 夜雨聆风
夜雨聆风





pdf2skill:让计算机视觉初学者把PDF文档变成AI技能包

向AI转型的程序员都关注公众号 机器学习AI算法工程
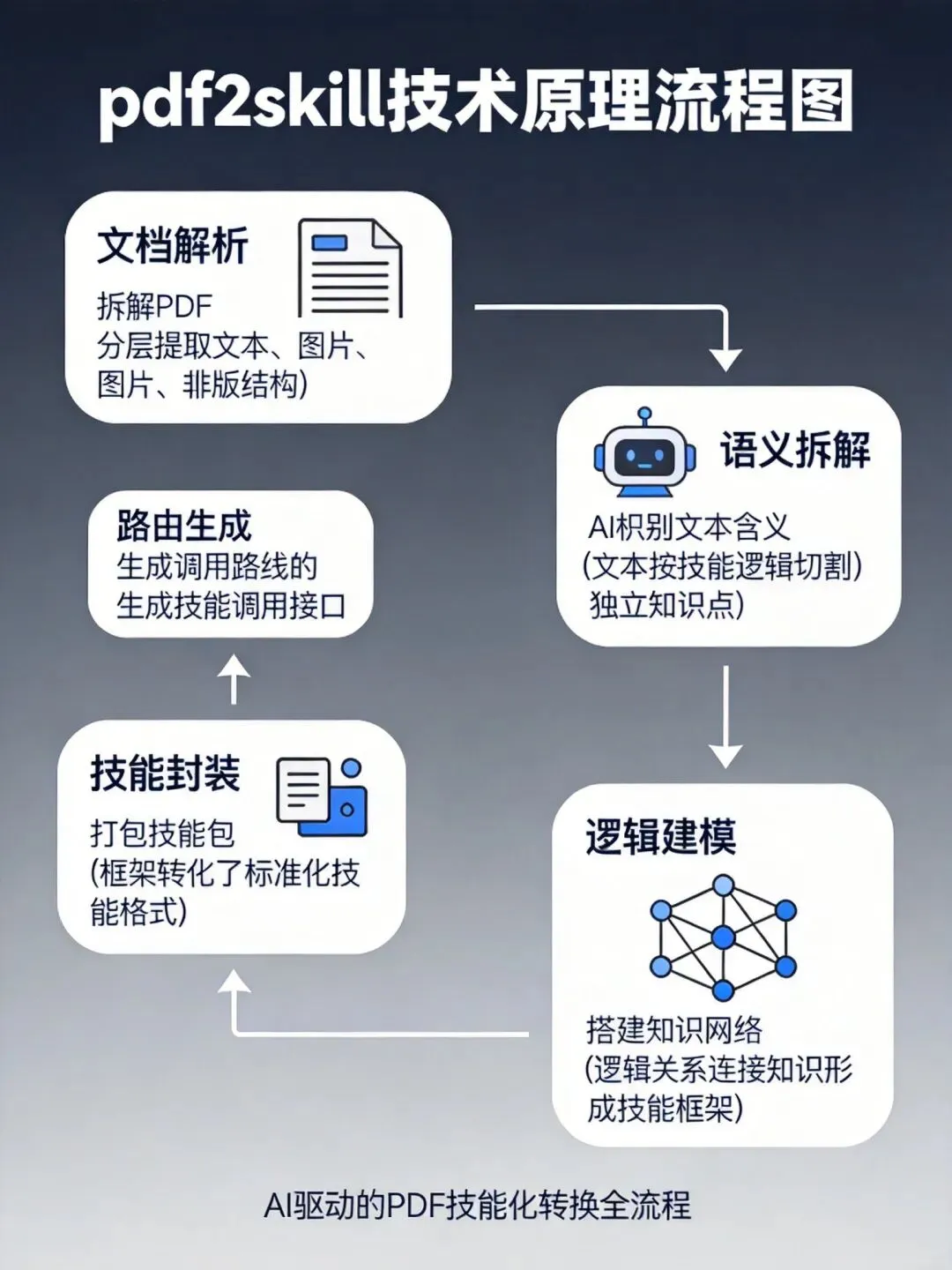
图注:pdf2skill技术原理流程图
作为计算机视觉研究者或工程师,你是否曾遇到这些困境:面对数百页技术文档需要手动提取算法步骤;阅读多篇论文后难以系统整理技术框架;希望将经典教材转化为可复用AI工具;团队协作中难以高效共享专业知识?
