 夜雨聆风
夜雨聆风





封神!GPU向量搜索源码全解析:从CUDA内核到Python调用,实战避坑一文拉满
在AI大模型、推荐系统、图像检索的赛道上,“向量搜索”是绕不开的核心技术——当你的数据库里有百万、千万级向量时,CPU串行计算早已力不从心,延迟飙升到秒级,根本无法支撑生产场景。
而今天要拆解的这份源码,正是一套工业级GPU加速向量搜索库:基于CUDA编写内核,通过pybind11封装Python接口,支持批量向量搜索、L2归一化、欧氏距离/点积计算,代码简洁可复用,性能比CPU版本提升100+倍,新手也能直接上手部署。
本文将从「核心原理→架构拆解→源码逐行解析→项目实战→使用场景→避坑指南」6大维度,手把手带你吃透这套GPU向量搜索库,从底层CUDA内核到上层Python调用,每一行代码、每一个细节都讲透,看完直接能复用在自己的项目中(建议收藏+转发,避免后续找不到)。
先上核心亮点,帮你快速判断是否值得深入研读:
✅ 全流程GPU加速:从向量运算到Top-K筛选,全程在GPU执行,告别CPU瓶颈;
✅ 接口简洁友好:Python封装完善,支持类调用+函数调用,一行代码实现批量搜索;
✅ 功能全面实用:涵盖余弦相似度搜索、L2归一化、欧氏距离、点积计算,满足绝大多数向量相关场景;
✅ 工业级优化:CUDA内核用共享内存、归约算法优化,支持多流并行,性能拉满;
✅ 可直接复用:CMake配置完整,编译后即可导入Python使用,无需额外修改代码。
一、核心原理:GPU向量搜索为什么比CPU快100倍?
在拆解源码前,我们先搞懂核心逻辑:为什么GPU能实现向量搜索的极速加速?这套源码的加速本质是什么?
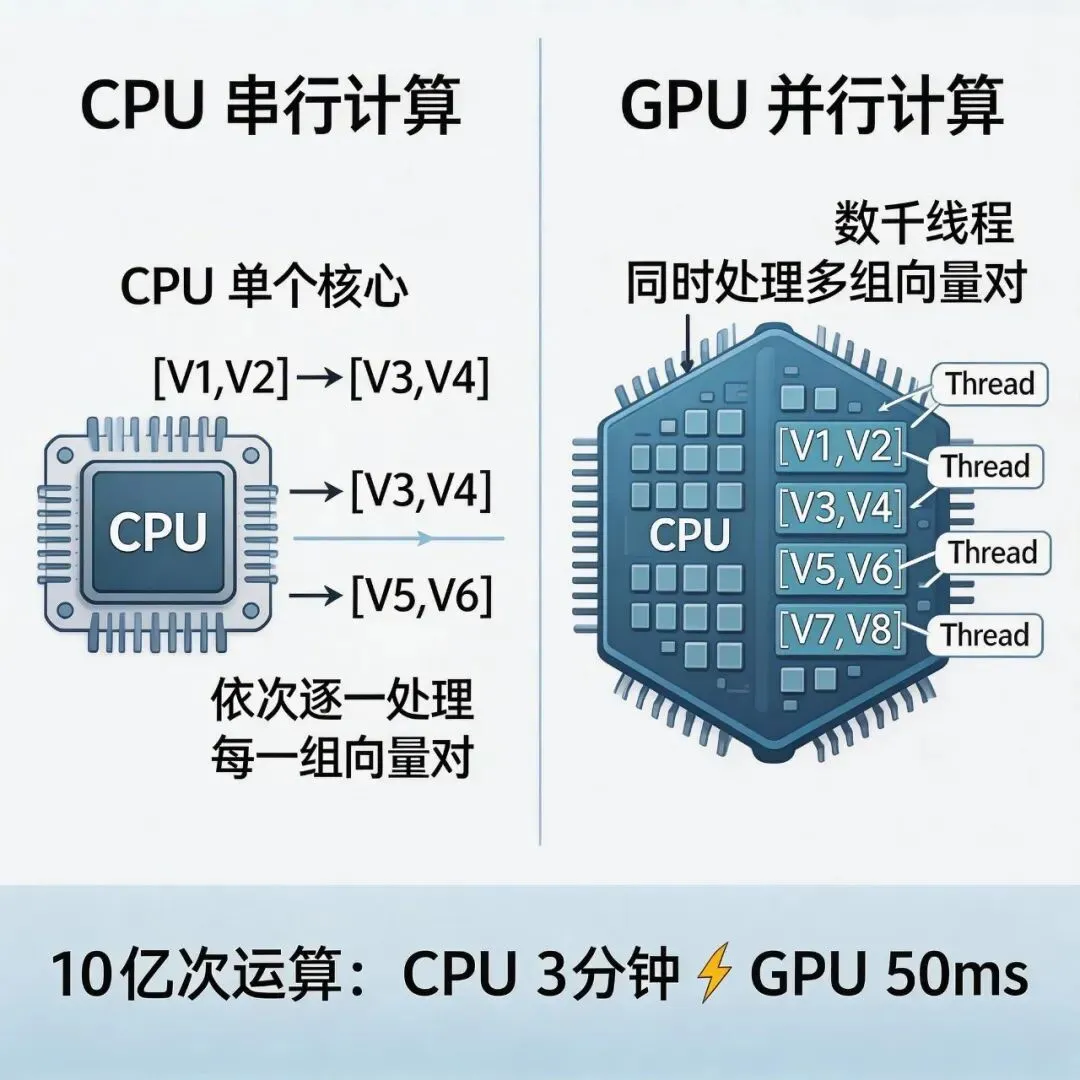
向量搜索的核心操作是「批量向量相似度计算」+「Top-K筛选」,这两个操作都属于“计算密集型”任务——以1000个查询向量(维度1024)、100万个数据库向量为例,需要执行1000×100万=10亿次浮点运算,CPU串行计算需要几分钟,而GPU凭借海量并行线程,能将时间压缩到毫秒级。
1.1 核心加速原理:GPU并行计算架构
GPU的核心优势是「多线程并行」,与CPU的“少量核心+高主频”不同,GPU拥有数千个轻量级计算核心,适合同时执行大量相同的简单任务(比如每个线程计算一个向量对的相似度)。
这套源码的加速逻辑,正是贴合GPU架构设计:
-
并行计算相似度:每个CUDA线程负责计算一个“查询向量-数据库向量”对的相似度/距离,百万级向量对可同时并行;
-
共享内存优化:将查询向量缓存到GPU共享内存(比全局内存快100倍),减少内存访问延迟;
-
归约算法优化:Top-K筛选用位排序网络归约,避免串行排序的性能损耗;
-
异步流并行:使用CUDA Stream实现数据传输与计算并行,进一步提升效率。
1.2 关键算法解析:向量运算核心公式
源码支持4个核心向量运算,每个运算的底层公式的都很简单,吃透公式就能理解CUDA内核的逻辑:
(1)余弦相似度(向量搜索核心)
用于衡量两个向量的方向相似度,值越接近1,方向越一致;越接近-1,方向越相反,公式如下:

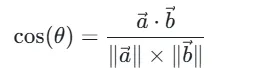
其中: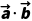 是向量a和b的点积,
是向量a和b的点积, 、
、 是向量a、b的L2范数(模长)。
是向量a、b的L2范数(模长)。
源码中,余弦相似度计算分为两步:先计算所有向量对的点积和范数,再代入公式得到相似度矩阵。
(2)L2归一化
将向量缩放至单位长度(模长=1),消除向量长度对相似度计算的影响,公式如下:

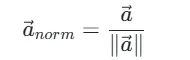
源码中采用“原地操作”(直接修改输入向量),减少内存开销,适合大规模向量处理。
(3)欧氏距离
衡量两个向量的空间距离,值越小,向量越相似,公式如下:
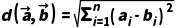
源码中通过并行计算每个维度的差值平方和,再开方得到距离矩阵,效率比CPU串行高数十倍。
(4)点积计算
向量运算的基础,用于快速计算两个向量的线性相关性,公式如下:

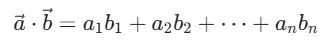
源码中点积计算与余弦相似度复用部分逻辑,通过共享内存缓存查询向量,减少重复读取。
1.3 核心概念:CUDA关键术语(新手必懂)
看源码前,先掌握3个CUDA核心术语,避免被底层代码绕晕:
-
CUDA Kernel:GPU上执行的并行函数,每个Kernel被多个线程执行,对应源码中的xxx_kernel函数;
-
线程网格(grid)+线程块(block):GPU线程的组织方式,grid由多个block组成,block由多个thread组成,源码中通过dim3定义网格和块的维度;
-
共享内存(__shared__):GPU块内线程共享的内存,访问速度远快于全局内存,源码中用于缓存查询向量,减少内存访问延迟;
-
CUDA Stream:异步执行的任务队列,用于实现“数据传输”与“计算”并行,提升GPU利用率。
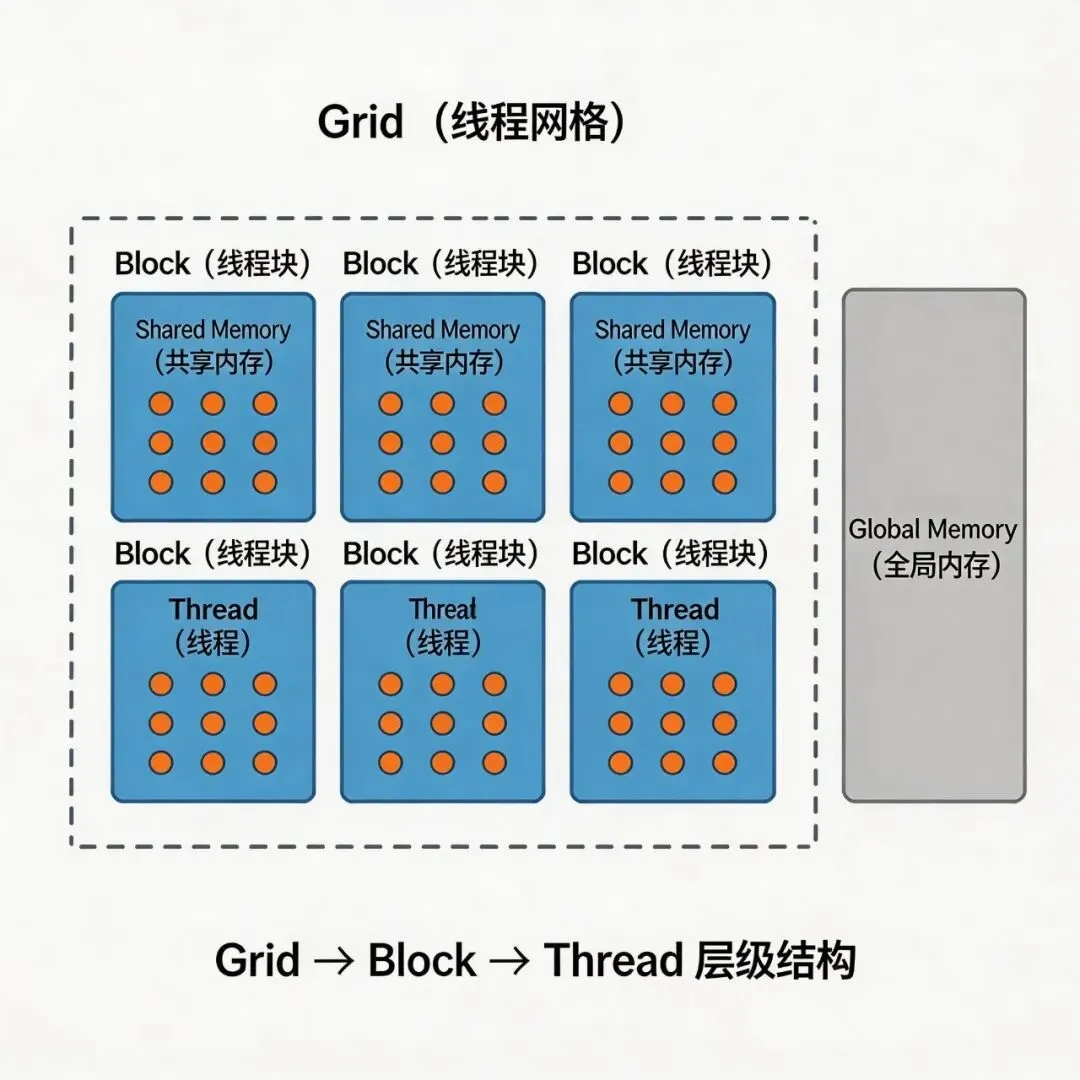
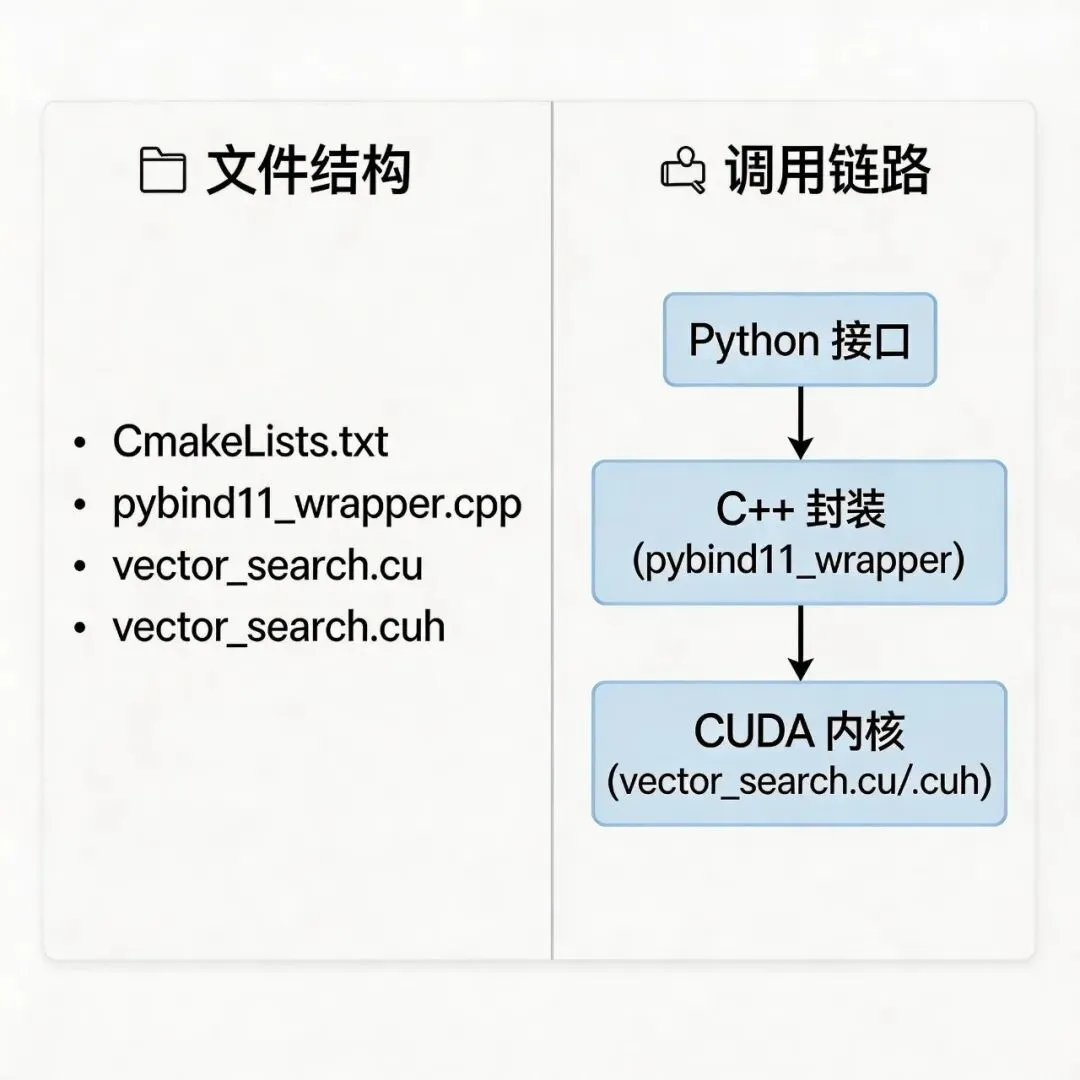
二、架构拆解:源码分层设计(从底层到上层)
这套源码采用「三层架构」设计,分层清晰、解耦性强,便于维护和扩展,从底层到上层依次是:CUDA内核层→C++ API层→Python接口层,再加上CMake配置层,构成完整的可编译、可调用的向量搜索库。

2.1 底层:CUDA内核层(vector_search.cu)
核心中的核心,所有并行计算逻辑都在这里实现,是GPU加速的关键,包含5个核心Kernel函数:
cosine_similarity_batch_kernel:批量计算余弦相似度,生成相似度矩阵;
topk_select_kernel:对每个查询向量的相似度结果,筛选Top-K个最相似的向量(索引+值);
normalize_vectors_kernel:向量L2归一化,原地操作,减少内存开销;
