 夜雨聆风
夜雨聆风





Ansys Fluent文档-UDF篇:用户自定义函数概述(UDFs)(二)
大多数用户自定义函数会访问Fluent求解器中的数据。由于求解器数据是基于网格组件定义的,因此在编写UDF之前,需要了解一些基本的网格术语。
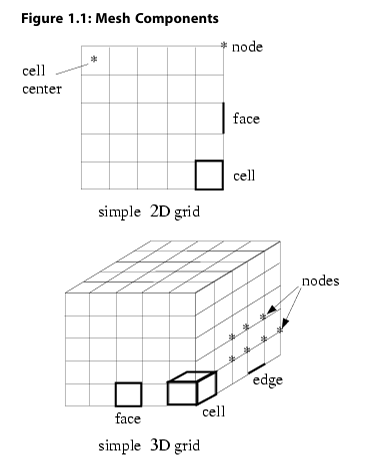
网格被划分为控制体或单元。每个单元由一组节点、一个单元中心以及包围单元的各个面所定义(图1.1:网格组件)。Fluent使用内部数据结构来定义网格的域;对网格中的单元、单元面和节点进行排序;并建立相邻单元之间的连接关系。
thread是Fluent中用于存储边界或单元区域信息的数据结构。Cell threads是单元的分组,face threads是面的分组。指向线程数据结构的指针通常被传递给函数,并在Fluent中进行操作,以访问每个线程所代表的边界或单元区域的信息。在Fluent模型的边界条件对话框中定义的每个边界或单元区域都有一个整数区域ID,该ID与区域内包含的数据相关联。在Fluent的对话框中不会看到“线程”这一术语,因此在编程UDF时,可以将“区域”视为等同于“线程”数据结构。
单元与单元面被分组为不同的区域,这些区域通常用于定义模型的物理组件(例如入口、出口、壁面、流体区域)。根据单元面是边界面还是内部面,其可能界定一个或两个单元。域是Fluent中的一种数据结构,用于存储网格中节点、面线程和单元线程集合的相关信息。
node 网格点,node thread 节点分组,edge 面(3D)的边界,face 单元(2D或3D)的边界,face thread 面的分组,cell 单元格,cell center 单元格数据存储的位置,cell thread 一组单元格,domain 节点、面和单元线程的分组。
1.6 Fluent中的数据类型
除了可以使用实数、整数等标准C和C++语言数据类型在UDF中定义数据外,还存在与求解器数据相关的Fluent特定数据类型。这些数据类型表示网格的计算单元(图1.1:网格组件)。使用这些数据类型定义的变量通常作为参数提供给DEFINE宏,以及访问Fluent求解器数据的其他特殊函数。
Fluent中一些较常用的数据类型包括:
Node 一种存储与网格点相关联的数据的结构化数据类型;
face_t 一种整数数据类型,用于识别面线程中的特定面;
cell_t 一种整数数据类型,用于识别细胞线程内的特定单元格;
Thread 一种结构数据类型,用于存储其所代表的单元组或面组共有的数据。Thread数据类型中包含一个指针数组(存储器),每个指针指向特定场变量(如压力、速度或梯度)的单元值或面值数组。在该指针数组中,用于识别指向特定场变量(单元值或面值)数组指针的索引类型为Svar。在多相流应用中,每个相以及混合物都有对应的线程结构;
Svar 用于标识Thread存储中指针的索引。该索引变量的所有可能值均列于src/storage/storage.h文件中该类型的枚举定义中。请注意,部分值是通过SV_[COUPLED_]SOLUTION_VAR[_WITH_FC](…)、SV_ UDS_I(…)或SV_UDSI_G(…)等宏生成的,因此不会在枚举中显式出现。若指针存储数组中的某个指针仍为NULL值,则表示尚未为相应场变量分配内存。可通过调用Alloc_Storage_Vars(domain, SV_…, …, SV_NULL)函数来改变此分配状态。表达式if(NULLP(THREAD_STORAGE(t, SV_…)))可用于检测特定场变量在给定线程上是否已完成内存分配;
