 夜雨聆风
夜雨聆风





翻完 OpenClaw 源码,我发现它火得一点都不冤
三天后,GitHub 涨了 6 万 Star。到现在,10 万+ Star,一周 200 万访客。
听起来很夸张对吧?更夸张的是,很多人翻完代码后说了一句:「这不就是个胶水项目吗?」
OpenClaw 的技术确实没什么门槛。它没有自研大模型,没有革命性的算法,甚至底层的 Agent 循环都是直接用的开源框架 Paimimo。
但它就是火了。
为什么?因为产品设计做对了。技术选型和系统架构怎么搭的,这才是值得拆的东西。
今天这篇文章,我把 OpenClaw 的底层拆干净,让你看清楚它到底是怎么搭的。看完之后你会发现——这套东西,你也能搭。
先搞清楚 OpenClaw 在解决什么问题
在拆技术之前,先说清楚一件事:OpenClaw 到底在干嘛。
一句话概括:它是一个跑在你自己电脑上的、能通过聊天工具控制的、有自主性的 AI 助手。
三个关键词:
个人 不是 SaaS 服务,是你自己的。数据存在你电脑上,性格你自己调教,能力你自己装配。你可以让它像渣女一样说话,也可以让它像沉默的管家一样只做事不废话。
自主 不是你一步步教它干活的 Workflow,而是你说一句「帮我把那个文件夹整理一下」,它自己去翻文件、分类、建索引。基于 ReAct 架构,能自己思考下一步该干什么。
助手 定位是帮你完成任务,不是替代你。你不需要说太多,把需求扔给它,它自己搞定。
明确了这个,我们来看它是怎么实现的。
系统架构全景
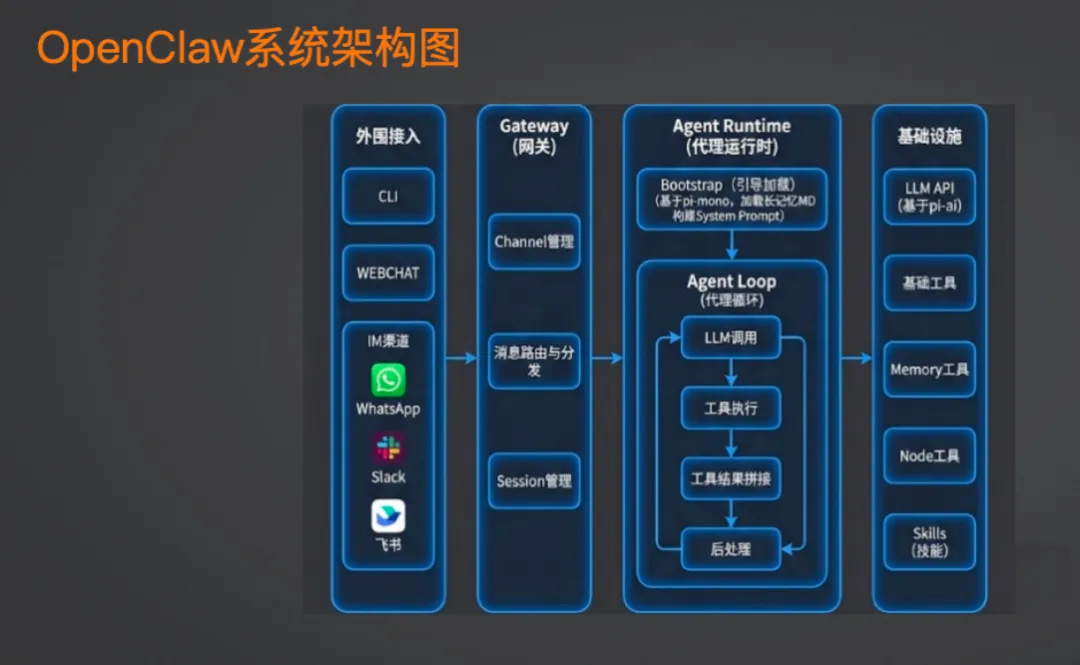
OpenClaw 的整体架构其实不复杂。
所有东西都跑在一个 Gateway 进程里,这是一个 Node.js 服务。它做的事情可以拆成这么几块:
Channel 管理是第一层。不管你从 WhatsApp 还是 QQ 发消息过来,都会对应到一个 Channel。每个用户的私聊、每个群组的对话,都是独立的 Channel。
