 夜雨聆风
夜雨聆风





RAG——RAG 索引(文档解析技术)
@ 目录
- 一、背景
- 二、LangChain Document Loaders 文档加载器
- 三、多格式文档解析
- 3.1、安装依赖库
- 3.2、定义加载各种格式文档的方法
- 3.3、调整 RAG 索引流程,处理文件夹中所有类型的文档文件
- 3.4、测试脚本 main 函数
- 四、PDF 文档解析
一、背景
-
RAG(检索增强生成)系统的首要步骤是索引(Indexing)流程中的文档解析。 -
文档解析技术的本质在于将格式各异、版式多样、元素多种的文档数据,包括段落、表格、标题、公式、多列、图片等文档区块,转化为阅读顺序正确的字符串信息。 -
“Quality in, Quality out” 是大模型技术的典型特征,高质量的文档解析能够从各种复杂格式的非结构化数据中提取出高精准度的信息,对 RAG 系统最终的效果起决定性的作用。 -
RAG 系统的应用场景主要集中在专业领域和企业场景。这些场景中,除了关系型和非关系型数据库,更多的数据以 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML、HTML 等多种格式存储。 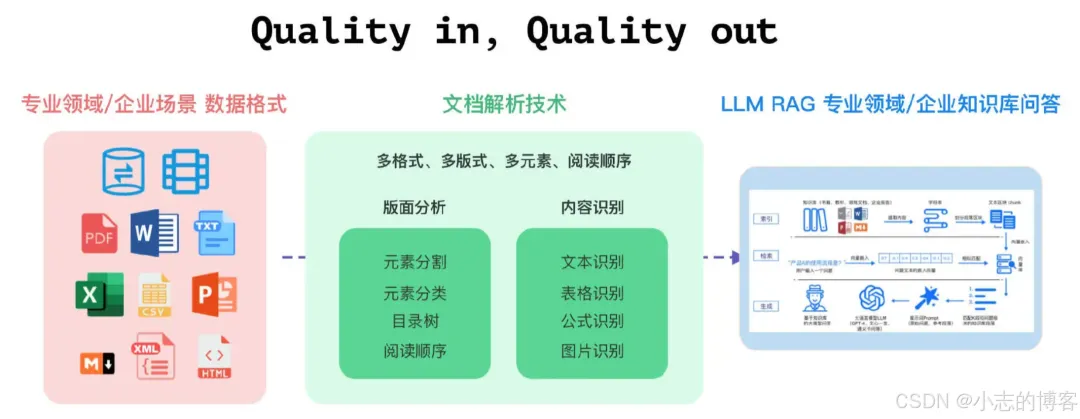
-
这篇文章我会先为你讲解各种文档格式的解析方法,并演示相关的代码。接下来,我将深入讲解 PDF 文件的解析,并提供针对性的技术方案分析。 -
此文章的所有代码和示例文档将公开发布在 Gitee 代码仓库https://gitee.com/techleadcy/rag_app.git 项目中,rag_app_lesson3.py 代码基于 RAG——从0到1快速搭建RAG应用 文章中的 rag_app_lesson2.py 进行迭代更新。
二、LangChain Document Loaders 文档加载器
-
本文章示例 RAG 项目基于 LangChain 架构,提供在实际应用场景中常见文档格式的解析方案,涵盖 PDF、TXT、Word、PPT、Excel、CSV、Markdown、XML 和 HTML 格式。鉴于 PDF 格式在实际应用中的使用占比最高,这节课的后半部分我们将对其进行深入讲解。
-
LangChain 提供了一套功能强大的文档加载器(Document Loaders),帮助开发者轻松地将数据源中的内容加载为文档对象。LangChain 定义了 BaseLoader 类和 Document 类,其中 BaseLoader 类负责定义如何从不同数据源加载文档,而 Document 类则统一描述了不同文档类型的元数据。
-
开发者可以基于 BaseLoader 类为特定数据源创建自定义加载器,并将其内容加载为 Document 对象。使用预构建的加载器比自行编写更加便捷。例如,PyPDF 加载器能够处理 PDF 文件,将多页文档分解为独立的、可分析的单元,并附带内容及诸如源信息、页码等重要元数据。