Domain 一种结构数据类型,用于存储与网格中节点、面和单元线程集合相关的数据。在单相应用中仅存在单一域结构。在多相应用中,每个相、相间相互作用以及混合物都有对应的域结构。混合物层级的域是多相模型中的最高层级结构。
重要提示:所有Fluent数据类型都区分大小写。
在Fluent中使用UDF时,函数可以访问流体区域和边界区域中单个单元或单元面上的求解变量。UDF需要接收适当的参数,例如线程引用(即指向特定线程的指针)以及单元或面的ID,以便能够访问单个单元或面。请注意,仅凭面ID或单元ID本身并不能唯一标识面或单元。始终需要线程指针与ID配合使用,以确定面(或单元)所属的线程。
某些UDF会接收单元索引变量(c)作为参数(例如在DEFINE_PROPERTY(my_function,c,t)中),或接收面索引变量(f)(例如在DEFINE_UDS_FLUX(my_function,f,t,i)中)。若未传递单元或面索引变量(例如cell_t c, face_t f)作为参数,但UDF中需要使用时,该变量在本地声明后始终可供函数调用。
传递给UDF的数据结构(以指针形式传递)取决于使用的DEFINE宏以及试图修改的属性或项。例如,DEFINE_ADJUST UDF是通用函数,会传递一个域指针(d)(如DEFINE_ADJUST(my_function, d)中的用法)。DEFINE_PROFILE UDF则传递一个指向函数所挂钩边界区域的线程指针(t),例如DEFINE_PROFILE(my_function, thread, i)中的用法。
某些UDF(例如DEFINE_ON_DEMAND函数)不会被传递任何数据结构的指针,而其他UDF则不会获得其所需的指针。若UDF需要访问求解器未通过参数传递的线程或域指针(非directly),则需使用Fluent提供的特殊宏来获取指针。例如DEFINE_ADJUST仅被传递域指针,因此若UDF需要线程指针,则需在本地声明变量并通过Lookup_Thread特殊宏获取。例外情况是:当UDF需要线程指针来循环遍历域中所有单元线程或面线程(分别使用thread_c_loop(c,t)或thread_f_loop(f,t))且该指针未被传递给DEFINE宏时。由于UDF将循环遍历域中所有线程,无需使用Lookup_Thread获取线程指针传递给循环宏;只需在调用循环前于本地声明线程指针(及单元/面ID)。
再举一个例子,如果使用DEFINE_ON_DEMAND(该宏不传递任何指针参数)来执行异步UDF,而当UDF需要域指针时,则该函数需要在本地声明域变量并使用Get_Domain获取它。
1.7 求解过程中的UDF调用顺序