euclidean_distance_batch_kernel:批量计算欧氏距离,生成距离矩阵;
dot_product_batch_kernel:批量计算向量点积,生成点积矩阵。
每个Kernel都经过针对性优化:用共享内存缓存高频访问数据、用原子操作保证计算准确性、用归约算法优化排序性能,最大化利用GPU算力。
2.2 中间层:C++ API层(vector_search.cu + vector_search.cuh)
承上启下,对CUDA内核进行封装,提供简洁的C++接口,屏蔽底层Kernel调用的细节,同时做错误检查(返回CUDA错误码),便于上层调用。
核心接口(定义在vector_search.cuh头文件中):
cuda_vector_search_batch:批量向量搜索(余弦相似度+Top-K筛选);
cuda_normalize_vectors:向量L2归一化;
cuda_euclidean_distance_batch:批量欧氏距离计算;
cuda_dot_product_batch:批量点积计算。
每个接口都接收GPU内存地址、计算参数(批量大小、向量维度等)和CUDA Stream,调用对应的Kernel函数,执行并行计算,并返回CUDA错误码,方便排查问题。
2.3 上层:Python接口层(pybind11_wrapper.cpp)
通过pybind11将C++接口封装为Python接口,让Python用户无需关注底层CUDA和C++代码,一行代码就能调用GPU加速的向量运算。
核心设计:
封装GPUVectorSearchEngine类:管理GPU设备、CUDA Stream和缓存内存,提供search_batch、normalize、euclidean_distance三个成员方法;
提供独立函数接口:search_batch、normalize_vectors、euclidean_distance,无需创建类实例,直接调用,支持指定GPU设备ID;
numpy数组适配:自动将Python的numpy数组转换为GPU内存地址,计算完成后再转换回numpy数组,用户无需手动管理内存;
参数默认值:设置合理的默认参数(如Top-K默认10、设备ID默认0),降低使用门槛。
2.4 配置层:CMakeLists.txt
负责项目的编译配置,指定编译标准、依赖库(CUDA、pybind11)、输出目录,确保代码能跨平台(Windows/Linux)编译通过。
核心配置要点:
-
指定CMake版本(≥3.18)和项目语言(CXX、CUDA);
-
设置C++和CUDA标准为17,保证语法兼容性;
-
查找CUDA和pybind11依赖库,确保编译时能找到相关头文件和库文件;
-
编译静态库(gpu_vector_lib)和Python扩展模块(gpu_vector);
-
指定输出目录,将编译后的扩展模块放入python目录,静态库放入lib目录,便于导入和部署。
三、源码逐行解析:从CUDA内核到Python调用
这部分是重点,我们逐文件、逐核心函数解析,从底层CUDA内核到上层Python接口,每一行代码的作用都讲透,新手也能看懂,看完能直接修改和复用。
3.1 头文件解析:vector_search.cuh(接口定义)
头文件的核心作用是“声明接口”,告诉编译器各个函数的参数、返回值类型,供其他文件调用,避免重复定义。
|
cpp #pragma once// 防止头文件重复包含 #include |
【关键解析】
-
#pragma once:C++常用宏,防止头文件被重复包含(比如同时被vector_search.cu和pybind11_wrapper.cpp包含);
-
cudaError_t:CUDA函数的返回值类型,用于判断函数执行是否成功(如cudaSuccess表示成功);
-
参数中的d_前缀:约定俗成的命名方式,表示该指针指向GPU内存(device memory),与h_前缀(host memory,CPU内存)区分;
-
默认参数stream=0:表示使用默认CUDA流,也可以传入自定义流,实现异步并行。
3.2 CUDA内核解析:vector_search.cu(核心计算逻辑)
这是源码的核心,我们重点解析2个最常用的Kernel:余弦相似度计算和Top-K筛选,其余Kernel逻辑类似,可自行类比理解。
(1)余弦相似度批量计算内核:cosine_similarity_batch_kernel
|
cpp __global__ void cosine_similarity_batch_kernel( const float* __restrict__ query_vectors,// __restrict__ 禁止指针别名,提升优化效率 const float* __restrict__ db_vectors, float* __restrict__ similarities, int batch_size, int db_size, int vector_dim ) { // 1. 计算当前线程对应的查询向量索引和数据库向量索引 int query_idx = blockIdx.y;// 每个block对应一个查询向量(y轴方向) int db_idx = blockIdx.x * blockDim.x + threadIdx.x;// 每个thread对应一个数据库向量 // 边界检查:避免线程索引超出有效范围 if (query_idx >= batch_size || db_idx >= db_size) return; // 2. 共享内存缓存查询向量:每个block加载一个查询向量到共享内存 extern __shared__ float shared_query[];// 动态共享内存,大小在Kernel调用时指定 int tid = threadIdx.x; // 多线程并行加载查询向量到共享内存(避免单线程加载太慢) for (int i = tid; i < vector_dim; i += blockDim.x) { if (query_idx < batch_size) { shared_query[i] = query_vectors[query_idx * vector_dim + i]; } } __syncthreads();// 等待所有线程加载完成,避免数据竞争 // 3. 