夜雨聆风
夜雨聆风





别再帮我总结了:OpenClaw pdf 把 PDF 变成内容流水线
💡 导读目录
📄 你有没有这种 PDF 焦虑?
🚀 OpenClaw 2026.3.2:PDF 变成”工具入口” 🎯 我把 PDF 流水线拆成 5 个固定产物 📋 复制即用的 MVT 模板 + ⚠️ 2 个必踩坑
🔧 我只改了一个配置:pdfMaxBytesMb = 50
📅 基于 OpenClaw 2026.3.2 更新 | ⏱️ 阅读约 6 分钟 | 🛠️ 附可复制模板
📄 你有没有这种 PDF 焦虑?
-
📚 行业报告、白皮书越攒越多,真要用时找不到关键结论
-
😵 看完 80 页,脑子里只剩”大概懂了”,写方案时拿不出结构和证据
-
⏳ 不是不努力,是”提炼”这一步太耗、太不稳定
👤 你对 AI 的常见指令:
💬 “帮我总结一下这份 PDF。”
🤖 AI 的回应:
[生成中…]
📄 “这是一份关于 XX 的报告,主要讲了 A、B、C 三个部分。第一部分…(一段看似完整的描述)”
😰 你的真实感受:
🤷 “好像说了很多,但我写不成文章,也落不到行动…”
⚡ “总结”是最容易产出、也最没用的一种输出。
你真正需要的不是一段话,而是一套可复用的资产:
🎯 观点 → 📐 结构 → 📊 证据 → ✅ 行动 → ⚠️ 边界
🚀 OpenClaw 2026.3.2:PDF 变成”工具入口”
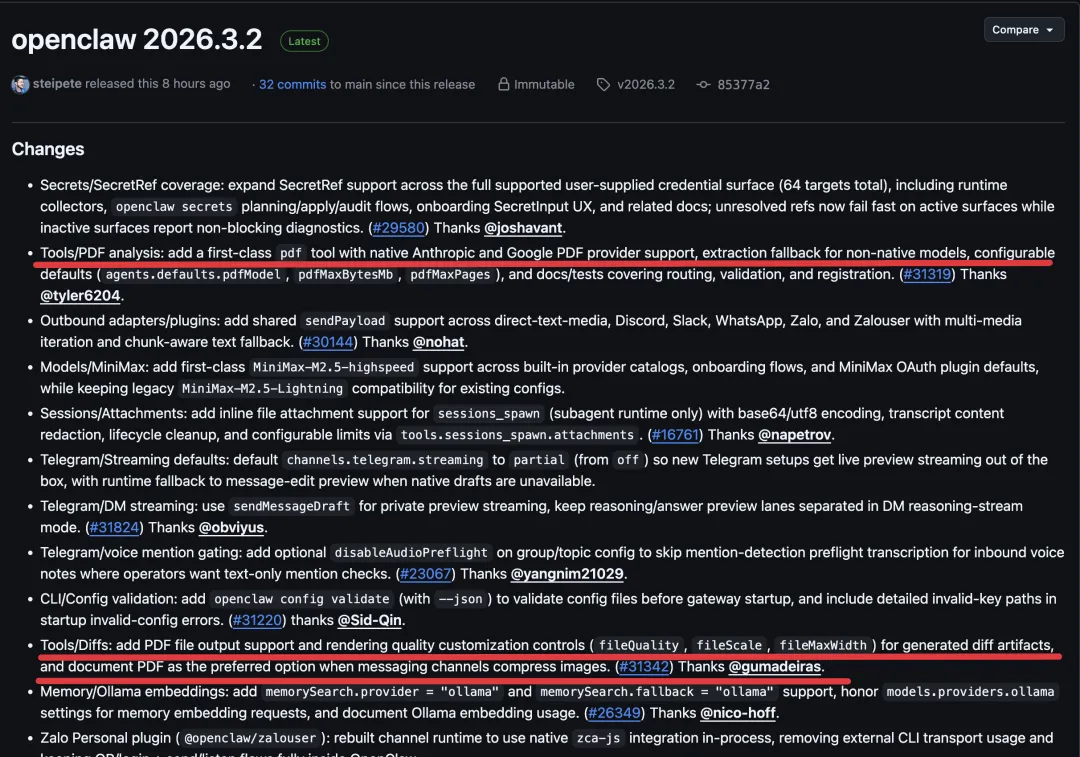
这次更新最实用的点是:新增了第一方 pdf 工具。
它的意义不是”又能读文件了”,而是把 PDF 变成了可编排的工作流入口:
🚨 小白防恐慌提示:为什么”总结”不好用?