-
langchain_community 是 LangChain 与常用第三方库相结合的拓展库。各类开源库和企业库基于 BaseLoader 类在 langchain_community 库中扩展了不同文档类型的加载器,这些加载器被归类于 langchain_community.document_loaders 模块中。每个加载器都可以输入对应的参数,如指定文档解析编码、解析特定元素等,以及对 Document 类进行提取或检索等操作。目前,已有超过 160 种数据加载器,覆盖了本地文件、云端文件、数据库、互联网平台、Web 服务等多种数据源。详情可以在 LangChain LangChain 官网查看。

-
Document Loader 模块是封装好的各种文档解析库集成 SDK,项目中使用还需要安装对应的文档解析库。
例如,当我们项目中使用 from langchain_community.document_loaders import PDFPlumberLoader 时,需要先通过命令行 pip install pdfplumber 安装 pdfplumber 库。
某些特殊情况下,还需要额外的依赖库,比如使用 UnstructuredMarkdownLoader 时,需要安装 unstructured 库来提供底层文档解析,还需要 markdown 库来支持 Markdown 文档格式更多能力。
此外,对于像 .doc 这种早期的文档类型,还需要安装 libreoffice 软件库才能进行解析。
-
实际研发场景中,使用 Document Loader 文档加载器模块时,需要根据具体的业务需求编写自定义的文档后处理逻辑。针对业务需求,开发者可以自行编写和实现对不同文档内容的解析,例如对标题、段落、表格、图片等元素的特殊处理。在本课程的案例中,我们将从 Document 类中提取所有文本内容,进行下一步的文档分块处理。
三、多格式文档解析
-
本次实战我们将解析不同类型的文档,其对应的 Document Loader 和所需的文档解析依赖库如下表所示: 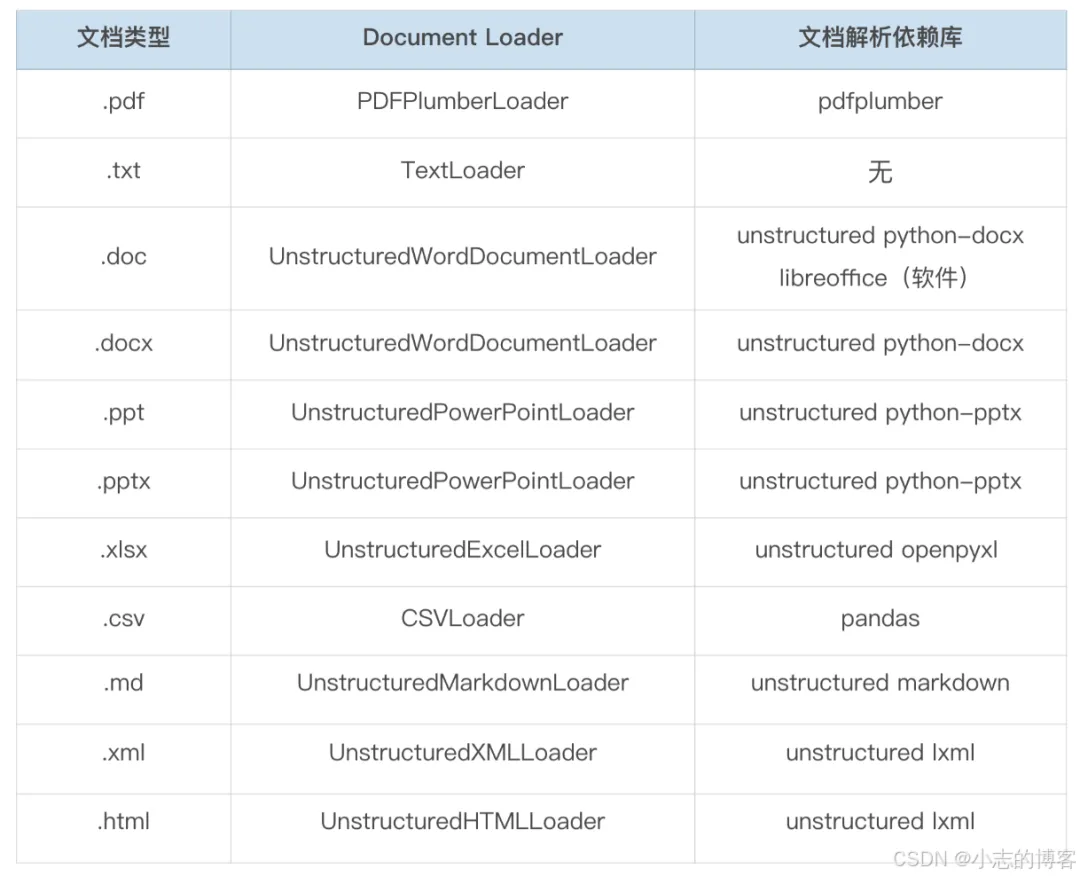
-
关于开发环境以及 langchain 和 langchain_community 等库的安装和配置,参考此文章RAG——从0到1快速搭建RAG应用。在执行以下指令之前,需要先完成此文章RAG——从0到1快速搭建RAG应用的实战内容。下面实战的代码更新在 Gitee 代码仓库https://gitee.com/techleadcy/rag_app.git 项目的 rag_app_lesson3.py 代码文件中。
3.1、安装依赖库
-
在使用 Document Loader 之前,先在命令行中执行以下安装命令:
source rag_env/bin/activate # 激活虚拟环境
pip install unstructured pdfplumber python-docx python-pptx markdown openpyxl pandas -i https://pypi.tuna.tsinghua.edu.cn/simple -
