 夜雨聆风
夜雨聆风





RAG 落地最大的坑,竟然藏在文档解析里?亲测 TextIn 后的真实思考
写在前面
为什么你的 RAG Demo 很完美,上线却“翻车”? 模型没错,可能是喂进去的数据碎了 。本文实测 TextIn 文档解析工具,聊聊如何解决企业级文档中 表格跨页、版面错乱等这一个RAG 落地中的难题。
背景
做过企业级 RAG(检索增强生成)或者知识库搭建的朋友,应该都经历过一个问题:在本地用Clean Data跑Demo时,LLM回答得准确率非常高,不过一旦接入企业真实的存量文档,比如扫描歪斜的合同、跨页的财务报表、复杂的招投标文件的时候,系统的回答准确率就直线下降。
最近在调研企业知识库项目时,发现开源 OCR 方案虽然很方便,但会有一些局限性,于是花时间深度测评了一款名为 TextIn 的智能文档解析工具。如果你的团队正卡在 非结构化文档转结构化数据 的瓶颈上,这篇实测记录或许能给你一些思路。
开源探索
作为开发者,我们习惯选择热门的开源项目,比如 PaddleOCR, Tesseract, 或最近比较火的 DeepSeek-OCR2。在项目初期或个人开发阶段,它们是神器。但在企业级生产环境中,会遇到了三个难以逾越的隐形高墙:
-
复杂版面的崩溃: 开源模型对纯文本处理尚可,但一旦遇到多栏排版或嵌套表格,解析出的文本顺序往往是错乱的。 RAG 检索时,上下文一乱,大模型就开始胡说八道。 -
长文档的噩梦: 企业文档动辄几十页,跨页的表格怎么拼?页眉页脚怎么去?这些都需要大量的规则代码去 打补丁,维护成本极高。 -
性能与运维: 随着并发量上来,自建 GPU 推理服务的成本和稳定性压力,往往超过了购买商业服务的费用。
