 夜雨聆风
夜雨聆风





UVM源码系统化学习规划
引言
-
第一部分:基础准备与认知构建 -
第二部分:UVM源码结构与核心类层次深度解析 -
第三部分:UVM核心机制与设计模式源码实现探秘 -
第四部分:系统化学习UVM源码的路线图与最佳实践 -
第五部分:高级应用与实战深造 -
第六部分:UVM的现状与未来展望(截至2026年初)
第一部分:基础准备与认知构建
1.1 必备的SystemVerilog知识体系
-
面向对象编程 (Object-Oriented Programming, OOP): 这是UVM的基石。必须深刻理解并能熟练运用: -
类与对象: class的定义、构造函数new()、句柄的赋值与传递。 -
继承与多态: extends关键字,父类与子类,虚方法virtual与动态绑定,这是实现工厂覆盖(override)和回调(callback)机制的基础 。 -
封装与访问控制: local,protected等关键字。 -
参数化类: parameterized class,UVM中广泛用于构建通用组件,如uvm_config_db。 -
静态与非静态成员: static变量和方法的作用。 -
抽象类与纯虚方法: virtual class和pure virtual function,UVM的顶层基类uvm_void就是一个抽象类。 -
高级数据类型与线程控制: -
动态数据结构: 动态数组、队列( $)、关联数组,这些是UVM内部管理组件、配置信息等的核心数据结构。 -
线程控制: fork...join,fork...join_any,fork...join_none是实现并行执行任务的基础,UVM的phase执行、driver与monitor的并行运行都依赖于此。 -
事件与旗语: event和semaphore用于线程间的同步与互斥。 -
随机化与约束 (Randomization and Constraints): -
rand/randc关键字,randomize()函数及其with子句。 -
constraint块的编写,包括soft约束、inside操作符、->蕴含操作符、foreach循环约束等。这是UVM中构建复杂随机激励(如uvm_sequence)的核心技术。 -
其他关键特性: -
接口 (Interface) 与虚拟接口 (Virtual Interface): 这是连接静态的验证平台和动态的类对象的桥梁,是 uvm_config_db传递DUT接口句柄的关键。 -
断言 (Assertions): SystemVerilog Assertions (SVA) 用于协议检查和功能断言。 -
覆盖率 (Coverage): 功能覆盖率( covergroup,coverpoint,cross)是衡量验证完备性的重要指标。 -
DPI (Direct Programming Interface): UVM源码中部分实现(如字符串处理)可能利用DPI调用C/C++函数以提高性能。
1.2 核心验证方法学概念
-
事务级建模 (Transaction-Level Modeling, TLM): TLM将底层信号级别的交互抽象为事务(transaction)级别的通信,实现了组件间的解耦。理解TLM 1.0/2.0的端口(port)、导出(export)、实现(imp)以及通信机制(blocking/non-blocking),是理解 uvm_driver与uvm_sequencer、uvm_monitor与uvm_scoreboard之间通信的关键。 -
覆盖率驱动验证 (Coverage-Driven Verification, CDV): CDV的核心思想是以功能覆盖率作为验证收敛的标志。验证过程围绕着“制定覆盖率模型 -> 生成随机激励 -> 运行仿真收集覆盖率 -> 分析覆盖率漏洞 -> 调整约束或定向测试”这一闭环进行。UVM的随机化和sequence机制正是服务于这一目标。 -
可重用验证组件 (Reusable Verification Components): UVM的设计目标之一就是最大化验证IP(VIP)的可重用性。通过将验证环境组件化(如UVM Agent)、标准化接口(如TLM)、分离测试用例( uvm_test)与验证平台(uvm_env),实现了验证资产在不同项目、不同层级间的复用。理解这一思想,有助于明白UVM为何要设计复杂的工厂(Factory)和配置(Config DB)机制。
第二部分:UVM源码结构与核心类层次深度解析
2.1 UVM源码目录结构导览
-
src/: 这是源码的核心目录,包含了所有的SystemVerilog源代码文件(.sv和.svh)。学习UVM源码的主要工作都在这个目录下进行。 -
