 夜雨聆风
夜雨聆风





今天!GPT-5.4 正式发布,不用插件,就能轻松操控电脑干活!

大家好,今天是坚持更新的第30天!
就在今天,OpenAI正式推出了全新一代旗舰模型GPT-5.4,与以往的GPT模型不一样的是,这次GPT-5.4发布,有个很大的亮点就是具备原生计算机使用能力。
我先刷完了OpenAI官方放出来的所有演示,最大的感受就是,它终于跳出了之前的局限。
跟OpenClaw类似一样的功能,而GPT-5.4将操控电脑的能力就藏在模型本身里,打开就能用,彻底跳出了依靠插件实现功能的固有模式。
这种改变不是简单的功能叠加,而是从底层逻辑上,优化了AI和计算机的交互的方式,也让之前只能算是尝鲜的操作形式,有了稳定落地的可能。
对于一直关注AI实用化进展的朋友来说,这样的更新远比各种抽象数据更有参考价值。
我们不用再纠结技术概念有多前沿,只需要看实际表现是否够顺畅、够好用,而这也是GPT-5.4这次更新最值得慢慢拆解的部分。
GPT-5.4 能做什么?
首先是专业工作能力
官方在GDPval基准上给出了GPT-5.4的成绩:83.0%(与 GPT-5.2 的 70.9% 相比)。GDPval是OpenAI内部自己提出的一个针对知识工作任务(Knowledge Work Tasks)的评估基准,用于衡量大语言模型LLM在模拟真实职场场景中的能力表现。
