 夜雨聆风
夜雨聆风





实用组学小工具——PLASMe质粒序列识别
PLASMe是由香港城市大学孙燕妮教授团队开发的一款开源生物信息学工具,专门用于从宏基因组短读长组装(short-read assemblies)中识别质粒序列(Plasmid contigs)。
质粒鉴定主要存在两个挑战。首先,质粒展现出高度的遗传多样性。除了频繁的突变,质粒在进化过程中还经历了大规模的结构变化,如插入、删除和易位。这些快速的突变和结构变化可能导致质粒之间的序列相似性非常低。第二个挑战是质粒和染色体之间共享的基因或片段。质粒和染色体在共同进化过程中频繁发生基因转移。因此,质粒和染色体可以共享高度相似的区域,使得质粒筛选变得困难,特别是对于短contigs。
PLASMe软件充分利用了基于比对和学习的方法的优势:其中的比对组件可以很容易地识别已知质粒,而使用Transformer 模型可以识别远源的质粒。通过将质粒序列编码为基于蛋白簇的token集定义的“语言”,Transformer可以通过位置编码和注意机制学习蛋白质的重要性及其相关性。
PLASMe软件的流程如下图所示。首先,过滤长度小于1k或大于350k的contigs。然后,将它们与质粒数据库使用BLASTN进行比对。如果contigs与参考序列的比对具有高的对齐覆盖度和一致度(默认为),则将其分类为质粒;否则,它们将根据其比对结果分配到相应的目(order),并调用对应的Transformer进行预测。
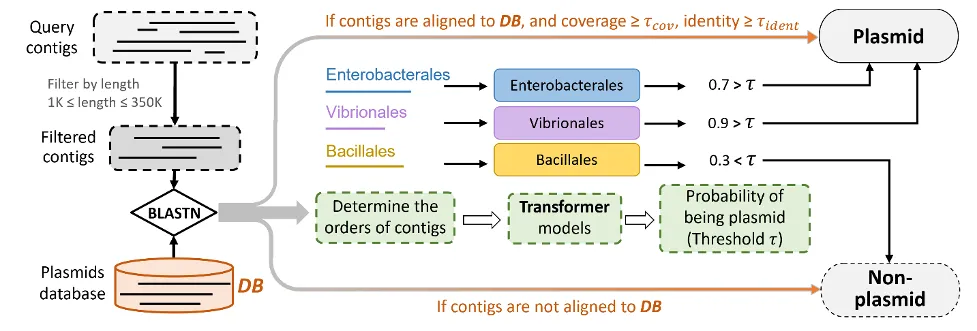
PLASMe是一款开源工具,支持在Linux系统下运行。
# 下载软件包
git clone https://github.com/HubertTang/PLASMe.gitcd PLASMe
# 创建PLASMe运行环境(需提前安装conda)
conda env create -f plasme.yamlconda activate plasme
# 下载参考数据库(12.4GB)
python PLASMe_db.py# 执行质粒序列预测
python PLASMe.py [INPUT_CONTIG] [OUTPUT_PLASMIDS] [OPTIONS]用户可以通过其GitHub仓库(https://github.com/HubertTang/PLASMe)获取源代码、使用指南和测试数据。其输入通常为FASTA格式的组装序列(contigs),输出为质粒的分类结果。