base/: 包含了UVM最基础的类,如uvm_object、uvm_component、uvm_transaction等的核心定义。 -
comps/: 包含标准的组件类,如uvm_driver、uvm_monitor、uvm_sequencer、uvm_agent、uvm_scoreboard等。 -
seq/: 包含了与sequence机制相关的类,如uvm_sequence、uvm_sequence_item等。 -
tlm1/,tlm2/: 分别包含了TLM 1.0和TLM 2.0的实现。 -
reg/: 包含了UVM寄存器抽象层(RAL)的完整实现。 -
dap/: 包含了数据访问策略(Data Access Policies)相关代码。 -
dpi/: 包含了DPI相关的C源代码。 -
uvm.sv: 这是一个顶层包文件,通过include指令将所有UVM源码文件组织在一起,用户在自己的环境中只需import uvm_pkg::*即可使用整个UVM库。 -
examples/: 包含大量使用UVM的示例,是学习UVM应用和调试源码的宝贵资源。 -
docs/: 包含UVM的官方文档,如HTML格式的类参考手册,是阅读源码时最重要的参考资料。
2.2 UVM核心类层次解剖
-
uvm_void (位于uvm_object_globals.svh):
-
uvm_object (位于base/uvm_object.sv):
-
核心功能:
-
工厂注册接口: 提供了与uvm_factory交互的静态函数,虽然具体实现由宏uvm_object_utils完成。
-
对象标识:提供了get_type_name()、get_inst_id()等函数。
-
数据操作框架: 定义了一系列do_开头的虚方法(do_copy, do_compare, do_print, do_pack, do_unpack),并提供了对应的非虚方法(copy, compare, print等)作为用户接口。这种设计被称为**模板方法模式**,用户通过实现`do_`方法来定制具体行为,而框架性的流程控制则在非虚方法中完成。
-
重要性:所有需要在验证平台中流动的数据(如transaction、sequence_item、configuration object)都必须直接或间接继承自uvm_object。
-
uvm_report_object (位于base/uvm_report_object.sv):
-
uvm_transaction (位于base/uvm_transaction.sv):
-
uvm_sequence_item (位于seq/uvm_sequence_item.svh):
-
uvm_component (位于base/uvm_component.sv):
-
核心功能:
-
层次结构: 通过parent句柄和children队列构建了UVM验证平台的树形结构(uvm_test_top)。get_full_name()可以返回其在层次结构中的唯一路径。
-
Phase机制:内置了对UVM Phase的感知和执行能力,是Phase机制的实际载体。
-
配置接口:提供了uvm_config_db的便捷访问接口。
-
TLM端口:允许组件之间通过TLM端口进行通信。
-
重要性: 验证环境中的所有结构化组件,如uvm_test、uvm_env、uvm_agent、uvm_driver、uvm_monitor、uvm_scoreboard、uvm_sequencer,都必须继承自uvm_component。
-
uvm_sequence_base (位于seq/uvm_sequence_base.svh):
-
核心功能: 提供了执行uvm_sequence_item的body任务框架,以及与uvm_sequencer交互的方法(start_item, finish_item)。
-
uvm_sequence #(REQ, RSP) (位于seq/uvm_sequence.svh):
第三部分:UVM核心机制与设计模式源码实现探秘
3.1 工厂机制 (Factory Mechanism): 灵活性的基石
-
注册 (Registration):
-
实现:通过uvm_component_utils(…)和uvm_object_utils(…)宏实现。
-
源码探秘:这两个宏会展开成一系列代码。关键部分是:
-
类型包装类(Type Wrapper):生成一个静态的、唯一的类型包装类的实例(例如 my_driver::type_id)。这个实例是该类型在工厂中的代理。 -
静态构造函数:在类型包装类中,定义一个静态的create()方法,该方法内部调用被注册类的构造函数new()来创建实例。 -
