 夜雨聆风
夜雨聆风





RAG技术全揭秘:四阶段带你从文档到答案生成
大模型很强,能知道牛顿,但是他不知道你是谁,也不知道一些非公开的信息。
带着众人的期待,RAG应运而生。它有效弥补了大模型仅凭记忆作答的短板,缓解了在面对未知问题时容易“编造”内容、产生“幻觉”的困境。
这也是目前包括智能体应用也都在使用的技术。

01
RAG是什么?
一句话定义:
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合检索和生成技术的模型。它通过引用外部知识库的信息来生成答案或内容,具有较强的可解释性和定制能力,适用于问答系统、文档生成、智能助手等多个自然语言处理任务中。
内容来自百度百科词条
RAG = 检索(Retrieval)+ 增强(Augmented)+ 生成(Generation)
通俗点说:让大模型在回答用户问题之前,先去你的知识库里“查资料”,然后根据查到的“真凭实据”来组织答案,给大模型的提示词示例:
你是一个专业的问答机器人。请仅基于以下提供的上下文片段来回答问题。如果上下文无法回答问题,请回答“无法从现有资料中找到答案”。### 上下文开始 ###{这里放置检索到的文本块}### 上下文结束 ###用户的问题是:{这里放置用户输入}请生成专业、准确、且基于上下文的回答:
02
RAG完整流程
RAG的完整流程可以分成4个阶段:文档准备阶段、索引阶段、检索阶段、生成阶段
1.文档准备阶段
这是RAG的起点,也可看成文档预处理阶段,这也是最容易被忽视却最重要的一步,文档质量直接决定检索效果。
流程拆解:
文档收集 → 格式转换 → 清洗去噪 → 元数据提取
每一步在做什么:
|
步骤 |
理解 |
|
文档收集 |
把各个地方的文档文件整理在一起 |
|
格式转换 |
把PDF、Word、Excel、图片统一转成可处理的文本 |
|
清洗去噪 |
去掉页眉页脚、广告、无关标记 |
|
元数据提取 |
给文档打标签:文档属性、作者、部门、日期、版本、权限 |
2.索引阶段
这一阶段主要是要构建可检索的知识库。
流程拆解:
清洗后的文档 → 文本分割 → 向量化 → 存入向量数据库
往往在实际中需要进行召回率测试:针对一批标准问题,看哪种分割方式能让检索器找到包含答案的正确块。
文本分割的有下面几类常用的方法,同时也要注意RAG实践中往往不是只用一种,而是多种组合:
|
方法论 |
解释 |
|
固定大小 |
按固定的字符数或Token数硬性切割,常配合重叠窗口使用(如块大小500,重叠50),防止关键信息被切断 |
|
递归分割 |
按优先级顺序尝试不同的分隔符(如:先按段落\n\n,再按句子\n,最后按空格或字符)进行分割,直到块大小符合要求 |
|
父子分割 |
检索时用小的子块匹配,提交上下文时用大的父块,以期兼顾精确度与上下文丰富度 |
|
语义分割 |
利用嵌入模型计算句子间的语义相似度,将相似度高的连续句子聚合为一个块,在语义转折处切分 |
|
文档结构分割 |
利用文档的固有结构(如Markdown的标题层级#、HTML标签、PDF的章节)作为分割边界 |