安装 .doc 文件的支持软件 LibreOffice:
sudo apt-get install libreoffice # Linux系统执行这条指令
brew install --cask libreoffice # MacOS系统执行这条指令
3.2、定义加载各种格式文档的方法
-
代码示例
from langchain_community.document_loaders import(
PDFPlumberLoader,
TextLoader,
UnstructuredWordDocumentLoader,
UnstructuredPowerPointLoader,
UnstructuredExcelLoader,
CSVLoader,
UnstructuredMarkdownLoader,
UnstructuredXMLLoader,
UnstructuredHTMLLoader,
) # 从 langchain_community.document_loaders 模块中导入各种类型文档加载器类
def load_document(file_path):
"""
解析各种文档格式的文件,返回文档内容字符串
:param file_path: 文档文件路径
:return: 返回文档内容的字符串
"""
# 定义文档解析加载器字典,根据文档类型选择对应的文档解析加载器类和输入参数
DOCUMENT_LOADER_MAPPING = {
".pdf": (PDFPlumberLoader, {}),
".txt": (TextLoader, {"encoding": "utf8"}),
".doc": (UnstructuredWordDocumentLoader, {}),
".docx": (UnstructuredWordDocumentLoader, {}),
".ppt": (UnstructuredPowerPointLoader, {}),
".pptx": (UnstructuredPowerPointLoader, {}),
".xlsx": (UnstructuredExcelLoader, {}),
".csv": (CSVLoader, {}),
".md": (UnstructuredMarkdownLoader, {}),
".xml": (UnstructuredXMLLoader, {}),
".html": (UnstructuredHTMLLoader, {}),
}
ext = os.path.splitext(file_path)[1] # 获取文件扩展名,确定文档类型
loader_tuple = DOCUMENT_LOADER_MAPPING.get(ext) # 获取文档对应的文档解析加载器类和参数元组
if loader_tuple: # 判断文档格式是否在加载器支持范围