用户自定义函数(UDF)会在Fluent求解过程中的预定时间被调用。但通过DEFINE_ON_DEMAND类型的UDF,它们也可以异步(或“按需”)执行。若使用DEFINE_EXECUTE_AT_END类型的UDF,Fluent会在每次迭代结束时调用该函数;DEFINE_EXECUTE_AT_EXIT在Fluent会话结束时触发;而DEFINE_EXECUTE_ON_LOADING则在编译的UDF库被加载时调用。根据所编写UDF类型的不同,理解其在求解过程中的调用时机对于代码编写至关重要。求解器内置了与用户自定义函数关联的调用接口,掌握迭代过程中函数调用的顺序有助于确定特定时刻可用的实时数据。
(1)基于压力的分离式求解器
基于压力的分离求解器的求解过程(图1.2:基于压力的分离求解器的求解过程)始于在求解迭代循环外执行的两步初始化序列。该序列首先将方程初始化为用户通过Fluent界面输入(或默认)的数值,随后调用PROFILE UDF,接着调用INIT UDF。初始化UDF会覆盖之前设置的初始化值。
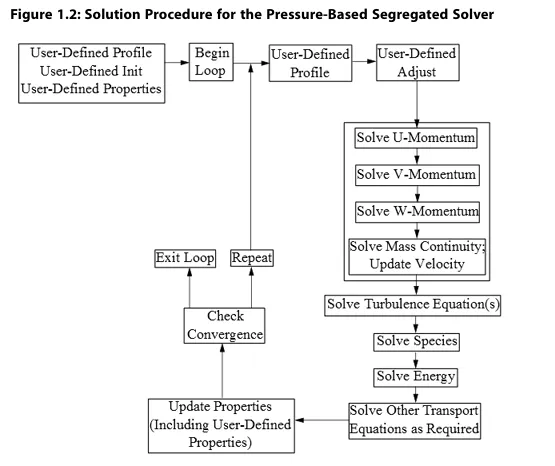
求解迭代循环从执行ADJUST UDF开始(注意仅首次迭代循环适用此规则;后续迭代循环会在ADJUST UDF之前先执行PROFILE UDF)。随后依次求解u、v、w速度的动量方程,接着进行质量连续性修正和速度更新。接下来根据需要求解能量方程与组分方程,继而求解湍流及其他标量输运方程。需要注意的是,每个变量的“求解”例程都会调用针对当前求解变量(如组分、速度)的PROFILE和SOURCE UDF。
在守恒方程之后,属性会被更新,包括属性UDF。因此,如果模型涉及气体定律,例如,此时将使用更新后的温度(以及压力和/或物种质量分数)来更新密度。系统会检查收敛性或额外请求的迭代次数,循环将相应继续或停止。
(2)基于压力的耦合求解器
基于压力的耦合求解器(图1.3:基于压力的耦合求解器求解流程)的求解过程始于在求解迭代循环外执行的两步初始化序列。该序列首先将方程初始化为用户通过Fluent界面输入(或默认)的数值,随后调用PROFILE UDF,继而调用INIT UDF。初始化UDF会覆盖先前设置的初始值。
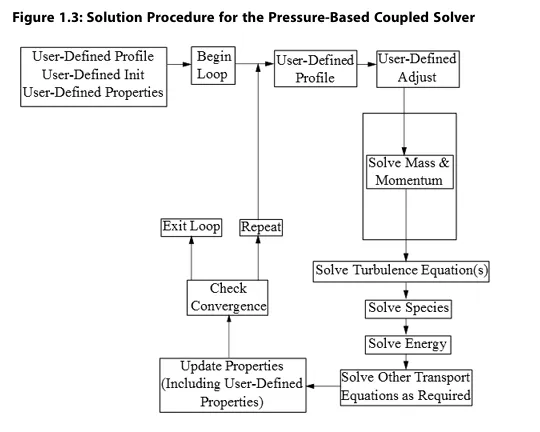
求解迭代循环从执行ADJUST UDF开始(注意仅首次迭代循环如此;后续迭代循环会在ADJUST UDF之前先执行PROFILE UDF)。接着,Fluent以耦合方式求解连续性和动量控制方程,即作为方程组或向量方程同步求解。随后按顺序求解能量、组分输运、湍流及其他所需的输运方程,剩余流程与基于压力的分离求解器相同。
(3)基于密度的求解器
与其他求解器一样,基于密度的求解器(图1.4:基于密度的求解器求解流程)的求解过程始于在求解迭代循环外执行的两步初始化序列。该序列首先将方程初始化为用户通过Fluent界面输入(或默认)的数值。随后调用PROFILE UDF,再调用INIT UDF。初始化UDF会覆盖先前设置的初始值。
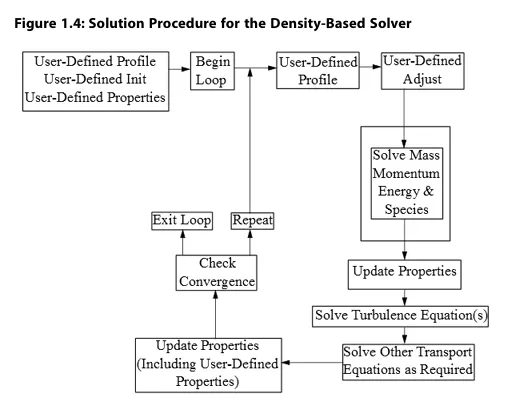
求解迭代循环从执行ADJUST UDF开始(注意仅首次迭代循环如此;后续迭代循环中,PROFILE UDF会在ADJUST UDF之前执行)。接着,Fluent以耦合方式联立求解连续性方程、动量方程、能量方程和物种输运方程,将其作为方程组或向量同步求解。随后按需顺序求解湍流方程及其他输运方程,剩余流程与基于压力的分离求解器相同。
1.8 多相流UDF的特殊注意事项
