 夜雨聆风
夜雨聆风





干货分享|快速构建第一个 A2A应用1
在学习智能体应用开发的过程中,动手搭建实验环境并练习编写简单示例代码至关重要。这不仅能帮助学习者更好地理解理论知识,也能加速将概念转化为实际技能的过程。本章将深入讲解实践本书所有案例所必需的软件,包括提供大模型服务的Ollama和用于管理Python虚拟环境的Miniconda1。为了帮助读者快速入门A2A,本文将通过一个极简但涵盖A2A基本元素的案例,讲解构建最小A2A应用的完成流程。
一、开发环境全栈指南
为了简化实验环境,本书选用了读者最易获取的系统和工具,操作系统采用Windows,即使在未配备GPU的计算机上,也能够完整实践本书的全部内容。由于A2A的核心目标是打通Agent之间的交流通道,而Agent本身是一种基于大模型的应用形式,因此需要搭建能够提供文本生成功能的大模型服务。
A2A-SDK与相关生态提供了多种语言的实现。为了降低学习成本,本书统一选用Python语言作为所有案例的开发语言,避免跨语言示例造成知识分散,从而影响读者对A2A本身的理解。这一选择的另一个好处是:Python简洁优雅,示例代码通常不超过60行。本书提供完整、可直接运行的示例代码,读者无须在阅读本书与查阅外部网站之间来回切换,从而保持专注。
在操作系统上直接安装Python来运行AI应用并不是理想做法,因为不同应用往往依赖不同版本的Python或多个应用所使用的依赖包之间存在冲突。为此,本书采用Miniconda,通过虚拟化方式为各章创建自成体系、相互隔离的Python运行环境。下图展示了本书实践部分所使用的开发环境技术栈的概览。
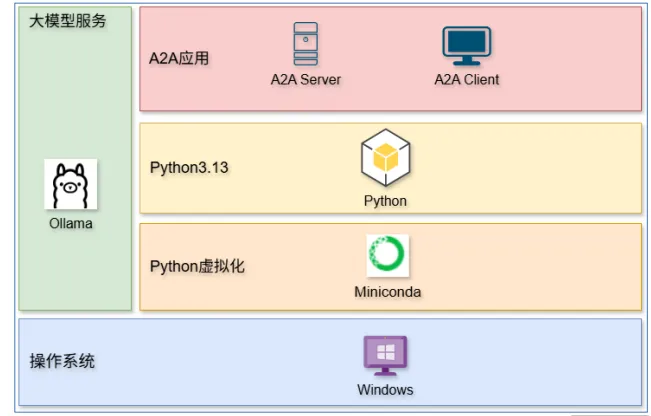
1.1 操作系统要求
本书选用Windows作为实践环境的操作系统,主要目的是降低读者的上手门槛。对大多数开发者来说,Windows是最易获得、最普及的操作系统。如果读者仅拥有一台只安装了Windows的笔记本电脑,也完全能够运行本书所有章节的案例。无论是在个人学习设备还是企业内部的开发工作站上,Windows系统都具有广泛的适用性,能够满足不同场景下的开发需求,为后续的大模型服务搭建、Python虚拟环境管理等任务提供稳定的平台支撑。此外,Windows丰富的图形化界面与便捷的操作方式,有助于开发者更直观地进行环境配置和故障排查,从而降低因系统操作复杂度而带来的
学习成本。
1.2 大模型服务要求
本书选用Ollama作为大模型服务的提供工具,同样是基于降低实践难度的考虑。许多读者可能并不具备GPU算力资源,而Ollama能够在CPU环境下加载大模型权重,并提供标准的OpenAI Chat兼容接口,为Agent提供文本生成服务。考虑到许多Agent需要使用大模型的Function-Calling特性,以实现主动调用工具的能力,本书在模型的选择上采用通义千问的Qwen3系列作为推理模型,因为它们完整支持Function-Calling特性。然而,需要特别指出的是,Ollama加载的是INT4量化版本的模型,其精度仅为GPU上运行的原始半精度(FP16)模型的1/4。以Qwen3为例,INT4数据类型用-8~+7的16个整数表达原始模型的81.9亿参数,即使结合了优化的缩放算法,精度损失带来的生成质量下降仍然十分明显。
因此,基于Ollama的模型仅适合作为开发环境下“可用但受限”的推理支撑,用于程序调试并无问题,但不适用于大多数生产级场景。
需要说明的是,选用Qwen3主要是为了保持全书案例的一致性与描述便利。实际上,只要所选模型支持Function-Calling功能,即可作为本书示例的底层推理模型,且更换模型在安装配置和代码适配方面都非常简单。
1.3 Python 虚拟化环境
直接用操作系统中全局安装的Python来运行AI程序,仅适用于功能简单、场景单一的应用。当在同一台机器上运行多个Python项目时,各类环境冲突问题出现的概率将显著增加。本书的技术栈选择在操作系统和Python运行环境之间增加一层虚拟化的中间层,目的在于减少读者在调试书中源代码时遇到的Python版本冲突、各章案例依赖库冲突等问题。
1. 虚拟化的必要性