工厂注册调用:在一个静态初始化块中,调用uvm_factory::get().register(this),将这个类型包装类实例注册到全局唯一的uvm_factory单例中。uvm_factory内部使用关联数组来存储类型名和其对应的类型包装器。
-
学习方法:使用编译器的预处理命令(如vcs -P …)展开一个使用了_utils宏的类,可以直接看到其源码实现。
-
创建 (Creation):
-
实现:使用type_id::create(name, parent)来创建对象,而非直接调用new()。
-
源码探秘:执行type_id::create()最终会转化为调用uvm_factory::create_object_by_type()或create_component_by_type()。工厂的create方法会执行以下步骤:
-
查找覆盖:首先检查是否存在针对此类型或实例路径的覆盖规则(override)。 -
确定最终类型:如果有覆盖,则使用被覆盖的类型;否则,使用请求的原始类型。 -
创建实例:通过查找到的最终类型的类型包装器,调用其create()静态方法,该方法内部调用new(),最终完成对象的实例化。
-
覆盖 (Override):
-
实现:通过factory.set_type_override_by_type(), factory.set_type_override_by_name(), factory.set_inst_override_by_type(), factory.set_inst_override_by_name()等方法设置覆盖规则。
-
源码探秘:uvm_factory内部维护着多个关联数组,用于存储不同类型的覆盖规则。例如,set_type_override_by_type(original_type, override_type)会将original_type作为键,override_type作为值,存入一个类型覆盖表中。set_inst_override_by_name(“uvm_test_top.env.agent.driver”, override_type)则会将实例路径字符串作为键,override_type作为值,存入一个实例覆盖表中。在create对象时,工厂会按照“实例覆盖优先于类型覆盖”的原则进行查找。
3.2 Phase机制:验证平台的生命周期管理
-
Phase的定义与分类:
-
源码探秘:UVM定义了一个uvm_phase基类,所有具体的phase(如build_phase, connect_phase, run_phase等)都是其实例。这些实例在UVM库初始化时被创建并组织成一个有向无环图(DAG),定义了它们的执行顺序和并行关系。uvm_common_phases.svh是定义标准phase的主要文件。
-
分类:主要分为两类:
-
Function Phases: 如build_phase, connect_phase等,自顶向下(top-down)或自底向上(bottom-up)执行,消耗仿真时间为0。 -
Task Phases: 如run_phase及其子phase(pre_reset, reset, configure等),是并行的,消耗仿真时间。
-
Phase的调度与执行流程:
-
源码探秘:uvm_root作为UVM环境的顶层,负责启动和管理整个phase执行流程。uvm_phase类中包含了exec_func和exec_task两个核心方法,它们会遍历UVM组件树,并调用每个组件对应的phase方法(如c.build_phase(this))。uvm_component中的m_run_phases任务是phase机制的核心调度器,它通过fork…join来启动所有注册的phase。
-
Objection机制:同步与结束控制的艺术
-
实现:在task phase中,通过phase.raise_objection(this)和phase.drop_objection(this)来控制phase的结束。
-
源码探秘:每个uvm_phase对象内部都维护着一个objection计数器。raise_objection会增加计数,drop_objection会减少计数。Phase调度器会持续监控这个计数器,只有当总计数器归零时,该phase才会被允许结束,并进入下一个phase。uvm_objection类是具体实现objection机制的类,它提供了详细的追溯和调试信息。
3.3 配置数据库 (Config DB): 全局信息的传递枢纽
-
uvm_config_db的 set 和 get 实现原理:
-