其核心目标是通过与行业专家(Industry Professionals) 的表现对比,量化 AI 模型在复杂知识型任务中的实用性和可靠性。
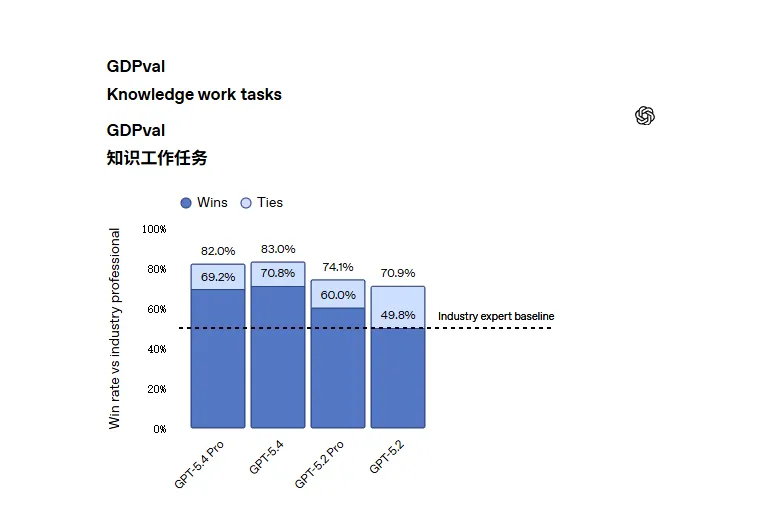
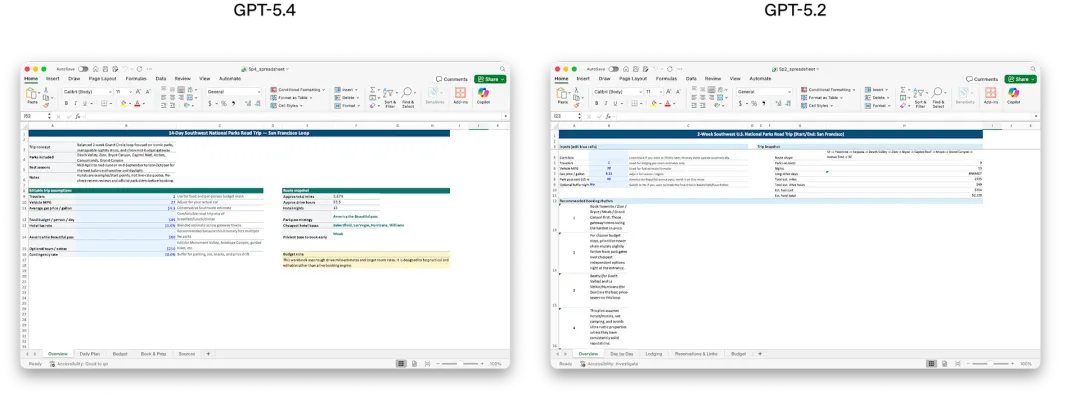
在针对表格建模的内部基准里,GPT-5.4的平均得分为87.3%,而 GPT-5.2 为 68.4%。
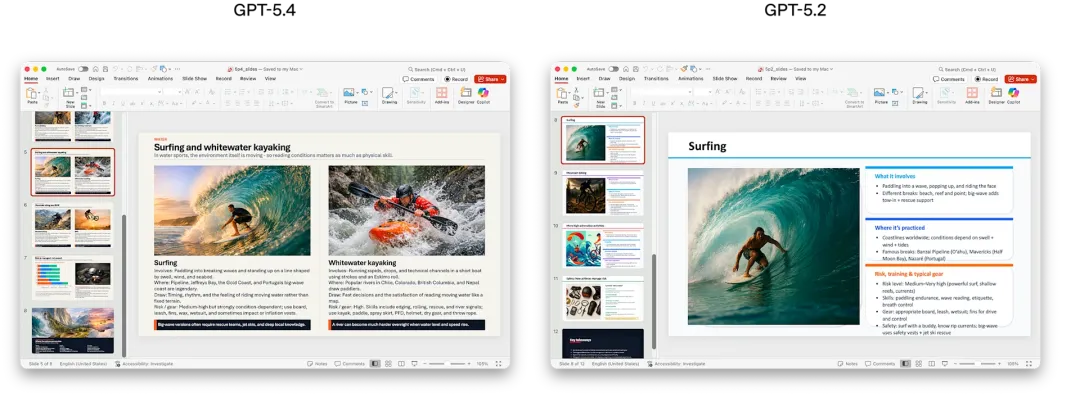
在ppt的质量上,人工评分更倾向于 GPT-5.4(偏好率 68.0%),这些数据说明在做具体、可评估的知识类任务上,官方认为新模型有明显进步。
Computer Use 和视觉感知
GPT-5.4,简直把模型能看见屏幕并动手做事的能力写进了产品说明中,这也就意味着AI可以根据截屏判断界面状态,然后下发键盘或鼠标操作来执行具体步骤。
简单来说,这套能力可以拆成两部分来理解:一是视觉理解,能把像素信息转成结构化的界面元素。
二是动作生成,能把决策转成可执行的操作序列。
GPT-5.4模型现在可以根据屏幕截图识别按钮和输入框,然后生成相应的点击或输入命令,这一步的关键在于把看见和做事两端可靠地连起来。