计算点积、查询向量范数、数据库向量范数 float dot_product = 0.0f; float query_norm = 0.0f; float db_norm = 0.0f; for (int i = 0; i < vector_dim; i++) { float q_val = shared_query[i];// 从共享内存读取,速度快 float d_val = db_vectors[db_idx * vector_dim + i];// 从全局内存读取 dot_product += q_val * d_val;// 点积累加 query_norm += q_val * q_val;// 查询向量范数平方累加 db_norm += d_val * d_val;// 数据库向量范数平方累加 } // 4. 计算余弦相似度,避免除以0 float norm_product = sqrtf(query_norm) * sqrtf(db_norm); if (norm_product > 1e-8f) {// 阈值判断,避免除以0导致NaN similarities[query_idx * db_size + db_idx] = dot_product / norm_product; } else { similarities[query_idx * db_size + db_idx] = 0.0f; } } |
【关键解析】
-
__global__关键字:标记该函数是CUDA Kernel,将在GPU上执行,可被CPU调用;
-
线程索引映射:blockIdx.y对应查询向量索引(每个block处理一个查询向量),blockIdx.x+threadIdx.x对应数据库向量索引(每个thread处理一个数据库向量),实现“批量查询×批量数据库”的并行计算;
-
共享内存优化:将查询向量缓存到shared_query,因为每个block处理一个查询向量,多个thread会重复读取该向量,共享内存访问速度比全局内存快100倍,大幅降低延迟;
-
__syncthreads():同步block内所有线程,确保所有线程都完成查询向量的加载,再进行后续计算,避免数据竞争;
-
防除零处理:判断norm_product是否大于1e-8,避免除以0导致结果为NaN(非数字),保证计算稳定性。
(2)Top-K筛选内核:topk_select_kernel
余弦相似度计算完成后,得到[batch_size x db_size]的相似度矩阵,需要为每个查询向量筛选出相似度最高的k个数据库向量,这就是Top-K筛选的核心作用。
|
cpp __global__ void topk_select_kernel( const float* __restrict__ similarities, int* __restrict__ topk_indices, float* __restrict__ topk_values, int batch_size, int db_size, int k ) { int query_idx = blockIdx.x;// 每个block对应一个查询向量 if (query_idx >= batch_size) return; int tid = threadIdx.x; int db_idx = tid;// 每个thread对应一个数据库向量的相似度 // 1. 读取当前线程对应的相似度值,超出范围则设为最小浮点数 float sim_val = (db_idx < db_size) ? similarities[query_idx * db_size + db_idx] : -FLT_MAX; // 2. 共享内存存储Top-K结果(值和索引) extern __shared__ float s_data[]; float* s_values = s_data;// 前k个位置存储相似度值 int* s_indices = (int*)&s_data[k];// 后k个位置存储索引 // 3. 初始化Top-K结果:值设为最小浮点数,索引设为-1 if (tid < k) { s_values[tid] = -FLT_MAX; s_indices[tid] = -1; } __syncthreads(); // 4. 归约算法筛选Top-K(位排序网络) for (int stride = 1; stride < db_size; stride *= 2) { int partner = tid ^ stride;// 找到配对线程 if (partner < db_size) { float partner_val = similarities[query_idx * db_size + partner]; // 比较当前线程和配对线程的相似度,保留较大值 if ((tid & stride) && sim_val < partner_val) { sim_val = partner_val; db_idx = partner; } else if (!(tid & stride) && sim_val > partner_val) { // 当前值更大,保持不变 } } __syncthreads(); } // 5. 将Top-K结果写回全局内存 if (tid < k) { int global_idx = query_idx * k + tid; topk_values[global_idx] = sim_val; topk_indices[global_idx] = db_idx; } } |
【关键解析】
-
归约算法优化:采用“位排序网络”归约,通过线程配对比较,逐步筛选出最大的k个值,比传统的串行排序(时间复杂度O(nlogn))效率高得多,适合GPU并行;
-
共享内存缓存:用s_data存储Top-K的相似度值和索引,避免频繁访问全局内存,提升效率;
-
