 Claude Code 中直接说:
分析一下 https://github.com/openclaw/openclaw 这个项目的架构或者英文:
Analyze the architecture of https://github.com/openclaw/openclawClaude Code 会自动触发 arch-analyzer Skill(因为 description 里的中英文关键词都能命中,然后按五个阶段执行。
你会看到的过程
Claude Code 执行时,你会在终端看到类似这样的过程:
🔍 阶段 1/5:获取代码 & 环境感知
> git clone --depth 1 https://github.com/openclaw/openclaw /tmp/target-repo
Cloning into '/tmp/target-repo'... done.
> ls /tmp/target-repo/package.json /tmp/target-repo/tsconfig.json ...
package.json tsconfig.json
→ 识别为 TypeScript ESM 项目
> cat /tmp/target-repo/package.json | head -20
→ Node.js 22+, pnpm 构建, 可选 Bun
────────────────────────────────────────
🗺️ 阶段 2/5:目录结构扫描
> find /tmp/target-repo -type f -not -path '*/node_modules/*' ...
→ 发现 247 个源文件
→ 识别到 14 个核心模块目录
────────────────────────────────────────
📖 阶段 3/5:子系统深度阅读(最耗时,约 8-10 分钟)
正在分析 [1/14] Gateway (src/gateway/)...
✓ WebSocket 服务器,默认端口 18789
✓ 事件驱动,非轮询
✓ JSON Schema 验证所有 frame
正在分析 [2/14] Session Router (src/session/)...
✓ 层级化 session key:agent:main:whatsapp:direct:+155...
...
正在分析 [3/14] Lane Queue (src/queue/)...
✓ 纯 TypeScript + Promises,无外部依赖
✓ per-session lane 保证并发安全
...
(继续分析其余 11 个子系统)
────────────────────────────────────────
🧩 阶段 4/5:架构模式识别
→ Hub-and-Spoke 模式
→ 事件驱动 + WebSocket 通信
→ 文件系统 + SQLite 持久化
→ 插件 Hook 扩展机制
→ 容器沙箱安全边界
────────────────────────────────────────
