 夜雨聆风
夜雨聆风





【统计知识】今天这篇文章真的把假设检验说明白了
假设检验和参数估计是统计推断的两个重要领域。
假设检验的定义
假设检验:先对总体参数提出某种假设,然后利用样本数据判断假设是否成立。在逻辑上,假设检验采用了反证法,即先提出假设,再通过适当的统计学方法证明这个假设基本不可能是真的。(说“基本”是因为统计得出的结果来自于随机样本,结论不可能是绝对的,所以我们只能根据概率上的一些依据进行相关的判断。)
假设检验依据的是小概率思想,即小概率事件在一次试验中基本上不会发生。
如果样本数据拒绝该假设,那么我们说该假设检验结果具有统计显著性。一项检验结果在统计上是“显著的”,意思是指样本和总体之间的差别不是由于抽样误差或偶然而造成的。
假设检验的术语
零假设(null hypothesis):是试验者想收集证据予以反对的假设,也称为原假设,通常记为 H0。例如:零假设是测试版本的指标均值小于等于原始版本的指标均值。
备择假设(alternative hypothesis):是试验者想收集证据予以支持的假设,通常记为H1或 Ha。例如:备择假设是测试版本的指标均值大于原始版本的指标均值。
双尾检验(two-tailed test):如果备择假设没有特定的方向性,并含有符号“≠”,这样的检验称为双尾检验。例如:零假设是测试版本的指标均值等于原始版本的指标均值,备择假设是测试版本的指标均值不等于原始版本的指标均值。