拿到 Channel 后,消息路由会把它分发到具体的 Agent 上。每个 Agent 管着自己的多个 Session——Session 就是你跟模型的一通对话。
这层网关的作用很简单:把不同来源的消息统一起来,让 Agent 运行时不用关心消息是从哪来的。
Session 运行时才是核心。它基于 Paimimo 框架构建,一条消息进来后:
-
先构造 System Prompt(后面重点讲) -
把用户消息放进 User Prompt -
进入 ReAct 循环
ReAct 循环本质上是个死循环:
调模型 → 模型输出想法和要用的工具 → 执行工具 → 把结果塞回上下文 → 再调模型 → 循环往复,直到任务完成。
比如你说「帮我生成股票早报」,它会这样跑:
-
第 1 轮:「我需要获取股票行情」→ 调用行情 API → 拿到数据 -
第 2 轮:「行情数据有了,我需要整理成报告格式」→ 调用文件写入工具 → 生成报告 -
第 3 轮:「报告写完了,任务完成」→ 跳出循环
架构就这些。说白了不难。但 OpenClaw 真正牛的地方,在于它在这个架构上做的几个技术设计。
技术亮点一:动态 System Prompt 加载
这是 OpenClaw 最基础也最聪明的设计。
在每次调模型之前,OpenClaw 会先拼装 System Prompt。除了基础的 ReAct 指令,它还会动态加载工作区里的一组 Markdown 文件。这些文件才是你的龙虾和别人龙虾不一样的原因。
|
|
|
|
|---|---|---|
| soul.md |
|
|
| identity.md |
|
|
| user.md |
|
|
| agent.md |
|
|
| tools.md |
|
|
Peter 开源 OpenClaw 的时候,唯一没开源的就是他自己那只龙虾的 soul.md。到现在没人知道他写了什么。
但社区里已经有大量分享了——有人让龙虾说话像霸道总裁,有人让它像日本管家一样恭敬。