📝 阶段 5/5:生成报告
✅ 报告已保存到 openclaw-architecture-report.md
覆盖 14 个子系统,8,200 字
整个过程约 10-15 分钟。其中阶段 3(逐模块深度阅读)最耗时,因为 AI 需要逐个打开文件、追踪 import 链、理解控制流。
高级用法
缩小分析范围:
如果你只想分析项目的某个子系统:
分析 openclaw 项目中 memory 子系统的实现,重点看混合搜索是怎么做的AI 会聚焦在 memory 相关的文件上,产出一份更深入但更窄的报告。
和另一个项目比较:
分析 openclaw 的 Channel Adapter 设计,和 Matrix 的 bridge 架构做对比分析本地项目:
分析我当前目录下的项目架构
不需要 clone,AI 直接读当前工作目录。
只看最近的变更:
分析 openclaw 最近 30 天的 commit,找出架构上的重大变更
在 OpenClaw 中使用
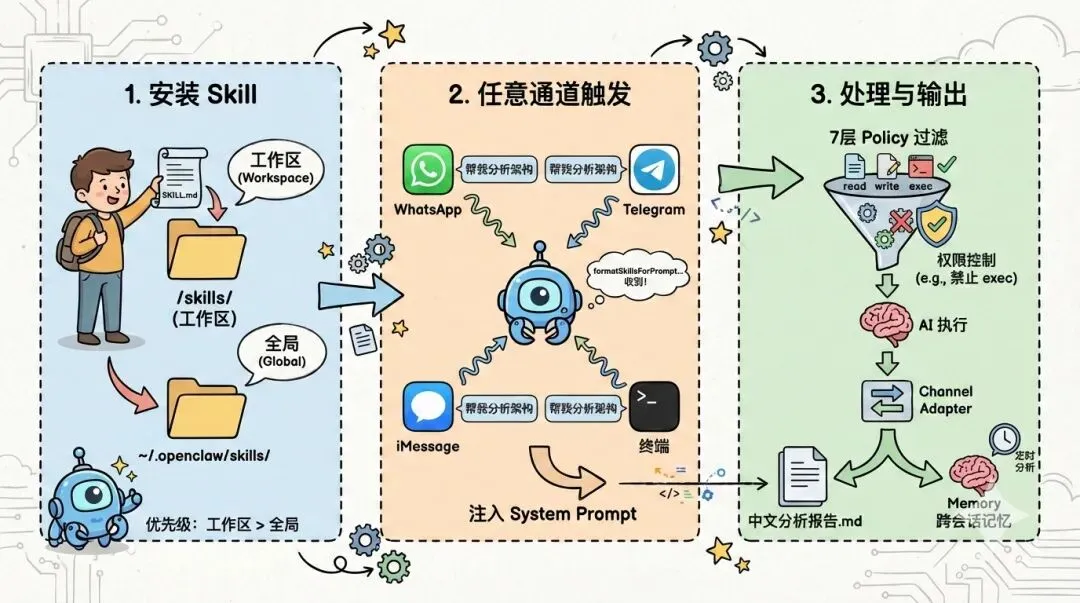
第一步:安装 Skill
OpenClaw 的 Skill 有三个加载位置,优先级从高到低:
# 方式一:工作区 skills(最高优先级)
mkdir -p ~/your-workspace/skills/arch-analyzer
cp SKILL.md ~/your-workspace/skills/arch-analyzer/SKILL.md
# 方式二:managed skills(全局可用)
mkdir -p ~/.openclaw/skills/arch-analyzer
cp SKILL.md ~/.openclaw/skills/arch-analyzer/SKILL.md
# 方式三:bundled skills(npm 包自带,最低优先级)
# 这个位置通常是项目维护者打包的,用户不需要手动操作第二步:通过任意通道触发
安装后,通过 OpenClaw 支持的任何通道发消息:
WhatsApp:
帮我分析一下 openclaw 这个项目的技术架构
Telegram 群聊:
@mybot 拆解一下 https://github.com/openclaw/openclaw 的源码
iMessage:
analyze the architecture of openclaw
本地终端:
openclaw chat "分析 openclaw 项目架构"OpenClaw 的处理流程
核心分析逻辑是一样的(都在读同一份 SKILL.md),但运行时环境有几个关键差异:
差异 1:Skill 注入方式
Claude Code 直接把 SKILL.md 加载到上下文里。OpenClaw 则是在 Agent 启动时,通过buildAgentSystemPrompt→formatSkillsForPrompt把所有可用 Skills 格式化成一段 compact XML 列表,注入到 system prompt 中。AI 看到用户消息后,再从这个列表里”选中”合适的 Skill 来执行。