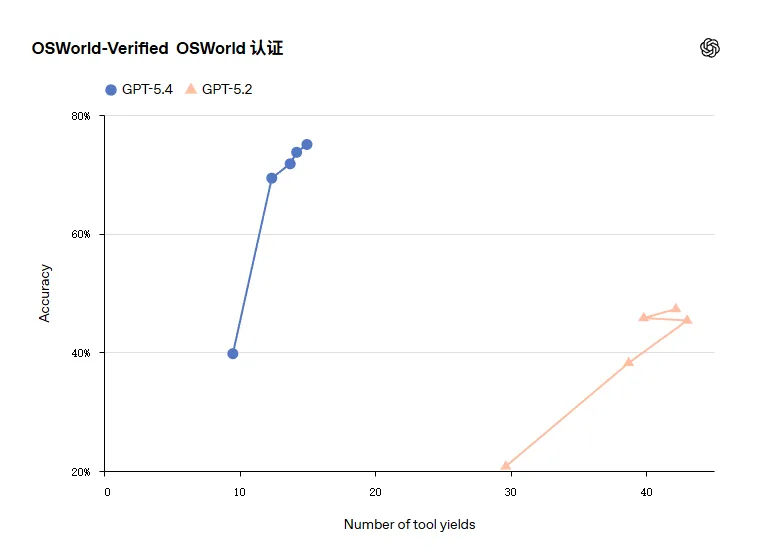
在OSWorld-Verified 75.0%,人类基准 72.4%,OSWorld是由加州大学伯克利分校(UC Berkeley)等机构的研究人员在2024年推出的一个基准测试框架。
目的是用于评估多模态智能体(Multimodal Agents)在真实操作系统环境中的能力。
简单来说,就是测试AI能否像人类一样操作电脑(如点击鼠标、输入文字、管理文件、使用浏览器等)来完成复杂任务。
视觉解析与文档处理
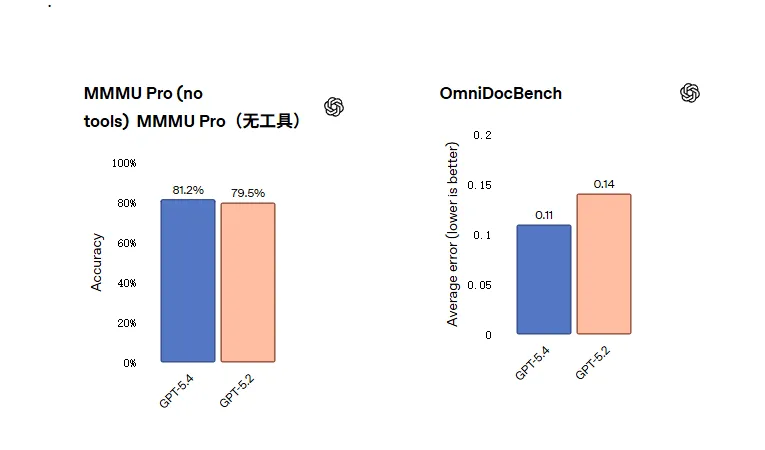
视觉理解基准 MMMU-Pro 上,GPT-5.4 达到 81.2%(比 GPT-5.2 的 79.5% 有提升),文档解析基准 OmniDocBench 的平均错误(normalized edit distance)从GPT-5.2的0.140降到GPT-5.4的0.109,表明在高保真文档读写和结构化输出上更精确。
官方还引入了original图像输入等级,现在GPT-5.4支持最高约10.24M像素或6000px最大边长的高分辨率输入,便于处理细节密集的界面/文档截图。
编码与工具协同
其实GPT-5.4的代码能力可以简单概括为原生专家化和长程可靠性,为什么这么说呢?
