 夜雨聆风
夜雨聆风





数据可视化|wordcloud词云图(附代码)
在信息爆炸的时代,如何从海量文本中快速捕捉关键词、洞察核心主题?词云图(Word Cloud)是一种直观又美观的可视化方式,它通过字体大小和颜色突出显示文本中出现频率较高的词汇,广泛应用于舆情分析、用户评论挖掘、新闻热点追踪等场景,它长这样:

今天,我们就来手把手教你使用Python中的wordcloud库生成高颜值词云图,并附上完整一键运行代码
一、什么是WordCloud?
WordCloud(词云)是一种将文本数据以视觉化形式呈现的技术:
词频越高,字体越大
可自定义形状、颜色、字体、背景等
支持中文、英文等多种语言
Python的wordcloud库是目前最流行的词云生成工具之一,大家可以去它的官网进行学习,上面有很多介绍和案例:https://amueller.github.io/word_cloud/index.html
下面正式干货开启~
二、实践案例
Step1.前置准备
在开始之前,需要安装以下必要的库(复制代码,在脚本里运行等待下载完成即可):
pip install wordcloud matplotlib jieba numpy pillow说明:
wordcloud:词云生成库
jieba:中文分词(处理中文文本必备)
matplotlib:用于绘图展示
numpy和Pillow:图像处理支持
知识点补充:啥是jieba?
jieba是一个用于中文文本分词的Python第三方库,是目前最流行、最易用的中文分词工具之一
为什么需要jieba?
英文等语言中,单词之间有空格分隔,例如:Natural language processing is powerful.
但中文没有天然分隔符,如:自然语言处理很强大
计算机无法直接知道这是 “自然/语言/处理/很/强大” 还是 “自然语言/处理/很强/大”
所以,中文NLP(自然语言处理)的第一步通常是“分词”,而jieba就是用来做这件事的,以下为一个简单栗子:
import jiebatext = "自然语言处理是人工智能的重要分支。"words = jieba.lcut(text) #返回 listprint(words)输出:['自然语言处理', '是', '人工智能', '的', '重要', '分支', '。']
知识点补充完毕,咱们回到正题~
Step2.复制代码,一键运行(语言为Python)
Case1:手动在脚本里输入内容的场景(中文、英文、手动设定、colormaps)
text = """人工智能是当今科技发展的核心驱动力之一。机器学习、深度学习、自然语言处理等技术正在改变我们的生活。千问、豆包等大模型是中国在人工智能领域的重要代表。"""
from wordcloud import WordCloudimport matplotlib.pyplot as pltimport jiebaimport random# 示例中文文本text = """人工智能是当今科技发展的核心驱动力之一。机器学习、深度学习、自然语言处理等技术正在改变我们的生活。千问、豆包等大模型是中国在人工智能领域的重要代表。"""# 停用词列表,添加你想要剔除的词语stopwords = {'的', '是', '之一', '等'}# 中文分词并去除停用词words = [word for word in jieba.cut(text) if word not in stopwords]words = ' '.join(words)# 自定义灰度颜色函数def grey_color_func(word, font_size, position, orientation, random_state=None, **kwargs):return "hsl(0, 0%%, %d%%)" % random.randint(60, 100)# 创建词云对象wc = WordCloud(font_path='simhei.ttf', # 字体设置width=800,height=400,background_color='black', # 背景颜色设置max_words=100,color_func=grey_color_func, # 使用自定义颜色函数).generate(words)# 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis('off') # 不显示坐标轴plt.show()# # 可选:保存为图片# wc.to_file("wordcloud.png")