差异 2:工具权限多一层过滤
SKILL.md 头部声明了tools: [read, write, exec]。在 OpenClaw 中,这些工具需要通过7 层 Tool Policy逐层过滤:
Profile Policy → Provider-Profile Policy → Global Policy
→ Global-by-Provider Policy → Agent Policy
→ Agent-by-Provider Policy → Group Policy
→ 再叠加 Sandbox 限制如果你的 Agent 配置里禁止了exec,那 Skill 中的 shell 命令(git clone、find、grep)就执行不了,AI 会退回到纯文件读取模式。
差异 3:报告投递到聊天通道
Claude Code 把报告保存为本地 Markdown 文件。OpenClaw 则通过 Channel Adapter 把报告发回你的聊天窗口。它会自动处理 Markdown → 各平台格式的转换和长消息分块。
OpenClaw 特有的优势
跨会话记忆:由于 OpenClaw 有 Memory 系统(MEMORY.md + 语义搜索),如果你之前分析过同一个项目的某些方面,AI 可以从记忆中召回之前的分析结果,做增量补充。
定时分析:OpenClaw 支持 cron 任务,你可以设置定期分析:
每周一早上 9 点,分析 openclaw 项目的最新提交,和上次分析对比,
告诉我架构上有什么变化OpenClaw 会在指定时间触发分析,并把结果发到你的聊天通道。
实战案例:OpenClaw 架构分析报告(摘要)
用这个 Skill 分析 OpenClaw 项目本身,产出了一份覆盖 14 个核心子系统的报告。下面是关键发现:
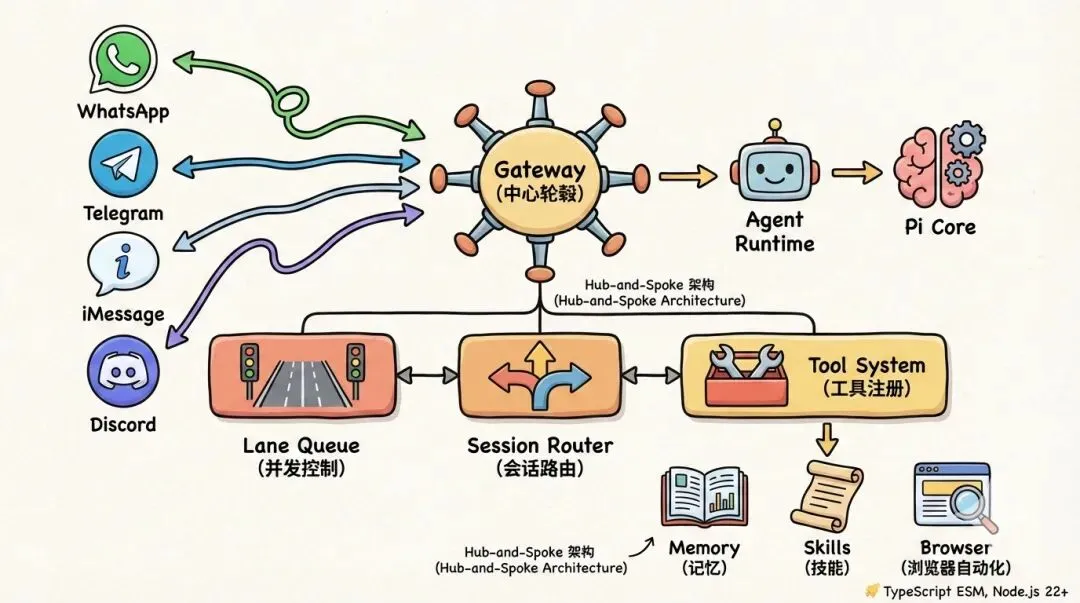
整体架构
OpenClaw 采用Hub-and-Spoke(轮毂-辐条)架构。Gateway 是中心轮毂,所有 Channel Adapter 是辐条。TypeScript ESM 项目,Node.js 22+。
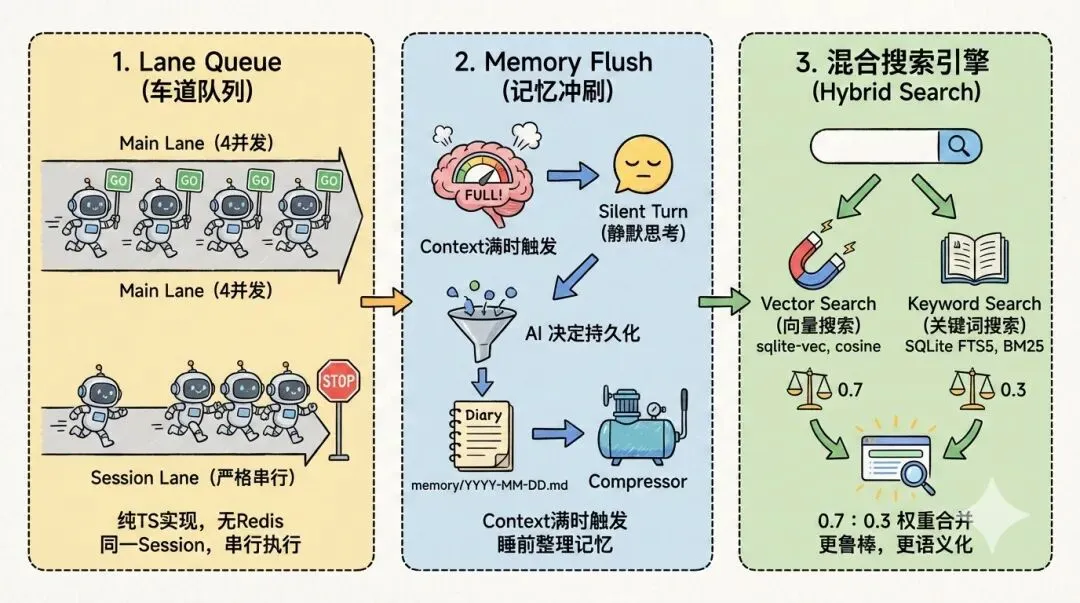
三个最值得关注的设计
Lane Queue(车道队列):纯 TypeScript + Promise 实现的并发控制,没有 Redis,没有消息队列中间件。通过 per-session lane 保证”同一 session 同一时间只有一个 agent run”。main lane 允许 4 个并发,session lane 严格串行,这是一个极具学习价值的并发设计。
Memory Flush(记忆冲刷):context window 快满时,不是直接截断,而是先触发一个对用户不可见的 silent turn,让 AI 自己决定哪些信息值得持久化,写入memory/YYYY-MM-DD.md后再压缩。灵感来自”睡前整理当天记忆”。