因为以往可能需要专门调用Codex系列模型来处理复杂编程,而GPT-5.4将这些专用能力内化了,表现在代码生成、语法理解、Debug上的基准水平直接达到了 GPT-5.3-Codex 的水准。
意味着GPT-5.4不仅是个通用模型,而且还拥有专用代码模型的硬实力,无需切换模型即可处理专业开发任务。
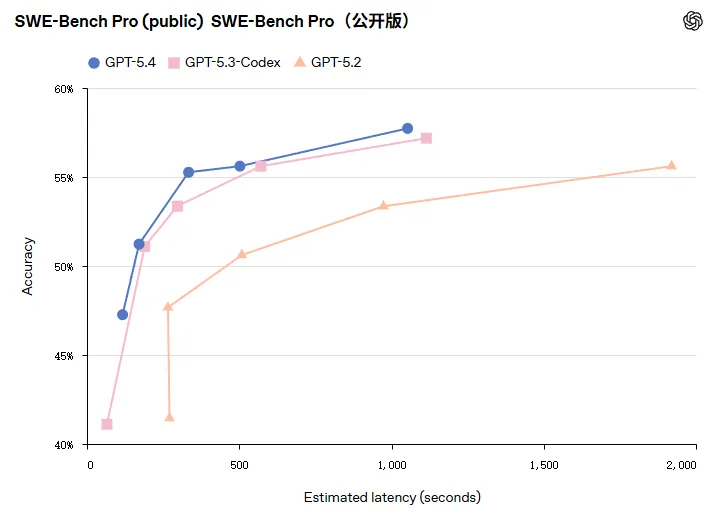
在 SWE-Bench Pro上,GPT-5.4得分为57.7%,略高于前代,官方把GPT-5.3-Codex的编码优势并入GPT-5.4,并同时发布了诸如 Playwright (Interactive) 的实验性 Codex 技能,用来在浏览器/Electron 环境中进行可视化调试与测试。
SWE-Bench (Software Engineering Bench) 是由普林斯顿大学等机构推出的基准测试,旨在评估 AI 解决真实世界软件工程问题的能力。
任务是给定一个GitHub仓库中的真实Issue(问题描述),要求AI生成代码Patch(补丁)来修复该问题。
但官方还提到 /fast 模式能带来至多1.5x 的 token 速率加速,API 层提供优先处理选项以降低延迟。
Tool Search 与 Agent 工具链
在早期的LLM 工具调用(tool calling)架构里,开发者通常采用一种非常直接的方式,就是把所有工具的完整定义一次性放进模型的上下文(prompt)中。
当模型开始推理时,它会在这些工具定义里选择一个进行调用,虽然说这套机制在工具数量不多的时候非常简单有效,但随着Agent 系统规模扩大,问题就开始出现了。
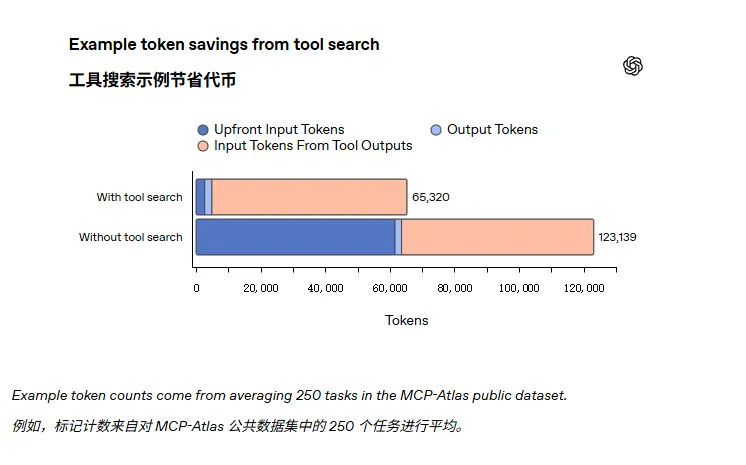
这在工具数量多的系统里会把上下文塞满、增加token成本并拖慢响应,但openai的tool search的思想是先交给模型一份精简的可用工具清单,在模型确实需要调用某个工具时候,再动态检索并把该工具的完整定义附加到对话里。
这样做的好处是既保留了工具可查找性,又避免了每次请求携带海量定义的开销。这个设计在面对含有大量MCP servers的系统时,能显著降低Token使用并提升响应速度。