单尾检验(one-tailed test):如果备择假设具有特定的方向性,并含有符号 “>” 或 “<” ,这样的检验称为单尾检验。单尾检验分为左尾(lower tail)和右尾(upper tail)。例如:零假设是测试版本的指标均值小于等于原始版本的指标均值,备择假设是测试版本的指标均值大于原始版本的指标均值。
检验统计量(test statistic):用于假设检验计算的统计量。例如:Z值、t值、F值、卡方值。
显著性水平(level of significance):当零假设为真时,错误拒绝零假设的临界概率,即犯第一类错误的最大概率,用α表示。例如:在5%的显著性水平下,样本数据拒绝原假设。
置信度(confidence level):置信区间包含总体参数的确信程度,即1-α。例如:95%的置信度表明有95%的确信度相信置信区间包含总体参数(假设进行100次抽样,有95次计算出的置信区间包含总体参数)。
置信区间(confidence interval):包含总体参数的随机区间。
功效(power):正确拒绝零假设的概率,即1-β。当检验结果是不能拒绝零假设,人们又需要进行决策时,需要关注功效。功效越大,犯第二类错误的可能性越小。
临界值(critical value):与检验统计量的具体值进行比较的值。是在概率密度分布图上的分位数。这个分位数在实际计算中比较麻烦,它需要对数据分布的密度函数积分来获得。
临界区域(critical region):拒绝原假设的检验统计量的取值范围,也称为拒绝域(rejection region),是由一组临界值组成的区域。如果检验统计量在拒绝域内,那么我们拒绝原假设。