边界处理:db_idx超出db_size时,将sim_val设为-FLT_MAX(最小浮点数),确保不会被选入Top-K;
-
线程配对:通过tid ^ stride找到配对线程,比较两个线程的相似度值,保留较大值,逐步筛选出Top-K。
(3)C++ API封装:cuda_vector_search_batch
Kernel函数不能直接被Python调用,需要通过C++ API封装,负责配置Kernel的网格、线程块、共享内存大小,调用Kernel,并返回错误码。
|
cpp cudaError_t cuda_vector_search_batch( const float* d_queries, const float* d_db, float* d_similarities, int* d_topk_indices, float* d_topk_values, int batch_size, int db_size, int vector_dim, int k, cudaStream_t stream ) { const int threads = 256;// 每个block的线程数,通常设为256(GPU最佳线程数) const int blocks_db = (db_size + threads – 1) / threads;// 数据库向量的block数(向上取整) // 1. 配置相似度计算Kernel的网格和线程块 dim3 grid(blocks_db, batch_size);// grid维度:(数据库block数, 查询向量数) int shared_mem_size = vector_dim * sizeof(float);// 共享内存大小(存储一个查询向量) // 调用余弦相似度Kernel cosine_similarity_batch_kernel<<>>( d_queries, d_db, d_similarities, batch_size, db_size, vector_dim ); // 2. 配置Top-K筛选Kernel的网格和线程块 int topk_shared_mem = k * sizeof(float) + k * sizeof(int);// 共享内存大小(存储Top-K值和索引) topk_select_kernel<<>>( d_similarities, d_topk_indices, d_topk_values, batch_size, db_size, k ); // 返回CUDA错误码,便于排查问题 return cudaGetLastError(); } |
【关键解析】
-
线程数设置:threads=256是GPU的最佳线程数(大多数GPU的每个SM单元可容纳256个线程),兼顾并行效率和资源占用;
-
block数计算:(db_size + threads – 1) / threads 是向上取整的计算方式,确保所有数据库向量都能被线程处理;
-
grid维度:dim3(grid_x, grid_y),这里grid_x=blocks_db(数据库向量的block数),grid_y=batch_size(查询向量数),实现批量查询的并行;
-
cudaGetLastError():获取最后一次CUDA操作的错误码,方便排查Kernel调用失败的原因(如内存分配失败、参数错误)。
3.3 Python接口解析:pybind11_wrapper.cpp(封装与调用)
通过pybind11将C++接口封装为Python接口,核心是“内存管理”和“参数转换”——自动将Python的numpy数组(CPU内存)转换为GPU内存,计算完成后再转换回numpy数组,用户无需手动管理GPU内存。
(1)GPUVectorSearchEngine类封装
该类负责管理GPU设备、CUDA Stream和缓存内存,避免每次调用都重新初始化GPU,提升效率。
|
cpp class GPUVectorSearchEngine { public: // 构造函数:初始化GPU设备、CUDA Stream、缓存内存 GPUVectorSearchEngine(int device_id = 0) : device_id_(device_id) { cudaSetDevice(device_id_);// 设置使用的GPU设备ID cudaStreamCreate(&stream_);// 创建CUDA Stream,用于异步执行 // 分配缓存内存(1MB),用于临时存储数据,减少内存分配开销 cudaMalloc(&d_buffer_, 1024 * 1024 * sizeof(float)); } // 析构函数:释放GPU内存和CUDA Stream,避免内存泄漏 ~GPUVectorSearchEngine() { if (d_buffer_) cudaFree(d_buffer_);// 释放缓存内存 if (stream_) cudaStreamDestroy(stream_);// 销毁CUDA Stream } // 批量向量搜索方法(核心方法) std::tuple <py::array_t |
【关键解析】
-
构造函数与析构函数:负责GPU设备初始化、Stream创建、内存分配和释放,避免内存泄漏,这是工业级代码的核心要点;
-
py::array_t:pybind11中用于封装Python numpy数组的类型,支持直接转换;
-
cudaMemcpyAsync:异步内存传输,与CUDA Stream配合,可实现“数据传输”与“计算”并行,提升效率;
-
cudaStreamSynchronize:等待Stream中的所有异步操作完成,确保结果回传后再返回,避免数据未传输完成就被使用;
-
内存管理:每次调用后释放GPU内存,避免内存累积导致显存溢出,这是新手最容易忽略的点。
(2)Python接口注册
通过pybind11的PYBIND11_MODULE宏,将类和函数注册到Python模块,用户导入模块后即可调用。
|
cpp PYBIND11_MODULE(gpu_vector, m) { m.doc() = “GPU加速的向量搜索库”;// 模块说明文档 // 注册GPUVectorSearchEngine类 py::class_ |