pdf2skill技术正是为解决这些痛点而生。它不是简单的PDF转文本工具,而是一个”文档转技能编译器”,能够自动将PDF文档中的知识转化为AI助手可直接调用的结构化技能包。通过本文,你将掌握如何利用这一技术将计算机视觉文档转化为实用AI技能,大幅提升研究与开发效率。

图注:传统PDF提取 vs pdf2skill技能化提取:从文本摘要到可执行能力的转变
三大常见误区
误区1:直接让AI总结PDF = 等同于pdf2skill❌ 错误理解:两者都是让AI读取PDF并生成内容。✅ 实际差异:直接总结是一次性消费(对话结束即失效),pdf2skill是永久可复用的能力(技能文件可持续调用)。
误区2:Claude Code Skills = 简单的快捷指令❌ 错误理解:Skills就是给AI预设几个常用命令。✅ 实际差异:Skills采用三层渐进式披露架构,确保AI按需加载能力,避免上下文浪费。
误区3:所有PDF都适合用pdf2skill处理❌ 错误理解:任何PDF都能一键转换为高质量技能。✅ 实际差异:pdf2skill对方法论类书籍(操作手册、行业报告)表现优异(★★★★★),对扫描版PDF效果较差(★★☆☆☆)。
pdf2skill技术原理:五大核心模块
图注:pdf2skill五大核心模块:文档解析→语义拆解→逻辑建模→技能封装→路由生成
步骤1:文档解析将PDF转换为结构化文本,处理目录、标题层级、表格和图表说明。pdf2skill支持三种PDF类型:原生文本型(最佳,★★★★★)、扫描型(需OCR,★★☆☆☆)、混合型(★★★☆☆)。
步骤2:语义拆解不按章节机械切割,而是按语义密度和逻辑边界智能拆分。精准识别:核心概念定义、操作步骤序列、异常处理分支、条件判断逻辑。特别适合提取算法步骤和公式推导。
步骤3:逻辑建模自动建立知识点之间的依赖关系:前置条件(A是B的前置条件)、异常分支(C是D的异常分支)、并行关系(E和F可并行执行)。对于计算机视觉算法文档,能够自动梳理算法组件之间的依赖关系和数据流。