loader_class, loader_args = loader_tuple # 解包元组,获取文档解析加载器类和参数
loader = loader_class(file_path, **loader_args) # 创建文档解析加载器实例,并传入文档文件路径
documents = loader.load() # 加载文档
content = "\n".join([doc.page_content for doc in documents]) # 多页文档内容组合为字符串
print(f"文档 {file_path} 的部分内容为: {content[:100]}...") # 仅用来展示文档内容的前100个字符
return content # 返回文档内容的多页拼合字符串
print(file_path+f",不支持的文档类型: '{ext}'") # 若文件格式不支持,输出信息,返回空字符串。
return""上述代码实现了解析多种文档格式并返回文档内容的字符串的方法 load_document。
函数通过检查文件的扩展名 ext,动态选择合适的文档加载器 Document Loader,使用相应的加载器调用对应库读取文档内容 documents。
支持的文档格式与对应的加载器类和参数在字典 DOCUMENT_LOADER_MAPPING 中进行了映射。
根据文件的扩展名,函数会实例化对应的加载器,并将文档内容加载为字符串 content,支持多页文档的合并处理。
3.3、调整 RAG 索引流程,处理文件夹中所有类型的文档文件
-
代码示例
def indexing_process(folder_path, embedding_model):
"""
索引流程:加载文件夹中的所有文档文件,并将其内容分割成文档块,计算这些小块的嵌入向量并将其存储在Faiss向量数据库中。
:param folder_path: 文档文件夹路径
:param embedding_model: 预加载的嵌入模型
:return: 返回Faiss嵌入向量索引和分割后的文本块原始内容列表
"""
# 初始化空的chunks列表,用于存储所有文档文件的文本块
all_chunks = []
# 遍历文件夹中的所有文档文件
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
# 检查是否为文件
if os.path.isfile(file_path):
# 解析文档文件,获得文档字符串内容
document_text = load_document(file_path)
print(f"文档 {filename} 的总字符数: {len(document_text)}")
# 配置RecursiveCharacterTextSplitter分割文本块库参数,每个文本块的大小为512字符(非token),相邻文本块之间的重叠128字符(非token)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=128
)
