 夜雨聆风
夜雨聆风





开源高性能文档提取利器Kreuzberg:支持75+格式、OCR及Docker部署

一、简介
-
• 这是一个基于 Rust 内核的多语言文档智能框架,它可以从 PDF、Office 文档、图像以及 76 种以上的文件格式中提取文本、元数据和结构化信息 -
• 为 Rust、Python、TypeScript/Node.js、Ruby、Go、Java、C#、PHP、Elixir、R 和 C 提供原生SDK -
• 支持多种OCR驱动,包括Tesseract、PaddleOCR、EasyOCR,可通过插件 API 扩展 -
• 由 Rust 编写,高性能,内存利用高效,适用超大文档解析 -
• 部署使用方式灵活,可作为库、CLI 工具、REST API 服务器或 MCP 服务器使用,提供Docker部署方式 -
• 该工具的开源地址参考:https://github.com/kreuzberg-dev/kreuzberg -
• 该工具的整体架构概览图参考如下 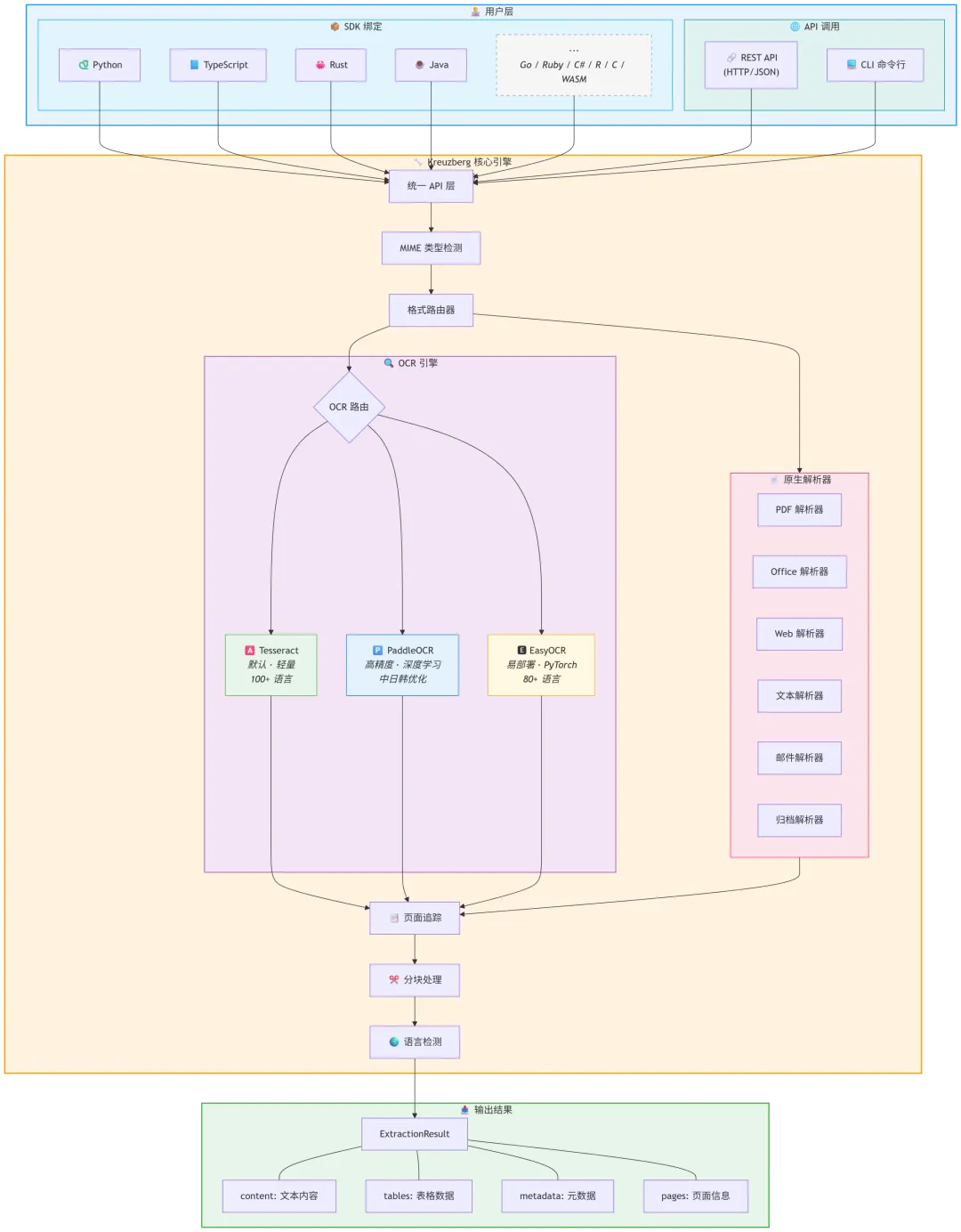
二、安装(Docker方式)
-
• 提前准备好Docker、docker-compose软件环境 -
• 新建配置文件config/kreuzberg.toml,配置内容参考如下,更多配置参考:https://docs.kreuzberg.dev/reference/configuration/
