 夜雨聆风
夜雨聆风





5秒拯救混乱PDF文献库!玉京AI让文献整理效率翻10倍

做科研,谁还没个“文件强迫症”?下载了一堆文献,往文件夹里一放,杂乱无章,看着这堆“乱码”,你想找一篇“胰腺癌免疫治疗”的文献,只能一篇篇点开看。想整理?手动重命名一篇至少30秒,50篇就是半小时。不整理?下次找文献直接崩溃。这个场景,是不是像极了每天在做无用功的你?
别让“文件命名”这种杂活儿,消耗你的科研精力
其实,这个问题本该有最简单的解法。
玉京中外文文献AI辅助系统的PDF文件名识别功能,就是来给你“减负”的,可把你那些乱七八糟的PDF文件名,一键变成整齐划一的“标准格式”。
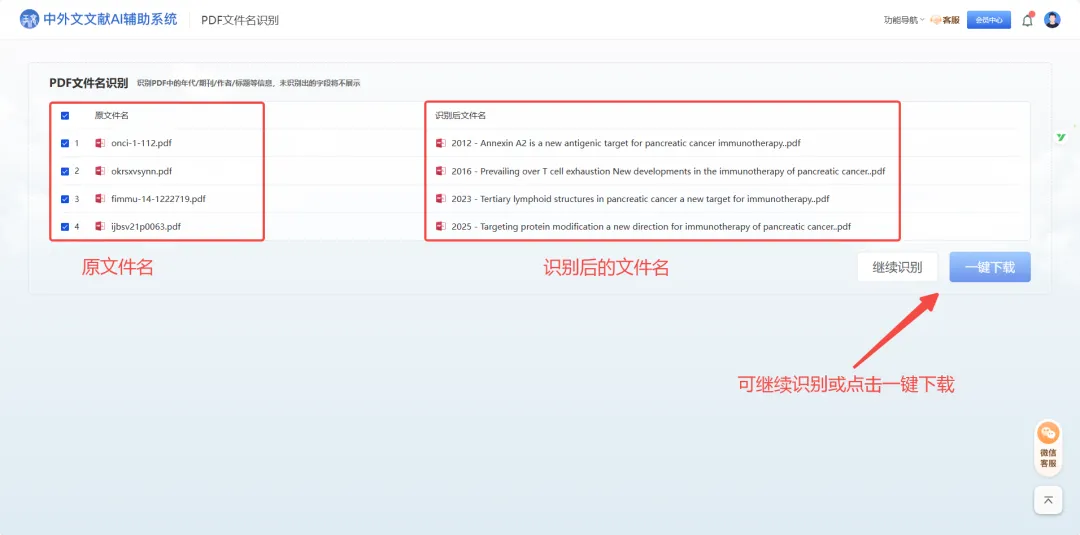
年代、标题、期刊、作者,清清楚楚。哪年的、讲的什么,一眼扫过去全知道。这才是做学问该有的样子。
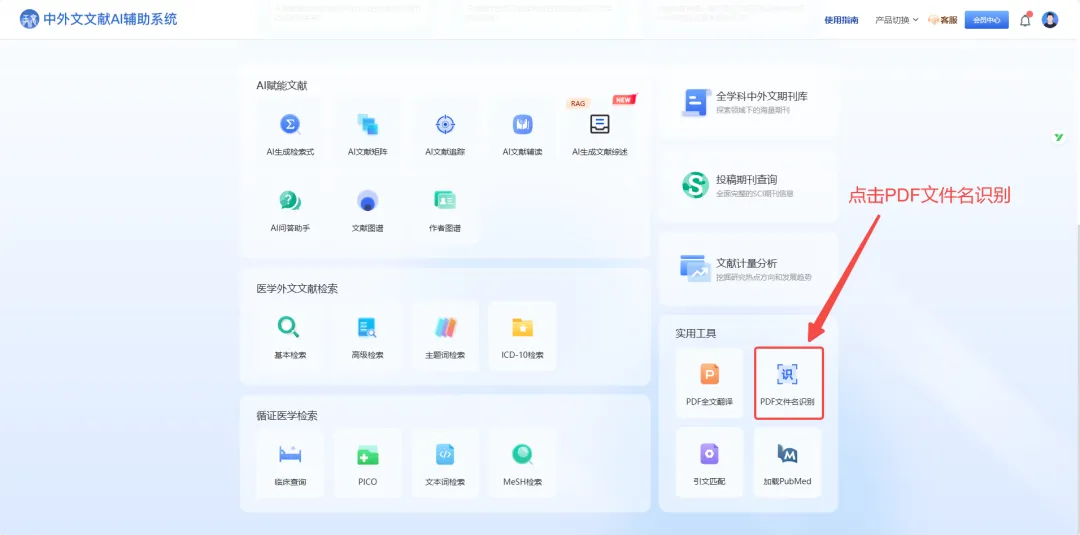
怎么操作?3步搞定,比你重命名一篇还快
1
扔进去
打开“PDF文件名识别”页面,把你那堆混乱的PDF直接拖拽到上传区域。支持批量,一次最多100个,总大小不超过500M——够你整理好几个月的下载量。
2
选格式
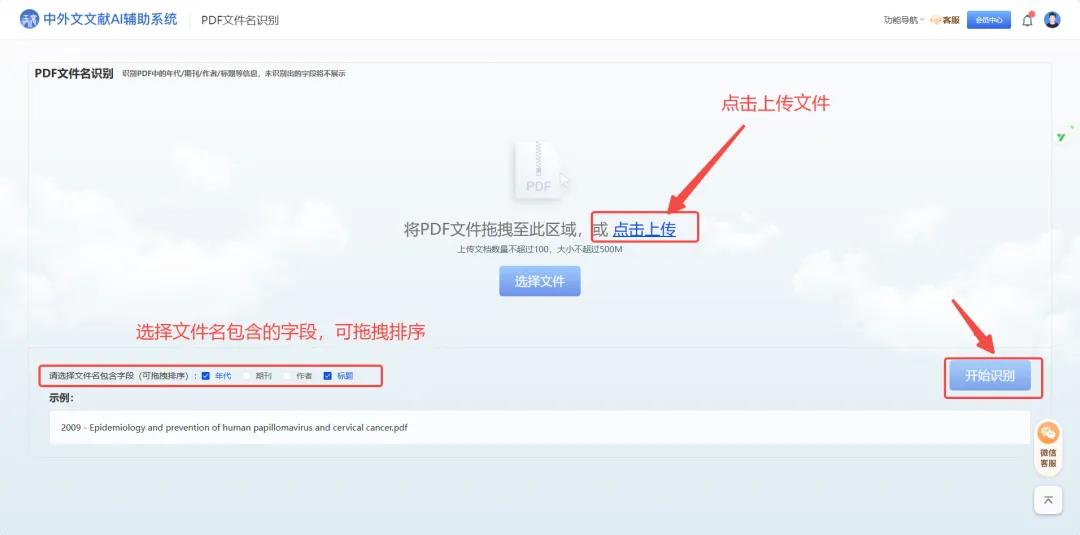
系统支持年代、期刊、作者、标题四个字段自由组合。你想怎么排,就怎么排。
-
想按时间线看研究脉络?就选“年代-标题”。
-
想投稿时方便引用?就选“作者-期刊-年代-标题”。
-
甚至可以用拖拽调整顺序:把“年代”拖到最前面,或者把“期刊”放在标题后,随你。
最关键的是:系统会记住你的习惯。这次选好,下次进来默认就是这套规则,不用重新选。
3