# 将文档文本分割成文本块Chunk
chunks = text_splitter.split_text(document_text)
print(f"文档 {filename} 分割的文本Chunk数量: {len(chunks)}")
# 将分割的文本块添加到总chunks列表中
all_chunks.extend(chunks)
# 文本块转化为嵌入向量列表,normalize_embeddings表示对嵌入向量进行归一化,用于准确计算相似度
......省略未改动部分
return index, all_chunks上述代码是在RAG——从0到1快速搭建RAG应用文章中的 indexing_process 函数基础上进行了迭代,新增了批量处理多种格式文档文件的功能。
调整部分为函数遍历文件夹中的所有文档文件,通过调用 load_document 获取文档的字符串内容,并将其切分为文本块 chunks,然后将所有文档的 chunks 汇总到一个总列表 all_chunks 中。
当前的实现主要聚焦于文档解析技术,chunks 和对应的嵌入向量 index 暂时存储在内存中,持久化存储的部分将在后续的向量库课程中详细讲解。
3.4、测试脚本 main 函数
-
测试脚本 main 函数在RAG——从0到1快速搭建RAG应用文章中的 main 函数基础上进行了调整:
# 索引流程:加载文件夹中各种格式文档,分割文本块,计算嵌入向量,存储在Faiss索引中(内存)
index, chunks = indexing_process('rag_app/data_lesson3', embedding_model) -
先参照RAG——从0到1快速搭建RAG应用文章的大模型参数配置方法,配置 qwen_model 与 qwen_api_key 参数后,在命令行窗口中执行指令定位到具体的 RAG 项目文件夹,在命令行中执行以下指令即可开始 RAG 应用测试:
source rag_env/bin/activate # 激活虚拟环境
python rag_app/rag_app_lesson3.py # 执行RAG应用脚本data_lesson3 文件夹内置了该文章涉及的所有格式的测试文档文件,所有文件的信息保持一致,旨在观察不同格式文档的解析效果。
测试代码通过 main 函数串联各个步骤,索引流程将 data_lesson3 中所有的文档文件进行解析,准确完成“下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?”的 RAG 问答任务。
四、PDF 文档解析
-
PDF 文件在我们的业务场景中占有最高的比例,广泛应用于商业、学术和个人领域。尽管 PDF 文件的内容在表达图像、文字和表格信息,但其本质上是一系列显示和打印指令的集合。如下图所示,即使是一个仅包含 “Hello World” 文字的简单 PDF,其文件内容也是一长串的打印指令。 
-