上海唯那生物已推出生信云平台服务,包含多种测序数据一键化分析流程和超百种实用小工具。可以帮助大家更方便的生物信息学分析,将操作流程简单化,无需安装软件,无需配置环境,即可快速输出需要的结果。
本节内容介绍的是免费小工具“质粒片段识别(PLASMe)”。您仅需微信扫码注册一个账号,在相应界面提交二代组装序列(fasta格式),就能从该序列中鉴定质粒片段。
-
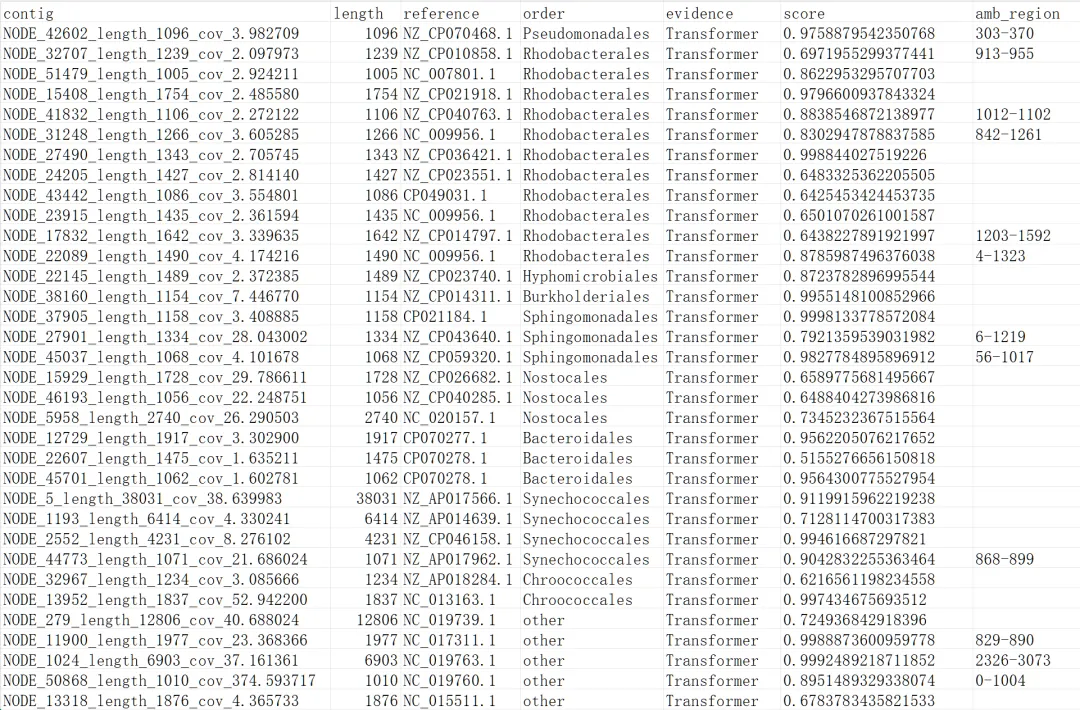
contig:每个片段的唯一标识符;
-
length:序列长度;
-
reference:参考序列编号;
-
order:宿主菌目级分类;
-
evidence:判定依据,Transformer 表明主要依赖其深度学习模型识别,说明这些序列与已知质粒的直接序列相似性可能不高,属于“远源”识别,BLAST 则代表通过高相似度序列比对直接判定;
-
score:置信度评分,PLASMe模型预测该片段为质粒的置信度,范围0-1。分数越接近1,置信度越高;
-
amb_region:模糊/不确定区域,标记了该contig内部,模型无法明确区分是质粒序列还是染色体序列的区间。以“起始-结束”坐标对表示。
模糊区域指的可能是与染色体共享的区域。如果查询源形包含大量模糊区域,则需谨慎,因为它可能源自染色体。
软件版本:PLASMe_v1.1
Tang X, Shang J, Ji Y, et al. PLASMe: a tool to identify PLASMid contigs from short-read assemblies using transformer. Nucleic Acids Res. 2023;51(15): e83. doi:10.1093/nar/gkad578
基因组组装注释、统计绘图、数据处理、格式转换、数据下载、比较分析,百款专业小工具免费用
注册即用,一键直达:
https://cloud.mimazi.net/tool/index.html
分析细菌基因组,选专业平台,认准密码子·生信云,注册即用,不限样本量,7天免费使用!
云流程使用,一键直达:
https://cloud.mimazi.net/cloud/index.html
