 夜雨聆风
夜雨聆风





一次前向传播"读懂"长文档:Doc-to-LoRA让大模型瞬间内化上下文
把一篇3万token的长文档压缩进大模型参数里,需要多久?传统方法要几百秒、几十GB显存,而Sakana AI提出的Doc-to-LoRA(D2L)只需不到1秒、不到2GB显存,性能还更好。更惊人的是,它在仅用256 token短文本训练后,能零样本泛化到超过32K token的长文档,准确率接近满分——这比基座模型原生上下文窗口长了4倍以上。
长上下文推理的效率困境
LLM通常通过ICL(In-Context Learning,上下文学习)来适配文档、任务和用户偏好——把相关信息放入上下文窗口即可。但这种方式有硬伤:Transformer的注意力计算复杂度是二次方的,长提示会导致延迟飙升、KV缓存膨胀,且生成质量在长上下文下往往下降。
CD(Context Distillation,上下文蒸馏)是一种替代方案:让LLM在没有上下文的情况下模仿自己在有上下文时的输出,从而将信息”内化”到模型参数中。但CD的致命问题在于每次内化都需要反复梯度更新,耗时耗力,无法用于交互式或端侧场景。
Doc-to-LoRA:一次前向传播完成上下文蒸馏
论文提出了D2L(Doc-to-LoRA),核心思路是用一个超网络(hypernetwork)元学习整个CD过程。训练完成后,给定任意新文档,D2L只需一次前向传播就能生成一组LoRA(Low-Rank Adaptation,低秩适配)适配器,将文档信息注入目标LLM的参数中。之后该LLM回答问题时完全不需要原始上下文,从而大幅降低推理延迟和显存占用。
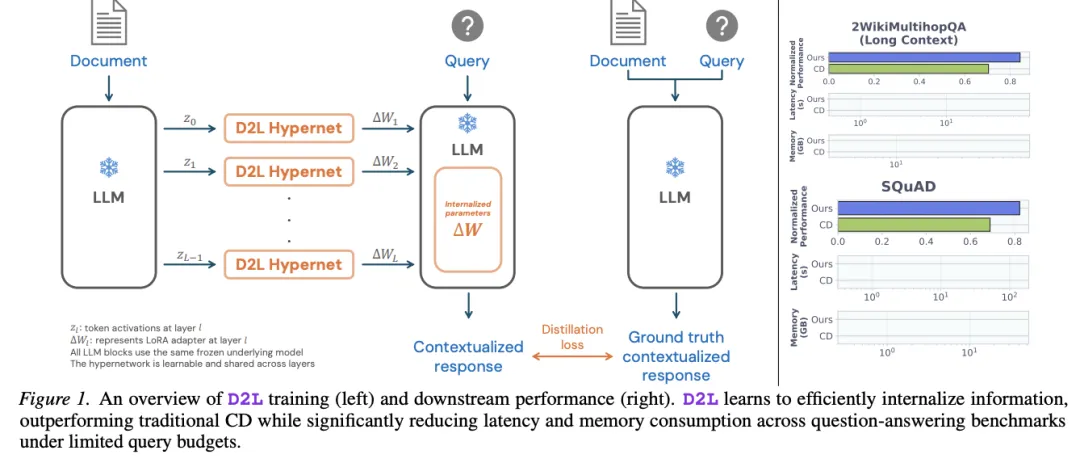
[Figure 1: D2L训练概览与下游性能] 左侧展示D2L的训练流程:超网络读取上下文的逐层token激活,生成LoRA矩阵;右侧展示在问答基准上,D2L在性能上优于传统CD,同时大幅降低延迟和显存消耗。