混合搜索引擎:记忆检索同时跑 Vector Search(sqlite-vec,cosine 距离)和 Keyword Search(SQLite FTS5,BM25),按 0.7:0.3 权重合并。比纯向量搜索更鲁棒,比纯关键词搜索更语义化。
完整报告超过 8000 字,涵盖 Gateway、Session Router、Lane Queue、Agent Runtime、系统提示词组装、Model Failover、Compaction、Tool 系统、Memory 系统、Skills 系统、Channel Adapters、DM Policy、Sandbox、Browser 自动化等 14 个子系统。
Skill 使用建议
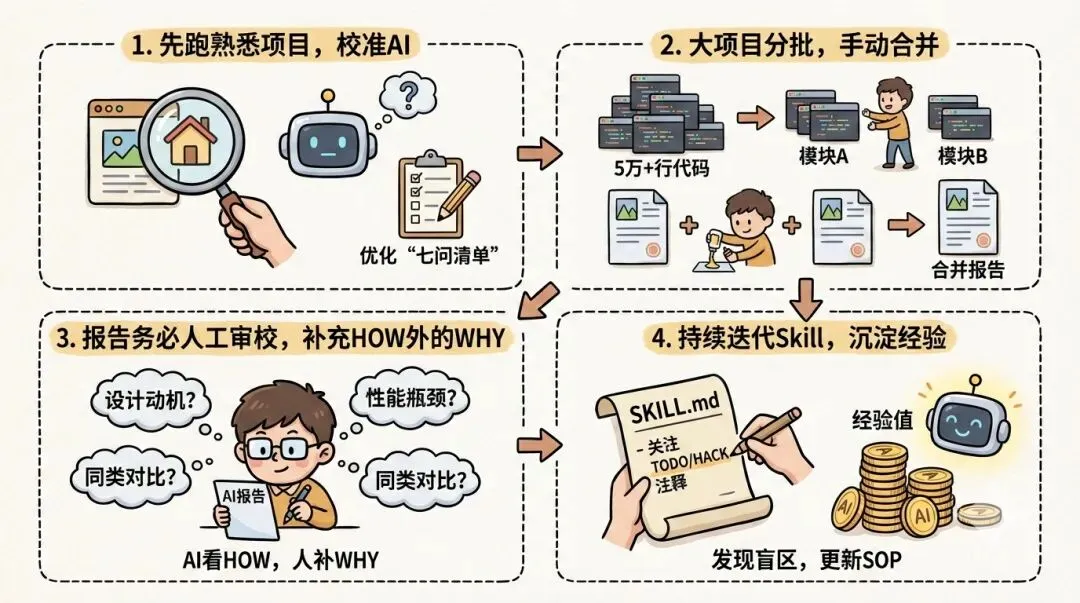
1、先跑一遍熟悉的项目
拿到 Skill 后,先对一个你熟悉的项目跑一遍,看看 AI 的分析和你的理解是否一致。如果某些方面分析不到位,在 SKILL.md 的”七问清单”中增加更具体的引导问题。
2、大项目分批分析
超过 5 万行代码的项目,建议分模块进行:
第一轮:分析 openclaw 的 Gateway、Session Router、Lane Queue
第二轮:分析 Agent Runtime 和 Model Failover
第三轮:分析 Memory 系统和 Skills 系统
第四轮:分析 Channel Adapters 和安全体系
最后手动合并成完整报告。
3、报告一定要人工审校
AI 读源码很准确,但三个方面需要你补充:
设计动机:AI 能看到 HOW,但 WHY 需要结合项目历史和作者意图。
性能特征:静态分析看不出运行时瓶颈。
同类对比:AI 的对比视野可能不够全面。
4、持续迭代 Skill
随着分析更多项目,你会发现通用的分析盲区。把这些补充到 SKILL.md 中。比如我后来加了”关注 TODO/FIXME/HACK 注释”。这些往往是理解技术债务的最佳线索。
让 AI 替你读源码、输出架构分析报告,核心不是 AI 有多聪明,而是你给它的方法论有多清晰。
一个好的 Skill 做三件事:
1. 划定范围:告诉 AI 该看什么、不该看什么。
2. 规定路径:先做什么、再做什么,每步产出什么。
3. 定义标准:报告长什么样、什么质量算合格。
这三件事做好了,10 分钟就能得到一份过去需要几天才能写出来的架构分析。当然,最终的审校和判断还是你的事,但这才是你作为架构师最该花时间的地方。
本文所有源码可直接复制使用。🛠️
延伸阅读:
Anthropic首个Skills构建指南:将专业知识和操作规范固化为自动化执行引擎
一文读懂 Claude Skills 如何重塑 AI 智能体架构
软件构建软件的未来:为什么 OpenClaw 背后的 Pi 值得你关注?
#AI编程 #架构分析 #开源项目 #源码阅读 #ClaudeCode #Claude #OpenClaw #Agent #Skill #技能 #Skill开发