步骤4:技能封装输出标准skill文件,每个技能包含:技能名称和id(机器可识别的唯一标识)、触发条件(什么场景下应该调用)、输入参数(需要用户提供什么信息)、执行逻辑(具体的分析步骤、判断规则、操作流程)、输出格式(结果以什么形式呈现)、依赖关系(和其他技能的前置/后置关系)。
步骤5:路由生成自动生成技能索引和路由规则,使AI能够根据用户问题自动匹配最相关的技能。对于复杂的计算机视觉技术文档尤为重要,能够帮助AI快速定位所需的算法或方法。
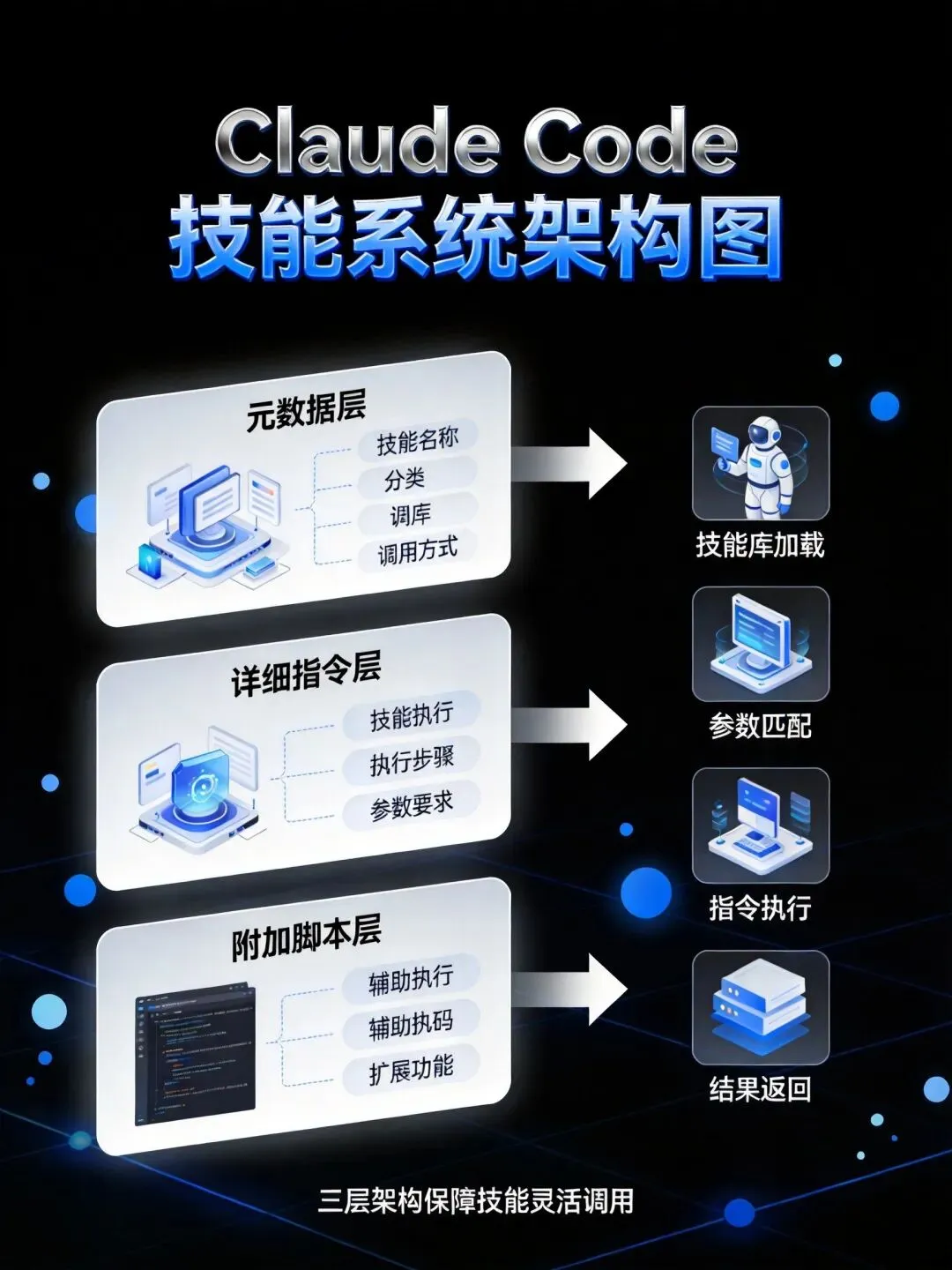
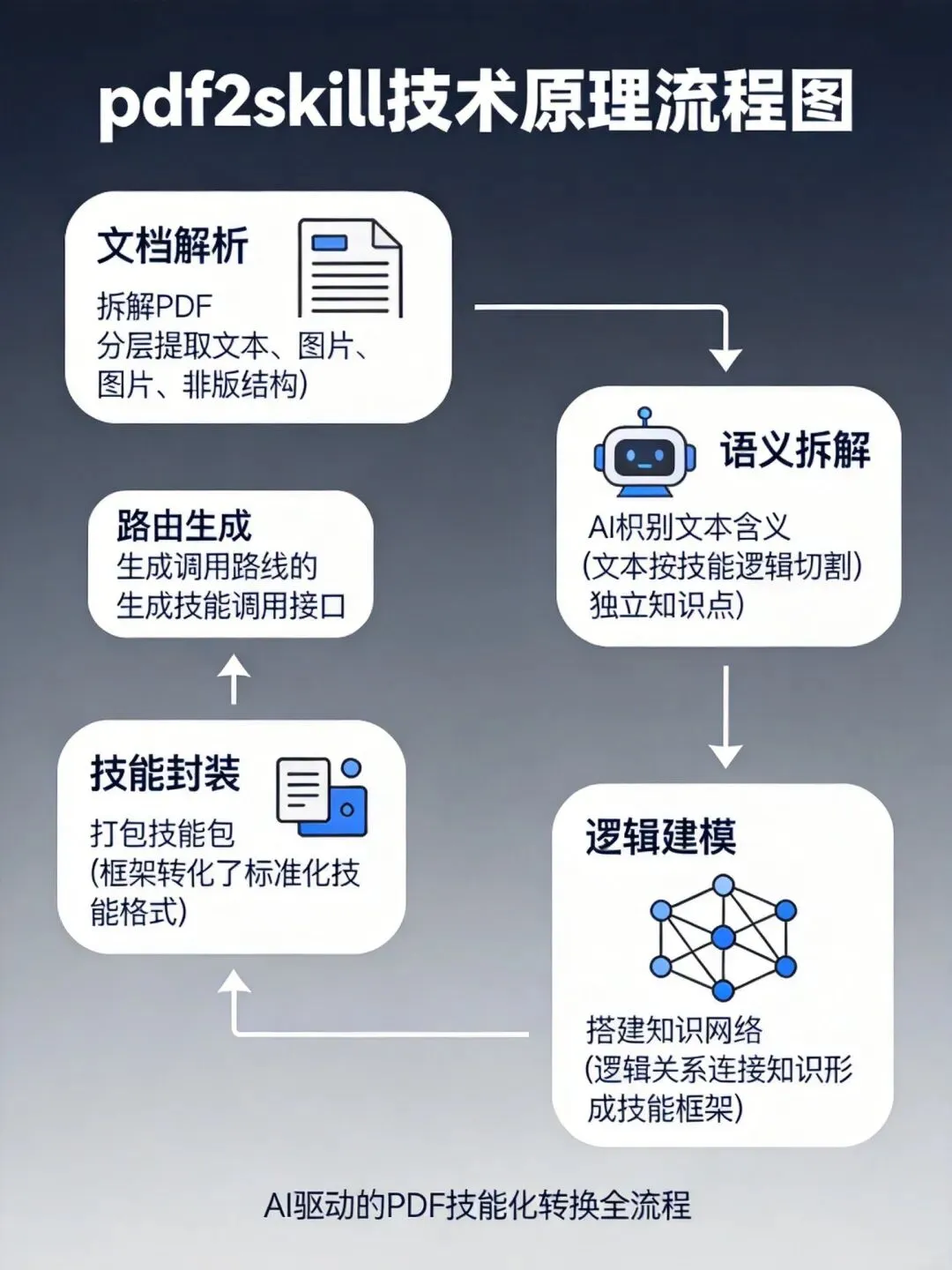
图注:Claude Code Skills三层架构:元数据层(始终加载)→详细指令层(触发时加载)→附加脚本层(按需访问)
实战案例:从YOLO论文到可调用技能
输入:一份关于YOLO目标检测算法的PDF论文(约30页,包含算法原理、网络架构、训练技巧、实验结果)
过程:上传到pdf2skill在线平台 → AI语义分析 → 生成skills.zip → 解压查看文件结构
输出:Claude Code能够准确调用”yolo-training-workflow”技能,给出专业的网络架构建议、参数优化策略、数据增强技巧
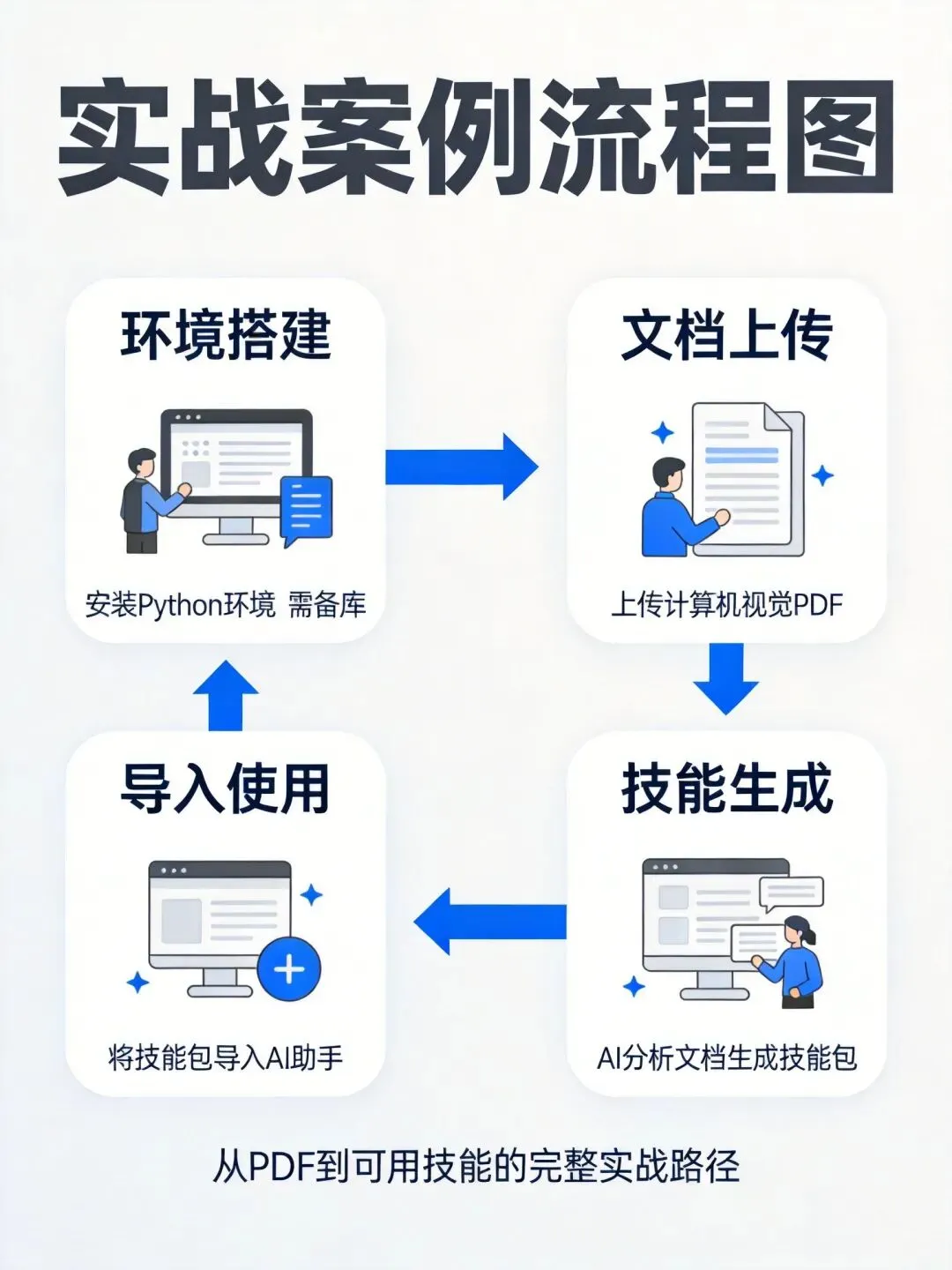
图注:YOLO论文PDF→技能包生成→导入Claude Code→实际使用:4步完整流程
Python代码实现(核心功能示例):
import pdfplumberfrom typing import Dict, Listimport jsonclass PDF2SkillConverter:"""pdf2skill核心转换器"""def __init__(self, pdf_path: str):self.pdf_path = pdf_pathself.content = []self.skills = []def extract_text_and_structure(self) -> List[Dict]:"""步骤1:提取文本和结构化信息"""with pdfplumber.open(self.pdf_path) as pdf:for page_num, page in