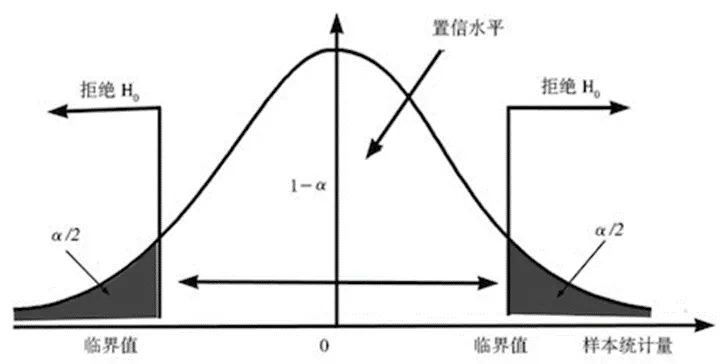
p值(p-value):在零假设为真时所得到的样本观察结果或获得更极端结果的概率。也可以说,p值是当原假设为真时,错误拒绝原假设的实际概率。左尾检验的P值为检验统计量x小于样本统计值C的概率,即:p = P( x < C) 右尾检验的P值为检验统计量x大于样本统计值C的概率,即:p = P( x > C)双尾检验的P值为检验统计量x落在样本统计值C为端点的尾部区域内的概率的2倍,即:p = 2P( x > C) (当C位于分布曲线的右端时) 或p = 2P( X< C) (当C 位于分布曲线的左端时) 。
效应量(effect size):样本间差异或相关程度的量化指标。效应量越大,两组平均数离得越远,差异越大。如果结果具有统计显著性,那么有必要报告效应量的大小。效应量太小,意味着即使结果有统计显著性,也缺乏实用价值。
假设检验的两类错误
第 I 类错误(弃真错误):零假设为真时错误地拒绝了零假设。犯第 I 类错误的最大概率记为 α(alpha)。第 II 类错误(取伪错误):零假设为假时错误地接受了零假设。犯第 II 类错误的最大概率记为 β(beta)。

在假设检验中,我们可能在决策上犯这两类错误。一般来说,在样本量确定的情况下,任何决策无法同时避免这两类错误的发生,即在减少第一类错误发生的同时,会增大第二类错误发生的几率,或者在减少第二类错误发生的同时,会增大第一类错误发生的几率。
