 夜雨聆风
夜雨聆风





我把17份PDF做成了一个可持续学习系统:核心不是AI,是流程
—
最近在备战某单位的考试,其实就是公务员行测的那套题:
时政热点 / 常识判断 /言语理解与表达 / 数量关系 / 判断推理 / 资料分析
手上有大量 PDF 复习资料,看得是真头大。其实大部分人在学习时都会遇到一个问题:
资料多、信息更多,每次看都像重新开荒。
把资料打印出来不光整理麻烦,学习过程中还得自己来回标记、涂改,一来二去看着就乱。
所以我马上想到,能不能用 Codex 帮我把这批复习资料整合起来,做成一个可持续运行的系统,把“文件堆”变成“可持续运行的系统”呢?这样复习起来不仅非常便捷同时还兼顾AI对知识点和题目的理解,可以大大提高复习效率。
说干就干,当成是个项目做了。我没有一次性输入所有资料,而是人为筛选了 17 份非常重要的PDF(共746页)资料,目标是我可以持续对其迭代更新和方便查找。
先说最终结果吧:
-
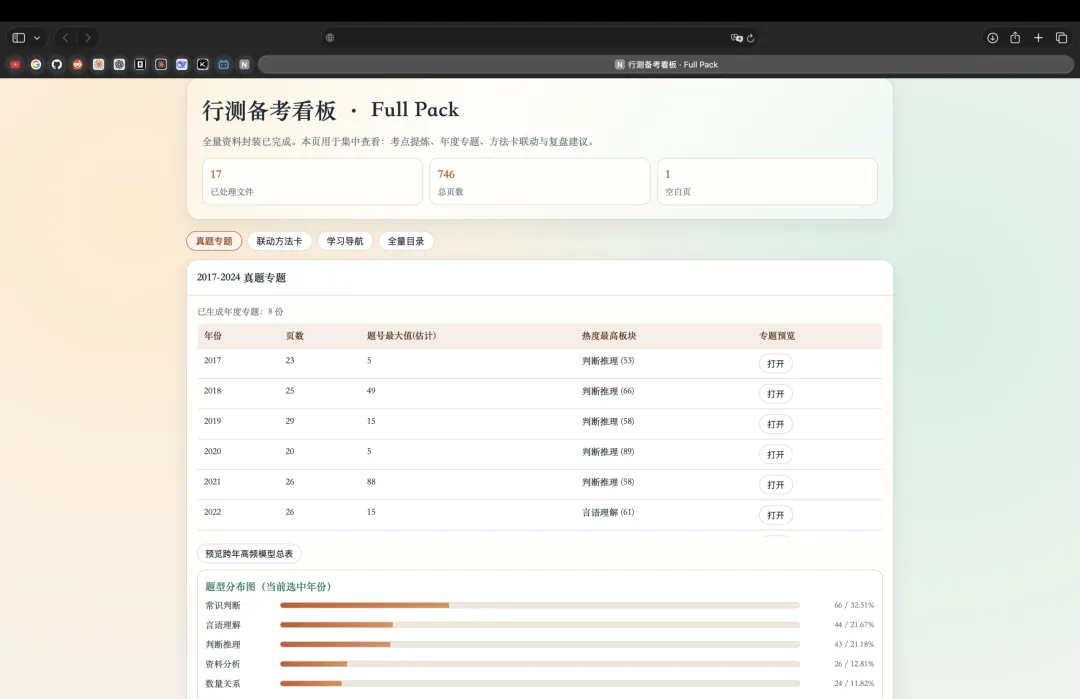
·476 道题完成结构化,结构化率 100% -
·可按年份、题号、关键词、OCR 页快速定位(OCR 页可以直接跳到 PDF 页) -
·非本地部署上线,可访问且能持续迭代更新
再说这次我最大的体会:
·当工具本身效率够高时,真正决定效率的,不再是工具,而是我们设定的可复用流程。
其实这也算是我对最近热议话题“AI会导致大量失业”的回应吧
——因为我始终认为”真正的人“是永远不会被AI取代的。
我做对的 8 步:
1.先统一目录和命名规范:
俗话说“万事开头难”,
这第一步是我认为最重要也是最难的一步,请根据个人业务场景和需求去做具体规划,
以我本次“项目”为例,我创建了主文件夹Math project,然后让 Codex 帮我处理子文件夹和命名(描述清楚我的需求)。
—
2.批量抽取文本并做质量检查:
其实就是把 PDF 转文本同时做质量检查。
这一步的本质:其实就是我上传复习资料的一个动作,你需要结合个人的具体需求给到codex一个可执行的prompt(当然别担心自己会出错,你可以随时纠正),剩下交给codex去识别和纠错,绝对懒人福音。
—
3.提炼核心考点与方法动作:
题型规律、关键考点、方法卡都提炼出来,方便复习和错题回流。
—
4.题目级结构化:
每道题整理成:题干 / 选项 / 答案 / 解析,方便筛选和快速查找。
—
5.建立错题回流:
错因 → 方法卡 → 对应题组 形成闭环,防止重复踩坑。
—
6.前端封装:
我让codex做了筛选、跳转、进度条等功能,还能通过 OCR 页快速定位 PDF 页面,让内容可点击。
—
7.本地+线上双通道发布:
优先保证本地可用,之后我再让codex上线非本地部署,方便随时更新(Netlify/GitHub)。
—
8.固化复盘机制:
建立 SOP(标准操作流程)、日志、收口清单、基线归档,每轮迭代都留痕迹,经验不会“消失”,同时开发过程中run出来的bug和各种问题也做了留档,方便下次开发相同项目时随时可以调用参考。
总结:
第3到第8步,其实都是我在推进过程中不断优化流程和 prompt,有种“顺水推舟”的感觉。
其实也是我文章的标题也是本文的核心观点:·在“项目”开始前就给出一个相对精准的需求描述(如果做不到也可以在过程中调整);·在构建你的“项目”过程中,要能识别目前“项目”完成度和“产品”是否能满足你的预期和需求,根据目前情况去不断调整你的prompt,从而实现控制和管理流程,以实现最终“项目”落地。
三条“关键”经验:
1.先结构化,再美化-数据不稳,界面再好看也不稳定;
2.先闭环,再扩展-先保证“能持续更新”,再追求“做得更大”;
3.每轮都留痕-没有日志和清单,经验会蒸发,下轮又从头踩坑。
(附上还不够完美的“产品”链接:https://murmurai.netlify.app/)
写在最后:
我认为目前我们处在新一轮“科技平权”的时代,无论你是谁,现在你都能够利用AI去做任何你曾经不敢想的事。我没有任何行业背景和经验,但我现在却利用AI创造了至少能满足我自己需求的“产品”。
所以—试试看吧,也许呢?
欢迎关注和留言,我会持续更新AI领域的内容,希望我能陪你走进属于你的“AI时代”。