enumerate(pdf.pages):text = page.extract_text()# 识别标题层级(简化示例)is_title = text.startswith('#') or len(text) < 100self.content.append({'page': page_num + 1,'text': text,'is_title': is_title,'type': self._classify_content(text)})return self.contentdef _classify_content(self, text: str) -> str:"""内容类型分类"""if '步骤' in text or 'step' in text.lower():return 'procedure'elif '公式' in text or 'equation' in text.lower():return 'formula'elif '表格' in text or 'table' in text.lower():return 'table'return 'text'def semantic_chunking(self) -> List[Dict]:"""步骤2:语义拆解"""chunks = []current_chunk = {'type': 'text', 'content': []}for item in self.content:if item['is_title'] and current_chunk['content']:chunks.append(current_chunk.copy())current_chunk = {'type': 'text', 'content': []}current_chunk['content'].append(item['text'])if current_chunk['content']:chunks.append(current_chunk)return chunksdef generate_skill(self, chunks: List[Dict]) -> List[Dict]:"""步骤3-5:技能生成(简化示例)"""for chunk in chunks:if any('训练' in s or 'training' in s.lower() for s in chunk['content']):skill = {'name': 'cnn-training-workflow','description': '卷积神经网络训练工作流程','trigger': ['train CNN', '训练流程'],'steps': chunk['content']}self.skills.append(skill)return self.skills# 使用示例converter = PDF2SkillConverter('yolo_paper.pdf')content = converter.extract_text_and_structure()chunks = converter.semantic_chunking()skills = converter.generate_skill(chunks)# 输出技能print(json.dumps(skills, indent=2, ensure_ascii=False))
关键要点
1. pdf2skill vs 传统PDF提取工具传统工具仅提取文本和表格(pdfplumber、PyPDF2),pdf2skill能理解逻辑关系并生成可调用技能。技术文档的技能化准确率达90%+,适合方法论书籍和操作手册。
2. Claude Code Skills的渐进式披露架构元数据层(始终加载,约100 tokens)+ 详细指令层(触发时加载,约2000 tokens)+ 附加脚本层(按需访问)。相比传统Agent一次性加载所有工具,节省80%的上下文token。
3. PDF类型识别的重要性原生文本型(★★★★★)最佳;扫描型需启用OCR(★☆☆☆☆);混合型需要根据内容密度评分。选择高质量PDF能显著提升技能生成质量。
4. 技能管理的最佳实践每个Skill目录包含SKILL.md(定义文件)、scripts/(脚本)、references/(参考资料)。技能应按领域分类管理(如computer-vision/、nlp/),并在SKILL.md中明确触发条件。
