 夜雨聆风
夜雨聆风





Claude 金融插件开源,可以把投行、卖方、私募、财富管理串成工作流

去年我上了清华校友金融班。课间聊天时,很多同学都在问同一件事,AI 到底能不能帮我们做研报。
有人想要的是 Research to Report,把业绩数据拉下来,分析完就能写成可发布的研报。
有人更关心 Spreadsheet Analysis,能不能把可比公司分析、DCF、LBO 这些事情串起来,少在数据、表格、模型之间反复搬运。
还有同学更现实,三表模型能不能从材料里自动填出来,再顺手把情景和压力测试跑一遍。
最后总会绕回一个问题,这些结论怎么变成可交付的东西,能不能沿着同一条链路跑完。
坦白说,那段时间我在这方面没有做太多研究。那时大模型能写,但我也见过太多写完了,却交不出去的尴尬。
直到三天前,我在 GitHub 上刷到 Anthropic 刚开源的一个项目,名字很直白,Claude for Financial Services Plugins。
它要做的事情也很直白,把金融工作里那些分散的动作连成一条端到端链路,并且把经验写进文件里,交给插件去执行和复用。
项目地址:https://github.com/anthropics/financial-services-plugins
它面向 Claude for Enterprise 的两种使用形态,Cowork 和 Claude Code。
PART 01|这不是单点工具 它想把研究到交付串成一条线
很多人第一次听到“插件”,容易把它理解成某个小按钮或小功能。点一下,帮你查个数,写段话。挺好,但也止步于此。
这个仓库的表达方式不一样。它不先罗列功能点,而是直接给出一组工作流。
例如:
从研究到报告(Research to Report),从表格到建模(Spreadsheet Analysis),从财务建模到三表(Financial Modeling),从材料到路演(Deal Materials),再到投后到汇报(Portfolio to Presentation)。
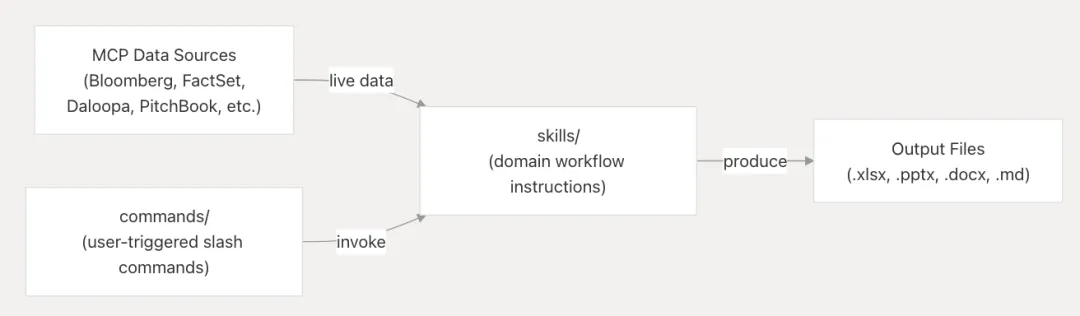
DeepWiki 里有一张我很喜欢的模型图。
它把一次典型会话的链路写得很清楚,由 commands 触发具体动作,数据从 MCP 数据源进来,进入 skills 里的工作流,再最后产出可交付的成果。
关于这几条路径,有张表格,总结得很好。
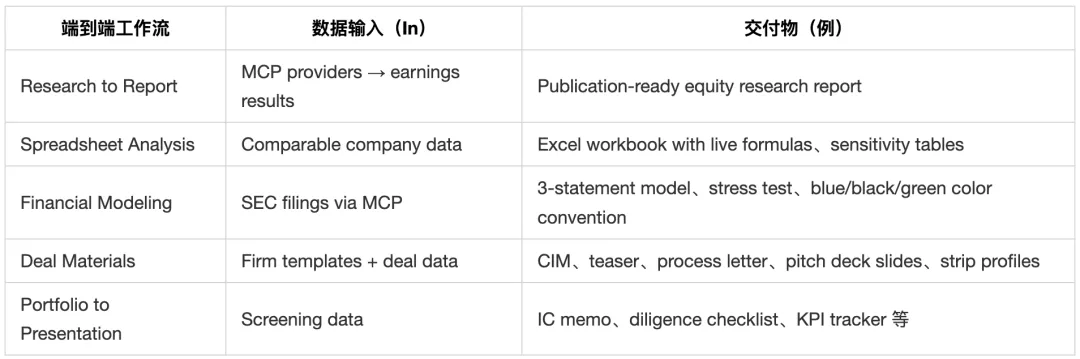
表格里的“交付物”只是常见落点,重点还是一条工作流从数据到交付的贯通。
你看,它更关心的是让你少做那些无意义的搬运,把研究、分析、建模、材料生产这些动作串成一条线。
端到端的价值在这里,把链路写清楚,把手工搬运变少,把可追溯变多。
这个逻辑和我在流程管理里常说的一样,端到端更像一条信息流,关键在于从头到尾一致地流动起来。
PART 02|真正厉害的是“文件化” 把隐性经验写进技能和命令
我看这个仓库,最喜欢的点,是它没有把自己包装成一个平台,而是把能力拆成一套文件结构。
先说生态。
这个仓库定义了一个核心插件 financial-analysis,以及四个加装插件 investment-banking、equity-research、private-equity、wealth-management。
除此之外,还有外部数据提供方维护的 partner-built 插件,路径在 ./partner-built/,例如 lseg 和 sp-global。
更关键的是,所有插件都登记在同一个 marketplace 目录文件里,.claude-plugin/marketplace.json。你可以把它当成组织层面的插件清单和分发目录。
marketplace.json 里登记的插件也很直观,基本覆盖了常见角色:
-
financial-analysis 核心插件,覆盖 DCF、comps、LBO、三表建模、竞品分析与 deck QC
-
investment-banking 加装插件,覆盖 CIM、teaser、buyer list、merger model 与 deal tracking
-
equity-research 加装插件,覆盖业绩解读、initiation 与研究工作流
-
private-equity 加装插件,覆盖 deal sourcing、公司发现、CRM 与外联
-
wealth-management 加装插件,覆盖客户回顾、理财规划、组合分析与客户报告
-
lseg 数据伙伴插件,覆盖债券定价、收益率曲线、外汇、期权与宏观看板
-
sp-global 数据伙伴插件,覆盖公司一页纸、业绩预览与交易摘要
再说结构。
每个插件目录都长得差不多,四个顶层组件很稳定。
-
.claude-plugin/plugin.json 负责声明插件信息,比如名称、版本、作者、描述
-
.mcp.json 负责声明 MCP 连接,提供外部数据源入口
-
commands/ 放用户显式调用的斜杠命令,比如 /comps、/cim、/earnings
-
skills/ 放工作方法与步骤,Claude 在上下文匹配时自动引用

