 夜雨聆风
夜雨聆风





长文档问答的检索难题,SmartChunk给出了一个优雅的解法
嗨,我是PaperAGI,主要关注LLM、RAG、Agent等AI前沿技术,每天分享业界最新成果和实战案例。
当前检索增强生成(RAG)系统普遍采用静态分块策略:文档被预先切割成固定长度的片段,检索时”一视同仁”地召回。这种设计存在三大硬伤:
-
块大小敏感:大块引入冗余噪声,小块丢失上下文关联 -
检索噪声高:无关或误导性片段污染生成质量 -
扩展性差:面对海量语料时效率急剧下降
简言之,传统RAG把”分块”当作预处理步骤,却忽视了不同查询需要不同粒度信息这一本质需求。
查询感知的动态检索框架
SmartChunk提出 “规划器+压缩器” 的双模块架构,实现检索粒度的实时自适应:
1. 规划器:查询驱动的抽象层级预测
核心创新是STITCH训练方案(Solve with RL, Then Imitate To Close Holes):
-
强化学习阶段:探索最优分块策略,学习何时精读、何时跳读 -
模仿学习阶段:将探索到的行为蒸馏为稳定策略,弥补稀疏奖励的缺陷 -
循环优化:RL与SFT交替进行,解决小模型微调中的不稳定性问题
2. 轻量级压缩模块:免摘要的语义嵌入
-
无需重复调用大模型生成摘要 -
直接产出高层语义嵌入(high-level chunk embeddings) -
在保持语义完整性的同时降低计算开销
工作原理图解
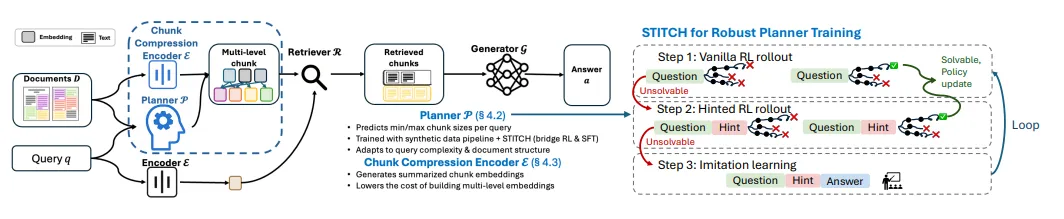
图1示意:传统RAG vs SmartChunk流程对比
-
左侧:固定分块→统一检索→生成 -
右侧:查询输入→规划器决策→动态分块→压缩检索→生成
关键机制:规划器根据查询复杂度实时判断抽象层级——简单查询粗粒度检索,复杂查询细粒度深挖,实现”该粗则粗,该细则细”。
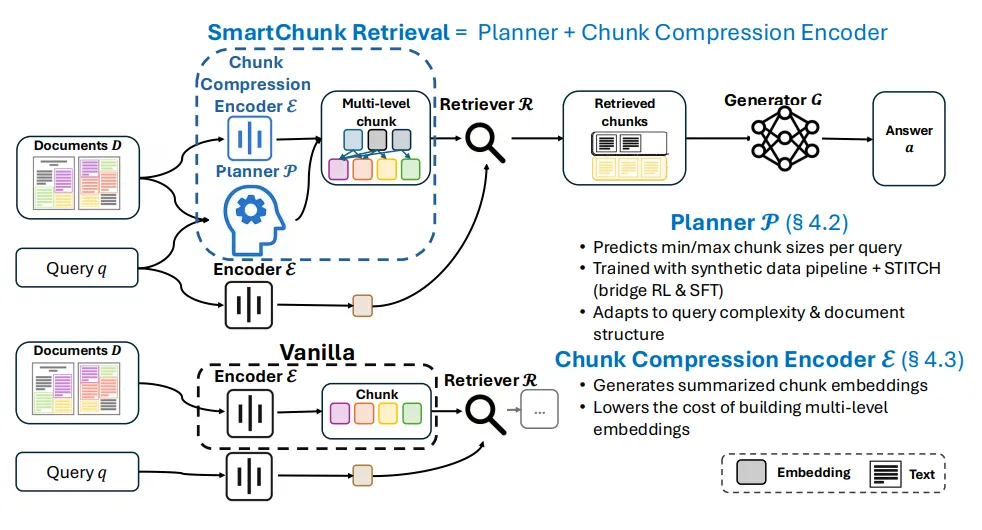
实验结果:性能与成本的双赢
在5个QA基准测试+1个跨域数据集上的验证显示:
|
|
|
|---|---|
| 准确性 |
|
| 成本效率 |
|
| 扩展性 |
|
| 泛化性 |
|
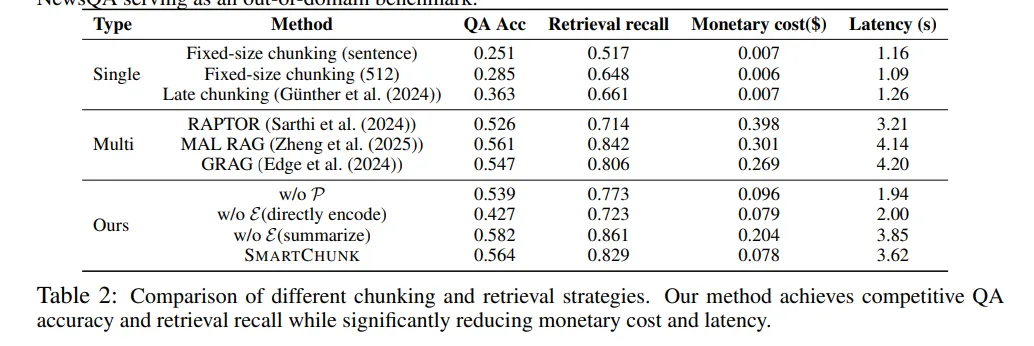
特别值得注意的是,STITCH方案在小模型后训练场景下展现出超越GRPO等传统方法的稳定性,证明”推理信息获取”本身是一个可学习的规划问题。
核心启示
SmartChunk的价值不仅在于技术改进,更在于范式转变:
-
从”系统优化”转向”学习优化”:RAG效率不仅是工程问题,更是推理学习问题 -
从”静态配置”转向”动态决策”:让模型自主决定如何阅读,而非人工预设规则 -
从”端到端生成”转向”元认知规划”:训练模型思考”该读什么”,而非仅思考”答案是什么”
一句话总结:SmartChunk让RAG系统拥有了”按需阅读”的智能,通过强化学习驱动的规划器动态调整检索策略,在准确性与效率之间找到最优平衡。
SmartChunk Retrieval: Query-Aware Chunk Compression with Planning for Efficient Document RAGhttps://arxiv.org/pdf/2602.22225