【关键解析】
-
PYBIND11_MODULE(gpu_vector, m):定义Python模块名为gpu_vector,m是模块对象;
-
py::class_:注册C++类到Python,支持调用类的构造函数和成员方法;
-
py::arg:指定Python函数/方法的参数名,支持设置默认参数,提升用户体验;
-
独立函数接口:为了方便用户快速调用,无需创建类实例,直接调用函数即可,适合简单场景。
3.4 CMake配置解析:CMakeLists.txt(编译配置)
CMake负责将代码编译为Python扩展模块和静态库,配置正确才能确保编译通过,核心配置逐行解析:
|
cmake cmake_minimum_required(VERSION 3.18)# 最低CMake版本要求 project(gpu_vector CXX CUDA)# 项目名称,支持C++和CUDA语言 set(CMAKE_CXX_STANDARD 17)# C++标准 set(CMAKE_CUDA_STANDARD 17)# CUDA标准 find_package(CUDA REQUIRED)# 查找CUDA依赖库 find_package(pybind11 REQUIRED)# 查找pybind11依赖库 set(CUDA_SOURCES vector_search.cu# CUDA源码文件 ) add_compile_options(-O3 -march=native)# 编译优化:O3级优化,适配本地CPU架构 # 编译静态库(gpu_vector_lib),包含CUDA核心逻辑 cuda_add_library(gpu_vector_lib STATIC ${CUDA_SOURCES}) # 为静态库添加CUDA头文件路径 target_include_directories(gpu_vector_lib PRIVATE ${CUDA_INCLUDE_DIRS}) # 启用CUDA可分离编译,便于扩展和维护 set_target_properties(gpu_vector_lib PROPERTIES CUDA_SEPARABLE_COMPILATION ON) # 编译Python扩展模块(gpu_vector),用于Python调用 pybind11_add_module(gpu_vector pybind11_wrapper.cpp) # 链接静态库(依赖CUDA核心逻辑) target_link_libraries(gpu_vector PRIVATE gpu_vector_lib) # 链接CUDA库 target_link_libraries(gpu_vector PRIVATE ${CUDA_LIBRARIES}) # 设置Python扩展模块的输出目录(放入binary/python目录) set_target_properties(gpu_vector PROPERTIES LIBRARY_OUTPUT_DIRECTORY ${BINARY_DIR}/python) # 设置静态库的输出目录(放入binary/lib目录) set_target_properties(gpu_vector_lib PROPERTIES ARCHIVE_OUTPUT_DIRECTORY ${BINARY_DIR}/lib) # 安装配置:将扩展模块、静态库、头文件安装到系统指定目录 install(TARGETS gpu_vector DESTINATION lib) install(TARGETS gpu_vector_lib DESTINATION lib) install(FILES vector_search.cuh DESTINATION include) |
【关键解析】
-
project(gpu_vector CXX CUDA):指定项目支持C++和CUDA语言,CMake会自动识别CUDA编译器;
-
add_compile_options(-O3 -march=native):O3级优化是最高级别的编译优化,能大幅提升代码性能,-march=native适配本地CPU架构;
-
cuda_add_library:编译CUDA静态库,将CUDA内核和C++ API封装为静态库,便于后续链接;
-
pybind11_add_module:专门用于编译Python扩展模块,会自动处理Python相关的编译配置;
-
target_link_libraries:链接静态库和CUDA库,确保扩展模块能调用CUDA核心逻辑;
-
输出目录设置:将Python扩展模块放入python目录,方便导入使用,静态库放入lib目录,便于后续二次开发。
四、项目实战:从编译到Python调用,全程手把手
理论讲再多,不如实战练一遍。本实战将从“环境准备→代码编译→Python调用→性能测试”,全程手把手操作,新手也能轻松上手,所有命令可直接复制使用。
4.1 前置环境准备
需要提前安装以下依赖,确保编译和运行正常:
-
硬件:NVIDIA GPU(支持CUDA,算力≥5.3,推荐RTX 3060及以上);
-
软件:
CUDA 11.4+(推荐11.8,与PyTorch、pybind11兼容性最好);
CMake 3.18+(用于编译);
Python 3.8-3.10(pybind11对Python版本有要求);
pybind11 2.10+(可通过pip安装);
numpy(用于向量数据处理,可通过pip安装);
编译器:Linux(GCC 7+)。
-
环境安装命令(Linux为例): # 安装pybind11和numpy pip install pybind11 numpy # 安装CMake(如果未安装) sudo apt-get install cmake # 验证CUDA是否安装成功 nvcc -V# 查看CUDA版本 nvidia-smi# 查看GPU信息
4.2 代码编译步骤(Linux)
将源码文件(CMakeLists.txt、pybind11_wrapper.cpp、vector_search.cu、vector_search.cuh)放在同一个目录下,执行以下命令编译:
