 夜雨聆风
夜雨聆风





异常检测插件更新:让“无数据”成为关键信号
随着企业越来越依赖实时洞察来维持可靠的运营,正确处理缺失数据已成为实现准确异常检测的关键。缺失数据往往讲述着它自己的故事——有时它只是噪音,但有时它是最关键的信号。
这让人想起二战中关于幸存者偏差的经典案例。分析师研究了从战斗中返回的飞机上的弹孔,最初想在受损最严重的地方(如机翼)增加装甲。一位统计学家指出,真正的危险出现在他们没有看到的地方——那些从未返回的飞机,因为引擎或驾驶舱被击中而坠毁。那些“缺失”的飞机揭示了真正需要装甲的地方。
同样,在现代监控中,数据的缺失可能比数据本身更重要。在本文中,我们将探讨 亚马逊 OpenSearch Service异常检测插件的最新改进,这些改进灵感来源于 Klarna 的实际监控用例,证明了有时“没有数据”本身就是重要的数据。
引言
亚马逊 OpenSearch Service 中的异常检测功能使用户能够自动识别数据流中的异常模式和行为。这一强大的能力已成为许多组织监控系统健康、早期发现问题并保持卓越运营的重要工具。
然而,我们发现了一些异常检测插件在处理时表现不佳的客户用例,特别是在那些输入数据缺失或不足的场景下。
本文重点介绍了异常检测插件插件模型的关键增强功能,解释了这些功能如何应对上述挑战,并通过实际监控用例中的真实示例说明了其影响。
挑战
全球数字银行和灵活支付提供商 Klarna 运营着一个庞大的消费者和商户集成生态系统,这对高可靠性和实时洞察提出了极高要求。为了在此生态系统中维持最高水平的质量和正常运行时间,Klarna 持续使用各种系统监控其集成和交易,旨在跟踪性能并实时发现问题。
Klarna 的监控用例涉及广泛的业务和交易指标,并在市场、区域、产品功能和集成等多个维度进行分析。这些因素的结合导致了极高基数的时间序列数据——在这种规模下,高效的聚合和异常检测既具有技术挑战性,又对成本高度敏感。
在迁移其一个实时监控系统时,Klarna 评估了多种替代方案,发现 OpenSearch 是其中具有前景的选择。其灵活的查询模型和可扩展的架构使得在处理复杂的高基数数据维度时极具吸引力,同时还能在商家和合作伙伴集成中保持细致的可见性。在测试期间,OpenSearch 被确认在检测多种类型的异常方面表现优异。
然而,他们在其中一个最关键的监控用例中遇到了局限性。设想这样一个场景:您需要实时监控多个系统中的交易流。目标是当流量出现异常时(例如,交易率意外下降或完全停止)接收警报。当 Klarna 部署各种 OpenSearch 异常检测器时,他们观察到,只要被监控的指标保持在零以上,检测器就能成功识别突然下降的情况。但是,当某个高基数实体的流量完全停止,而整体数据流继续正常运行时,该实体并未触发任何异常通知。
示例场景
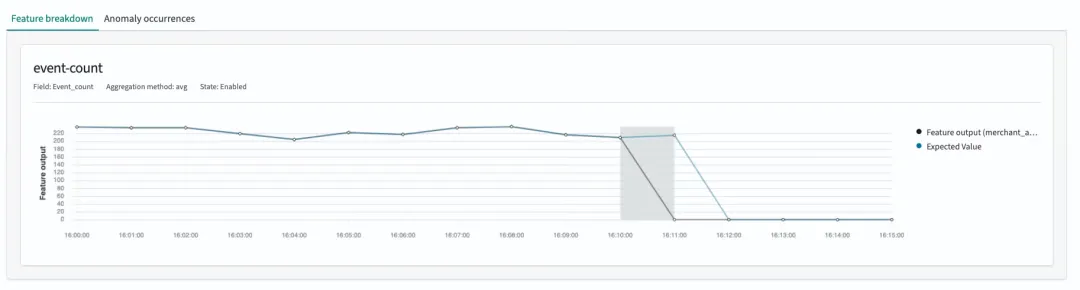
为了进一步调查,Klarna 团队搭建了一个类似生产环境的测试环境,在该环境中生成合成事件,并实时导入 OpenSearch 集群。在下例中,图表显示了其中一个受监控实体(标识为 merchant_ab12)的事件计数。在测试期间,他们暂时停用了该实体的事件生成,导致事件计数出现了持续约 30 分钟的明显下降,如下图所示。
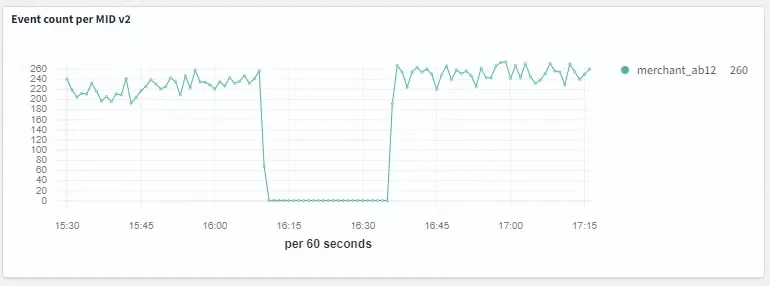
在进行此测试之前,他们部署了一个配置为 5 分钟检测间隔的 OpenSearch 异常检测器。如前所述,只要指标未达到零,检测器就能正确识别下降。在此测试场景中,完整的下降发生在两次检测器运行之间,导致系统完全错过了该异常。