源码探秘:uvm_config_db`本质上是对一个名为uvm_resource_db的全局资源数据库的封装。当你调用uvm_config_db::set(this, inst_name, field_name, value)时,它会将这些信息(上下文路径、字段名、值)打包成一个uvm_resource对象,并存入全局的资源池中。
-
调用uvm_config_db::get(this, “”, field_name, value)时,它会根据当前组件的完整路径(this.get_full_name())和字段名,在资源池中进行查找。
-
资源池与匹配算法:
-
源码探秘:uvm_resource_db内部使用关联数组或队列来存储资源。查找过程支持通配符(*),并遵循“最具体匹配”原则。例如,set(this, “uvm_test_top.env.*”, “my_field”, 1)设置的资源,可以被uvm_test_top.env.agent1和uvm_test_top.env.agent2同时get到。如果同时存在一个更精确的set(this, “uvm_test_top.env.agent1”, “my_field”, 2),那么agent1在get时会优先匹配到值为2的资源。
3.4 Sequence机制:激励生成的核心
-
uvm_sequence 与 uvm_sequencer 的交互:
-
源码探秘:这种交互是基于TLM实现的。uvm_sequencer内部包含一个seq_item_export,而uvm_driver包含一个seq_item_port,它们在connect_phase中连接。当一个sequence在uvm_sequencer上执行时,它通过调用start_item(item)向sequencer请求仲裁。
-
uvm_sequencer在获得总线访问权后,会通过其m_req_fifo将item发送出去。driver通过seq_item_port.get_next_item(req)从sequencer获取item。
-
启动Sequence的方式及其源码实现:
-
default_sequence:uvm_sequencer的run_phase中会检查default_sequence是否被设置,如果设置了,则会自动start它。
-
seq.start(sequencer):这是最常用的手动启动方式。start()任务是核心,它会设置sequence与sequencer的父子关系,然后调用sequence的body()任务。在body()任务返回后,start()会完成清理工作。
第四部分:系统化学习UVM源码的路线图与最佳实践
4.1 四阶段学习路线图 (A Four-Stage Learning Roadmap)
-
第一阶段:对象模型与基础 (Stage 1: Object Model & Basics)
-
学习目标:理解UVM世界的基本构成单元,掌握UVM对象的通用属性和工厂机制的原理。
-
核心源码文件:
-
uvm_object.svh / uvm_object.sv: 理解数据操作的模板方法模式(copy/do_copy等)。 -
uvm_factory.svh: 阅读register, create_*, set_*_override等核心函数的实现。 -
uvm_component.svh: 理解组件的层次结构(parent, children)和构造过程。
-
实践任务:手动展开`uvm_object_utils宏,理解其作用。编写一个简单的程序,不使用uvm_test,直接调用factory的API来创建和覆盖对象。
-
第二阶段:配置与报告 (Stage 2: Configuration & Reporting)
-
学习目标:掌握UVM中信息传递的两种主要方式:层次化配置和全局报告。
-
核心源码文件:
-
uvm_config_db.svh: 分析其set/get静态方法如何调用uvm_resource_db。 -
uvm_resource_db.svh: 探究资源池的实现和匹配算法。 -
uvm_report_object.svh: 理解 `uvm_info/`uvm_error等宏如何最终调用`uvm_report_handler`。 -
uvm_report_handler.svh: 分析报告处理的流程,如ID、severity、verbosity的过滤。
-
实践任务:编写一个实验,测试uvm_config_db的通配符和优先级规则。尝试实现一个uvm_report_catcher来捕获并修改特定的报告消息。
-
第三阶段:生命周期与同步 (Stage 3: Lifecycle & Synchronization)
-
学习目标:理解UVM验证平台的完整执行流程和同步机制。
-
核心源码文件:
-