具体而言,论文的元训练目标如下:将上下文c输入冻结的目标LLM获取逐层token激活Z,然后一个共享的超网络将每层激活映射为该层的LoRA矩阵。优化目标是最小化”有上下文的教师模型”与”装载了LoRA的学生模型”之间的KL散度。与传统CD逐样本优化不同,D2L用一个超网络跨所有上下文泛化,将查询生成和反向传播的开销全部摊销到训练阶段。
架构关键设计:Perceiver与分块机制
论文基于Perceiver架构设计超网络,利用交叉注意力将变长输入映射到固定数量的隐向量,再通过逐层输出头生成LoRA的A矩阵和B矩阵。整个超网络包含8个交叉注意力块,无自注意力层,总共仅3.09亿可训练参数。
分块机制是处理长文档的核心。 论文将长上下文切分为K个等长块,每块独立通过超网络生成rank-8的LoRA适配器,然后沿秩维度拼接,最终得到总秩为r·K的适配器。这使得D2L无需改变超网络输出形状,就能为更长文档生成更高秩的适配器。生成的适配器应用于基座模型每个MLP块的”down projection”层。
合成任务验证:大海捞针
论文首先在NIAH(Needle-in-a-Haystack,大海捞针)任务上验证D2L。该任务要求模型从大量干扰文本中定位一个特殊的4位数字。基座模型为gemma-2-2b-it(8K上下文长度),D2L的训练数据仅使用32到256 token的输入,评估时最大块大小为1024 token。
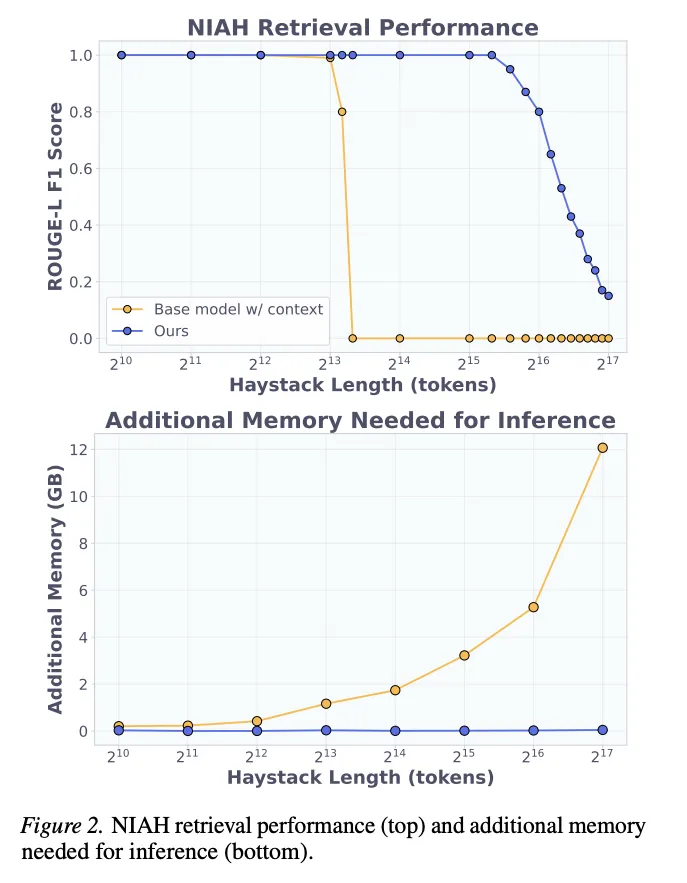
[Figure 2: NIAH检索性能(上)与推理额外显存消耗(下)] D2L在8K token内实现完美准确率,在超过基座模型上下文窗口后仍保持高准确率直至约40K token;显存方面,基座模型处理128K token需超过12GB额外显存,而D2L始终低于50MB。
