 夜雨聆风
夜雨聆风





Context 不是免费的:解析长文档 agent 的性能天花板与架构优化
- 文章讨论构建真实世界AI智能体时常见问题:处理长文档的JSON解析输出(如坐标、置信度分数)占用整个上下文窗口,导致智能体无法有效工作。
- 作者提出解决方案:将解析输出分离为纯内容(Markdown格式用于智能体推理)和元数据(存储在文件系统中,按需通过工具查询),并优化提示词以鼓励代理使用搜索工具而非全载文档。
导读: 随着模型上下文窗口不断扩大,我们似乎习惯了“暴力输入”,但 1M Token 的杂乱数据往往不如 200k 的精炼信息。本文深入剖析了构建复杂 Agent(如法律、金融、建筑领域)时的常见性能瓶颈:原始解析输出对模型推理的干扰。通过引入“Markdown 编号块 + 沙盒代码查询”的架构模式,我们不仅能保留精确到 PDF 像素级的引用能力,还能让 Agent 的注意力重新聚焦在逻辑推理上。这是一场关于“信息密度”与“工具调用”的技术进化。
作者 Raunak(@raunakdoesdev)是一位专注开源科学、优雅软件架构与精致界面的独立开发者与创业者。目前正在构建Reducto AI,擅长AI代理、文档解析与复杂工作流优化,曾在Anthropic黑客松获奖,热衷分享真实世界AI工程经验。
我在构建现实世界智能体时看到的最常见问题——以及如何修复它。
最近,我反复从构建各种文档相关智能体的客户那里听到同一个问题。他们通过 API 处理长文档,将生成的 JSON 响应喂给智能体,结果在智能体还没开始干正事之前,整个 上下文窗口(Context Window) 就已经被塞满了。
我在很多场景中都见过这种情况:审查合同的法律 AI 智能体、处理理赔的保险智能体,有时是处理 10-K 表格提取数据的金融智能体。
但问题的本质总是一样的:原始解析输出包含的信息远超智能体所需,而这些多余的信息正严重损害性能。
一个例子:建筑工作流智能体
最近的一个例子让这个问题变得尤为清晰:一位客户正在构建一个用于建筑项目的“变更单(Change Order)”审查智能体。他们带着一份 100 页的变更单来找我们,这份文档解析后产生了 20 万行 JSON 代码。
该工作流允许承包商提交变更单,智能体则根据原始合同、进度表和单价表进行交叉比对,并在审查电子表格中标记出不一致之处。由于用户是负责数百万美元索赔的建筑项目经理(PM),每一项发现都需要链接回原始 PDF 的精确区域。
他们利用沙盒环境、电子表格工具和边界框(Bounding Box)引用构建了整个系统。听起来很扎实,对吧?
但智能体在处理长文档时总是卡住。他们的第一直觉是在系统顶层增加一些东西:比如目录、章节摘要,或者想办法给智能体一个可以进一步钻取的压缩视图。
我扫了一眼那 20 万个 token 里到底装了什么,立刻发现了一个更好的解决方案。
问题所在:原始 API 响应并非为智能体输入而设计
Reducto 的解析响应是为了工程灵活性而设计的。每个模块(Block)都有边界框坐标、OCR 置信度分数、类型分类、坐标数据——这是一个对文档丰富且忠实的还原。
这正是你开发文档阅读器或版面分析工具时所需要的。
但这不是你希望放入智能体上下文窗口里的东西。
当你把原始 JSON 交给智能体时,大部分 token 并不是文档内容,而是像素坐标、置信度浮点数和结构化元数据。智能体正试图在密集的边界框数组中艰难前行,同时还要推理合同条款和单价。
我们为工程师结构化 JSON,而不是为了让智能体直接消耗。大多数结构化 API 响应可能都是如此,不只是我们的。
这中间有一个很多团队都忽略了的预处理步骤。
更好的解决方案
在解析输出进入智能体之前,将其拆分为两种表示:内容(Content)和元数据(Metadata)。
- 从 API 响应中提取内容(如
.result.chunks[0].content)并写入一个 .md (Markdown) 文件。 - 丢掉坐标、置信度分数和块元数据。
- 剩下的就是一个干净、可读的文档版本。
难点在于: 许多客户需要“块级引用”。当智能体标记某项内容时,产品需要高亮显示原始 PDF 中的精确区域。你不能扔掉边界框,但你也不需要把它们放在上下文窗口里。
修复方法很简单:在 Markdown 中为每个块编号。
块 0 | 第一节:一般条款
块 1 | 承包商应提供所有人工、材料和设备...
块 2 | 附件 B 中规定的单价应作为所有定价的依据...