这也是我转向关注 TextIn 的原因。它的定位非常清晰:将复杂文档转变为结构化数据。
TextIn 测评
在 RAG 系统中,表格(Table) 是信息的重灾区,也是高价值密度的金矿。我选了几个比较典型真实且复杂的样本进行测试,TextIn 的表现确实让我有些惊讶。
跨页长表格的自动缝合
以往的 OCR 会把一个跨页表格识别成两个独立的表,导致中间的数据断层。但是 TextIn 它不仅仅是识别文字,而是理解了文档结构。对于跨页的长表,能够智能识别并自动拼接。
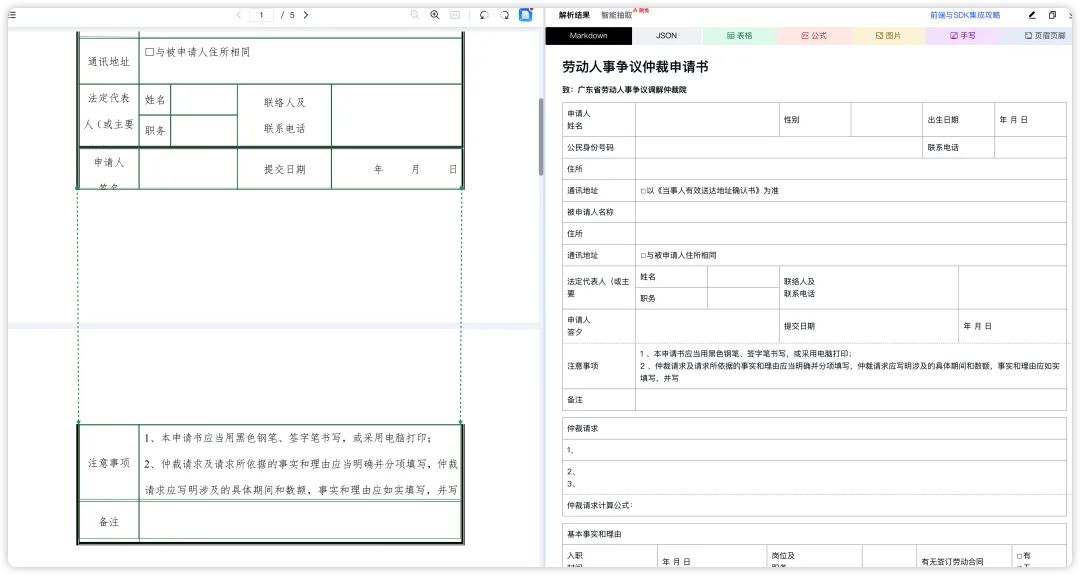
解析出来的结果是表格是逻辑连贯的。
无线表与复杂嵌套
很多技术规格书或老旧报表,表格是没有边框的(无线表),或者单元格里套着单元格(嵌套/合并)。
实测结果: TextIn 的无线表识别准确率极高。对于合并单元格,它能精准地在输出的结构化数据(如 HTML 或 Markdown)中通过 rowspan 和 colspan 完美还原结构。这对于保持知识的语义完整性至关重要。
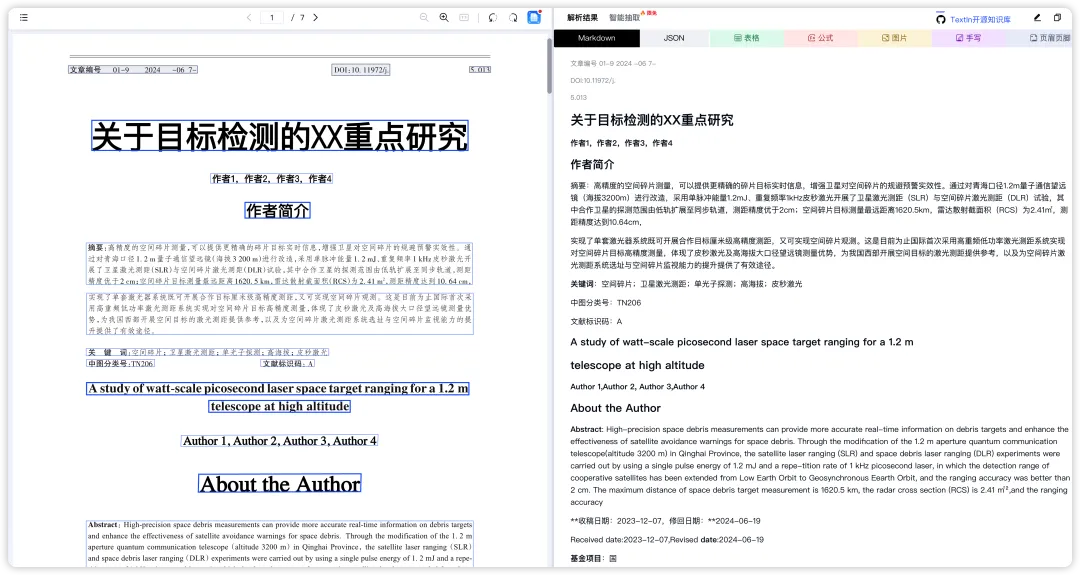
那些容易被忽视的“生产级”细节
除了表格,真实业务场景中还有很多“脏数据”。
-
文档矫正: 很多归档材料是人工扫描的,甚至是手机拍的,歪歪扭扭。TextIn 在解析前自带文档矫正,对于扭曲、透视变形的文档,先修图再识字,从源头保证了准确率。
-
手写体识别: 在审批流、工单处理场景,手写签名和批注很常见。实测下来,即使是比较潦草的连笔字,识别效果也相当能打。
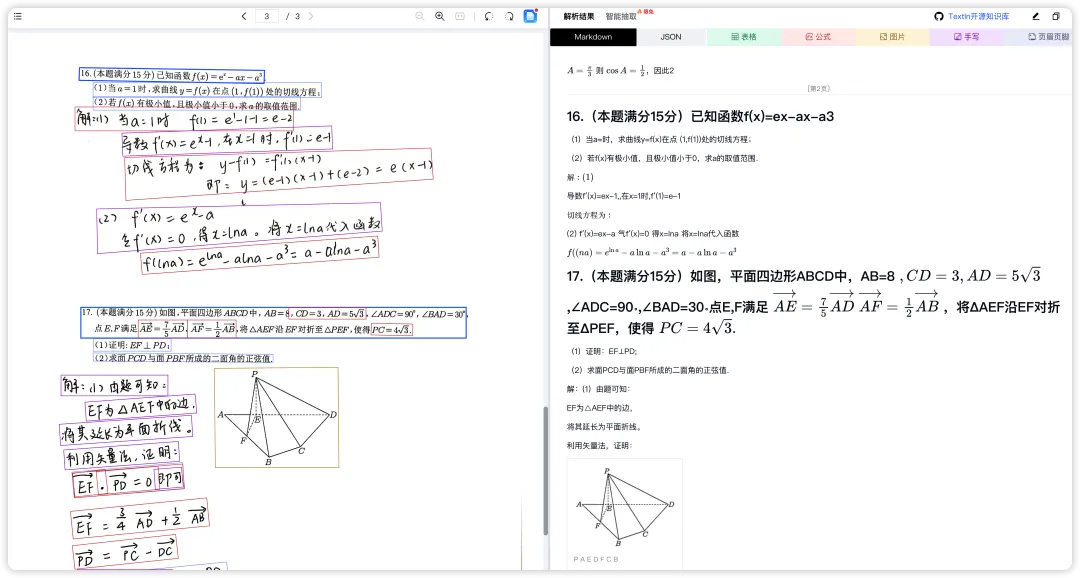
如何使用 TextIn?