在许多情况下,为单相流编写的UDF源代码与多相流相同。例如,使用DEFINE_PROFILE定义的单相边界剖面C或C++代码与多相剖面代码并无差异——前提是该函数仅从图形用户界面所挂接的相级域中访问数据。若UDF不需要显式传递指向所需线程或域结构的指针,则需要使用专门的多相流宏(例如THREAD_SUB_THREAD)进行检索。
(1)多相特定数据类型
除了《Ansys Fluent中的数据类型》介绍的Fluent专用数据类型外,还存在专用于多相流UDF的特殊线程和域数据结构。当使用多相流模型(混合模型、VOF模型或欧拉模型)时,这些数据类型用于存储所有相混合物的属性和变量,以及每个单独相的属性和变量。
在多相应用中,顶层域被称为超域。每个相占据一个称为子域的域。引入了第三种域类型,即交互域,以便定义相互作用机制。当需要混合物的属性和变量(各相的总和)时,超域用于承载这些综合量,而子域则携带各个相的相关信息。
在单相中,混合物的概念用于表示所有物种(组分)的总和,而在多相中,它表示所有相的总和。这种区分非常重要,因为Fluent具有处理多相多组分的能力,例如,一个相可以由物种的混合物组成。
由于求解器信息存储在线程数据结构中,线程必须与超域以及每个子域相关联。也就是说,在超域中定义的每个单元或面线程,都对应着为每个子域定义的相应单元或面线程。超域线程中定义的某些信息会与各子域的对应线程共享。与超域关联的线程称为“超线程”,而与子域关联的线程称为相级线程或“子线程”。域和线程的层次结构如图1.5:域和线程结构层次所示。
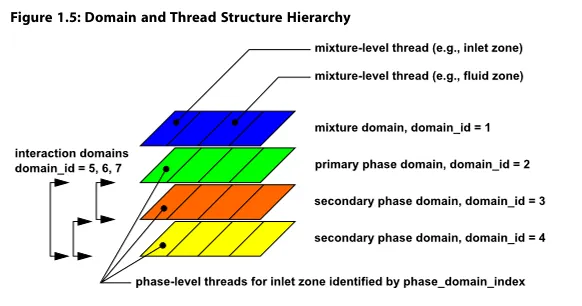
图1.5:域与线程结构层次介绍了domain_id和phase_domain_index的概念。domain_id可在UDF中用于区分超级域与主次级相级域。超级域(混合域)的domain_id始终赋值为1。交互域也通过domain_id进行标识。如图1.5:域与线程结构层次所示,domain_id元素不一定按顺序排列。
phase_domain_index可在UDF中用于区分主相位级线程和辅助相位级线程。对于主相位级线程,phase_domain_index始终被赋值为0。
传递给用户自定义函数(UDF)的数据结构取决于启用的多相流模型、待修改的属性或项、所使用的DEFINE宏以及要作用的域(混合物或相)。为了更好地理解这一点,可以考虑混合物模型与欧拉多相流模型之间的差异。在混合物模型中,求解的是混合物的单一动量方程,其属性由各相之和决定。而在欧拉模型中,则为每一相求解动量方程。Fluent允许在使用混合物模型时直接为相混合物指定动量源(使用DEFINE_SOURCE),但在欧拉模型中则不行。对于后者,可以为各相单独指定动量源。因此,多相流模型以及被UDF修改的项共同决定了需要哪个域或线程。
挂钩到相混合物上的UDF会接收超域(或混合物层级)结构,而挂钩到特定相上的函数则接收子域(或相层级)结构。DEFINE_ADJUST和DEFINE_INIT UDF固定连接至混合物层级域,其他类型的UDF则挂钩到不同的相域。
参考资料:《Ansys Fluent UDF Manual》 2023R1
CFD理论基础合集(持续更新中):
Ansys Fluent帮助文档-UDF篇:用户自定义函数概述(UDFs)(一)
特别感谢您的阅读、点赞、转发、推荐!