uvm_phase.svh: 理解phase的domain、schedule和节点关系。 -
uvm_common_phases.svh: 查看标准phase是如何被定义和组织的。 -
uvm_objection.svh: 分析objection如何被raise/drop,以及计数器的工作原理。 -
uvm_root.sv: 阅读run_test任务,这是UVM仿真的入口和总控制器。
-
实践任务:尝试自定义一个phase,并将其插入到run_phase的某个子phase之间。设计一个场景,其中多个组件通过objection来协调一个复杂任务的结束。
-
第四阶段:高级特性与激励生成 (Stage 4: Advanced Features & Stimulus Generation)
-
学习目标:掌握UVM最核心的动态行为机制——Sequence,以及其他高级扩展机制。
-
核心源码文件:
-
uvm_sequencer_base.svh: 分析sequencer的仲裁和与driver的TLM通信。 -
uvm_sequence_base.svh: 理解start/body任务,以及start_item/finish_item的流程。 -
uvm_callback.svh: 学习回调池的实现和回调的注册、触发机制。 -
uvm_reg_block.svh (及其他reg目录文件): 初步了解寄存器模型的实现方式,如read/write任务如何最终转换为总线sequence。
-
实践任务:画出seq.start(sqr)后,sequence、sequencer、driver之间完整的交互时序图和函数调用链。实现一个自定义的回调类,在不修改driver的情况下,注入一些额外的操作。
4.2 学习资源与工具箱
-
权威文档与书籍:
-
UVM类参考手册 (UVM Class Reference):这是最权威、最准确的参考,应与源码并排查看。 -
UVM Cookbook: 由Verification Academy提供,包含了大量最佳实践和应用范例,有助于理解源码的设计意图。 -
《UVM实战》 (作者:张强): 这本中文书籍深受国内工程师喜爱,其源码解析部分非常详尽,是极佳的辅助读物。其配套源码也值得研究。
-
在线平台与社区:
-
Verification Academy: Mentor, a Siemens Business (现为Siemens EDA) 维护的网站,是UVM的“娘家”,有最全面的教程和论坛。 -
Accellera官网: UVM标准和参考实现的发布地。 -
Edaplayground: 一个在线的SystemVerilog/UVM编译和仿真环境,非常适合快速验证对源码的理解和进行小型实验。 -
GitHub: 搜索UVM或UVM verification,可以找到大量的开源验证平台,是学习真实项目应用和高级技巧的宝库。
-
高效源码阅读工具:
-
支持代码跳转的编辑器:VSCode配合SystemVerilog/UVM插件、Vim/gVim配合ctags,或者商业IDE(如DVT Eclipse),可以极大地提高在庞大源码中导航和追踪函数定义的效率。
4.3 学习方法论与最佳实践
-
问题驱动式学习法: 不要为了读源码而读源码。带着问题去读,效率最高。例如,“uvm_config_db的通配符是如何实现的?”然后带着这个问题去追踪代码,目标明确,收获也更大。
-
示例驱动与日志分析法: 找一个简单的UVM示例,然后将UVM库的报告等级调到最高(uvm_verbosity=UVM_FULL或UVM_DEBUG),运行仿真。通过观察详细的日志输出,可以清晰地看到UVM内部的执行流程、函数调用和状态变化,这比静态阅读代码要直观得多。
-
动手实践与项目结合: 学习源码的最终目的是为了更好地应用。将在源码中学到的知识应用到实际项目中,例如,尝试优化项目中config_db的滥用,或者为现有driver添加回调扩展点。实践是检验和巩固知识的唯一标准 。 -
把飞哥的UVM源代码分析全部看完,😄
第五部分:高级应用与实战深造
5.1 通过开源项目掌握高级技巧
-
关注点:
-
复杂Sequence组织:学习他们如何组织虚拟序列(virtual sequence)、分层序列(layered sequence)来管理复杂的测试场景。 -
自定义扩展:观察他们是否对UVM进行了扩展,例如自定义phase 、自定义sequencer仲裁算法,或者开发了通用的基础组件库。 -
脚本自动化:学习他们如何使用脚本(Python, Perl, Make)来自动化测试用例的生成、编译和回归测试。
5.2 高级调试与性能分析
-
高级调试技巧:
-