这些文件不是固定的。你跟龙虾聊天的过程中,它会自己决定更新这些文件。比如某天你聊到自己喜欢吃火锅,它觉得「这个偏好应该记在 user.md 里」,就自己记进去了。下次你问它「今晚吃什么」,它就会考虑到你爱吃火锅。
但这也带来一个问题:这些 MD 文件会越来越大。System Prompt 光基础部分就要 1.5 万 Token。加上 Memory、Skill 描述,用久了能飙到 3 万甚至 5 万 Token。
所以 OpenClaw 必须用强模型。那些小模型,上下文超过几万 Token 就开始犯迷糊。这也是为什么有人说本地跑 OpenClaw 纯属浪费——小模型连 ReAct 都干不好。
技术亮点二:上下文的剪裁和压缩
OpenClaw 是单 Agent 架构。不是那种多个 Agent 分工合作的设计,而是一个 Agent 从头干到尾。
单 Agent 的好处是简单。坏处是上下文会爆。
每一轮 ReAct 循环,模型的想法、工具调用的入参、工具返回的结果,全部追加到上下文里。
System Prompt 已经 5 万 Token 了,再加上工具结果——读一个文件就是整个文件内容,搜一次网就是 20 条结果——上下文很快就满了。
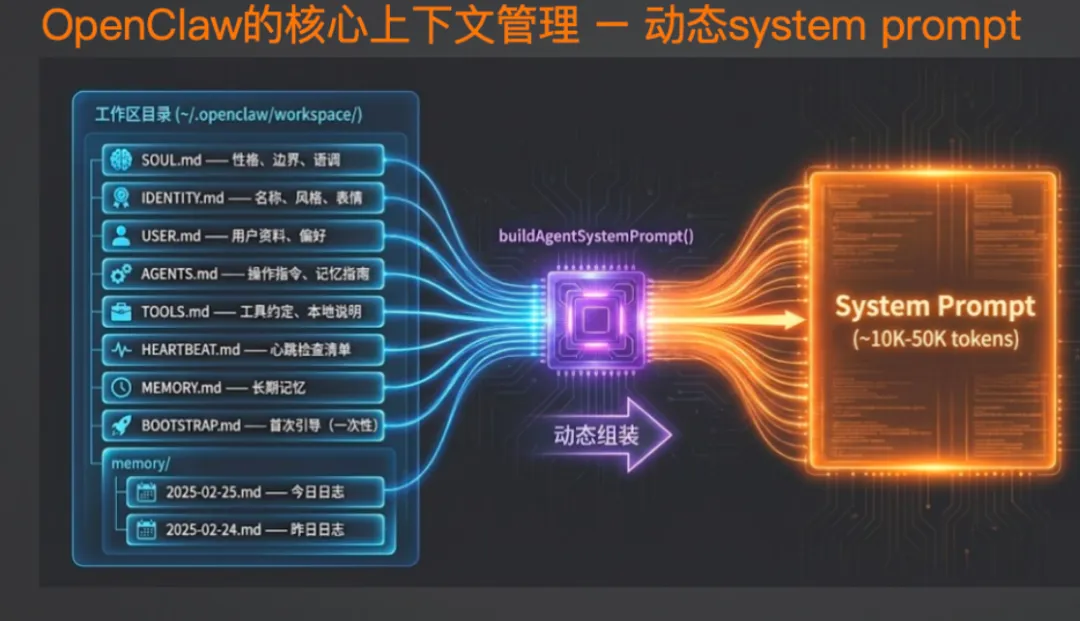
OpenClaw 的解决方案分两步:
剪裁
最占空间的是工具结果。OpenClaw 的做法很直接:自动把 N 轮前的工具结果全部隐掉,只保留模型当时的思考和工具入参。
比如 10 轮前模型读了一个文件,那个文件内容可能有 5000 Token。剪裁后,上下文里只保留「模型决定读 xxx 文件」和「模型基于文件内容得出了 xxx 结论」,原始文件内容就不占空间了。
压缩
剪裁不够用的时候,还有压缩。
整个流程是这样的:
-
框架监控上下文 Token 数,比如设定阈值 80K -
快到 80K 了,触发压缩 -