use_cache = true # 开启结果缓存(强烈推荐)enable_quality_processing = true # 是否启用质量处理(去重、修复乱码 mojibake、空白规范化等)[server]host = "0.0.0.0"port = 8000[ocr]backend = "paddle-ocr" # PaddleOCR(强烈推荐中文)language = "ch" # 简体中文(PaddleOCR 专用,效果最佳)-
• 新建docker-compose.yml配置文件,内容如下
services: kreuzberg-api: image: ghcr.io/kreuzberg-dev/kreuzberg:latest container_name: kreuzberg-api ports: - "8000:8000" environment: - KREUZBERG_MAX_UPLOAD_SIZE_MB=500 # 大文件支持(默认 100MB) - RUST_LOG=info # 日志级别 volumes: - ./config:/config:ro # 只读挂载配置 - ./cache:/app/.kreuzberg # 关键!持久化 PaddleOCR 模型缓存(首次下载后永久复用) command: - serve - --config - /config/kreuzberg.toml restart: unless-stopped healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8000/health"] interval: 30s timeout: 10s retries: 3 # 可选:资源限制(生产推荐) # deploy: # resources: # limits: # cpus: '2.0' # memory: 4G-
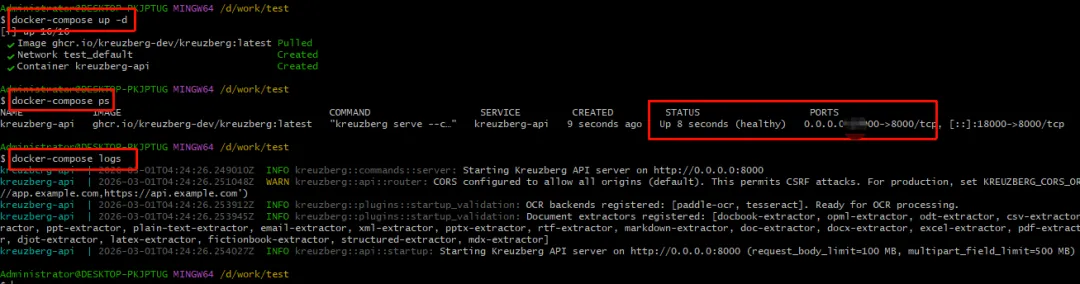