5. 当前实现的局限性复杂公式识别准确率约85%(有待提升);图表理解有限(网络架构图难以解析);超大型PDF(500页以上)处理速度较慢(15-30分钟)。
6. 适用场景判断矩阵技术文档、操作手册、行业报告(★★★★★)→ 强烈推荐;学术论文(★★★★☆)→ 推荐;扫描版PDF(★★☆☆☆)→ 不推荐;小说、文学类(★☆☆☆☆)→ 不适用。
性能数据对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
数据来源:微信公众号官方文档、GitHub开源项目、技术博客分析(NVIDIA技术博客)
工具使用指南
pdf2skill在线平台使用(推荐)1. 访问 pdf2skills.memect.cn2. 上传PDF文档(建议100页以内)3. 等待处理完成(2-15分钟,根据文档大小)4. 下载生成的 skills.zip 文件5. 解压并导入Claude Code或OpenCode
Claude Code Skills管理1. 将技能包放入 ~/.claude/skills/ 目录2. 每个技能目录需包含 SKILL.md 文件3. SKILL.md 包含 YAML frontmatter(name、description、trigger)4. 可选目录:scripts/(脚本)、references/(参考资料)5. 重启Claude Code使技能生效
参数调优建议• 图像尺寸:1280(提高小字体和复杂公式识别率)• 置信度阈值:0.25-0.3(平衡精度和召回率)• 并行处理:启用(加速大型文档处理)• OCR模式:处理扫描版PDF时必须启用• 表格识别:始终启用(提取实验结果和参数表)• 公式识别:始终启用(识别数学公式并转换为LaTeX)

图注:知识不是存储在PDF中的静态资产,而是能够被AI按需调用的动态能力 —— pdf2skill核心理念
机器学习算法AI大数据技术
搜索公众号添加:datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加:datayx