先把当前所有原始信息写进 Memory 的日志文件(完整保留,不丢数据) -
再用模型对历史上下文做一次摘要,只保留关键信息 -
压缩后的 Message List 变得很精炼,但详细信息在日志文件里,需要时用 Memory 工具去查
这套机制保证了两件事:任务不会因为上下文溢出而中断;历史信息也不会真的丢掉。
技术亮点三:双层长记忆系统
龙虾经常干一件让人觉得暖心的事——突然想起你很久以前聊过的一件小事。
这不是巧合,是系统设计。
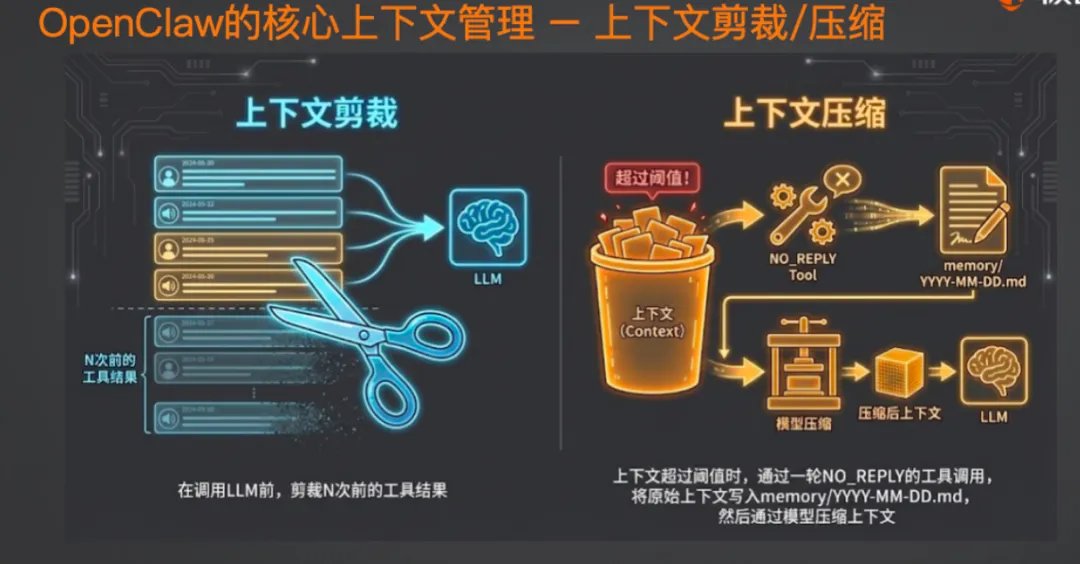
第一层:memory.md
模型在心跳触发时(后面会讲),会不定期检查聊天记录和运行日志,把最重要的记忆点写进 memory.md。比如你说过「下周三有个重要面试」,它会记下来。
下次拼 System Prompt 时,memory.md 作为长期记忆被加载进上下文,模型就知道这些信息了。
第二层:Memory Search 工具
memory.md 只记核心信息,细节在哪呢?在之前上下文压缩时写入的那些日志文件里。
OpenClaw 为这些日志做了向量索引。底层没用什么专业向量数据库,就是 SQLite 自带的轻量级向量存储。
搜索时用的是混合检索:
-
向量搜索:按语义相似度召回一批结果(权重 70%) -
关键词搜索:按精确匹配召回另一批(权重 30%)
两者加权合并、重排序,再结合时间衰减策略,返回最相关的 Top K 内容。
这套设计不算复杂,但效果确实好。龙虾能在几百轮对话的历史里精准找到你提过的事情。
后台任务:CronTab + Heartbeat 双调度
OpenClaw 最让人惊喜的体验是主动性——你没找它,它主动找你。
这背后靠的是两套调度机制。
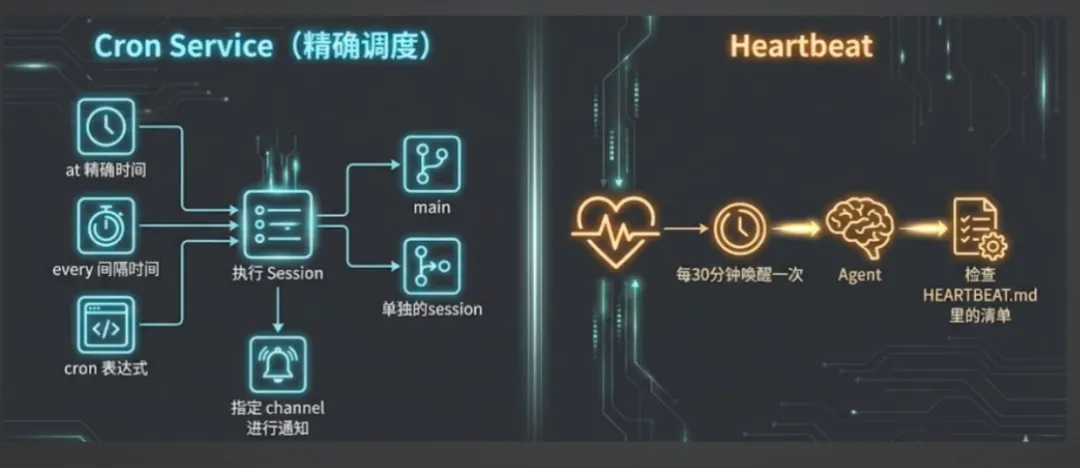
CronTab
OpenClaw 维护一个 cron.json 文件,支持三种定时任务:
-
精确时间:「今晚 8 点提醒我参加直播」 -