• 配置完成,执行如下命令启动即可
docker-compose up -d成功启动服务截图参考如下
三、使用
更多接口参考:https://docs.kreuzberg.dev/guides/api-server/#api-endpoints
1. 从上传的文件中提取文本内容接口
-
• 接口:POST /extract -
• 参数:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
{ "ocr": { "language": "eng" }, "force_ocr": true, "pages": { "extract_pages": true, "insert_page_markers": true, "marker_format": "\n\n=== 第 {page_num} 页 ===\n\n" }, "images": { "extract_images": true }} |
|
|
|
|
|
-
• 响应内容:
[ { "content": "提取到的文本内容...", "mime_type": "application/pdf", "metadata": { "page_count": 10, "author": "张三" }, "tables": [], "detected_languages": ["ch"], "pages": [], //多页内容 "chunks": null, "images": null, ...更多参数 }]2. 调用示例
-
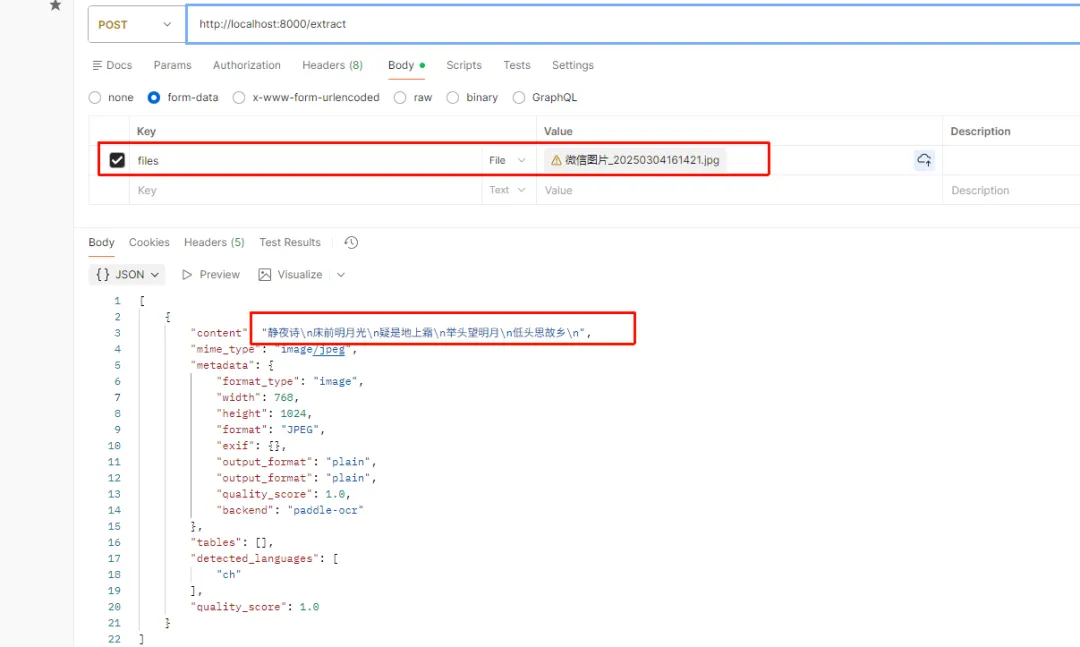