commands 文件里会写清楚它要调用哪个 skill,还会声明必要参数。你可以把它理解成明确的按钮,把一件复杂工作变成可重复的一次按下。
这些东西有个共同点。它们主要是 Markdown 与 JSON。
换句话说,这是一个更像知识工程和工作流工程的项目。没有编译代码,没有构建步骤,也不需要你额外维护一套基础设施。
整个项目集成了 41 个 skills、38 个 commands、11 个 MCP。
它把做金融的经验拆成两条腿。
第一条腿是 skills。你可以把它理解成 SOP,加上专业判断的边界。比如做可比公司(comps)、做 DCF、做 LBO,怎么拉数据,怎么校验,怎么配色,怎么写假设。它把这些写成可复用的工作法,让输出更一致。
第二条腿是 commands。它更像一套可按下的动作键,你在会话里直接敲 /comps、/dcf、/earnings、/ic-memo,Claude 就按这个插件定义的方式去做事。
团队管理里有一个朴素道理,隐性经验只有写成可执行的标准,才可能沉淀成组织能力。否则,永远是某个高手很会做,一旦人走了,方法也走了。
PART 03|企业落地的关键不在安装 而在定制与治理
到这里,问题来了。既然仓库都开源了,我是不是照着装一遍就行?
安装只是第一步。关键在定制与治理。
原因很简单。
金融工作最容易出风险的地方,往往不在算不算得出来,而在口径对不对。
同样是收入、同样是 EBITDA、同样是自由现金流,不同团队、不同场景的定义可能不同。你把这个差别忽略掉,输出越快,错得越快。
还有,MCP 连接集中定义在 financial-analysis 核心插件的 .mcp.json,并且会共享给加装插件。访问这些数据源通常需要订阅或 API key。这个设计挺现实,把数据入口做成可控的基础能力,再在上面叠加不同角色的工作流。
所以,我给一个更务实的落地路径。
第一步,先把数据入口跑通。你不需要一开始就追求全量连接。选 1 到 2 个最常用的数据源,让链路先闭环。闭环之后再扩展。这里的关键动作是把 .mcp.json 当成数据接入的单一入口来管理,减少各自为政。
第二步,再把口径写清楚。把你们团队最常争论的 10 个定义写进 skills 文件里。收入怎么拆,增长怎么解释,异常怎么处理,引用怎么标注。写得越清楚,后面越省事。你也可以把 marketplace 目录文件当成组织级别的开关,哪些插件允许被安装,哪些输出格式是强制的,这些都能收敛到一个地方。
第三步,最后把交付物固化。重点不是生成几个文件,而是每条工作流最后都要落到可交付的成果上。模型里哪些假设必须标注来源。研报里哪些表述必须带引用。材料出给老板之前要过哪些审校清单。把这些写成模板和规则,让输出靠标准,而不是靠记忆。
做到这三步,你会发现插件的意义变了。它不再是一个帮你写得更快的助手,更像一个把团队经验写进系统的载体。
PART 04| 写在最后
如果你想快速上手,这个项目给了两条路。
一条是 Claude Desktop 的 Cowork,把这个 GitHub 仓库作为 marketplace 添加,然后在里面选插件安装。
另一条是 Claude Code,用命令行安装,先装 financial analysis 核心插件,再按角色装投行、卖方、私募、财富管理等插件。
claude plugin marketplace add anthropics/financial-services-pluginsclaude plugin install financial-analysis@financial-services-plugins
当然,这些插件辅助金融工作流,但不提供投资建议。任何 AI 生成的分析,都应由专业人士复核后再使用。
大模型解决的,往往是写。
而组织真正稀缺的,是标准。当方法、口径、模板被写进插件,AI 才能在你们的体系里稳定地产出可交付的工作。