间隔时间:「每隔 20 分钟提醒我一次」 -
Cron 表达式:「工作日每天早上 8 点给我行情报告」
任务执行完后,结果通过指定的 Channel 推送给你。比如你在 QQ 上创建了任务,结果就发回你的 QQ。
Heartbeat
每 30 分钟无脑唤醒一次。
唤醒后干什么?检查心跳清单。
这个清单是日常聊天中积累的。当 OpenClaw 觉得某个事情是长期任务,就会自己塞进心跳清单。比如知道你朋友下周生日,它就会把「到时发祝福」记进去。
每次心跳唤醒时,它根据当前日期判断清单里有没有该做的事。有就主动做,没有就安静返回。
这两套机制一起,让 OpenClaw 从「你叫它才来」变成了「它主动找你」。
以前的 AI 助手都是一次性的。你问完它就消失了。OpenClaw 的双调度把短任务变成了长期任务,这才是它最让人上瘾的地方。
Skill 渐进式披露:150 个技能不炸上下文
OpenClaw 能装大量 Skill——有人装了 150 个。
但问题来了:150 个 Skill 的详细说明全塞进 System Prompt,Token 数不是 5 万,是 50 万都打不住。
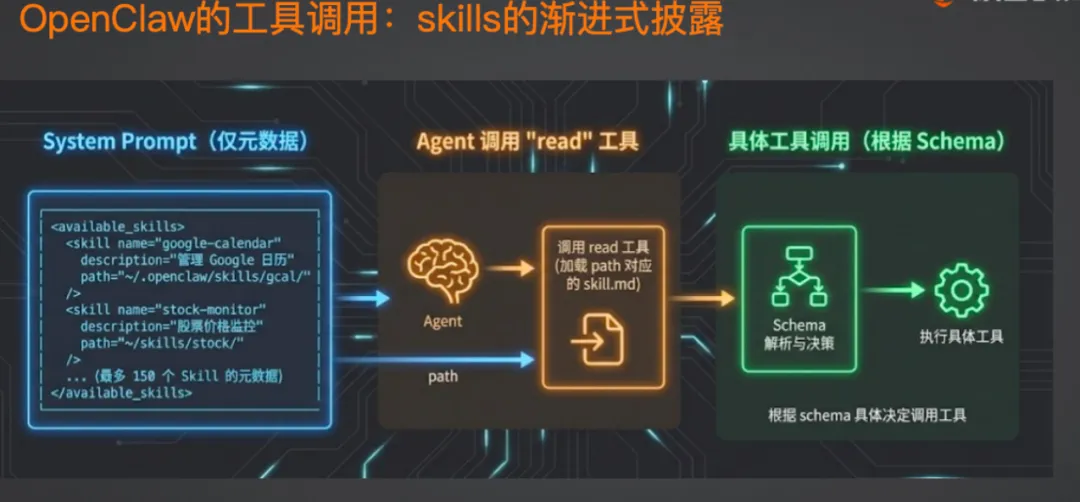
OpenClaw 的解决方案叫渐进式披露。原理很简单:
-
System Prompt 只加载每个 Skill 的名字和一句话描述(每个不超过 100 Token) -
当模型决定要用某个 Skill 时,调用「加载 Skill」工具 -
这个工具读取对应的 skill.md 文件,把完整说明加到上下文里 -
模型根据说明执行具体操作
用到才加载,不用不占空间。
更有意思的是,OpenClaw 还支持一键安装 Skill。你直接说「我想要一个管理 Notebook 的能力」,它自己去 Skill Hub 搜索、下载、安装。从此你的龙虾就多了一个技能。