colormap='Set1_r'from wordcloud import WordCloudimport matplotlib.pyplot as pltimport jieba# 示例中文文本text = """人工智能是当今科技发展的核心驱动力之一。机器学习、深度学习、自然语言处理等技术正在改变我们的生活。千问、豆包等大模型是中国在人工智能领域的重要代表。"""# 停用词列表,添加你想要剔除的词语stopwords = {'的', '是', '之一', '等'}# 中文分词并去除停用词words = [word for word in jieba.cut(text) if word not in stopwords]words = ' '.join(words)# 创建词云对象wc = WordCloud(font_path='simhei.ttf',width=800,height=400,background_color='white',max_words=100,colormap='Set1_r').generate(words)# 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.show()# # 可选:保存为图片# wc.to_file("wordcloud.png")

# 英文则无需分词,文字素材来自美联储 Minutes of the Federal Open Market Committee January 27–28, 2026from wordcloud import WordCloudimport matplotlib.pyplot as plttext = """Developments in Financial Markets and Open Market OperationsThe manager turned first to an overview of broad market developmentsduring the intermeeting period. Respondents to the Open Market DeskSurvey of Market Expectations (Desk survey) continued to see the economyas resilient and again marked up their forecasts for real gross domesticproduct (GDP) growth in 2026, while their expectations for headlinepersonal consumption expenditures (PCE) inflation and the unemploymentrate were little changed. Market- and survey-based policy rate expectationswere likewise little changed. Market-based measures of policy rate expectationsindicated one to two 25 basis point rate cuts this year, and the median modal path of thefederal funds rate, as given in the Desk survey, continued to indicate expectations oftwo 25 basis point rate cuts this year."""wc = WordCloud(width=800,height=400,font_path='msyh.ttc',background_color='white').generate(text)plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.show()# # 可选:保存为图片# wc.to_file("wordcloud.png")

Case2:读取文档内容生成词语图
上面每次都需要手动输入文字在脚本中,有点麻烦,下面我们来处理读取现有文档来生成词语图的场景,我使用AI写了一篇关于人工智能的文章,我们来用它生成词语图
AI生成的文章内容如下:
人工智能:改变世界的智能革命人工智能(Artificial Intelligence,简称AI)是当前科技领域最热门的话题之一。从智能手机的语音助手到自动驾驶汽车,从医疗诊断到金融预测,AI正在以惊人的速度改变着我们的生活。那么,究竟什么是人工智能?它是如何工作的?又将如何影响我们的未来?本文将为您揭开人工智能的神秘面纱,带您走进这个充满无限可能的智能世界。 一、人工智能的定义与发展历程1. 什么是人工智能?人工智能是一门旨在使计算机系统能够模拟、延伸和扩展人类智能的技术科学。它涉及机器学习、自然语言处理、计算机视觉、专家系统等多个领域。简单来说,人工智能就是让机器能够像人类一样思考、学习和解决问题。 2. 人工智能的发展历程人工智能的发展可以追溯到20世纪50年代。