工具再好,也要看怎么用。在 RAG 架构中,我建议将 TextIn 放在 ETL(提取、转换、加载) 的最前端。
最佳实践流程:
-
输入: 各种格式的源文件(PDF, JPG, Docx)。 -
TextIn 解析: 调用 API,开启 表格还原和文档树分析。 -
输出格式选择: 强烈建议选择 Markdown 格式。 (因为当前主流的 LLM 对 Markdown 的理解能力最强。TextIn 导出的 Markdown 能保留标题层级和表格结构。) -
分块(Chunking): 基于 TextIn 解析出的段落和标题层级进行切分,而不是简单的按字符数切分。这样可以保证每个 Chunk 的语义是完整的。
方法一:web平台
TextIn 提供了一个在线的Web平台,可以通过浏览器直接使用,无需编写任何代码即可快速试用API并感受效果。产品地址链接:https://cc.co/16YSbq
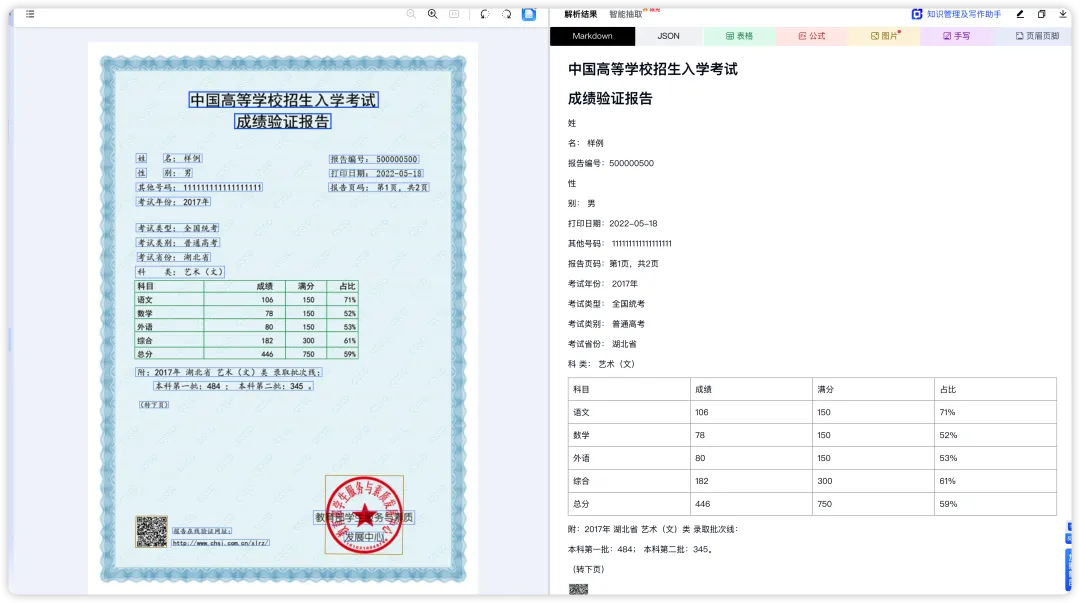
我们可以点击预存的示例文档,也可以自行上传文档(如发票、表格或报告等)在右侧快速查看解析结果并与原文档进行对照;
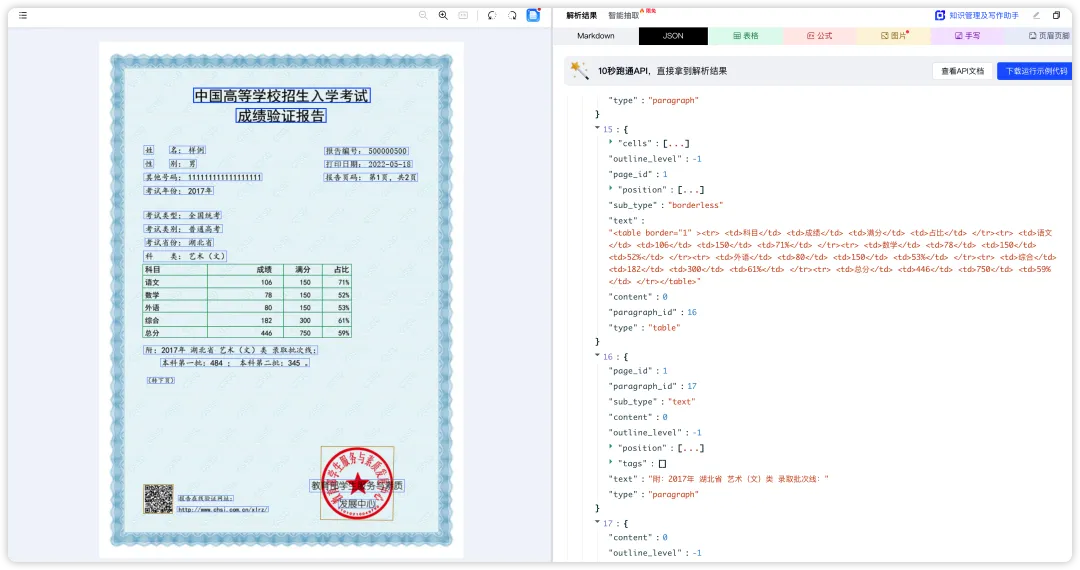
右上栏切换查看JSON格式输出以及特定元素解析结果,同时也支持对解析结果 进行编辑、复制、导出等操作 ;点击左侧 参数配置 可自定义参数。
方法二:api 接口
代码示例: 作为一个开发者,必须要看 API 易用性。这是 Python 调用 TextIn 通用文档解析的一个简单 Demo:
import jsonimport requestsclassOCRClient:def__init__(self, app_id: str, secret_code: str): self.app_id = app_id self.secret_code = secret_codedefrecognize(self, file_content: bytes, options: dict) -> str:# 构建请求参数 params = {}for key, value in options.items(): params[key] = str(value)# 设置请求头 headers = {"x-ti-app-id": self.app_id,"x-ti-secret-code": self.secret_code,# 方式一:读取本地文件"Content-Type": "application/octet-stream"# 方式二:使用URL方式# "Content-Type": "text/plain" }# 发送请求 response = requests.post(f"https://api.textin.com/ai/service/v1/pdf_to_markdown", params=params, headers=headers, data=file_content )# 检查响应状态 response.raise_for_status()return response.text解析文档并变成markdown形式。