PDF 文件的显示效果不受设备、软件或系统的影响,但对计算机而言,它是一种非数据结构化的格式,储存的信息无法直接被理解。此外,大模型的训练数据中不包含直接的 PDF 文件,无法直接理解。 -
PDF 解析,对于纯文本格式可以转换为文本字符串,而对于包含多种元素的复杂格式,选择 MarkDown 文件作为统一的输出格式最为合适。这是因为 MarkDown 文件关注内容本身,而非打印格式,能够表示多种文档元素内容。MarkDown 格式被广泛接受于互联网世界,其信息能够被大模型理解。 -
PDF 文件分为电子版和扫描版。PDF 电子版可以通过规则解析,提取出文本、表格等文档元素。目前,有许多开源库可以支持,例如 pyPDF2、PyMuPDF、pdfminer、pdfplumber 和 papermage 等。这些库在 langchain_community.document_loaders 中基本都有对应的加载器,方便在不同场景下切换使用。 -
在基于规则的开源库中,pdfplumber 对中文支持较好,且在表格解析方面表现优秀,但对双栏文本的解析能力较差;pdfminer 和 PyMuPDF 对中文支持良好,但表格解析效果较弱;pyPDF2 对英文支持较好,但中文支持较差;papermage 集成了 pdfminer 和其他工具,特别适合处理论文场景。开发者可以根据实际业务场景的测试结果选择合适的工具,pdfplumber 或 pdfminer 都是当前不错的选择。 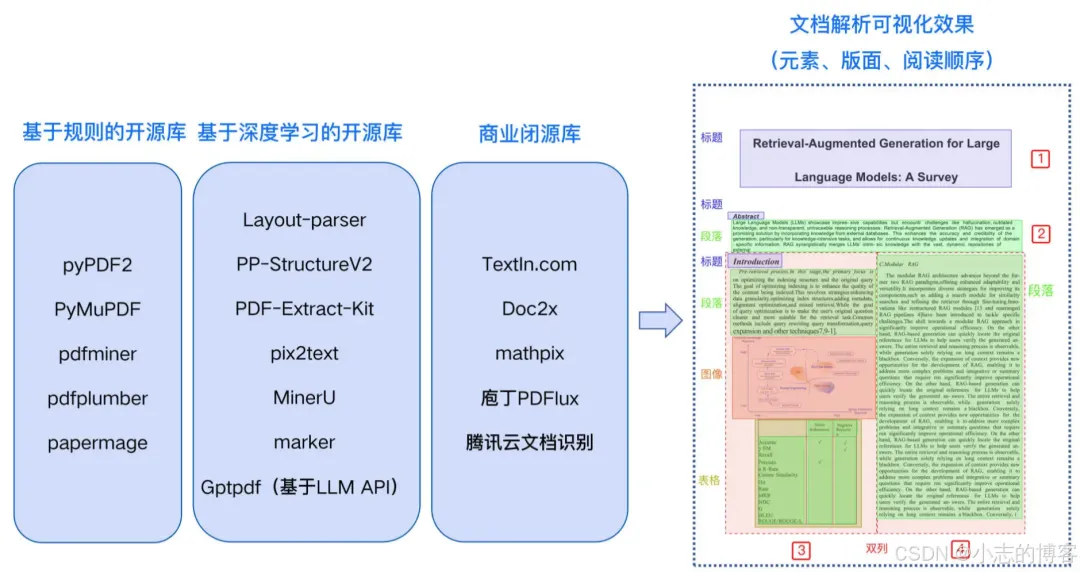
-
PDF 扫描版需要经过文本识别和表格识别 PDF 扫描图像,才能提取出文档中的各类元素。同时要真正实现文档解析的目标,无论扫描版还是电子版均需进行版面分析和阅读顺序的还原,将内容解析为一个包含所有文档元素并且具有正确阅读顺序的 MarkDown 文件。单纯依赖规则解析是无法实现这一目标的,目前支持这些功能的多为基于深度学习的开源库,如 Layout-parser、PP-StructureV2、PDF-Extract-Kit、pix2text、MinerU、marker 等。 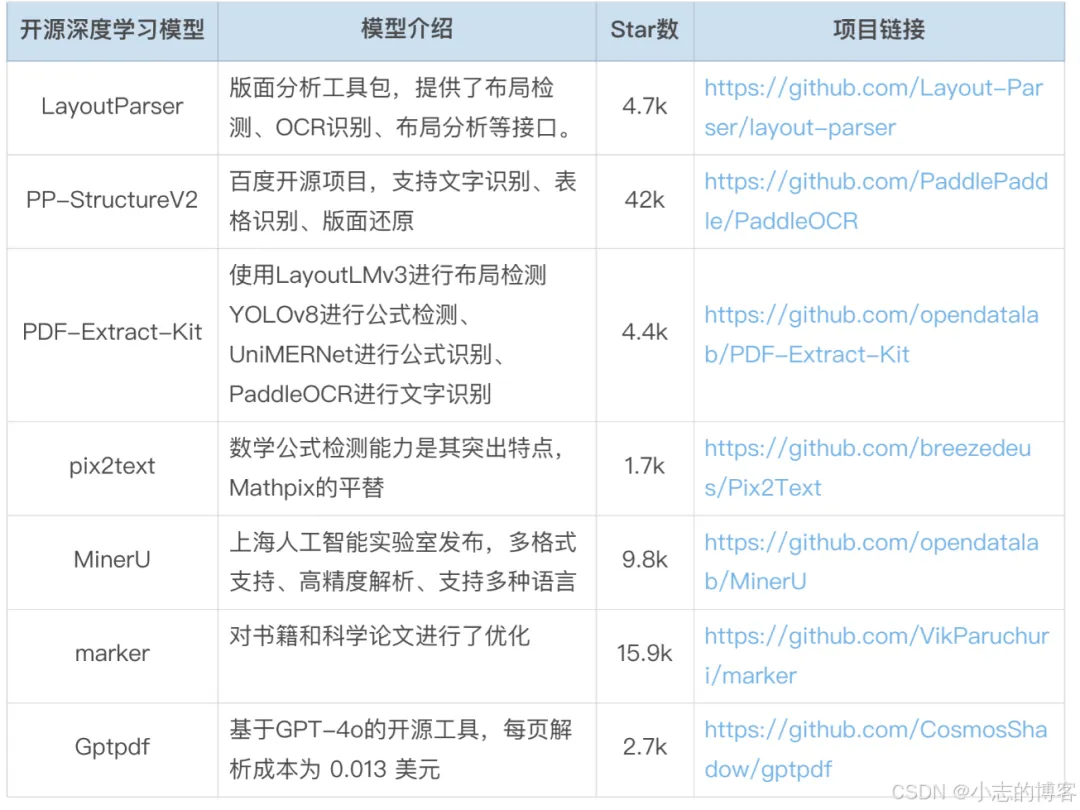
-
由于 PDF 文档解析整体流程用到了多个深度学习模型组合,真正在生产场景中会遇到效率问题。商业闭源库由于其部署的云端集群可以做并行处理和工程效率优化,所以在精度和效率上都能做到生产中的级别,比如 TextIn.com、Doc2x、mathpix、庖丁 PDFlux、腾讯云文档识别等,当然商业库会存在成本问题,你可以按需选择。 -
此外,还需要进一步探索 PDF 中的图像内容理解,不仅限于文字模态,还包括对图片中非文字内容的解析,如常见的折线图、柱状图等,也包含重要的内容信息。将这些内容转换为文字形式并嵌入到 MarkDown 文件中,通常需要依赖端到端的多模态大模型,如 GPT-4o 或 Gemini。然而,目前这些模型在效率和成本方面仍存在挑战,但其未来潜力巨大,值得期待。