源码级断点调试:利用Verdi、Simvision等调试工具,在UVM库的源码中设置断点,单步跟踪执行流程,观察内部变量的变化。这是定位疑难杂症的终极手段。 -
利用UVM内置调试开关:UVM提供了丰富的调试开关,如+UVM_OBJECTION_TRACE可以追踪objection的升降,+UVM_CONFIG_DB_TRACE可以追踪config_db的存取。 -
集成波形分析器:将UVM内部的关键变量(如sequencer的仲裁队列、scoreboard的匹配FIFO)通过编译选项导出到波形文件(FSDB, VPD)中进行观察,可以直观地分析数据流和时序关系。
-
性能瓶颈定位与优化实战:
-
识别性能瓶颈:仿真缓慢通常由几个原因造成:
-
过度随机化:过于复杂的约束或大量的随机变量会消耗大量求解时间。 -
低效的数据结构:在scoreboard等组件中使用了低效的算法(如嵌套循环查找)。 -
频繁的uvm_config_db调用:在循环中频繁set/get会带来开销。 -
过多的报告信息:UVM_INFO级别的消息在循环中大量打印会严重拖慢仿真。
-
优化案例:
-
案例一:优化随机约束。使用soft约束和双向约束(solve … before …)指导求解器。将可以在post_randomize()中计算的字段移出约束。 -
案例二:优化config_db。将只需在build_phase设置一次的配置项(如virtual interface)严格限制在该phase,避免在run_phase中滥用。对于需要频繁更新的配置,考虑使用其他机制(如TLM分析端口)。 -
案例三:手动实现数据操作方法。uvm_*_utils宏提供的copy, compare等方法是通用的,但性能非最优。对于性能关键的transaction,可以手动实现do_copy, do_compare等方法,用简单的位拷贝或逐字段赋值代替基于反射的通用实现,可以显著提升性能。
5.3 制定个人学习与实践计划
-
设定学习里程碑:参照第四部分的四阶段路线图,为每个阶段设定明确的时间节点和完成标准。例如:
-
第一月:完成第一阶段学习,能够独立解释工厂机制的完整流程。 -
第二月:完成第二阶段学习,能够利用uvm_report_catcher定制报告系统。 -
第三、四月:完成第三、四阶段学习,能够画出UVM phase调度和sequence执行的详细流程图。
-
学习计划模板示例: 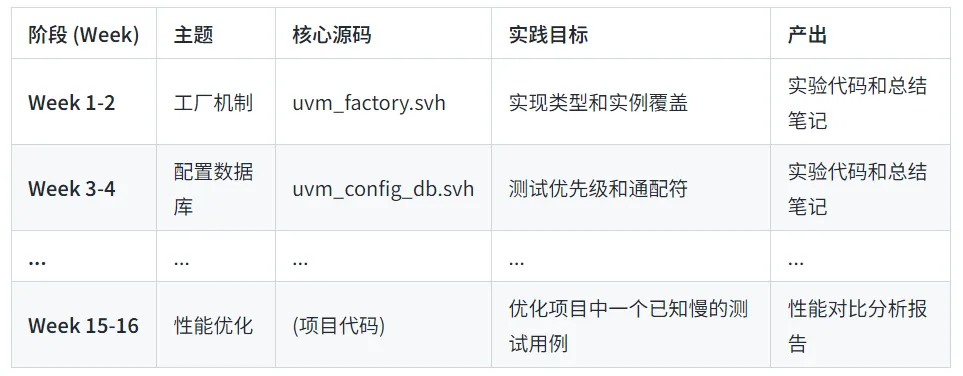
第六部分:UVM的现状与未来展望(截至2026年初)
6.1 当前主流标准:IEEE 1800.2-2020
-
与UVM 1.2的关键差异:
-
向后不兼容的变更:标准化移除了一些UVM 1.2中已标记为deprecated(不推荐使用)的API和变量,例如uvm_sequence_base::starting_phase被移除,推荐使用set/get_starting_phase()方法。 -
API修正与增强:对一些API的行为进行了更精确的定义,修复了UVM 1.2中的一些已知缺陷。 -
源码结构微调:为了符合IEEE标准,源码的目录结构和部分文件名可能有细微调整。 -
迁移至IEEE标准的建议:对于仍在使用旧版UVM 1.1d或1.2的项目,迁移到IEEE 1800.2-2020是大势所趋。迁移时需注意编译器关于deprecated API的警告,并逐步替换为新的API。Accellera提供了迁移指南和社区支持来帮助用户过渡。
6.2 2026年及未来的发展趋势
-
与系统级验证(PSS)的融合:可移植激励标准(Portable Stimulus Standard, PSS)在比UVM更高的抽象层次上描述测试意图。未来的趋势是将PSS生成的抽象测试场景,自动合成为底层的UVM sequence来执行。PSS+UVM的混合方法学将成为复杂SoC验证的主流。 -
在硬件加速平台上的原生支持:随着设计规模的急剧增大,纯软件仿真已无法满足性能需求。UVM环境如何更友好地运行在FPGA原型验证(Prototyping)和硬件仿真加速(Emulation)平台上,是一个持续的研究方向。这可能涉及UVM库的特定版本或新的“UVM-HSA”(Hardware-Software Acceleration)方法学。 -
AI/ML在UVM验证中的应用:人工智能和机器学习技术正被探索用于辅助验证。例如:
-
智能测试激励生成:利用AI分析覆盖率漏洞和设计状态,自动生成能最快填补覆盖率空洞的sequence或约束。 -
智能Debug:AI可以分析大量的回归失败日志,自动定位错误的根本原因,缩短调试时间。 -
AI辅助的验证环境生成:未来可能通过更高阶的语言描述验证需求,由AI自动生成UVM验证环境的基础框架代码。