目前常用的Python版本范围为3.7至3.13。虽然新版本通常兼容旧版本,但版本跨度较大时,依然可能出现兼容性问题。即使是相邻版本,如3.12和3.13,也可能导致某些依赖库无法正常运行。例如,在A2A-Python中就存在依赖Python特定版本的情况:Python 3.13为asyncio.Queue新增了shutdown()方法,提供非阻塞的队列关闭方式,可避免潜在的死锁问题。因此,建议根据项目需求选择适配的Python版本,而非盲目追求最新版本。
简单项目的依赖库较少,项目的依赖库数量会随着项目复杂度的提升而增加。即便项目看似只依赖一个库,该库本身可能依赖多个第三方库,而这些依赖在版本更新时不一定保持向后兼容。如果项目中未明确指定依赖库的版本,或仅指定了最小兼容版本,随着时间推移,新版本可能由于移除了某些方法、修改函数入参个数、升级内部依赖等原因,导致项目无法正常运行。在大模型应用中,Transformers、PyTorch、NumPy等库更新频繁,版本不兼容问题更是常见。同一台机器上的多个应用往往对某些库的版本要求不同,由此引发的冲突也相对较多,而使用Python虚拟环境可以实现项目间的隔离,是解决此类问题的最佳方式。
除了解决Python环境的冲突问题外,Python虚拟化还能为每个项目创建独立的运行空间,使项目的依赖管理更加清晰、高效。开发者可以针对不同项目分别安装所需的库及其对应版本,而无须担心影响其他项目。本书将为每一章创建独立的虚拟环境,用于管理依赖关系。当需要将项目迁移到其他机器时,只需导出虚拟环境的依赖配置文件,即可在目标机器上快速重建相同的开发环境。这不仅降低了环境配置的复杂度,也大幅减少了时间成本。
2. 虚拟化工具的选择
Python的虚拟化方案包括Anaconda、Poetry、venv和uv等多种工具。本书在进行技术选型时,综合考虑了安装便利性、镜像生态完善程度以及适用场景等因素,最终选择了Anaconda的精简版本——Miniconda。下面简要说明未选用其他方案的原因。
Poetry是一款功能强大的Python虚拟化环境和依赖管理工具,尤其擅长处理复杂的库依赖关系,但它的国内镜像资源相对较少,安装和拉取依赖时可能不够顺畅。
venv是Python内置的虚拟化工具,不选择venv的主要原因是它依赖系统中已有的Python,需要安装Python后才能创建环境。从“在Python里再安装一个用于隔离的Python环境”的操作逻辑来看,多少显得有些别扭。
uv是一个轻量、绿色且功能强大的工具,只需一个uv.exe即可运行。但它的不足在于每执行一条命令都需要加上“uv run”前缀,使用体验更像在执行uv的命令,而非直接操作Python。对初学者而言稍显麻烦。uv更适合MCP等自动化场景,因为此类场景下调用程序的命令通常由MCP Host程序发起,而非人工输入。
需要说明的是,最终选择Miniconda也有笔者个人习惯的因素。实际上,上述所有工具都能够满足本书的实践需求,并可用于生产环境。
Miniconda直接安装在操作系统中,不依赖系统自带的Python。通过Miniconda创建的虚拟环境与当前工作目录无关;使用时只需分清当前终端提示符位于哪一个环境(非虚拟环境的命令提示符前一般会显示base字样),即可在任意目录执行pip、python等命令。由Miniconda创建的虚拟环境对应用具有良好的隔离效果,如下图所示。

二、实验环境安装与配置
本书的实验环境设计充分考虑了读者的资源易获得性与操作便捷性,因此未采用需要 GPU 才能运行的高精度大模型方案,而是选择了能够运行量化模型、满足 Agent 调试要求的 Ollama 平台。此外,为了隔离每章的 Python 依赖环境,还需安装 Miniconda。
2.1 Ollama 安装与配置
Windows版的Ollama安装程序可从Ollama的官方网站下载。下载的安装包为OllamaSetup.exe。如果下载时遇到困难,可使用镜像站点https://aliendao.cn/ollama#。
运行OllamaSetup.exe,保持默认选项即可完成安装。安装完成后,为减少对C盘空间的占用,可将操作系统的环境变量OLLAMA_MODELS设置为其他磁盘路径,使新下载的模型存放在指定目录而非默认的C盘。
若需要让其他机器访问本机的Ollama服务,可将环境变量OLLAMA_HOST设置为“0.0.0.0”,而非默认仅允许本地访问的127.0.0.1:11434。需要注意,这样会带来暴露服务端口的安全风险,应谨慎设置。
另外,Ollama在Windows中以系统服务的方式运行,因此修改环境变量后需要重启Ollama服务。