点开始
点击“开始识别”静待1分钟,刚才那一堆“乱码”已经变成了整整齐齐的标准文献名。如果想要识别更多,可以点击“继续识别”。
为什么你需要这个功能?
1
节省的是时间,保护的是精力
整理50篇文献,手动改可能要花掉半小时——这半小时本该用在读文献、写笔记上。改文件名这种毫无技术含量的事,交给机器去做,你的大脑值得用来思考更重要的东西。
2
找文献终于不用“靠缘分”
以前找文献,只能靠记忆:“好像是个2022年的……标题里有therapy……是哪个期刊来着?”然后在文件夹里瞎点。
现在直接看文件名:2022 – 标题 – 期刊.pdf,想找哪篇一目了然。写文章时插入参考文献,也不会因为文件名混乱而漏引错引。
3
符合你的习惯,不是让你去适应它
不是所有文献管理工具都要你学一套新逻辑。这里你可以自定义命名规则:有人习惯“年代+标题”,有人需要“作者+期刊”,有人必须把“期刊”放第一位。拖一拖,排好序,以后就按这个来。
能省一步是一步
科研路上,我们已经被各种繁杂事务消耗得够多了——投稿格式改来改去,参考文献调了又调,数据整理耗时耗力。
“PDF文件名识别”不解决科研的大问题,但它能帮你解决每天都会遇到的那个小麻烦。 而正是这些小麻烦,日积月累,偷走了我们本该专注在学术本身的时间。
文件已经拖进去了,剩下的交给玉京PDF文件名识别。你只管安心读文献、做研究。

关于玉京:
玉京(深圳)量子科技有限公司,是一家聚焦人工智能与多学科智慧融合发展的创新型科技企业。公司依托在中外文文献领域20余年的深厚积累,推出基于大模型技术与海量中外文文献数据深度融合的五款核心产品:AI学术搜索系统、中外文文献AI辅助系统、AI辅助科研系统、临床问题AI智循系统以及AI辅助诊疗系统。