因为”总结”产出的是”压缩后的描述”。但写作/汇报需要的是可引用的证据 + 可写的结构 + 可执行的下一步。这不是字数问题,是输出类型的问题。
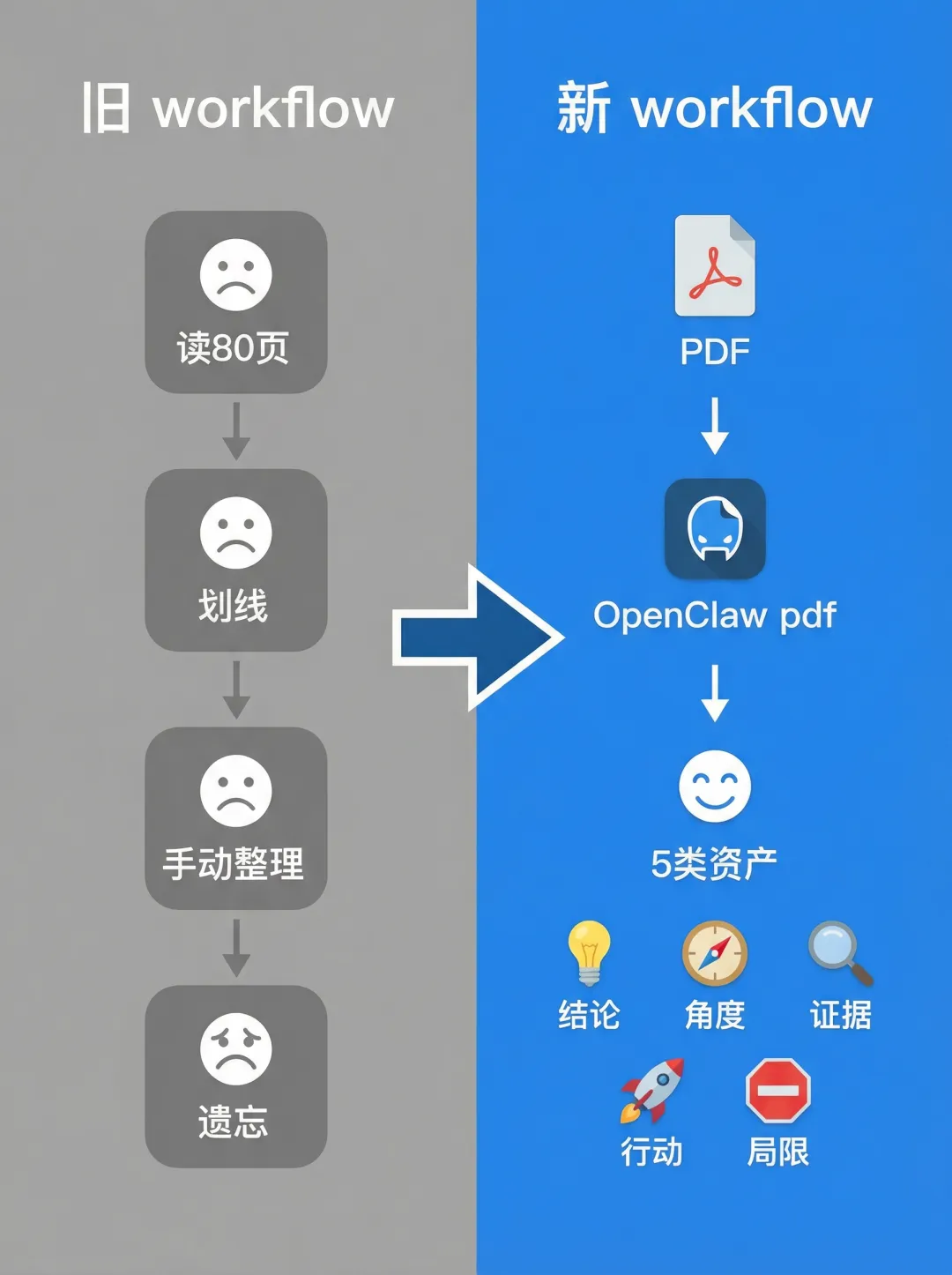
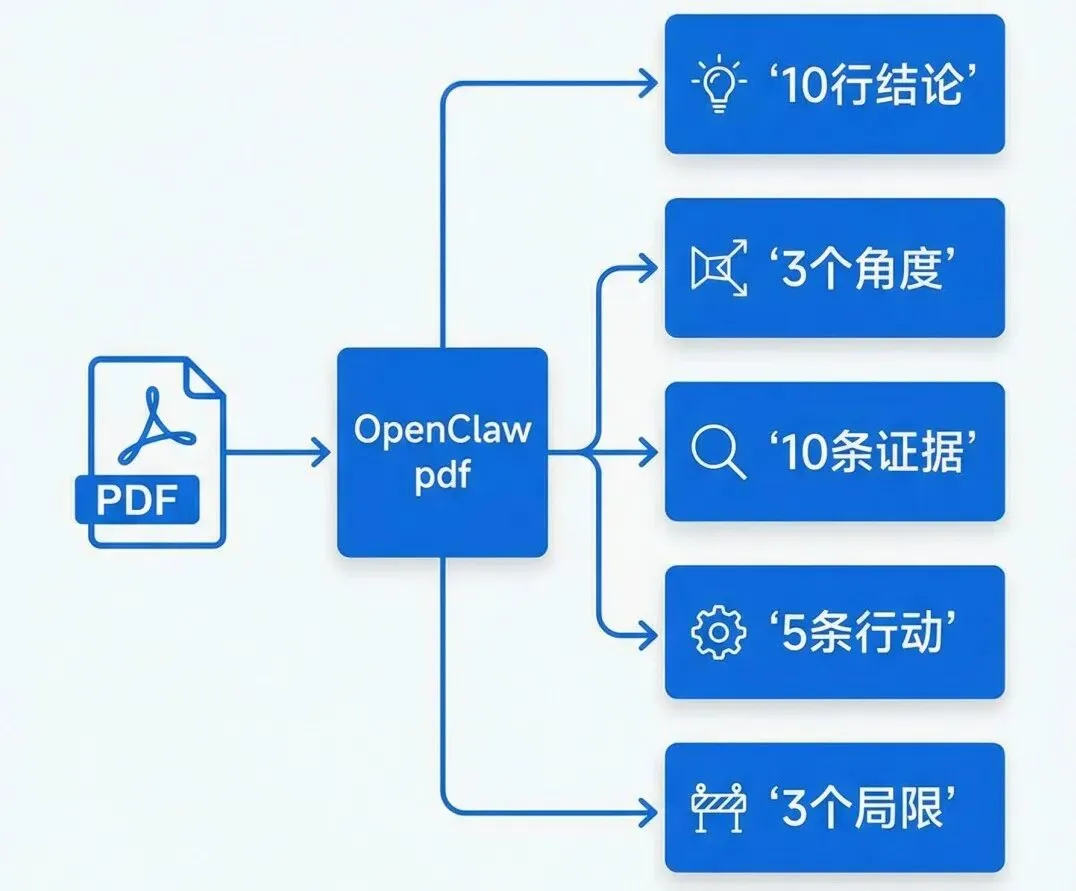
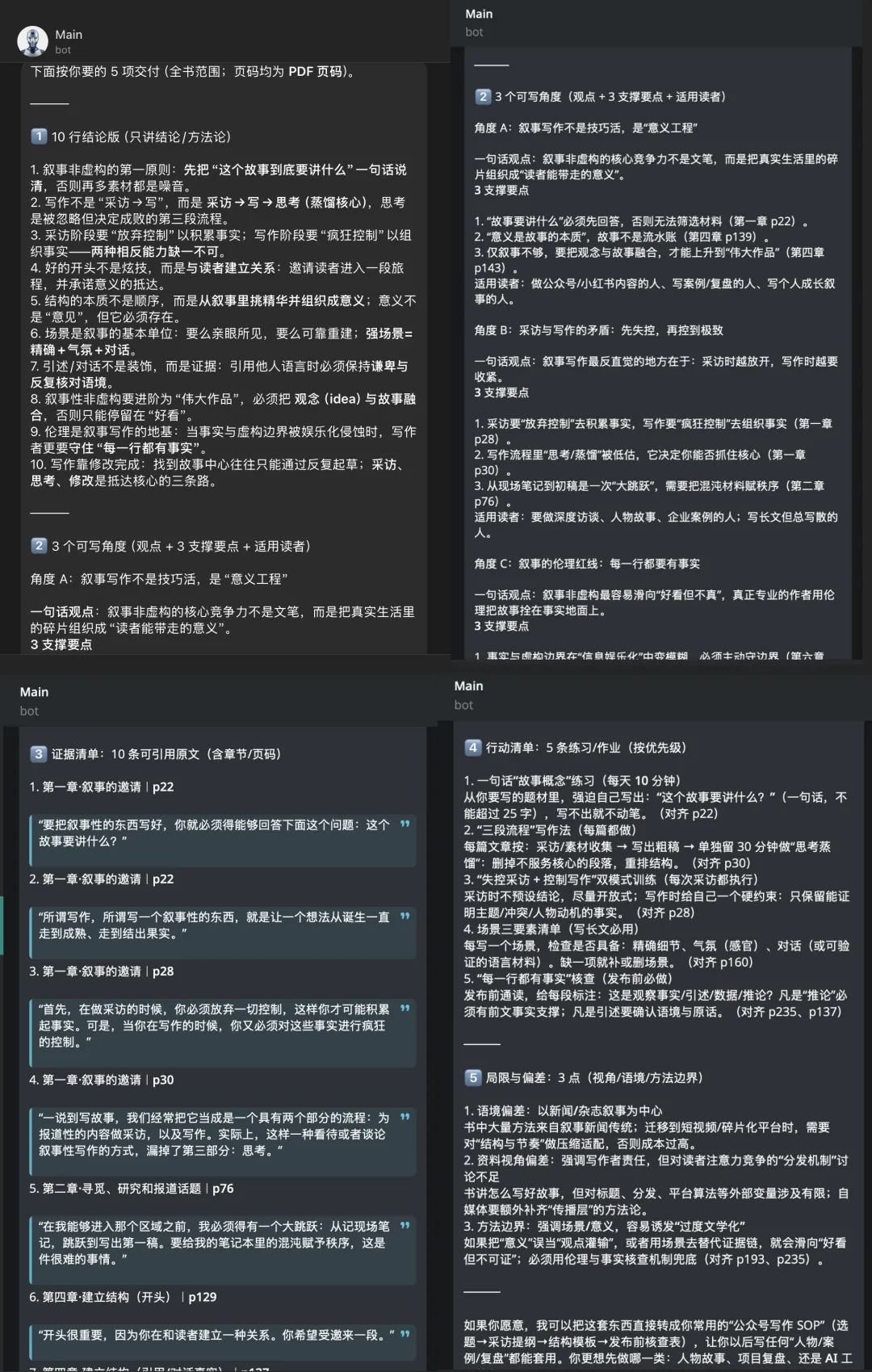
🎯 我把 PDF 流水线拆成 5 个固定产物
现在处理任何 PDF,我都强制让 AI 输出这 5 类东西:
📌 10 行结论
💡 3 个可写角度
📊 证据清单
✅ 行动清单
⚠️ 局限与偏差
🎯 这 5 类齐了,你就不可能”只停留在理解”,而是会自然走向”可产出”。
请在微信客户端打开
🔬 实测:我拿《哈佛非虚构写作课》跑了一遍
为了避免”看更新日志想象收益”,我直接拿一本完整书籍 PDF 做实验。