1956年,达特茅斯会议被认为是人工智能诞生的标志,会议首次提出了“人工智能”这一术语。此后,人工智能经历了几次高潮和低谷: ·1950s-1960s:人工智能的黄金时期,出现了逻辑理论机、通用问题解决器等早期AI系统。 ·1970s-1980s:第一次AI寒冬,由于技术限制和过高的期望,AI研究陷入低谷。 ·1990s-2000s:专家系统和机器学习的兴起,AI开始在特定领域得到应用。 ·2010s至今:深度学习的突破,大数据和计算能力的提升,推动AI进入快速发展期。 二、人工智能的核心技术1. 机器学习(Machine Learning)机器学习是人工智能的核心技术之一,它使计算机能够从数据中学习并改进性能,而无需明确编程。机器学习主要分为以下几类: ·监督学习:通过标记数据训练模型,例如图像识别、垃圾邮件过滤。 ·无监督学习:从无标记数据中发现模式,例如聚类分析、异常检测。 ·强化学习:通过与环境互动学习最优策略,例如AlphaGo、自动驾驶。 2. 深度学习(Deep Learning)深度学习是机器学习的一个分支,它模仿人脑神经网络的结构和功能。通过多层神经网络,深度学习能够处理复杂的数据,如图像、语音和自然语言。著名的深度学习模型包括卷积神经网络(CNN)用于图像识别,循环神经网络(RNN)用于序列数据处理。 3. 自然语言处理(NLP)自然语言处理使计算机能够理解、解释和生成人类语言。常见的应用包括机器翻译、语音识别、聊天机器人等。近年来,预训练语言模型如BERT、GPT系列的出现,极大地提升了NLP的性能。 4. 计算机视觉(Computer Vision)计算机视觉让机器能够“看”和理解图像与视频。它广泛应用于人脸识别、自动驾驶、医学影像分析等领域。深度学习的发展,特别是CNN的应用,使得计算机视觉的准确率大幅提高。 三、人工智能的应用领域1. 医疗健康AI在医疗领域的应用包括疾病诊断、药物研发、个性化治疗等。例如,AI系统可以通过分析医学影像(如X光、CT扫描)辅助医生发现早期病变;通过分析大量病历数据,预测患者的疾病风险。 2. 自动驾驶自动驾驶是AI的重要应用之一。通过传感器(如摄像头、雷达、激光雷达)收集数据,AI系统能够实时感知环境、做出决策并控制车辆。目前,自动驾驶技术已经进入L4级别(高度自动驾驶),未来有望实现完全自动驾驶。 3. 金融服务AI在金融领域用于风险评估、 fraud detection、算法交易等。例如,银行使用AI分析客户的信用数据,评估贷款风险;投资机构利用AI进行股票预测和高频交易。 4. 教育AI在教育中的应用包括个性化学习、智能辅导、自动评分等。例如,AI系统可以根据学生的学习情况提供定制化的学习内容;通过分析学生的答题数据,帮助教师了解学生的薄弱环节。 5. 娱乐与媒体AI在娱乐领域的应用包括推荐系统(如Netflix、抖音的推荐算法)、游戏AI(如AlphaGo)、虚拟偶像等。此外,AI还可以用于生成音乐、绘画等创意内容。 四、人工智能的挑战与伦理问题1. 技术挑战·数据隐私:AI需要大量数据进行训练,但数据收集和使用可能侵犯个人隐私。 ·算法偏见:如果训练数据存在偏见,AI系统可能会产生歧视性结果。 ·可解释性:许多AI模型(如深度学习)是“黑箱”,难以解释其决策过程。 ·安全性:AI系统可能受到攻击,例如对抗样本攻击,导致错误决策。 2. 伦理问题·就业影响:AI可能替代部分人类工作,导致失业问题。 ·责任归属:当AI系统做出错误决策时,责任应由谁承担? ·自主武器:AI在军事领域的应用可能引发伦理争议。 ·公平性:如何确保AI系统的决策公平,不歧视特定群体? 五、人工智能的未来展望尽管面临挑战,人工智能的未来仍然充满希望。以下是一些可能的发展方向: ·通用人工智能(AGI):目前的AI是弱人工智能(专注于特定任务),未来可能发展出能够像人类一样处理各种任务的通用人工智能。 ·人机协作:AI将成为人类的助手,而非替代者,实现人机协同工作。 ·边缘计算与AI结合:AI模型将部署在边缘设备(如手机、传感器)上,实现实时处理和低延迟。 ·AI伦理与治理:建立全球统一的AI伦理框架和治理体系,确保AI的安全和负责任发展。 六、结语人工智能是一场深刻的技术革命,它正在改变我们的生活方式、工作方式和思维方式。作为一项强大的工具,AI既带来了巨大的机遇,也带来了严峻的挑战。我们需要以开放、理性的态度对待AI,在推动技术进步的同时,重视伦理和安全问题,让人工智能更好地服务于人类社会。未来,人工智能将继续发展,成为推动经济增长和社会进步的重要力量。让我们共同期待这个智能时代的到来! |
我们将上述文章命名为:测试文档.docx
还是一样的,文档名称改啥都行,找到代码的这一行修改对应即可(就在下方完整代码最开始的地方):
# 读取 Word 文档doc = Document('测试文档.docx') # 这里改成你的 .docx 文件
然后我们来上完整案例:
重要:我们在读取文章时,因为文章的字数一般不少,肯定会有很多类似如【的、了、是……】等等对于我们看云词图没意义的字,所以我们得把这些剔除掉