块 3 | 1.1 工作范围
块 4 | 本变更单涵盖的工作包括对...的修改
完整的解析 JSON(或从中提取的 CSV)存放在智能体的沙盒文件系统中。智能体阅读并推理 Markdown 内容。当它发现值得引用的内容时——比如第 47 块中的单价不一致——它会编写一段简单的 pandas 代码,从结构化文件中提取对应的边界框。
元数据永远不会占用上下文窗口。它只在需要时,通过代码按需获取。
这就是为什么沙盒化编码智能体在处理文档工作时如此强大。智能体对待结构化元数据就像开发者一样:将其视为待查询的数据,而不是待阅读的文本。
原本 20 万 token 的 JSON 变成了:一个用于理解的干净 Markdown 文件 + 一个用于空间查询的结构化文件。设置这一切只需要大约 20 行的后处理代码。
一个值得修正的提示词模式(Prompt Pattern)
在许多系统提示词中,总能看到类似这样的指令:
“从头到尾阅读每个附件文档。”
这听起来很合理,你希望智能体严谨周全。但模型非常擅长执行指令,哪怕指令本身并不合理。当你告诉智能体从头到尾阅读每个文档时,它会尝试将每个文件都加载到上下文窗口中。对于一份 100 页的变更单加上证明文件,智能体在做任何有用的工作之前,上下文预算就已经耗尽了。
这样写效果会好得多:
“利用附件文档回答问题。使用子智能体或工具来有效管理上下文。如果文件很大,请搜索相关章节,而不是加载整个文档。”
区别是巨大的。第一种提示词产生的智能体像是一个在考试前死记硬背教科书的学生;第二种则像是一个研究员,它会搜索(grep)相关章节、阅读特定片段、利用工具提取特定数据。它是在引导(navigate)文档,而不是试图背诵文档。
这对工具设计也很重要。如果你的智能体正在填写审查表格,一个能通过关键词或章节标题搜索并返回相关块的工具,远比一个将整个文件甩进对话里的工具更有用。
完整的流水线方案
对于文档密集型智能体,行之有效的通用方案如下:
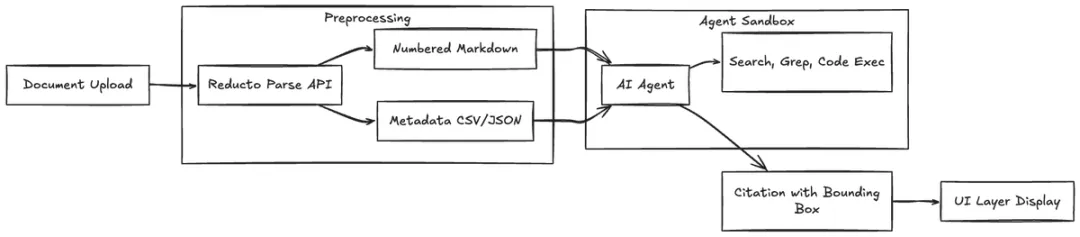
- 文档上传
- Reducto 解析 API(获取全保真 JSON)
- 预处理(约 20 行代码)
- 提取块内容 → 带有编号的 .md 文件
- 存储元数据 → 沙盒中的 CSV/JSON 文件
- (可选)生成章节索引
- 智能体沙盒
- .md 文件:智能体阅读并推理
- 元数据文件:智能体在需要时通过代码查询
- 工具:搜索、grep、代码执行、带有引用的单元格写入
- 智能体引用第 47 块 → 编写 pandas 片段 → 提取边界框
- 应用层在原始 PDF 中渲染高亮引用
当然,还有其他可行的方法:
- 向量搜索分块(Chunking with vector search)
- 层级化摘要(Hierarchical summarization)
- 微调检索(Fine-tuned retrieval)
但对于智能体需要跨文档进行详细交叉引用并产生精确引用的用例,将内容与元数据分离并给智能体提供干净的 Markdown,对我们合作过的团队来说效果非常好。
核心原则
人们很容易尝试用更大的上下文窗口来解决长文档问题。但是,一个包含 90% 坐标元数据的 100 万 token 上下文,效果不如一个拥有干净 Markdown 和优秀工具的 20 万 token 上下文。
上下文不是免费的。每一个 token 都会影响模型的行为,而那些对任务无用的 token 会积极地挤占掉那些有用的 token。
我们的 Reducto API 旨在实现最高保真度。对于在它之上进行构建的工程师来说,这是正确的默认设置。但 API 返回的所有数据与智能体实际需要的数据之间存在差距。
我们已经看到客户通过弥合这一差距,显著提升了准确率和性能,从而为他们的终端用户带来了更好的结果和性能更佳的智能体。
您在处理此类问题时有什么其他方法或想法吗?欢迎交流!
原文:https://x.com/raunakdoesdev/status/2029610657008783407