在大多数情况下,人们会控制第一类错误发生的概率。在进行假设检验时,人们通过事先给定显著性水平α的值来控制第一类错误发生的概率,常用的 α 值有 0.01,0.05,0.1。如果犯第一类错误的成本不高,那么可以选择较大的α值;如果犯第一类错误的成本很高,则选择较小的α值。
注:人们将只控制第一类错误的假设检验称为显著性检验,许多假设检验的应用都属于这一类型。
假设检验的步骤
1,定义总体2,确定原假设和备择假设3,选择检验统计量(确定假设检验的种类)4,选择显著性水平5,从总体进行抽样,得到一定的数据6,根据样本数据计算检验统计量的具体值7,依据所构造的检验统计量的抽样分布和显著性水平,确定临界值和拒绝域8,比较检验统计量的值与临界值,如果检验统计量的值在拒绝域内,则拒绝原假设
P值
为了完成假设检验,需要先定义一个概念:P值。P值其实就是把一些极端的情况加起来,为什么要这么做,其实就是因为这些点很难取到,如果你取到了,那么说明前面的假设不对了。
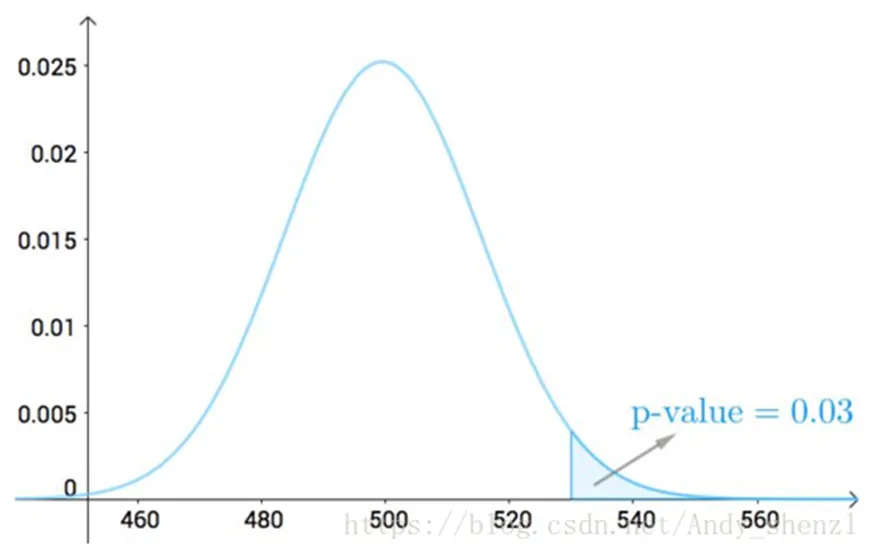
(我上面只取了单侧P值,说明下:取单侧还是双侧,取决于你的应用,什么叫做更极端的点,也取决于你的应用)
单侧检验
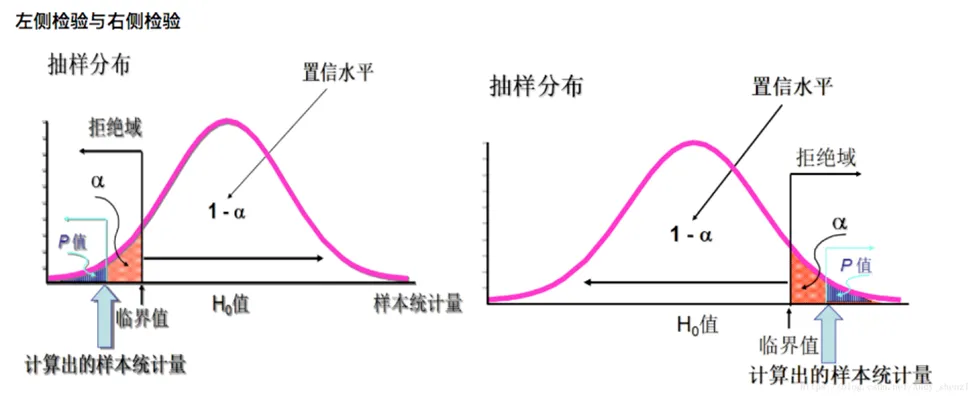
当关键词有不得少于/低于的时候用左侧,比如灯泡的使用寿命不得少于/低于700小时时
当关键词有不得多于/高于的时候用右侧,比如次品率不得多于/高于5%时
双侧检验
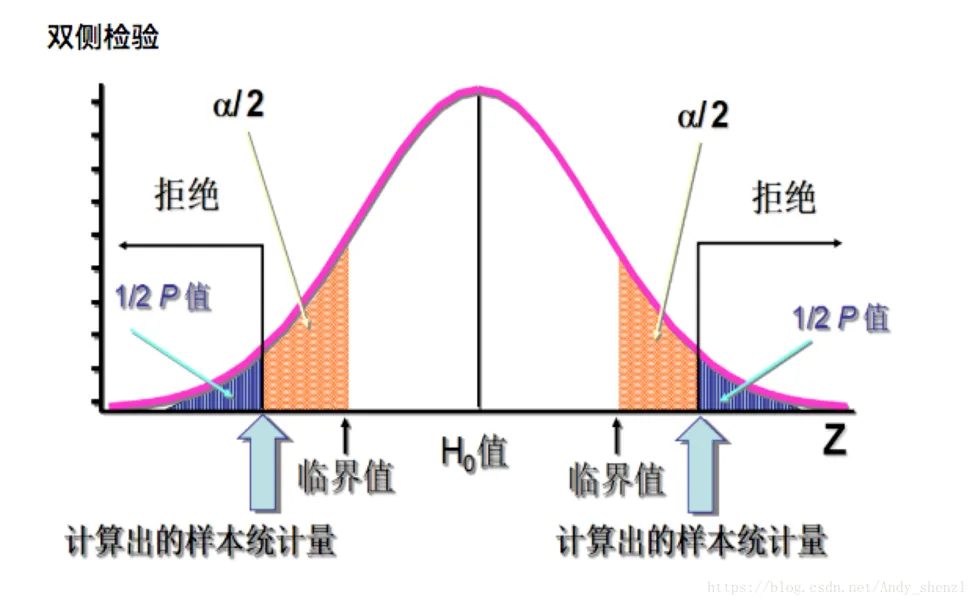