使用的方法就是创建一个【停用词列表】,把不要的字和词语放进去,这样最终生成的图就会剔除这些
停用词列表大概长这样(中英文都是一样的做法):
stopwords = {# 基础中文停用词'的', '了', '在'}
然后完整代码如下:
from docx import Documentfrom wordcloud import WordCloudimport matplotlib.pyplot as pltimport jieba# 1. 读取 Word 文档doc = Document('测试文档.docx') # 这里改成你的 .docx 文件# 提取所有段落文本text = '\n'.join([paragraph.text for paragraph in doc.paragraphs])# 如果文档中有表格,也可以提取表格内容for table in doc.tables:for row in table.rows:for cell in row.cells:text += '\n' + cell.text# 2. 停用词列表stopwords = {# 基础中文停用词'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个','上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好','自己', '这', '那', '里', '就是', '还是', '等', '之一', '我们', '他们', '她', '它','其', '之', '与', '或', '及', '而', '以', '可', '能', '将', '会', '可以', '能够','通过', '进行', '实现', '包括', '例如', '比如', '如', '以及', '同时', '此外',# 标点符号与空白'、', ',', '。', ';', ':', '?', '!', '"', "'", '“', '”', '‘', '’', '(', ')','【', '】', '[', ']', ' ', '\n', '\t', '\r', '·', '…', '—', '-', '——',# 泛化名词(来自你的文档)'技术', '系统', '领域', '问题', '方式', '方法', '过程', '结果', '能力', '应用','方面', '部分', '情况', '数据', '信息', '内容', '概念', '工具', '模型', '任务','工作', '生活', '社会', '世界', '时代', '力量', '代表', '标志', '阶段', '时期',# 泛化动词/形容词'改变', '使用', '处理', '分析', '学习', '训练', '生成', '提供', '做出', '带来','推动', '发展', '提升', '提高', '解决', '模拟', '扩展', '延伸', '涉及', '用于','重要', '关键', '强大', '巨大', '严峻', '深刻', '当前', '未来', '目前', '近年来','常见', '广泛', '可能', '潜在', '实际', '真正', '完全', '高度', '特定', '各种',# 单字(通常无独立意义)'中', '大', '小', '高', '低', '新', '旧', '多', '少', '全', '部', '些', '种', '类','所', '被', '给', '让', '使', '把', '对', '于', '由', '从', '向', '往', '当', '并'}# 3. 中文分词并去除停用词words = [word for word in jieba.cut(text) if word not in stopwords and len(word.strip()) > 0]words = ' '.join(words)# 4. 创建词云对象wc = WordCloud(font_path='simhei.ttf',width=800,height=400,background_color='white',max_words=100,# colormap='Set1_r').generate(words)# 5. 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.show()# # 可选:保存为图片# wc.to_file("wordcloud.png")
结果:

可以看到我的图还是会有类似“您”、“为”这样对于云词图没意义的字样,我们只需要再回到脚本里在【停用词列表】里继续添加,直到满意为止,这里我就不弄了
三、进阶实战:自定义形状
上面我们解决了【设定颜色】 + 【读取文件内容】2种场景,那么怎么画出我文章一开始的那种可以自定义图形形状的云词图呢?