在Windows命令行下,可通过以下命令从Ollama官网拉取Qwen3模型并将模型加载到内存进行推理测试:
# 拉取模型ollama pull qwen3# 运行模型ollama run qwen3
ollama run会启动交互方式推理,用户输入问题后模型将返回生成结果,如下图所示。

需要说明的是,ollama run命令可自动拉取镜像,在对外提供生成式API服务时,并不需要手动执行该命令。Ollama的后台服务会根据API调用自动加载模型并完成推理。
2.2 Miniconda 的安装与验证
Miniconda可从Anaconda的官网下载。运行下载的Miniconda3-latest-Windows-x86_64.exe,按默认选项完成安装。建议将Miniconda安装目录中的Scripts子目录添加到操作系统环境变量Path中,以便于在执行conda命令时,操作系统能正确找到conda.exe。
安装完成后,可通过conda -V命令来验证安装,若执行结果显示出Miniconda的版本号,则说明安装成功。
三、入门案例场景设计
本章的入门案例旨在完成一个极简但具有代表性的任务:构建一个能够获取当前时间的Agent,并将其封装为一个A2A Server。当A2A Client发送请求时,该Server能准确返回当前的日期和时间。虽然场景非常简单,却涵盖了A2A应用开发中的核心要素,包括清晰的服务接口定义、规范的消息格式封装以及客户端与服务端的通信交互流程设计等,有助于读者直观理解A2A协议在实际应用中的基本运作机制。
通过这个案例,读者可以快速掌握如何基于现有技术栈搭建一个可运行的A2A应用框架,为后续学习更复杂的多Agent协作、状态管理等扩展功能奠定基础。
乍看之下,“获取当前时间”是一个极其简单的功能,但在实际应用中却具有重要意义。例如,在基于大模型的聊天应用中,如果不借助外部工具,仅依靠大模型自身的生成能力,无法获取与“当前时刻”相关的信息。当用户询问“历史上的今天”之类的问题时,模型并不知道“今天”究竟是哪一天,因而无法生成相应的答案。
在Agent应用中,这类任务通常依赖大模型的Function-Calling功能,由模型调用Agent内部提供的工具来获取当前时间。工具返回的时间信息会写入Agent与大模型的上下文,从而使大模型能够正确理解“当前时间”,进而生成与当前时间相关的内容。
在A2A应用中,通信双方均为Agent。如果某个Agent需要借助大模型完成特定功能,而这些功能又依赖当前时间,那么自然需要通过专门的时间获取工具来确保功能的正确实现。本章的案例正是为这一类场景提供基础模式与实现思路。
四、架构与核心组件
本例遵循A2A模式下的典型Client/Server架构。A2A的设计哲学强调“公开细节以换取更高的灵活性”,这一理念在A2A Server所暴露的大量技术细节中体现得尤为明显。
一个典型的A2A Server通常由以下核心组件构成:用于描述服务能力的Agent Card定义、负责接收客户端请求的HTTP Server、代表传输协议并处理消息格式的A2A Application、维护长生命周期状态并进行请求分发的RequestHandler、负责任务数据持久化的TaskStore、调度并执行Agent的AgentExecutor,以及实现具体业务逻辑的Agent。A2A Client则封装在一个Client对象中。Client会从A2A Server获取Agent Card的内容,形成调用所需的技术参数,随后向A2A Server发送消息,并处理服务端返回的推送响应。整体架构如下图所示。
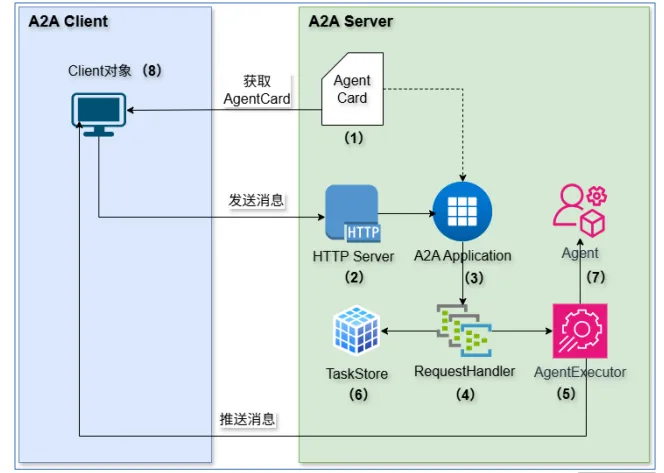
4.1 Agent Card 服务能力描述
Agent Card是A2A中用于描述Agent服务能力的核心元数据,相当于一份标准化的服务说明书。它详细定义了Agent所提供服务的接口信息、功能描述、参数规范、返回结果格式以及通信协议要求等关键内容。借助Agent Card,A2A Client能够清晰了解Server端Agent的能力范围,包括支持的功能及其调用举例等。通过此类标准化定义,Client可根据自身需求准确选择并调用Server端的服务,而无须关心Server内部复杂的实现逻辑。
4.2 HTTP Server 通信通道的实现