结果显示,D2L在最长40K token(40个块)时仍保持接近完美的准确率,这是训练时最大块数(8块)的5倍。超过该长度后性能才开始平缓下降。而基座模型在超过8K token后准确率急剧崩塌。在显存方面,处理128K token时基座模型需要超过12GB额外显存,D2L则始终低于50MB。
真实问答任务:更快、更省、更准
论文在6个真实QA基准上评估D2L,包括短文本任务SQuAD、DROP、ROPES,以及LongBench中的长文档任务2WikiMultihopQA、MultiFieldQA、QASPER。评估指标为词级ROUGE-L F1分数(相对于基座模型直接读取上下文的性能归一化)。
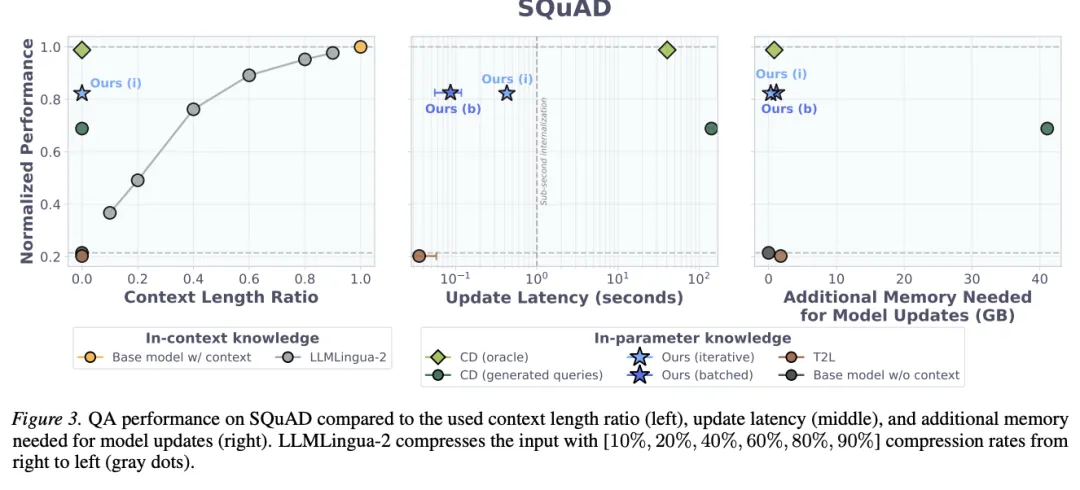
[Figure 3: SQuAD上的QA性能、更新延迟与额外显存] D2L在所有参数内知识基线中表现最优,在SQuAD上达到基座模型ICL上界的82.5%相对性能;更新延迟低于1秒,而CD(oracle)约40秒,带生成查询的CD超过100秒。
在短文本任务上,D2L在三个基准中均优于所有参数内知识基线。在更新效率方面,D2L的内化延迟不到1秒,额外显存低于2GB;而带生成查询的CD需要超过100秒和40GB以上显存。
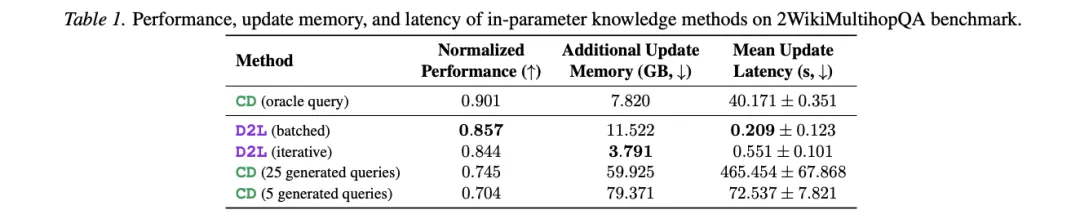
[Table 1: 2WikiMultihopQA上参数内知识方法的性能、更新显存与延迟] D2L(batched模式)归一化性能0.857,更新延迟仅0.209秒;CD(5个生成查询)性能0.704,延迟72.5秒,显存79.4GB。
在长文档任务上,D2L从未在训练中见过超过2344 token的样本,却能零样本泛化到32K token的文档。
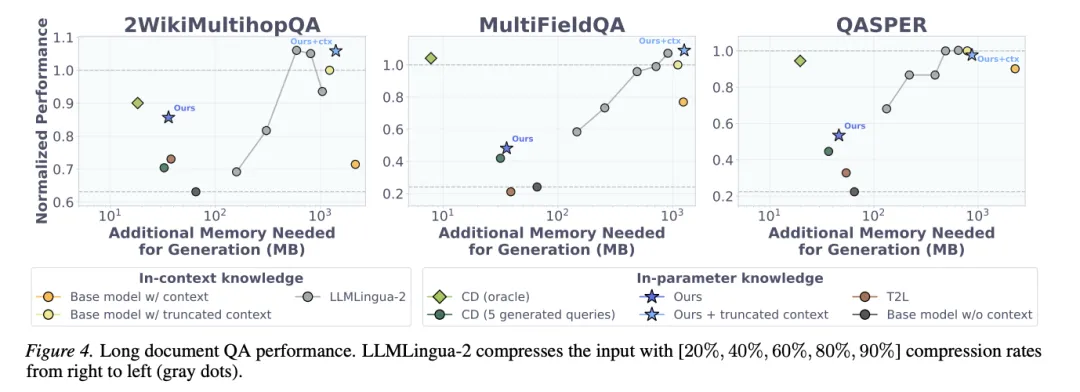