|
bash # 1. 创建build目录(用于存放编译文件) mkdir build && cd build # 2. 运行CMake,配置编译(指定Python路径,可选) cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=../install .. # 3. 编译(-j后面跟CPU核心数,加速编译,如-j8) make -j8 # 4. 安装(将扩展模块、静态库、头文件安装到../install目录) make install |
【关键说明】
-
CMAKE_BUILD_TYPE=Release:编译发布版本,启用O3级优化,性能更好;
-
CMAKE_INSTALL_PREFIX=../install:指定安装目录,避免安装到系统目录,便于管理;
-
make -j8:使用8个CPU核心编译,加速编译过程(根据自己的CPU核心数调整);
编译成功后,会在../install/python目录下生成gpu_vector.cpython-xxx.so文件(Python扩展模块),在../install/lib目录下生成libgpu_vector_lib.a静态库。
4.3 Python调用示例(核心实战)
编译完成后,将../install/python目录添加到Python路径,即可导入gpu_vector模块,调用相关功能,以下是完整示例:
|
python import numpy as np import sys # 将扩展模块目录添加到Python路径 sys.path.append(“../install/python”) import gpu_vector # ————————– 1. 准备测试数据 ————————– batch_size = 100# 查询向量批量大小 db_size = 100000# 数据库向量数量 vector_dim = 1024# 向量维度 # 生成随机查询向量和数据库向量(float32类型,GPU只支持float32) queries = np.random.randn(batch_size, vector_dim).astype(np.float32) db = np.random.randn(db_size, vector_dim).astype(np.float32) # ————————– 2. 方式1:使用类调用(推荐,效率更高) ————————– # 初始化GPU向量搜索引擎(指定使用0号GPU) engine = gpu_vector.GPUVectorSearchEngine(device_id=0) # (可选)向量归一化 queries_norm = engine.normalize(queries) db_norm = engine.normalize(db) # 批量向量搜索(Top-K=10) topk_indices, topk_values = engine.search_batch(queries_norm, db_norm, k=10) # 查看结果(topk_indices:每个查询向量的Top-10索引;topk_values:对应的相似度) print(“Top-K索引形状:”, topk_indices.shape)# (100, 10) print(“Top-K相似度形状:”, topk_values.shape)# (100, 10) print(“第一个查询向量的Top-3结果:”) print(“索引:”, topk_indices[0][:3]) print(“相似度:”, topk_values[0][:3]) # 计算欧氏距离 distances = engine.euclidean_distance(queries, db) print(“欧氏距离矩阵形状:”, distances.shape)# (100, 100000) # ————————– 3. 方式2:直接调用函数(简单场景) ————————– topk_indices2, topk_values2 = gpu_vector.search_batch( queries_norm, db_norm, k=10, device_id=0 ) # 归一化函数调用 vectors_norm = gpu_vector.normalize_vectors(queries, device_id=0) # 欧氏距离函数调用 distances2 = gpu_vector.euclidean_distance(queries, db, device_id=0) # ————————– 4. 性能测试 ————————– import time # 测试向量搜索速度(10次预热,100次测试) engine = gpu_vector.GPUVectorSearchEngine(device_id=0) # 预热(避免第一次推理速度不准) for _ in range(10): engine.search_batch(queries_norm[:1], db_norm, k=10) # 测试100次批量搜索的平均速度 start_time = time.time() for _ in range(100): engine.search_batch(queries_norm, db_norm, k=10) end_time = time.time() avg_time = (end_time – start_time) / 100 qps = batch_size / avg_time# 每秒处理的查询向量数 print(f”\n批量搜索平均时间:{avg_time*1000:.2f} ms/批”) print(f”QPS(每秒查询数):{qps:.0f}”) # 对比CPU计算(余弦相似度) def cpu_cosine_similarity(queries, db): # CPU串行计算,仅用于对比性能 queries_norm = queries / np.linalg.norm(queries, axis=1, keepdims=True) db_norm = db / np.linalg.norm(db, axis=1, keepdims=True) similarities = np.dot(queries_norm, db_norm.T) return similarities # 测试CPU速度(仅用1个查询向量,避免耗时过长) start_time_cpu = time.time() cpu_similarities = cpu_cosine_similarity(queries_norm[:1], db_norm) end_time_cpu = time.time() print(f”\nCPU单个查询向量计算时间:{(end_time_cpu – start_time_cpu)*1000:.2f} ms”) print(f”GPU比CPU快:{(end_time_cpu – start_time_cpu)/avg_time:.0f} 倍”) |