|
模型智能分割 |
直接提示大语言模型根据语义完整性来生成分割块,或让Agent动态决定如何分块以完成特定任务 |
向量化是把把文本片段转换成数学向量的过程,比如,“苹果”这个词,被向量化后,可能会变成一个像这样的数学向量:
“苹果”→ [0.8, 0.1, 0.9, 0.3, …]
常用的向量(Embedding)模型:Qwen3-Embedding、bge-m3
常用的向量数据库:Milvus、Qdrant、Weaviate、Elasticsearch、FAISS、Chroma
3.检索阶段
检索阶段的核心目标是在召回率(Recall) 和精准度(Precision) 之间取得平衡。召回率不足可能导致漏掉正确答案,而精准度不够则可能返回错误答案。
从用户提出问题到获得最相关的知识片段,通常经历以下关键步骤:
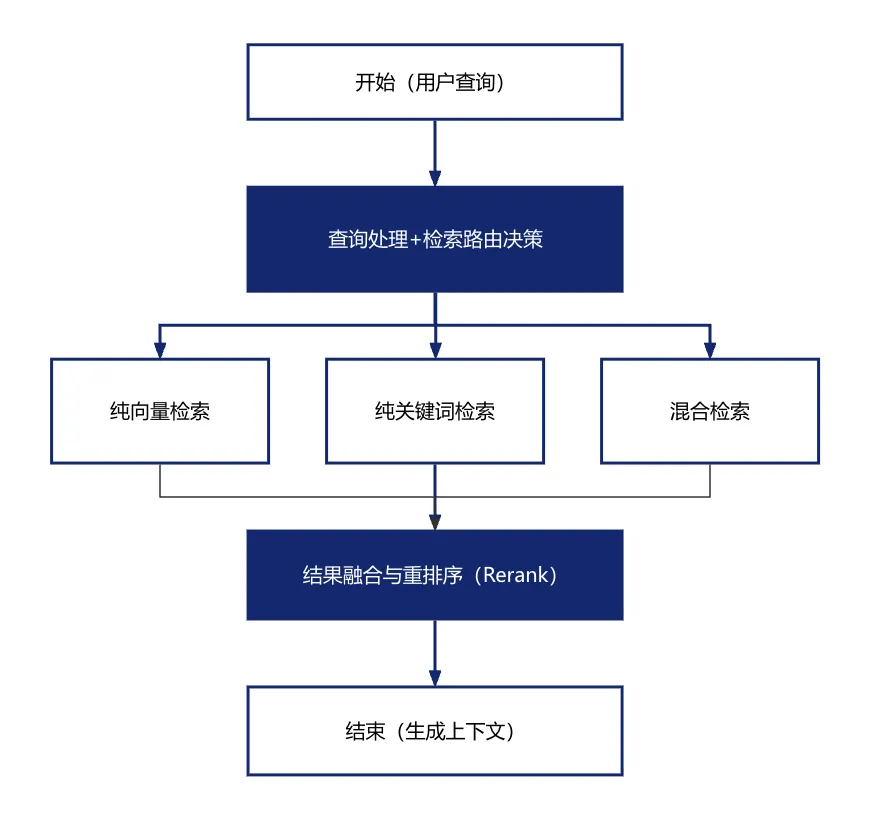
每一步在做什么:
|
步骤 |
理解 |
|
查询处理+检索路由决策 |
对用户查询进行预处理,并决定采用哪种检索策略:纯向量检索、纯关键词检索还是混合检索 |
|
纯向量检索 |
将用户问题向量化,用同一个Embedding模型转换成向量,在向量数据库中计算与所有文档片段的相似度(如余弦相似度) |
|
纯关键词检索 |
使用BM25等算法进行关键词匹配检索,适合精确词匹配场景 |
|
混合检索 |
向量检索 + 关键词检索双路并行,结果合并去重,兼顾语义理解与词法匹配 |
|
结果融合与重排序(Rerank) |
用交叉编码器对初筛结果重新排序,把最相关的往前排 |
重排序(Rerank)原理图:
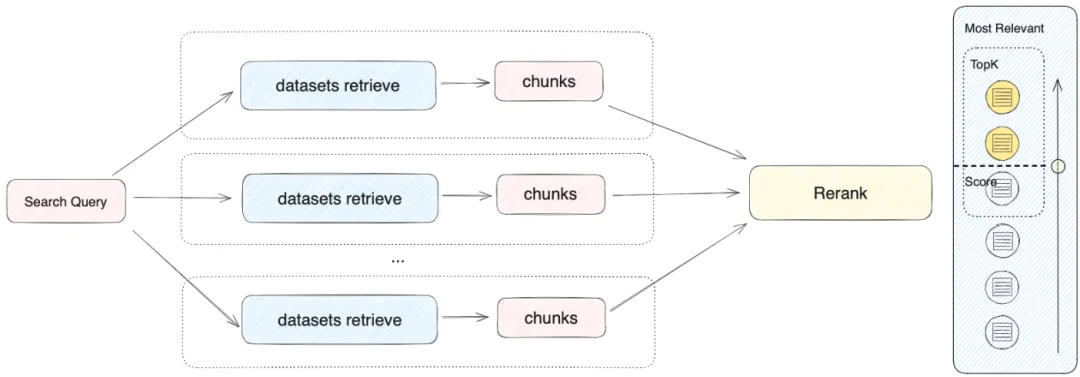
来自Dify官网,详见:https://docs.dify.ai
4.生成(Generation)阶段
流程拆解:
(用户问题 + 检索到的片段)→ 组装Prompt → 调用大模型 → 生成答案 → 后处理
每一步在做什么:
|
步骤 |
理解 |
|
组装Prompt |
把问题和检索到的资料按提示词模板组织成提示词 |
|
调用大模型 |
把Prompt发给LLM |
|
生成答案 |
模型基于资料生成回答 |
|
后处理 |
检查格式、加引用标注、过滤敏感词 |
最后,了解下目前RAG的应用场景:
|
场景 |
举例 |
|
企业服务 |
企业知识管理、员工自助服务、新员工培训 |
|
公共/政务 |
政务咨询与服务、政策解读与推送 |
|
金融 |
智能投研分析、合规风控咨询、智能客服、呼叫中心质检 |
|
医疗 |
临床决策支持、辅助疾病诊断、药物管理与研究 |
|
法律 |
合同审查、法律咨询、案例检索与法规匹配 |
|
其他 |
智能车载助手、教育学习、体育训练分析等 |
RAG不是什么黑科技,它只是一种设计思想:让大模型在回答前先查资料。
参考:
百度百科:https://baike.baidu.com/item/检索增强生成?fromModule=lemma_search-box
Dify:https://docs.dify.ai