答案就是一个词:mask
在词云(WordCloud)中,mask 决定了文字最终排列成什么形状,你要什么形状的mask,弄张对应的图片即可
下面我们正式开始:
Case1:手动输入文字场景
我们先准备一张mask图,这里我手动画了一个圆圈,把它保存成图片,命名为:测试-圆.png

mask名称叫啥都行,只要对应匹配到代码里即可,改代码里这一行:
mask = np.array(Image.open("测试-圆.png")) # 替换为你的图片然后我们上完整代码:
from wordcloud import WordCloudimport matplotlib.pyplot as pltimport jiebaimport numpy as np # 用于处理图片数组from PIL import Image # 用于读取图片# 示例中文文本text = """人工智能是当今科技发展的核心驱动力之一。机器学习、深度学习、自然语言处理等技术正在改变我们的生活。千问、豆包等大模型是中国在人工智能领域的重要代表。"""# 停用词列表,添加你想要剔除的词语stopwords = {'的', '是', '之一', '等'}# 中文分词并去除停用词words = [word for word in jieba.cut(text) if word not in stopwords]words = ' '.join(words)# 读取mask图片(请替换为你的mask_image图片路径,支持jpg/png等格式)# 示例:mask_image.png 是你准备好的蒙版图片,建议使用黑白对比明显的图片try:mask = np.array(Image.open("测试-圆.png")) # 替换为你的图片except FileNotFoundError:print("未找到mask图片,将使用默认矩形生成词云")mask = None# 创建词云对象(新增mask参数)wc = WordCloud(font_path='simhei.ttf',width=800,height=400,background_color='white',max_words=100,colormap='tab20c',mask=mask, # 传入蒙版图片数组contour_width=1, # 可选:添加蒙版轮廓线contour_color='black' # 可选:轮廓线颜色).generate(words)# 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.show()# # 可选:保存为图片# wc.to_file("wordcloud.png")
结果为:
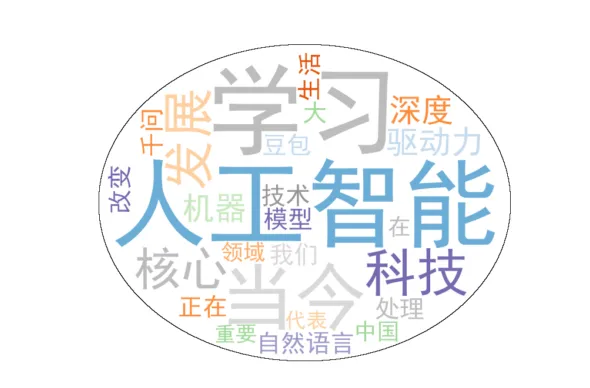
然后我们画另一种,让文字显示在圆圈的外面,命名为:测试-圆-1.png

代码:
from wordcloud import WordCloudimport matplotlib.pyplot as pltimport jiebaimport numpy as np # 用于处理图片数组from PIL import Image # 用于读取图片# 示例中文文本text = """人工智能是当今科技发展的核心驱动力之一。机器学习、深度学习、自然语言处理等技术正在改变我们的生活。千问、豆包等大模型是中国在人工智能领域的重要代表。"""# 停用词列表,添加你想要剔除的词语stopwords = {'的', '是', '之一', '等'}# 中文分词并去除停用词words = [word for word in jieba.cut(text) if word not in stopwords]words = ' '.join(words)# mask读取try:mask = np.array(Image.open("测试-圆-1.png")) # 替换为你的图片except FileNotFoundError:print("未找到蒙版图片,将使用默认矩形生成词云")mask = None# 创建词云对象(新增mask参数)wc = WordCloud(font_path='simhei.ttf',width=800,height=400,background_color='white',max_words=100,colormap='binary',mask=mask,contour_width=1,contour_color='black').generate(words)# 显示词云图plt.figure(figsize=(10, 5))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.show()# # 可选:保存为图片# wc.to_file("wordcloud.png")
结果为:
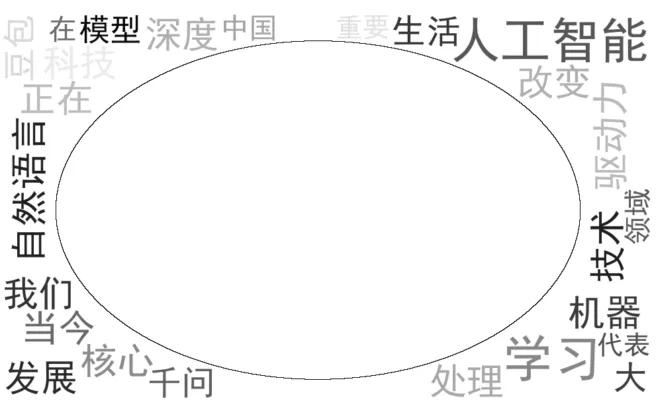
可以看到mask的原理是云词图显示在深色系(非白色)的地方
Case2.读取文档场景
我文章一开始的图就是这样画的:
from docx import Documentfrom wordcloud import WordCloudimport matplotlib.pyplot as pltimport jiebaimport numpy as npfrom PIL import Imageimport random# 读取 Word 文档doc = Document('测试文档.docx')text = '\n'.join([p.text for p in doc.paragraphs])for table in doc.tables:for row in table.rows:for cell in row.cells:text += '\n' + cell.text# 停用词列表(同前)stopwords = {# 基础中文停用词'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个','上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好','自己', '这', '那', '里', '就是', '还是', '等', '之一', '我们', '他们', '她', '它','其', '之', '与', '或', '及', '而', '以', '可', '能', '将', '会', '可以', '能够','通过', '进行', '实现', '包括', '例如', '比如', '如', '以及', '同时', '此外',# 标点符号与空白'、', ',', '。', ';', ':', '?', '!', '"', "'", '“', '”', '‘', '’', '(', ')','【', '】', '[', ']', ' ', '\n', '\t', '\r', '·', '…', '—', '-', '——',# 泛化名词(来自你的文档)'技术', '系统', '领域', '问题', '方式', '方法', '过程', '结果', '能力', '应用','方面', '部分', '情况', '数据', '信息', '内容', '概念', '工具', '模型', '任务','工作', '生活', '社会', '世界', '时代', '力量', '代表', '标志', '阶段', '时期',# 泛化动词/形容词'改变', '使用', '处理', '分析', '学习', '训练', '生成', '提供', '做出', '带来','推动', '发展', '提升', '提高', '解决', '模拟', '扩展', '延伸', '涉及', '用于','重要', '关键', '强大', '巨大', '严峻', '深刻', '当前', '未来', '目前', '近年来','常见', '广泛', '可能', '潜在', '实际', '真正', '完全', '高度', '特定', '各种',# 单字(通常无独立意义)'中', '大', '小', '高', '低', '新', '旧', '多', '少', '全', '部', '些', '种', '类','所', '被', '给', '让', '使', '把', '对', '于', '由', '从', '向', '往', '当', '并'}# 分词并过滤words = ' '.join([w for w in jieba.cut(text) if w not in stopwords and len(w.strip()) > 1])# 读取 masktry:mask = np.array(Image.open("爱心.png")) # 替换为你的图片路径except FileNotFoundError:print("未找到蒙版图片,将使用默认矩形生成词云")mask = None# 金色渐变颜色函数def golden_color_func(word, font_size, position, orientation, random_state=None, **kwargs):return f"hsl(45, 100%, {60 + random.randint(0, 30)}%)"# 生成词云wc = WordCloud(font_path='msyh.ttc',width=800,height=600,background_color='black',max_words=200,color_func=golden_color_func,mask=mask,contour_width=1,contour_color='gold',min_font_size=26, #最小字max_font_size=250, #最大字random_state=42).generate(words)# 显示plt.figure(figsize=(14, 9))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.tight_layout()plt.show()# 可选:保存# wc.to_file("golden_wordcloud.png")
结果如下,也在文章一开始放过啦~

词云图虽简单,却极具表现力。只需几行代码,就能将枯燥的文本转化为视觉焦点。掌握wordcloud,让枯燥的文字变的好看起来~