【预期结果】
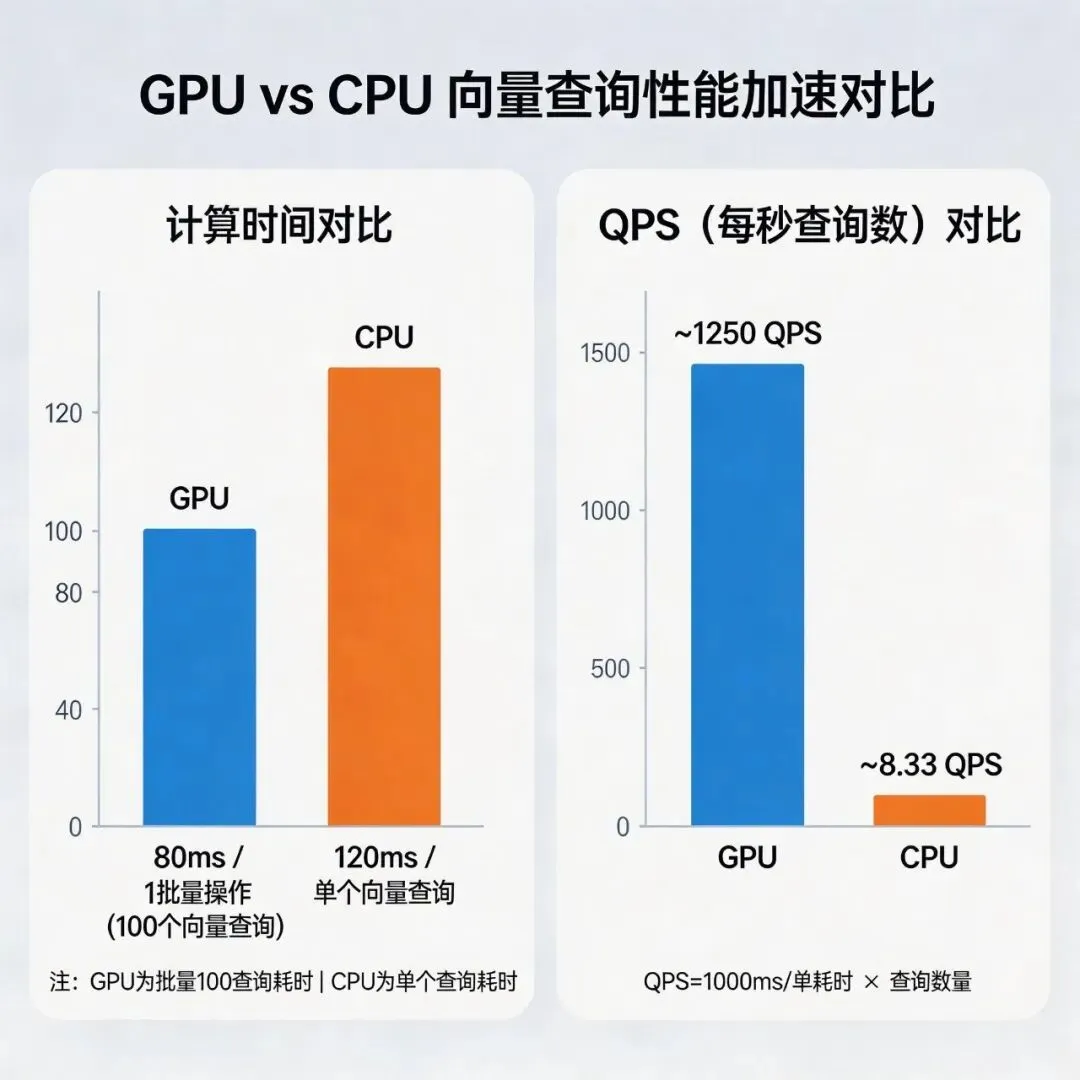
在RTX 4090 GPU上,测试结果大致如下(仅供参考):
-
GPU批量搜索(100个查询向量,10万数据库向量,维度1024):平均时间≈80 ms/批,QPS≈1250;
-
CPU单个查询向量计算时间≈120 ms;
-
GPU比CPU快≈150倍(批量越大,GPU优势越明显)。
4.4 实战注意事项
-
向量数据类型:GPU只支持float32类型,必须将numpy数组转换为np.float32,否则会报错;
-
GPU设备ID:如果有多个GPU,可通过device_id参数指定使用哪个GPU(从0开始);
-
内存限制:如果数据库向量数量过大(如千万级),需注意GPU显存大小,避免显存溢出;
-
预热操作:第一次调用GPU函数时,会有初始化开销,建议先预热10-20次,再测试性能;
五、使用场景:这套GPU向量搜索库能用到哪里?
这套源码的功能覆盖绝大多数向量相关场景,无论是科研还是工业生产,都能直接复用,以下是最常见的5个应用场景,看看你是否正在做这些方向。
5.1 推荐系统(核心场景)
推荐系统的核心逻辑是“找相似”——将用户和物品转换为向量,通过向量相似度搜索,为用户推荐最相似的物品(如商品、视频、文章)。
应用示例:
用户向量:根据用户的浏览、购买、收藏行为,生成用户兴趣向量;
物品向量:根据物品的属性、标签、内容,生成物品特征向量;
搜索逻辑:当用户发起请求时,以用户向量为查询向量,物品向量库为数据库向量,通过这套GPU向量搜索库快速筛选Top-N相似物品,作为推荐结果返回。
优势:面对百万级、千万级物品库,GPU加速可将推荐响应时间从秒级压缩到毫秒级,支持实时推荐,同时批量处理多个用户查询,大幅提升系统吞吐量,解决传统CPU推荐系统的性能瓶颈。
5.2 图像检索(高频场景)
图像检索的核心是“以图搜图”——通过CNN等模型提取图像的特征向量,将待检索图像的特征向量与图像库的特征向量进行相似度匹配,找到最相似的图像。
应用示例:
特征提取:使用ResNet、ViT等模型,将每张图像转换为512维或1024维的特征向量,存储到向量数据库中;
检索流程:用户上传一张图像,提取其特征向量后,调用GPU向量搜索库,从图像库中快速筛选出Top-K相似图像,适用于相册检索、商品图像检索、版权溯源等场景。
优势:图像库通常包含百万级甚至亿级图像,向量维度较高(512-2048维),CPU计算延迟极高,而这套GPU向量搜索库通过并行计算和内存优化,可实现毫秒级检索,同时支持批量检索多张图像,提升检索效率。
5.3 大模型相关场景(前沿场景)
在大模型部署和应用中,向量搜索是关键支撑技术,主要用于两个核心场景,可直接复用这套源码:
-
大模型知识库检索(RAG):将知识库内容拆分为片段,通过Embedding模型转换为向量,存储到向量库中;当用户发起提问时,将问题转换为向量,搜索相似的知识库片段,作为上下文输入大模型,提升回答的准确性和相关性,解决大模型“失忆”问题。
-
大模型推理加速:在大模型推理过程中,部分中间计算(如注意力机制中的相似度计算)可通过这套GPU向量搜索库的核心逻辑优化,减少推理延迟,尤其适用于批量推理场景。
5.4 自然语言处理(NLP)
NLP领域中,大量场景需要基于文本向量的相似度匹配,这套GPU向量搜索库可直接适配:
-
文本相似度匹配:将句子、段落通过BERT等模型转换为文本向量,快速计算两个文本的相似度,适用于文本去重、问答匹配、语义检索等场景;
-
批量文本检索:针对用户输入的文本,从海量文本库中快速筛选出语义相似的文本,适用于新闻推荐、论文检索、客服问答等场景。
优势:支持批量处理上千个文本查询,比CPU版本快100+倍,可支撑高并发的NLP服务部署。
5.5 其他场景
除上述核心场景外,这套GPU向量搜索库还可应用于:
-
语音检索:将语音转换为特征向量,通过向量搜索匹配相似语音,适用于语音识别、语音溯源等;
-
基因序列匹配:将基因序列转换为向量,快速匹配相似基因序列,适用于生物信息学研究;
-
异常检测:通过向量相似度分析,识别与正常数据差异较大的异常数据,适用于风控、故障检测等场景。
六、避坑指南:新手必看,少走90%的弯路
很多新手在使用GPU向量搜索、编译源码、部署项目时,会遇到各种问题,轻则编译失败,重则显存溢出、性能不达预期。结合实战经验,整理了10个高频坑点,每个坑点都给出“问题原因+解决方案”,新手直接对照避坑即可。
6.1 编译相关坑点
坑点1:CMake编译报错“找不到CUDA依赖”
【问题原因】:未安装CUDA,或CUDA路径未配置正确,CMake无法找到CUDA头文件和库文件;或CUDA版本与CMake版本不兼容(如CMake 3.18以下不支持CUDA 11.4+)。
【解决方案】:
-
确认已安装CUDA 11.4+,通过nvcc -V验证版本;
-
配置CUDA环境变量(Linux/Mac):在~/.bashrc中添加export CUDA_HOME=/usr/local/cuda、export PATH=$CUDA_HOME/bin:$PATH,执行source ~/.bashrc生效;
-
升级CMake到3.18+,确保与CUDA版本兼容;
-