单侧检验指按分布的一侧计算显著性水平概率的检验。用于检验大于、小于、高于、低于、优于、劣于等有确定性大小关系的假设检验问题。这类问题的确定是有一定的理论依据的。假设检验写作:μ1<μ2或μ1>μ2。双侧检验指按分布两端计算显著性水平概率的检验, 应用于理论上不能确定两个总体一个一定比另一个大或小的假设检验。一般假设检验写作H1:μ1≠μ2。
单样本假设检验
单样本假设检验,是指我们对某一个样本点进行检验,是否满足我们的假设,比如学生身高,产品大小。
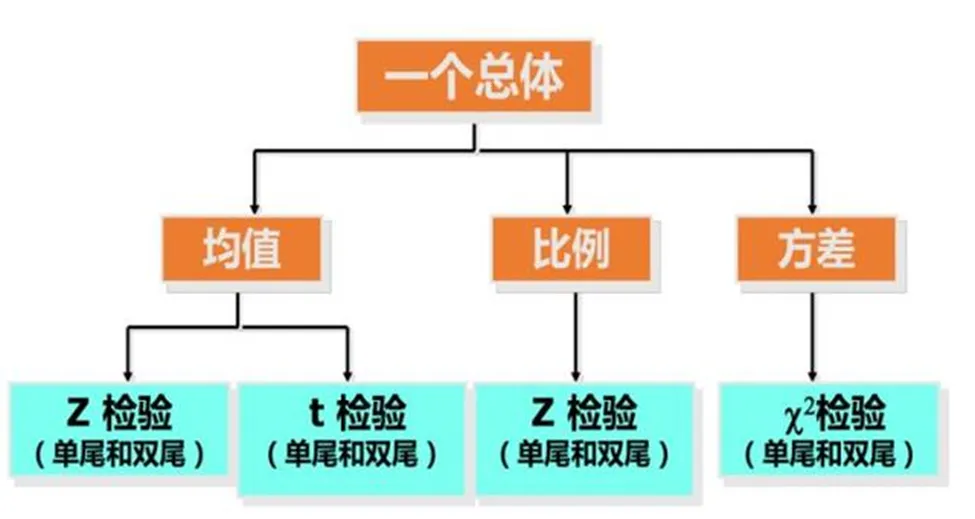
以均值为例进行如下分析,我们来看看样本适合哪种检验。
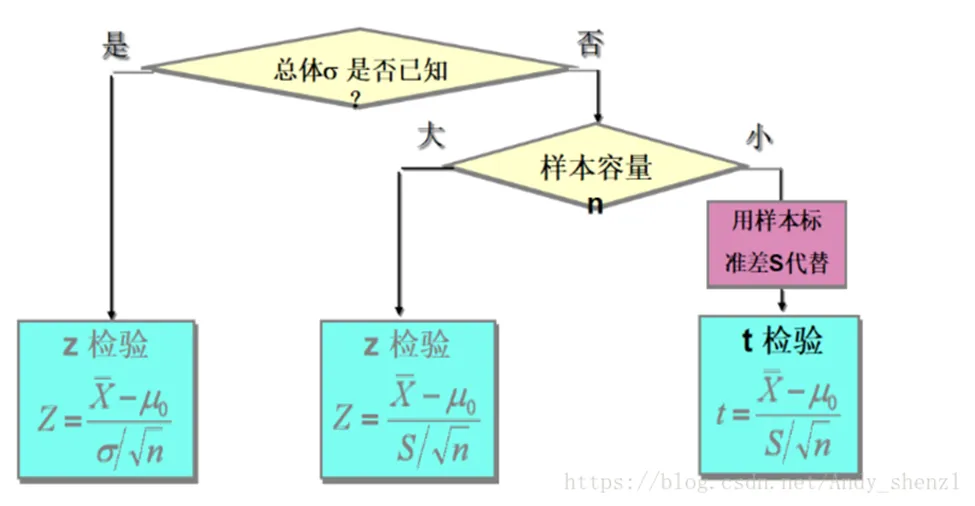
Z检验适用条件:大样本量(n>30),样本来自正态分布,且总体标准差已知。
举个例子:某机床厂加工一种零件,根据经验知道,该厂加工零件的椭圆度近似服从正态分布,其总体均值为μ=0.081mm,总体标准差为σ= 0.025 。今换一种新机床进行加工,抽取n=200个零件进行检验,得到的椭圆度为0.076mm。试问新机床加工零件的椭圆度的均值与以前有无显著差异?(α=0.05)
我们知道总体均值和总体方差,根据上图的规则可以看出我们可以用Z统计量:

双样本假设检验
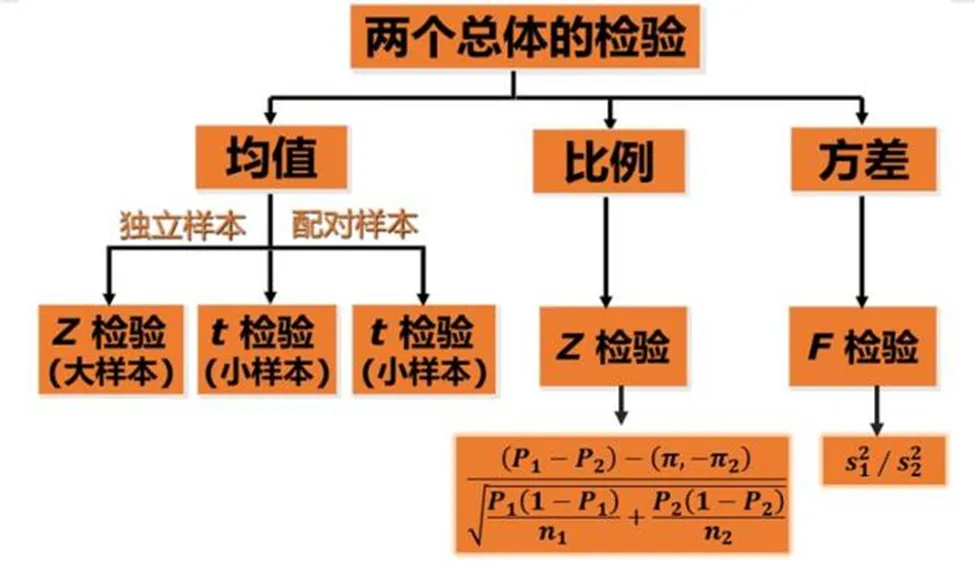
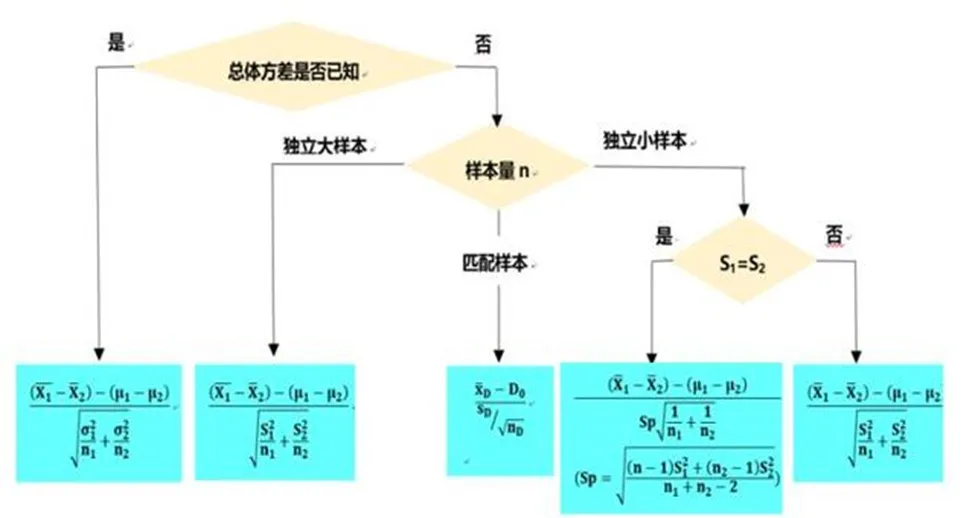
以均值差为例进行如下分析分析,看适合哪种检验。
本文来源:量化研究方法
