夜雨聆风
夜雨聆风





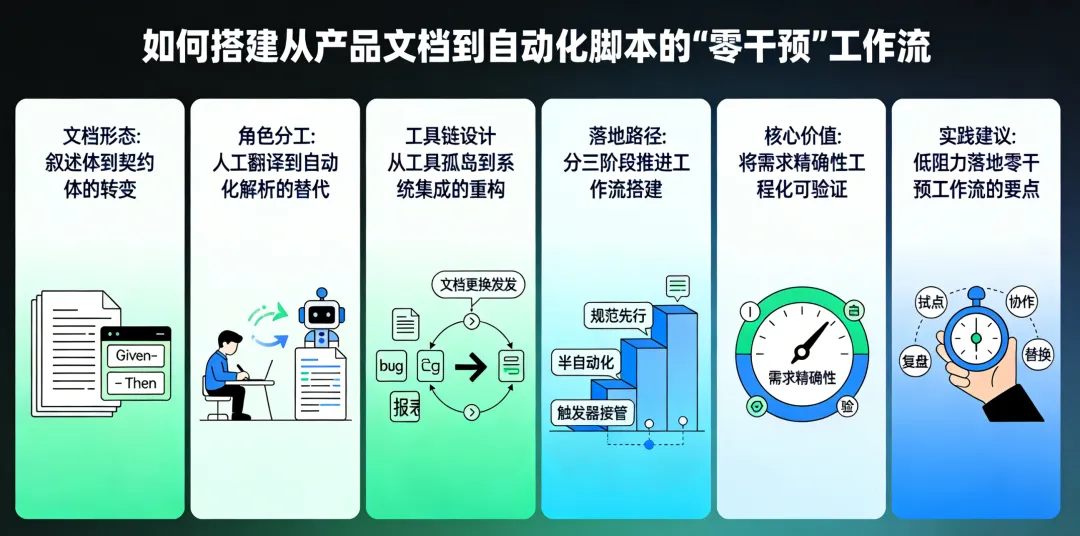
如何搭建从产品文档到自动化脚本的"零干预"工作流
前言
几乎每个有一定规模的技术团队,都曾经历过这样一个尴尬时刻:产品经理更新了 PRD,测试工程师开始手动比对变更,逐条翻译成测试用例,再一行一行地写自动化脚本——这个链路少则两天,多则一周。而在这段时间里,需求已经在迭代,脚本还没跑起来。
这不是效率问题,这是工作流的结构性缺陷。
大多数团队处理“PRD → 测试”这条链路的方式,本质上是把文档当成“参考资料”,让人来做“翻译工作”。而我们真正应该追问的是:PRD 能不能直接就是可执行的用例描述?文档能不能同时承担“沟通载体”和“自动化输入源”两种角色?
这篇文章想讨论的,正是这两种思维模式之间的本质差异——“文档作为参考”与“文档作为契约”——以及如何在这个认知升级的基础上,搭建一套真正意义上的零干预工作流。
文章将从以下几个维度展开:
-
文档形态的对比:非结构化叙述 vs. 结构化契约 -
角色分工的对比:人工翻译 vs. 自动化解析 -
工具链设计的对比:临时拼凑 vs. 系统集成 -
落地路径:如何分阶段推进这套工作流的实际搭建
一、文档形态:从“叙述体”到“契约体”
当 PRD 只是一篇说明文
传统 PRD 的写法,是以产品经理的视角讲述功能的背景、目标和交互逻辑。这种写法天然倾向于叙述性语言:
-
“用户可以在个人中心修改头像” -
“支持上传 JPG、PNG 格式,大小不超过 2MB” -
“上传失败时给出友好提示”
读起来清晰,理解没有障碍。但当测试工程师拿到这份文档,需要提取用例时,他必须自己做出一系列判断:边界值是什么?异常路径有哪些?哪些是主干流程,哪些是边缘场景?