它甚至能自己写 Skill。比如你说「我需要一个百度搜索工具」,它自己写脚本、放进 Skill 目录。这就是为什么有人说 OpenClaw 能「自主进化」。
想自己搭一个?9 步蓝图
看完上面的拆解,你会发现 OpenClaw 的每个模块都不难。难的是把它们攒在一起,并且打磨好细节。
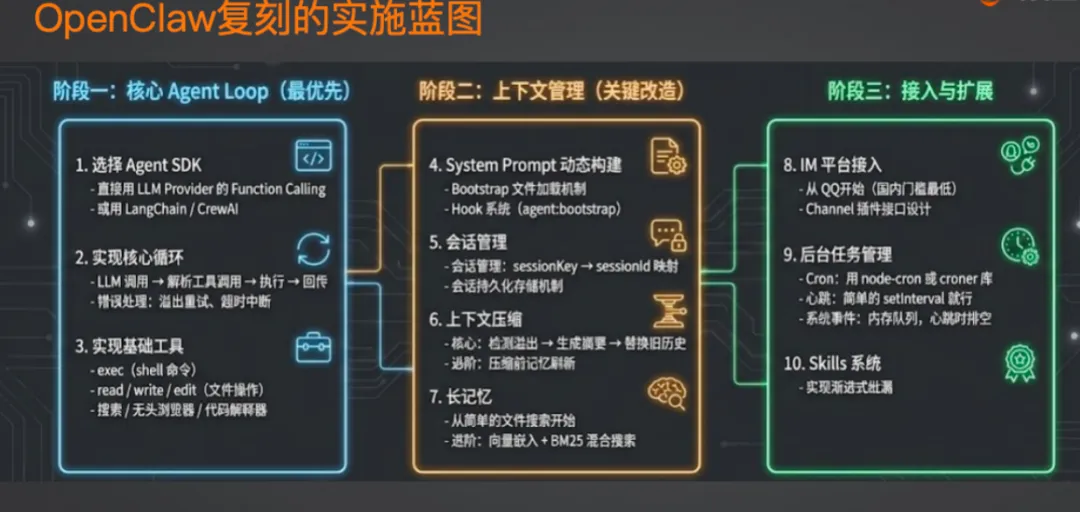
如果你想自己复刻,路线图是这样的:
-
搞定 Agent 核心:选好模型,跑通 ReAct 循环。可以自己写,也可以用 LangChain 之类的框架 -
装好基础工具:Shell 命令、文件读写、无头浏览器(Playwright)、代码解释器。缺一个都不行 -
做 System Prompt 动态构建:用 Markdown 文件管理,让模型自动加载 -
加 Hook 系统:在 System Prompt 构建前后、模型调用前后、工具调用前后插钩子,方便调试和安全管控 -
搞会话管理:Session 何时新建、何时复用、何时重试、存在哪里 -
做上下文工程:溢出检测、摘要生成、裁剪压缩,想更强就加长记忆 -
接入 IM 平台:国内推荐 QQ(飞书需要企业环境,钉钉配置麻烦) -
加后台任务:CronTab + 心跳机制 -
做 Skill 加载:实现渐进式披露
这一套理解了原理,花一两周时间,加上 Vibe Coding,搭出来不是问题。
春节期间已经有七八个各种 Claw 冒出来了——Python 版、Go 版、Rust 版都有。核心就是这套东西。
OpenClaw 技术上没什么黑魔法。
IM 做入口,ReAct 做决策,动态 Prompt 做个性化,双调度做主动性,渐进式披露管 Skill 扩展。每一个模块单拎出来都不新鲜。但攒在一起,就变成了一个让人忍不住分享的产品。
2026 年做 AI 产品,技术不是瓶颈。怎么把技术变成人愿意用、愿意传的东西,这才是真正的门槛。
OpenClaw 给了一个样板。而且是开源的、可以复刻的。
剩下的,就看你愿不愿意动手了。
