 夜雨聆风
夜雨聆风





别急着喂AI吃“文档”!先看看你的“数据食材”洗干净了吗?
|
构建高质量知识库的标准化数据预处理 一份给所有人的AI知识库数据准备指南 |

导语
想用AI帮你管理公司文件、回答客户问题,甚至当你的个人超级大脑吗?2026年了,这想法很棒!但很多人第一步就错了,直接把一堆乱七八糟的文档、PDF、聊天记录“扔”给AI。
结果就是AI要么“胡言乱语”,要么“答非所问”。问题出在哪?你的“数据食材”没处理好。
今天,我们就用最直白的话,告诉不同角色的你,该怎么一步步准备好数据,喂出一个聪明又靠谱的AI知识库。
01
先别管技术,搞懂这“五步洗菜法”

想象一下你要做一桌好菜,AI就是厨师,你的文档就是食材。直接扔烂叶子、带泥的萝卜给厨师,能做出美味吗?处理数据也一样,有五步必须做:
01
洗菜:数据清洗
去除文档中的无用信息,如页眉页脚、广告、乱码、重复段落。
核心工具:Python的Pandas库和Unstructured库;对于扫描件,推荐Tesseract等OCR工具。
02
去敏感:数据脱敏
保护隐私,移除或替换手机号、身份证号等敏感信息。
常用方法:删除法、掩码法(如1385678)、替换法(用虚构值)、泛化法(如将具体年龄转为年龄段)。
核心工具:开源库如MaskPy,或企业级平台如IBM InfoSphere Optim。
03
切菜:数据结构化
将长文档按语义切割成大小合适的“知识块”,并标注来源。
核心技巧:按自然段落或标题切割,保持语义完整;利用LangChain或LlamaIndex等框架的文本分割器。
04
编码:数据向量化
将文本“块”转换为AI可理解的数字向量,并存入向量数据库。
操作要点:为中文文档选择BGE系列或M3E等嵌入模型;使用Chroma(简易)或Milvus(强大)等向量数据库存储。
05
留底:合规审计
记录数据处理的全链路,确保流程可追溯、可审计。
操作建议:使用DataHub等工具自动化记录“数据血缘”。
02
不同角色的操作重点
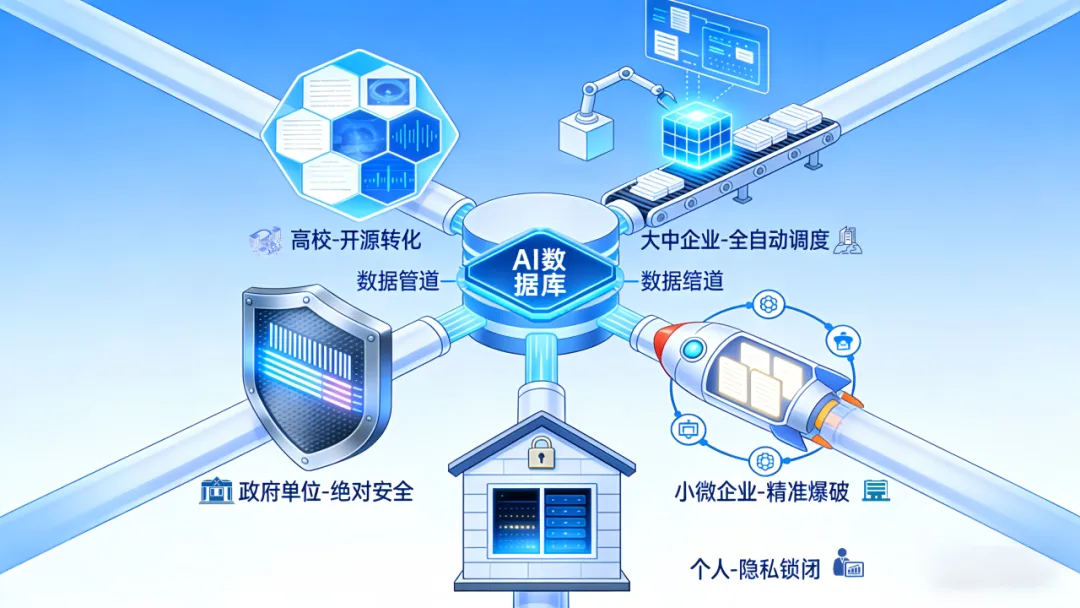
数据处理绝非“一刀切”。面对政府的敏感信息、企业的海量业务数据、个人的私密笔记,清洗与治理的重点、工具与流程都应有专属的“配方”。

政府/大型国企:
安全第一,流程必须绝对规范、可追溯。必须用最严格的方法(比如差分隐私)处理任何可能涉及个人和国家的信息。
核心口诀:“流程标准化,安全放第一,每一步都要经得起查。”

中大型企业:
搭建自动化数据处理流水线,选用高性能向量数据库,重点打通各部门间的“信息孤岛”。
核心口诀:“自动化流水线是核心,选好向量数据库撑住场面,打通各部门数据是关键战役。”

小微企业/初创团队:
使用LangChain + ChromaDB等现成组合快速搭建原型,优先聚焦核心数据,可考虑云服务。
核心口诀:“现成工具快速上手,集中火力做好核心数据,别在前期过度折腾。”

个人/创作者:
优先本地部署以保护隐私,处理前做好数据脱敏,可尝试AnythingLLM等一体化工具。
核心口诀:“数据不离本地,隐私大于一切,用顺手的一体化工具简化流程。”

高校/医院/研究院:
善用开源工具,处理好论文、病例等多模态数据,并建立统一规范。
核心口诀:“开源工具是法宝,多模态数据处理好,统一规范效率高。”

建议
-
从小处开始:先选取一个重要的子集(如最新产品Q&A)跑通全流程。
-
重视“切菜”:多花时间试验不同的文本分割方法,这对最终效果影响最大。
-
做好记录:即便使用Excel记录处理过程,对未来也大有裨益。


最后
记住,给AI准备数据,就像为一位挑剔但潜力巨大的厨师准备食材。你花在“洗、切、配”上的每一分钟心思,都会直接体现在它端出的“答案”这道菜的质量上。现在,就从整理你手头最重要的那份文档开始吧!