这个“判断过程”,就是信息损耗的源头,也是返工的高发区。
当 PRD 变成结构化契约
契约体的 PRD,不是让产品经理学会写代码,而是约定一种双方都能理解的结构规范。最直接的形式,是在每个功能模块下,用 Given-When-Then 的格式描述行为预期:
-
Given:用户已登录,进入个人中心 -
When:上传一张 3MB 的 JPG 图片 -
Then:系统返回“文件大小超出限制”的错误提示,头像不更新
这种写法,产品经理多花 20% 的时间,却能让后续的用例提取、自动化脚本生成几乎不需要人工介入。
核心差异在于:叙述体传递的是“意图”,契约体传递的是“可验证的行为”。前者需要人来解释,后者可以被机器解析。
二、角色分工:从“人工翻译”到“自动化解析”
测试工程师的隐性成本
在传统流程中,测试工程师承担了大量“翻译”工作:把产品语言翻译成测试语言,再把测试语言翻译成自动化脚本。这部分工作不产生技术资产,无法被复用,也无法被度量。
更危险的是,这种翻译依赖个人理解,不同工程师对同一条需求的解读可能存在偏差。一旦某个边界场景被遗漏,往往要到上线后的 Bug 复盘会上才会暴露。
解析器替代翻译者
当 PRD 采用结构化格式写作后,这条链路可以被工具接管。实际上,目前已有成熟的实践路径:
-
使用 Cucumber / Gherkin 语法规范 PRD 中的验收条件,测试框架可以直接读取 -
借助 LLM(大语言模型) 对非完全结构化的 PRD 进行语义解析,自动生成测试用例草稿 -
通过 CI/CD 管道 在 PRD 文档变更时触发用例更新检查,而不是等待人工通知
一个真实的场景:某中型 SaaS 团队在引入 Gherkin 格式的验收条件后,自动化用例的首次通过率从 61% 提升到 84%,原因不是脚本写得更好,而是需求本身变得更精确了。
这是思维模式升级带来的系统性收益,不是工具替换带来的局部改善。
三、工具链设计:从“临时拼凑”到“系统集成”
工具孤岛的普遍困境
大多数团队的测试工具链,是随着团队成长逐渐“堆”出来的:需求管理用 Confluence,缺陷跟踪用 Jira,自动化脚本放在 Git,测试报告发到飞书群。每个工具都在孤立运转,链接它们的是人的手动操作。
这种拼凑式架构有一个致命弱点:当任何一个环节出现变更,信息需要人来同步,延迟和失真在所难免。
以“文档变更”为触发器的集成设计
零干预工作流的核心设计原则只有一条:让文档变更成为整条链路的唯一触发源。
具体架构可以这样设计:
-
PRD 存储层:采用支持版本控制的文档系统(如 Notion API、Confluence REST API,或直接用 Markdown + Git) -
解析层:在文档更新时,通过 Webhook 触发解析服务,提取结构化用例数据 -
生成层:调用 LLM 或规则引擎,将结构化用例转化为自动化脚本框架(Playwright、Pytest 等) -
执行层:脚本提交至 CI/CD,自动运行并生成报告 -
反馈层:测试结果与原始需求 ID 关联,失败项直接链接回对应 PRD 章节
这条链路一旦跑通,产品经理修改了一条验收条件,12 小时内对应的自动化用例就已经在流水线里跑过了一遍。这不是未来,这是现在可以实现的工程状态。
四、落地路径:分阶段推进,而非一次重构
为什么大多数“流程改造”半途而废
这类工作流改造失败的原因,很少是技术问题,更多是节奏问题。团队试图一次性推翻旧流程、引入新规范、部署新工具,结果在阻力最大的时候,整个改造计划被日常迭代压力淹没。
三个可执行的推进阶段
第一阶段:规范先行(1-2 个迭代)
不引入任何新工具,只做一件事:在现有 PRD 模板中,新增“验收条件”字段,并约定用 Given-When-Then 格式填写。产品、测试双方对齐一次,形成共识。
第二阶段:半自动化(1 个季度)
引入 LLM 辅助工具,将结构化验收条件批量转换为测试用例草稿。测试工程师从“从零编写”变为“审核修改”,工作量降低,质量提升。
第三阶段:触发器接管(持续优化)
在文档系统和 CI/CD 之间建立自动化桥接,让文档变更自动触发用例更新流程。这个阶段需要一定的工程投入,但有前两个阶段的基础,技术风险和组织阻力都已大幅降低。
结尾:超越工具,回归本质
有人会问:这套流程对小团队是否过于复杂?
答案取决于你如何定义“复杂”。如果说“复杂”是指一次性部署的成本,那确实需要投入。但如果你把每个迭代中测试工程师花在手工翻译上的时间加总,把每次需求变更后脚本没有同步更新的风险加总,你会发现现有流程的隐性成本,远比想象中高得多。
这套工作流的核心价值,不在于节省了多少人力,而在于它把“需求精确性”这个原本模糊的质量属性,变成了一个可工程化验证的指标。当文档即契约,当契约即代码,产品与研发之间的信息鸿沟才真正开始收窄。
给有意推进这件事的团队几个建议:
-
从一个模块试点,而不是全面铺开,用数据说话 -
让产品经理参与工具选型,格式规范的推行,产品侧的认可比技术侧的驱动更有效 -
把“文档质量”纳入迭代复盘,与 Bug 率、发布稳定性一起讨论 -
保持工具链的可替换性,核心是规范和数据格式,而不是绑定某一个具体工具
最好的工作流,是那种让每个人都能把精力用在真正需要判断力的地方的工作流。当机器可以处理翻译,人就应该去做设计;当文档可以驱动脚本,工程师就应该去做架构。
这是效率的问题,也是每个技术团队值得认真对待的工程尊严问题。