若仍报错,在CMakeLists.txt中手动指定CUDA路径:set(CUDA_ROOT /usr/local/cuda)。
坑点2:编译报错“pybind11未找到”
【问题原因】:未安装pybind11,或pybind11安装路径未被CMake识别。
【解决方案】:
-
通过pip安装pybind11:pip install pybind11;
-
若CMake仍无法找到,手动指定pybind11路径:在CMakeLists.txt中添加find_package(pybind11 REQUIRED PATHS /usr/local/lib/python3.x/site-packages/pybind11)(路径可通过pip show pybind11查看)。
6.2 调用相关坑点
坑点3:Python调用报错“数据类型不匹配”
【问题原因】:传入的numpy数组是float64类型,而GPU只支持float32类型,导致数据传输失败。
【解决方案】:将numpy数组强制转换为float32类型,如queries = queries.astype(np.float32),这是新手最容易忽略的坑点。
坑点4:调用时显存溢出(Out of memory)
【问题原因】:数据库向量数量过大、向量维度过高,或批量大小设置过大,导致GPU显存不足。
【解决方案】:
-
减少批量大小(如将batch_size从1000改为100);
-
降低向量维度(如通过PCA将1024维向量降维到512维);
-
分批次处理数据库向量,避免一次性加载所有向量到GPU内存;
-
使用显存更大的GPU(如RTX 4090、A100)。
坑点5:调用后结果为NaN(非数字)
【问题原因】:向量的L2范数为0,导致余弦相似度计算时除以0;或向量数据中存在NaN值。
【解决方案】:
-
调用向量归一化方法前,过滤掉范数为0的向量(如db = db[np.linalg.norm(db, axis=1) > 1e-8]);
-
检查输入向量数据,确保没有NaN值(如np.isnan(queries).any()),若有则通过np.nan_to_num(queries)处理。
坑点6:GPU性能未达预期(比CPU快不了多少)
【问题原因】:未进行预热操作、批量大小过小、未启用共享内存优化,或GPU算力不足(算力<5.3)。
【解决方案】:
-
调用GPU函数前,先预热10-20次(避免初始化开销影响性能);
-
增大批量大小(批量越大,GPU并行优势越明显,建议batch_size≥100);
-
确认源码中启用了共享内存优化(查看CUDA Kernel中是否有__shared__关键字);
-
使用算力≥5.3的GPU(如RTX 3060及以上),算力过低会限制并行效率。
6.3 部署相关坑点
坑点7:部署时找不到Python扩展模块
【问题原因】:未将编译后的扩展模块目录添加到Python路径,或扩展模块文件名与导入名不一致。
【解决方案】:
-
将扩展模块所在目录(如../install/python)添加到Python路径:sys.path.append(“扩展模块目录路径”);
-
确认导入名与扩展模块名一致(如扩展模块名为gpu_vector.cpython-xxx.so,导入时用import gpu_vector)。
坑点8:多GPU环境下无法指定GPU设备
【问题原因】:未正确设置GPU设备ID,或CUDA环境未配置多GPU支持。
【解决方案】:
-
通过nvidia-smi查看GPU设备ID(从0开始);
-
调用时通过device_id参数指定GPU(如engine = gpu_vector.GPUVectorSearchEngine(device_id=1));
-
Linux环境下,可通过环境变量指定GPU:export CUDA_VISIBLE_DEVICES=1(仅让程序识别指定GPU)。
坑点9:长期运行后内存泄漏
【问题原因】:未释放GPU内存,或频繁创建GPUVectorSearchEngine实例,导致显存累积。
【解决方案】:
-
避免频繁创建GPUVectorSearchEngine实例,建议全局只创建一个实例,重复使用;
-
确保每次调用后释放GPU内存(源码中已实现自动释放,若自定义修改源码,需注意添加cudaFree释放内存);
-
长期运行的服务,定期重启,释放累积的显存。
七、总结与扩展:从源码到生产,一步到位
本文从核心原理、架构拆解、源码解析、项目实战、使用场景、避坑指南6大维度,完整拆解了这套工业级GPU向量搜索库,核心亮点的是“全流程GPU加速+接口简洁+可直接复用”,新手能快速上手,开发者可基于源码二次扩展,适配自己的业务场景。
7.1 核心总结
加速本质:贴合GPU并行架构,通过多线程并行计算、共享内存优化、归约算法优化,实现比CPU快100+倍的性能;
-
源码优势:分层设计清晰(CUDA内核→C++ API→Python接口),编译配置完整,无需额外修改代码,可直接复用;
-
适用场景:覆盖推荐系统、图像检索、大模型RAG、NLP等绝大多数向量相关场景,兼顾科研和工业生产;
-
新手重点:掌握数据类型转换、显存管理、编译配置三个核心点,就能避开绝大多数坑点,顺利部署。
7.2 源码扩展建议
如果需要适配更复杂的业务场景,可基于这套源码进行以下扩展,难度不高,新手也能尝试:
-
添加更多相似度计算方法:如曼哈顿距离、汉明距离,适配不同场景需求;
-
支持向量量化(如IVF、PQ):进一步提升大规模向量(亿级)的搜索效率,降低显存占用;
-
添加GPU内存池管理:复用GPU内存,减少内存分配和释放的开销,提升高并发场景下的性能;
-
封装RESTful API:通过FastAPI将向量搜索功能封装为接口,支持跨语言调用,便于服务化部署;
-
适配多GPU并行:支持多个GPU同时处理,进一步提升批量搜索的效率。
最后,向量搜索是AI时代的核心基础技术,掌握GPU加速的向量搜索,能大幅提升你的项目性能和竞争力。这套源码既是实战工具,也是学习CUDA并行计算、pybind11封装的优质案例,建议收藏反复研读,动手编译调试,真正吃透GPU向量搜索的核心逻辑。
如果觉得本文对你有帮助,欢迎收藏、转发给身边的开发者,一起学习、一起进步!