给 OpenClaw 的不是”总结全书”,而是上面那 5 类固定产物。结果:
🤖 输出片段(10 行结论节选):
🎤 “采访本质是加速的亲密”🎬 “结尾比开场更重要”👤 “人物靠细节立住,不靠形容词”
💡 输出片段(一个可写角度):
🏆 “失败者的更衣室永远比赢家的更衣室更有趣” —— 这句话几乎直接就是一篇文章的主轴。
✨ 我喜欢这种输出的原因:它不是”描述这本书”,而是在帮我生成写作的骨架。
📋 复制即用:MVT(最小可用模板)
👇 直接复制粘贴,以后每次丢 PDF 都用它:
MVT:PDF 拆解模板
⚠️ 两个必踩坑(来自文档,但很多人会忽略)
🚫 坑 1:原生模式不支持 pages
Anthropic/Google 原生 PDF 模式不支持 pages 参数,传了会报错。想按页抽取,走 fallback 模式。
🚫 坑 2:烂输入很难被”救回来”
扫描件、图片型 PDF、排版混乱的文档,输出稳定性会下降。先把流程跑通,再逐步优化。
🔧 我做的唯一设置:pdfMaxBytesMb = 50
为了让书籍/报告不轻易被拦截,我只改了一条默认配置:
openclaw.json
✅ 这一条很朴素:不需要每次手动传参数,大一点的 PDF 也能直接进入你的”提炼流水线”。
🎯 真正的效率提升,是”可复用的提炼方式”
OpenClaw 2026.3.2 这次更新对我最有价值的点:
📥 输入一次 → 📦 产出一整套内容资产 → 🧠 你只负责选角度和做判断
如果你也经常被报告、白皮书、课程资料淹没,建议从今天开始把”帮我总结”替换成上面的 MVT。
你会很快感受到:
⏱️ 省下来的不是阅读时间,而是”从资料到产出”的黑洞时间。
📌 一个小练习
🗂️ 找一份你最近最想读、但一直没时间读完的 PDF
📋 用 MVT 跑一遍,先拿到 5 类产物
🎯 再决定要不要精读
💬 如果你处理的 PDF 类型很固定,也可以把场景发我,我帮你把 MVT 改成更贴合的专用版。
⬇️ 扫码加作者微信 ⬇️