 夜雨聆风
夜雨聆风





社区OpenClaw三部曲及结合文档layout布局的多模态Embedding思路ColParse
今天是2026年3月7日,星期六,北京,天气晴
看两个东西,一个是openclaw这阵很火,但是火归火,还是需要做个归结,因此,社区也做了一些讨论,形成OpenClaw三部曲,感兴趣的可以看看这波热潮冷静的思考。
另一个还是要回归技术,看结合文档layout布局的文档检索思路ColParse,也是一种结合范畴。
多看,多思考,会有收获。
一、openclaw的一些认识-OpenClaw三部曲
最近openclaw很火,但是从技术角度而言,并没有新的东西,社区也做了系列的讨论,根据讨论的情况,我们形成了社区openclaw三部曲,包括【老刘说NLP-OpenClaw 三部曲之演进篇】、【老刘说NLP-OpenClaw 三部曲之技术篇】-OpenClaw 技术解析、【老刘说NLP-OpenClaw 三部曲之反思篇】,欢迎在社区一同跟进、讨论进展。
综合我们的讨论的结果,社区统一认识的是,这其实是一种全民化的agent体验潮而已,技术上没什么,是产品形态、全民普及的范畴。
所以,如果仅仅谈产品层面,撇开起技术安全性上的风险,择其中的一些对话来看看,会很有意思;
openclaw这波热度怎么走?觉得最主要不是技术面,全是用户面,我跟你讲,我现在搞的很多东西都是略微懂一点技术,养养好虾,当助手。里头其实会养虾的人比例不高的,大多数人养虾养养就是死虾一堆,没用。是有会养虾的,没养的这个虾的能力越来越厉害,因为虾自己会安装工具,自己会长能力就是要被人精心的调教。它确实是个养虾过程。根本不不懂代码的呀,他只是跟瞎聊天,然后先把东西做对了,就就说不错不错,那些虾就记住了,那做错了就就丢掉嘛。
现在问我下的人,大多数跟技术没什么太大关系,要么是管理层,要么是朋友,一直关注AI,但以前不发声,这回虾一出来,好多人都在问,就是说至少这个形式已经打动了普通百姓了。