A2A支持JSON-RPC 2.0、HTTP+JSON/REST和gRPC三种通道,其中前两种基于HTTP Server监听客户端请求。在实际部署中,HTTP Server需要应对高并发访问,因此在架构上采用异步处理机制。系统使用基于Starlette1构建的FastAPI2框架作为HTTP服务基础,可高效支持异步请求处理,从而显著提升服务吞吐量。
4.3 A2A Application HTTP 服务载体
A2A Application是A2A在HTTP服务层面的具体实现载体,继承自Starlette的Application类,负责将A2A规范与HTTP通信机制融合。其主要职责包括:
对A2A消息格式进行解析和封装。
完成请求的路由分发。
与后续的RequestHandler组件衔接。
当HTTP Server接收到客户端发送的请求后,会先将原始数据交由A2A Application处理。A2AApplication会按照A2A定义的消息结构解码请求,提取关键信息,如目标服务标识与调用参数等,再依据路由规则将处理后的请求分发至对应的RequestHandler。在生成响应时,A2A Application会按A2A协议要求封装业务处理结果,确保客户端能够正确解析与理解响应内容。
4.4 RequestHandler 的分发职责
RequestHandler是A2A Server中负责请求分发与长状态(stateful)管理的核心组件。其主要职责包括:
接收A2A Application传递的请求。
根据服务标识和参数信息匹配相应业务逻辑。
管理请求过程中的长状态数据。
在处理请求时,RequestHandler会首先校验请求的合法性,例如参数完整性与格式规范性。校验通过后,将请求根据路由映射关系分发给对应的业务处理单元(如对应的Agent执行器)。对于需要保持会话状态的场景(如多轮交互),RequestHandler会通过内置的状态管理机制记录每个请求的上下文信息,确保后续请求能够基于历史交互数据进行准确处理,避免因状态丢失导致业务逻辑中断。
4.5 TaskStore 持久化方案
TaskStore是A2A Server中用于任务数据持久化存储与管理的组件,主要负责保存任务的执行状态、历史记录及上下文信息等。它为RequestHandler的长状态管理和AgentExecutor的任务调度提供持久的上下文关联数据支持。TaskStore常见的实现方式包括数据库或内存存储。具体选型需根据业务场景的性能要求、数据规模和持久化需求综合确定。
4.6 AgentExecutor 调度者角色
AgentExecutor是A2A Server中负责调度并执行Agent任务的核心执行组件。它在接收来自RequestHandler分发的业务请求后,会根据请求的具体内容和参数调用对应的Agent实例来完成实际的业务逻辑处理。
在执行过程中,AgentExecutor需要实时监控Agent的运行状态,包括任务启动、执行进度跟踪、异常捕获与任务取消等。同时,AgentExecutor会与TaskStore进行交互,在任务执行的关键节点将相关的任务数据持久化存储到TaskStore中,以便后续进行任务追踪与审计。
4.7 Agent 具体业务实现
Agent是A2A应用中的业务实现组件,直接承载了具体的业务逻辑和功能。Agent通常基于相应的Agent框架开发,如LangGraph、CrewAI、Semantic Kernel等。这些框架应用大语言模型的生成能力、多种角色协同、提示词工程以及工作流等技术开发Agent应用。在通过A2A协议与其他Agent整合时,Agent需要对外公开可调用接口,并交由AgentExecutor负责统一调度与执行。
4.8 Client 请求发起方的职能
在A2A模式的Client/Server架构中,Client作为发起服务请求的一方,其核心功能在于与Server建立稳定的通信连接,并按照A2A规范完成完整的服务调用流程。当Client需要调用Server提供的服务时,应首先获取Server的Agent Card信息,然后构造请求消息,并通过通信通道(如HTTP或gRPC)将请求发送至Server指定端口,随后接收返回结果。这个过程通常以异步方式执行。此外,Client还需维护与Server的会话状态,尤其在多轮交互场景中,要确保上下文信息的连续性,使Server能够基于历史交互数据正确理解后续请求。
快速构建第一个 A2A应用1结束啦!后续文章更精彩,关注后不迷路!

本文摘自《构建自主AI:深入A2A协议的智能体开发》,具体内容请以书籍为准。
