 夜雨聆风
夜雨聆风





AI浏览器插件被京东淘宝被误封?提示在爬虫!

电商平台通过技术手段限制异常访问,本质是在数据成为核心资产的当下,构建商业护城河、维护竞争壁垒的必然之举。这背后交织着平台安全、商业利益与用户权益的多重博弈。
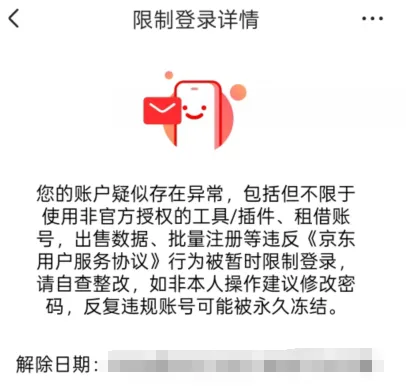
电商平台,长时间频繁只逛不买,极有可能会被认为是”非正常用户”。这时候你就会有下面疑问?我什么插件也没安装,只是浏览了商品,点击了商品,收藏加购了商品,怎么把我的账号给限制了?其根本原因是平台以为你是其他平台的来获取信息的,一直点开链接,访问商品,比价。
鉴于此,作为一名10年京东运营的小姐姐,笔者分析了如下4点,仅供参考。
一、反爬虫:防御数据资产的技术高墙
京东、淘宝、拼多多等平台部署的反爬虫系统(如行为验证、IP限制、指纹识别),直接目标是保护商品信息、价格动态、用户评价等核心数据。这些数据是算法推荐、精准营销和供应链优化的基础,一旦被大规模爬取,平台的核心竞争力可能被削弱。尤其在存量竞争时代,数据壁垒本身就是关键的竞争壁垒。反爬措施在保护平台的同时,也可能“误伤”正常比价或研究行为的用户,引发体验与安全的矛盾。

二、插件与AI浏览器:游走于便利与违规之间
比价插件、优惠券工具等浏览器插件,代表了用户对信息透明和消费自主的追求。它们帮助消费者打破信息不对称,做出更优决策。但对平台而言,这类工具往往绕过官方接口获取数据,干扰了个性化营销体系,甚至分流交易,触及商业根本。AI浏览器更强的自动化能力,使得传统反爬手段面临挑战,促使平台持续升级检测技术(如分析交互模式、API调用)。这实质是控制权之争:平台希望用户行为留存于自有生态闭环内,而工具方则试图开辟更开放的数据通道。
三、商业竞争与“大数据杀熟”的阴影
严格的反爬与插件限制,在客观上巩固了平台对用户数据的垄断。当跨平台比价和数据获取变得困难,用户画像便更集中于单一平台,为差异化定价(即“大数据杀熟”)提供了土壤。用户难以获取全面、透明的价格信息,议价能力随之减弱。从行业角度看,头部平台通过技术手段建立的数据孤岛,可能抬高市场准入门槛,抑制基于公开数据的创新与公平竞争。
四、寻找平衡点:安全、开放与权益的共存
理想的治理需要多方平衡:
-
平台应优化算法精准度,减少对正常用户的误判,并提供畅通的申诉渠道。
-
监管需明确商业数据的产权与合理使用边界,既保护企业核心资产,又防止数据垄断阻碍竞争。对于辅助消费决策的合规工具,可探索建立安全的数据接口标准。
-
用户应了解平台规则,谨慎使用来历不明的插件或共享账号,保护自身账户安全,同时保持对个人数据使用的知情与警惕。
结语
技术防御的升级不应以牺牲用户体验和市场开放为代价。电商生态的健康发展,需要在平台安全、商业创新、消费者权益及公平竞争之间找到可持续的平衡点。只有当技术用于促进更可信、更透明的连接,而非构筑不可逾越的高墙,数字商业才能走向更繁荣的未来。