所以你可以想他实际上百姓怎么写agent的,怎么把agent的调教起来的事儿啊?不能老是找程序员啊,程序员解决问题太麻烦了。第一次让百姓说,我不找程序员自己解决问题多好啊。根本上我觉得还是会很火很火的。我在跟更多的跟技术没什么太大的关系,而是略懂技术的百姓受益最大。技术这个圈子,其实弄下它意意义不大。
技术这头,我觉得可能要关心的就是这个生态,就是,因为你我也看了看他的生态,我觉得他做的还是可以的。虽然代码全是AI写的,我靠,太啰嗦了。问题是这个生态已经把一个架子给定义好了,然后大家往里头贡献啥也弄好了,实际上贡献的也都不是人,估计是人操纵的AI。更大的意义不是技术上的,而是技术怎么能够落地到用户里头。
所以关心技术的人可能这个没啥意义,关心产品的可能这个还是意义挺大的。适合关系产品的人,适合使用产品的百姓用户。我们做技术的,有一天到说Agent…. 这是第一次让百姓知道Agent到底是什么鬼, 他们的意义是什么?他能操纵,他才有认识啊。他不能操纵,永远是被动的呀。就是这样。
二、结合文档layout布局的文档检索思路ColParse
主要讲的故事是视觉文档检索(VDR)任务的思路,基于版面信息的多向量检索与解析视觉文档表示。
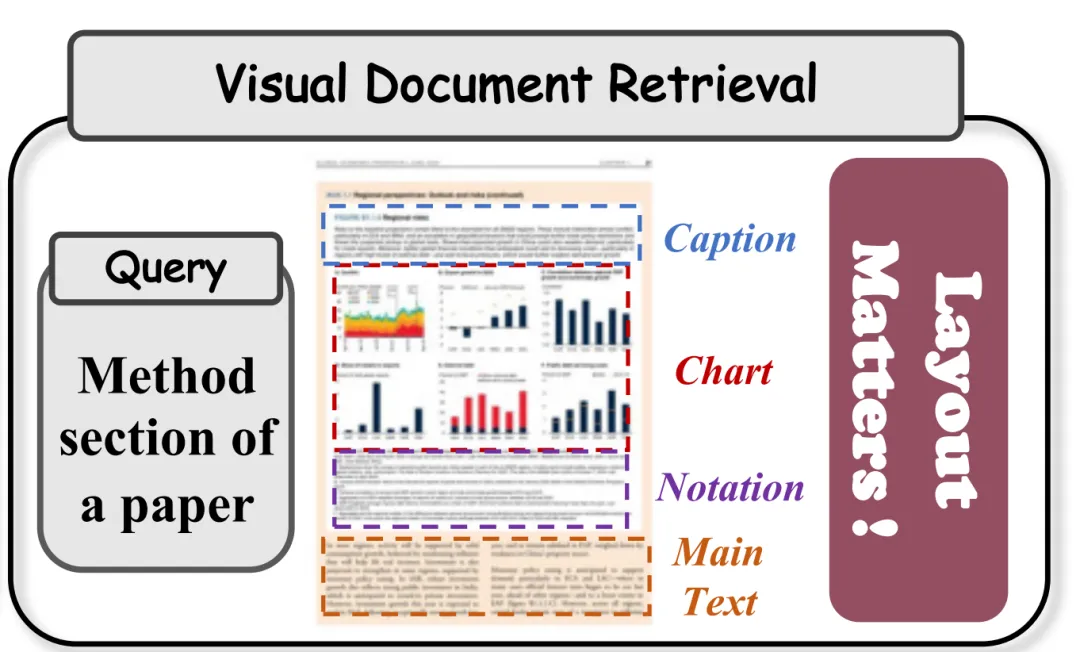
工作在《Beyond the Grid: Layout-Informed Multi-Vector Retrieval with Parsed Visual Document Representations》,https://arxiv.org/pdf/2603.01666,ColParse,思路是提出布局感知的多向量构建思路:通过文档解析提取语义子图像(表格、段落等),融合局部与全局向量,生成紧凑且结构感知的多向量表示。