[Figure 4: 长文档QA性能与生成阶段额外显存] D2L在2WikiMultihopQA和MultiFieldQA上优于CD基线,同时将生成阶段显存从ICL的约1GB降至不到100MB。有趣的是,在D2L内化后再让模型读取截断上下文,性能还能进一步提升。
跨模态零样本迁移:从视觉到文本
论文还探索了一个令人意外的应用:用VLM(Visual-Language Model,视觉语言模型)gemma-3-4b-it作为上下文编码器,将视觉信息通过D2L注入纯文本模型gemma-2-2b-it。D2L在训练中从未见过任何图像,却在Imagenette(ImageNet的10类子集)上达到了75.03%的分类准确率,远超10%的随机基线。
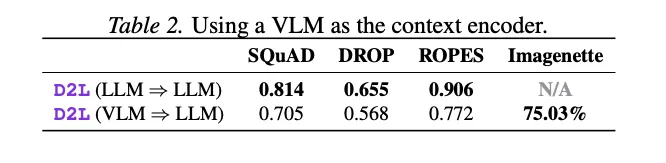
[Table 2: 使用VLM作为上下文编码器的结果] VLM到LLM的跨模态D2L在Imagenette上达到75.03%准确率,文本QA性能有所下降但仍可用。
X说
论文分析认为,D2L之所以在有限计算预算下优于传统CD,是因为超网络在数百万上下文样本上训练,学会了模拟在大量查询上蒸馏的效果。实验证实,即使将CD的生成查询数增加到100个(耗时超过10分钟/样本),其SQuAD性能(0.650)仍远低于D2L(0.866)。
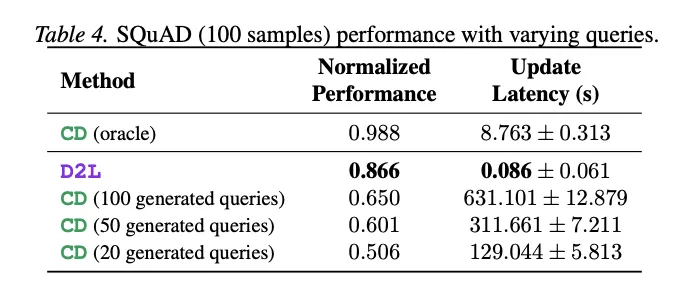
[Table 4: SQuAD上不同查询数的CD与D2L对比] D2L性能0.866,延迟0.086秒;CD(100个查询)性能0.650,延迟631秒。
一句话总结D2L的核心价值:用一次前向传播替代数百次梯度更新,将上下文蒸馏从分钟级压缩到亚秒级,同时保持甚至提升了内化质量。 这为LLM的频繁知识更新、个性化聊天行为以及端侧部署打开了新的可能性。
论文原始标题:Doc-to-LoRA: Learning to Instantly Internalize Contexts
论文链接:https://arxiv.org/abs/2602.15902
#无影寺