• 示例1:高效、准确的OCR能力 输入手写文字图像: 
识别结果正确
-
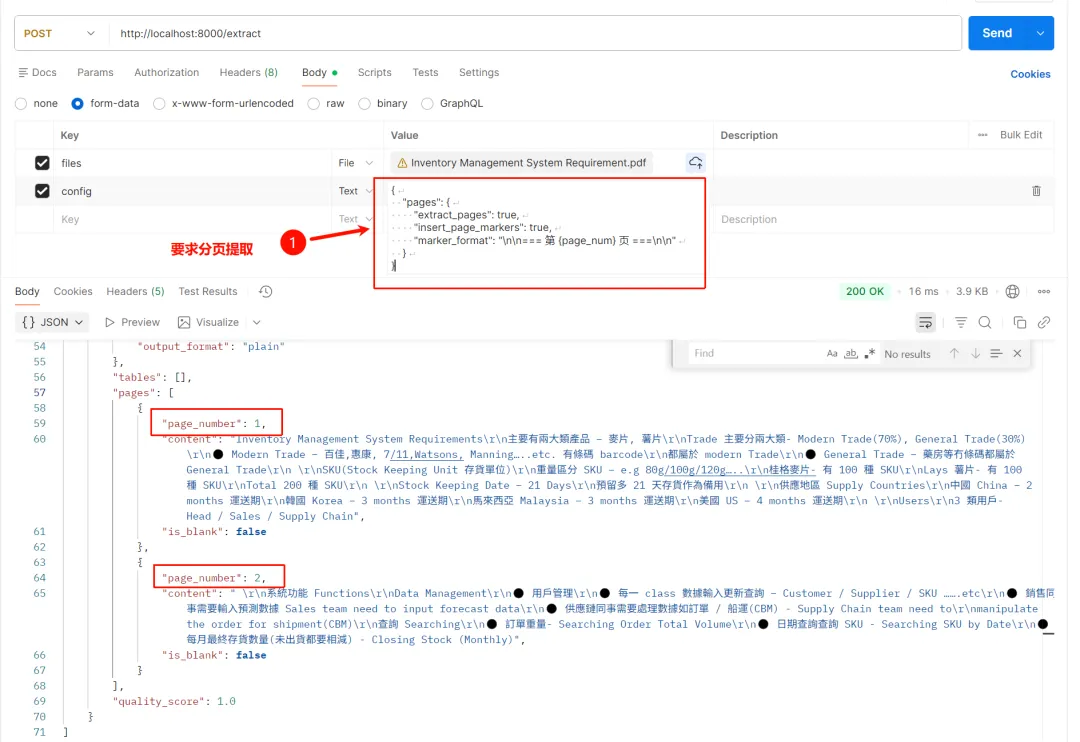
• 示例2:分页提取文档 提交一个多页的PDF文档,config字段需要配置:{“pages”: { “extract_pages”: true, “insert_page_markers”: true, “marker_format”: “\n\n= 第 {page_num} 页 =\n\n” }

准确按照分页返回提取文本
-
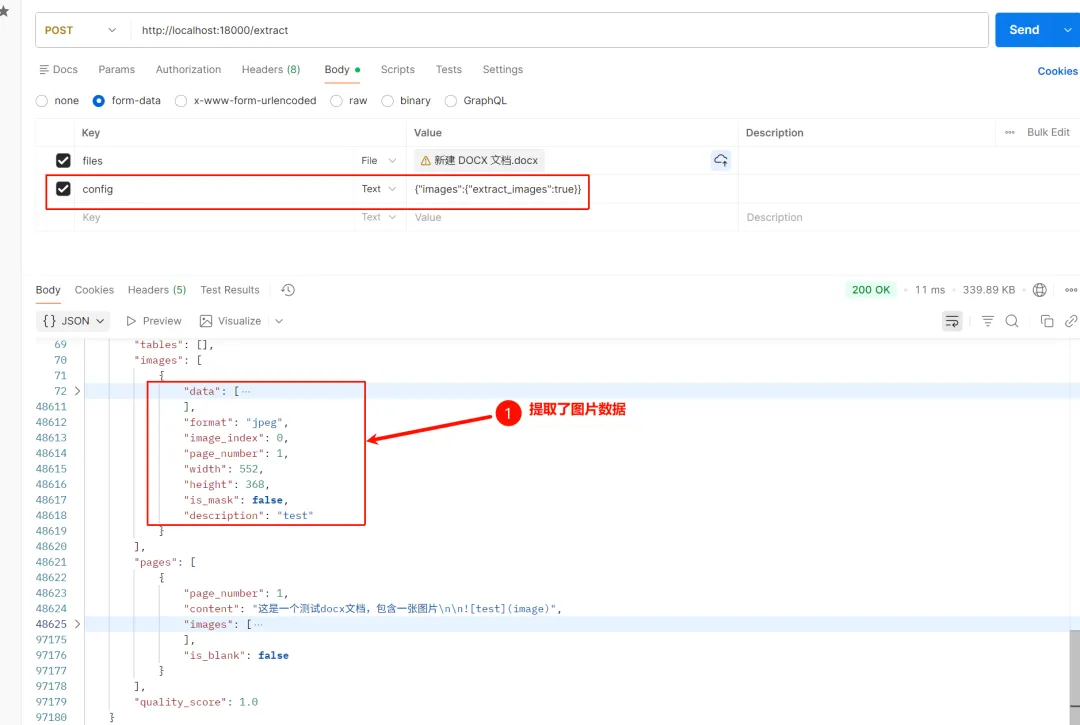
• 示例三:可以提取文档中的图片数据 提交一个包含图片的文档,config字段需要配置:{“images”:{“extract_images”:true}} 
能够提取文本和图片资源数据
-
• 更多参数应用与使用示例…(请自行探索)
四、总结
-
• Kreuzberg是一个非常不错的文档文本提取工具,支持丰富文档类型、OCR、高性能提取、易于部署与接入使用 -
• 提供了各种开发语言的SDK,另外最好的一点是支持Docker一键部署为文档提取服务,通过API集成到各种服务 -
• 特别适合配合LLM使用,提取markdown格式内容,作为知识库数据或者对话语料
 推荐一下个人网站(本文内容如有错漏只会在个人博客更新):
推荐一下个人网站(本文内容如有错漏只会在个人博客更新):
-
博客:https://blog.luler.top/d/110
-
应用:https://cas.luler.top/
-
导航站:https://nav.luler.top/
-
开源推荐:https://gitshare.luler.top/