这里可以先回顾下多向量这种方法:
先说背景,与自然图像检索不同,视觉文档(如学术论文、财务报告和发票)由密集的文字内容、复杂的版式布局以及图形元素共同定义,为有效捕捉这些细粒度的细节,该领域主要采用多向量检索架构,将每页文档表示为一系列块级嵌入,并采用晚期交互机制(如MaxSim)来计算相关性。但其广泛应用受到一个关键瓶颈的制约:存储开销巨大,为每一页存储数百甚至数千个嵌入向量,使得大规模部署变得实际困难。
为解决这一问题,陆续有了多种优化策略:

一个是聚合,例如Light-ColPali使用聚类技术将相似的向量聚合。然而,该方法通常会导致细粒度信息的稀释,从而引起性能不稳定;
一个是剪枝,如DocPruner在剔除冗余嵌入。这些方法在激进压缩下难以维持性能。
一个是额外token,如是MetaEmbed,引入一组抽象的、可学习的token,以形成紧凑的多向量表示。虽然具有创新性,但这些token缺乏对文档固有版面结构的显式锚定,限制了其捕捉关键版面特异性语义的能力。
所以,既然是文档,那就跟文档解析的方法,借助布局信息结合下,所以,就有了ColParse这个工作。
先说思路:
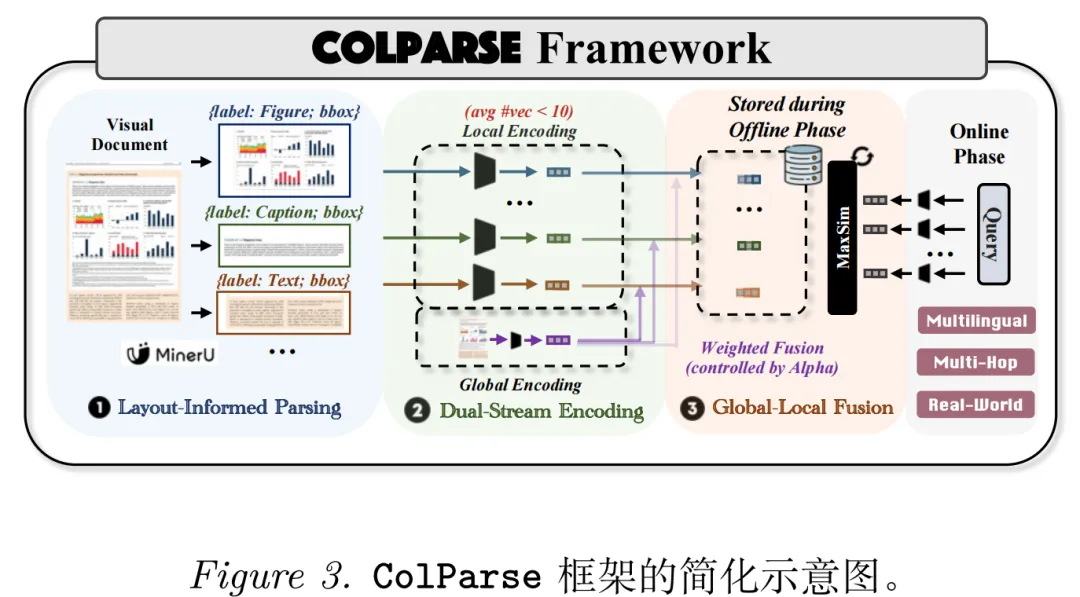
与在统一的图像块网格或抽象token上操作不同,ColParse首先采用一个专用的文档解析模型,将每一页文档智能地分割成少量k语义上有意义、布局信息丰富的子图像(例如:表格、图表、段落),其中k通常小于10。这些k子图像随后由标准的单向量检索模型分别编码,生成k个局部向量。
同时,整页文档被编码以生成一个全局向量,用以捕捉整体上下文信息。最后,通过加权逐元素相加的方式,将全局向量融合到每个k局部向量中。
这一过程为每页文档生成k个融合向量,整合了细粒度的、布局相关的细节以及整体页面级别的上下文信息。
实现流程就是4步骤:
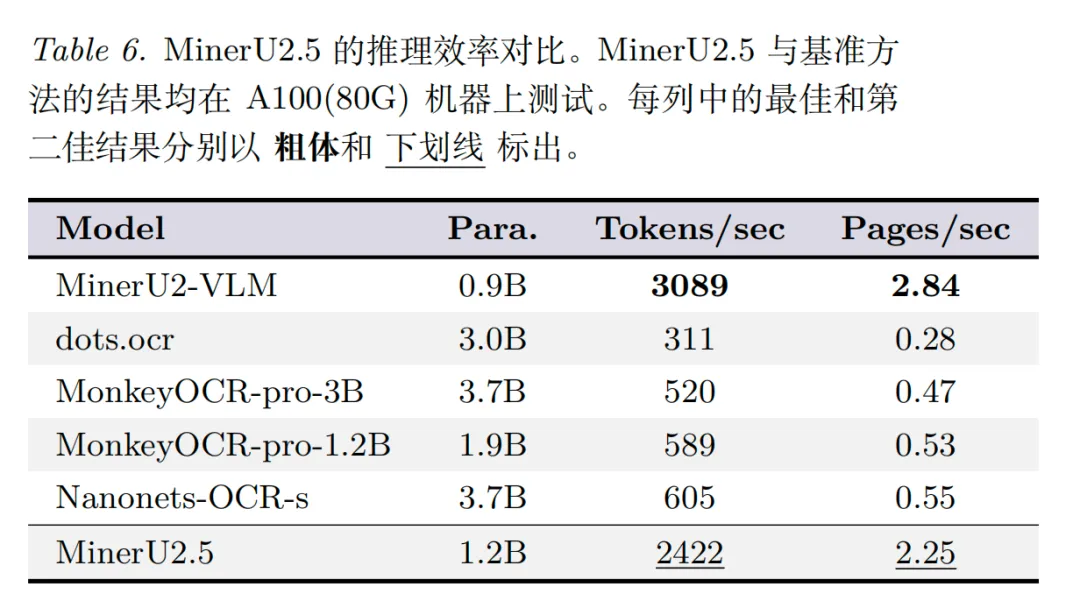
step1.布局解析:用MinerU2.5模型将文档分割为k个(k<10)语义子图像;
step2.双流编码:分别编码子图像(局部向量)和整页文档(全局向量);
step3.加权融合:通过因子α(最优0.6-0.8)融合局部与全局向量,生成最终表示;
step4.在线检索:采用MaxSim计算相关性得分。
最后说几点结论:
ColParse在各种基准测试中始终优于单一向量基础模型【直接送整图拿到向量,如GME-2B/7B等】以及多向量模型【将文档解析出的所有子图像同时输入基础模型,利用其对多图像输入的原生支持,生成一个代表性向量】。受版式信息启发的子图像表示能够捕捉到通常在统一全局嵌入中“稀释”的关键细粒度细节;
基于版面信息的分解在构建多向量方面显著优于传统的token级别切分或聚类思路【基于版式解析结果,将这些token进行分块并聚合,而位于解析边界框之外的token则被丢弃,分成type-cluster(相同内容类型的token通过语义聚类合并)、type-mean(相同内容类型的token通过平均汇聚合并)、subimg-cluster(来自同一子图像区域的token进行聚类)、以及subimg-mean(来自同一子图像区域的token进行汇聚)。】
最后,看下使用效果,如下:
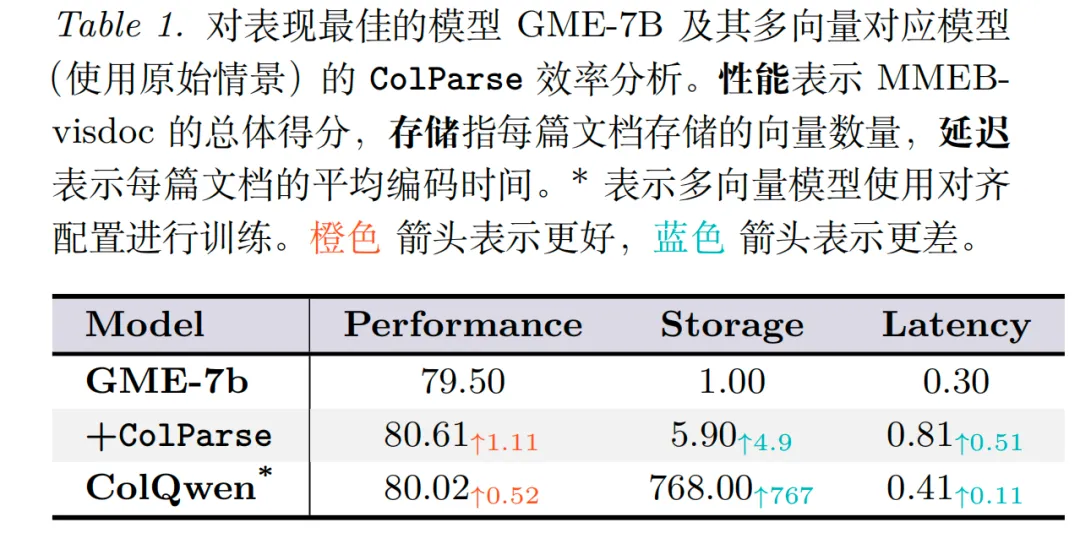
参考文献
1、https://arxiv.org/pdf/2603.01666
关于我们
老刘,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解感兴趣,并对每日早报、老刘说NLP历史线上分享、心得交流等感兴趣的,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。