defmain():# 创建客户端实例,需替换你的API Key client = OCRClient("你的x-ti-app-id", "你的x-ti-secret-code")# 读取本地文件with open("你的文件.pdf", "rb") as f: file_content = f.read()# 设置URL参数,可按需设置,这里已为你默认设置了一些参数 options = dict( dpi=144, get_image="objects", markdown_details=1, page_count=10, parse_mode="auto", table_flavor="html" )try: response = client.recognize(file_content, options)# 保存完整的JSON响应到result.json文件with open("result.json", "w", encoding="utf-8") as f: f.write(response)# 解析JSON响应以提取markdown内容 json_response = json.loads(response)if"result"in json_response and"markdown"in json_response["result"]: markdown_content = json_response["result"]["markdown"]with open("result.md", "w", encoding="utf-8") as f: f.write(markdown_content) print(response)except Exception as e: print(f"Error: {e}")if __name__ == "__main__": main()更多文档可以看TextIn的文档,非常详细的文档 https://docs.textin.com/xparse/parse-quickstart
最后
如果你的业务涉及大量非标、复杂的文档处理,且对准确率和SLA有高要求,TextIn 这种成熟的商业化方案,其实是帮团队剔除隐形成本。它解决的不仅仅是 OCR 识字的问题,而是 版面理解 和 数据结构化 的问题。
在 RAG 的下半场,谁能把私有数据清洗得更干净,谁的大模型就更聪明。 如果你正在被复杂的文档解析困扰,或者想提升企业知识库的召回准确率,不妨去 TextIn 官网申请一个试用 Key,跑一下你们最复杂的那个 PDF 试试。
使用地址:https://cc.co/16YSbq