于是OpenAI在MCP-Atlas的250个任务评测里比较了两种配置:一是把所有 MCP 函数全部暴露在模型上下文中,二是把这些 MCP 服务放在 tool search 后面。
结果显示,tool search 模式在保持相同准确率的前提下,Toeken的使用减少了约47%。这是对大量工具场景下成本与效率改进的直接量化证据。
另外,GPT-5.4还改进了Agentictool calling(工具调用)agentic tool calling是指模型在推理过程中决定何时使用哪些工具、如何并行或串行调用它们,以及在工具返回后如何继续推理。
GPT-5.4 在这方面比前代更准确也更高效,在Toolathlon这类测试上,用更少的交互轮次完成任务的概率更高。
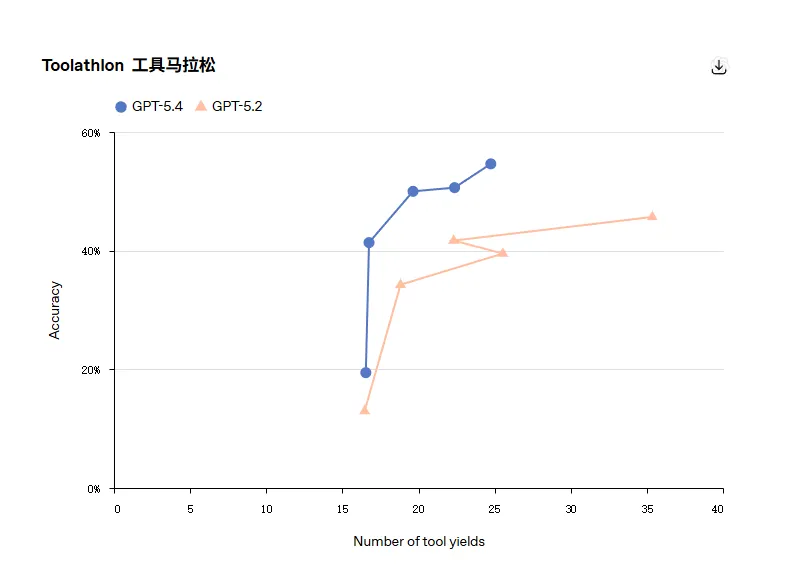
在OpenAI 给出的概念里,tool yield是衡量并行化收益比单纯统计工具调用更有意义的度量。
举例来说,如果一次流程里先并行调用三组工具,然后再并行调用三组工具,则yield数为 2。更少的yields通常意味着更低的总体延迟与更好的并行利用率,所以说这个概念对设计低延迟agent很关键。
写到最后
这篇文章只是对GPT-5.4部分核心的能力进行一个简单的总结概括出来,用大家通俗易懂的语言去描述,所以没有加入实测案例之类的。
感兴趣的朋友,可以打开官方文档,让AI进行一个简单总结解读。
GPT-5.4的官方文档介绍:
https://openai.com/index/introducing-gpt-5-4/
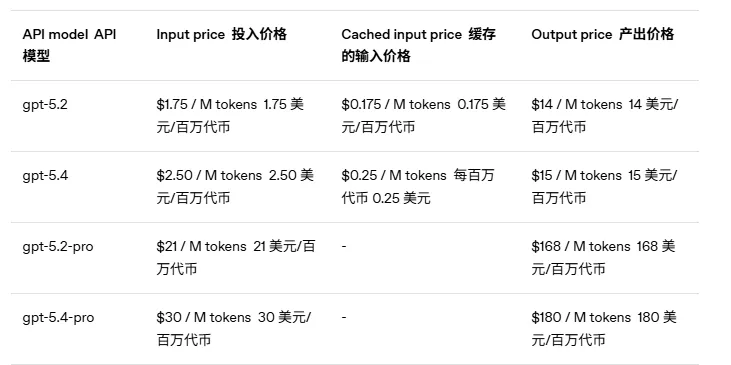
可以说GPT-5.4完全可以接入openclaw实现复杂任务操作,但是价格比较贵了,如图,百万Token输出需要15美元,换成成人民币都快一百多了,有需要的朋友可以选择接入尝试下的。
感谢你能读到这里,目前openclaw的安装教程还在肝,后面我也会第一时间发到公众号,让大家都能0成本0基础搭建属于自己的Openclaw。
欢迎关注公众号,后续还会分享更多实用的AI工具和用法,帮你把 AI 用在实处。