即使指标在几个间隔内保持为零,检测器继续执行但未能报告任何异常。当输入流大约在 30 分钟后恢复时,检测器最终识别出了一个异常——不是因为它识别到了之前的下降,而是因为流量重新开始且指标回升至零以上。黑线表示每个 5 分钟间隔的指标聚合。请注意,在指标为零时没有记录任何数据点。检测器没有在大约 16:10 下降开始时标记异常(如数据和上图所示),而是在大约 16:35 报告了异常,如下图所示,该事件对应于恢复阶段的开始。
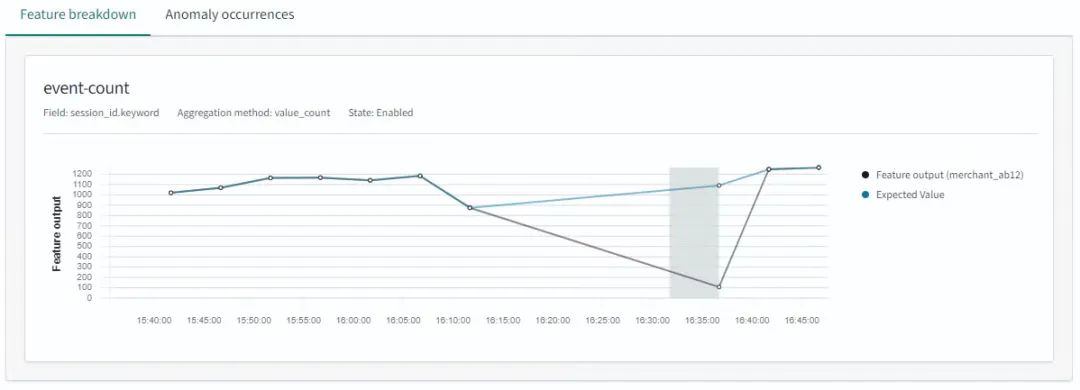
经过进一步调查,团队发现这种行为源于检测器实现中使用的底层 value_count 聚合方式。检测器并未将缺失事件表示为零指标值,而是将数据缺失视为完全暂停检测的信号。这导致了对用户来说不直观的结果,因为零计数仍然应该是一个有效且有意义的评估值。实际上,这种局限性使得在被监控指标降至零时(可以说是检测最为关键的时刻)无法精确检测到异常。
解决方案
Klarna 的经验提出了异常检测中的一个关键问题:如何处理缺失数据?首先且最简单的策略通常是放宽检测器间隔。在许多监控设置中,稍微延长间隔是减少空数据桶数量的最直接方法。然而,对于实时用例来说,过长的间隔会导致检测过于滞后。当放宽间隔不可行时,插补是首选解决方案,但必须谨慎处理——在长间隙上进行插补可能会引入过时且不具代表性的信息。
研究表明,与留空缺口相比,使用插补技术增强的异常检测方法在处理不完整数据时表现显著更好。使用 ROC 曲线下面积(AUC)作为评估指标(衡量异常检测器正确地将随机选择的异常点排在随机选择的正常点之上的概率),结果表明,随着缺失值比例 ρ的增加,所有方法的 AUC 均会下降,但插补方法下降得较为平缓,而简化方法(即仅丢弃缺失维度)则会出现灾难性失败。
具体来说,随着 ρ 从 0 增加到 0.8,插补方法保持了强劲的性能,AUC 仅从 1.0 下降到约 0.8。相比之下,简化方法的 AUC 在缺失率较高(ρ=0.7,0.8 )下从 1.0 暴跌至 0.5——相当于随机猜测。
“先插补,后检测”流程
基于此背景,OpenSearch 2.17 引入了可配置的插补功能。这项新功能由 “先插补,后检测” 流程驱动。在每个检测间隔,系统首先使用策略控制的插补器完成当前的特征向量,然后才对已完成的向量进行评分。该流程的有效性取决于所选的插补策略。这一解决方案提供了三种策略:
-
PREVIOUS (最后已知值):
适用场景:当缺失数据不应触发异常时使用。
原理:通过延续最后一次观测值来填补缺口,维持异常检测模型所需的连续序列。这对于连续事件流(如因网络问题、日志故障或不规则采样而导致事件丢失或空白间隔的应用日志、点击流或按时间聚合的交易日志)尤其有价值。通过维持连续性,检测器可以专注于识别真正的异常(如意外的峰值或低谷),而不被短暂的缺口所干扰。此外,这种方法对于多特征检测器尤为有用,因为单个缺失特征可能会导致整个元组被丢弃。
-
ZERO 或 FIXED_VALUES:
适用场景:当缺失数据应被视为潜在异常时使用。
原理:通过填入一个在历史分布中极为罕见的“不可能”值(例如零或一个大的负值,如 -999),使插补点在检测器中脱颖而出。这在因中断导致的数据缺失的场景中至关重要,因为数据的缺失本身就是想要检测的信号。这种方法与 PREVIOUS 形成对比,后者旨在让缺失数据无缝融合。
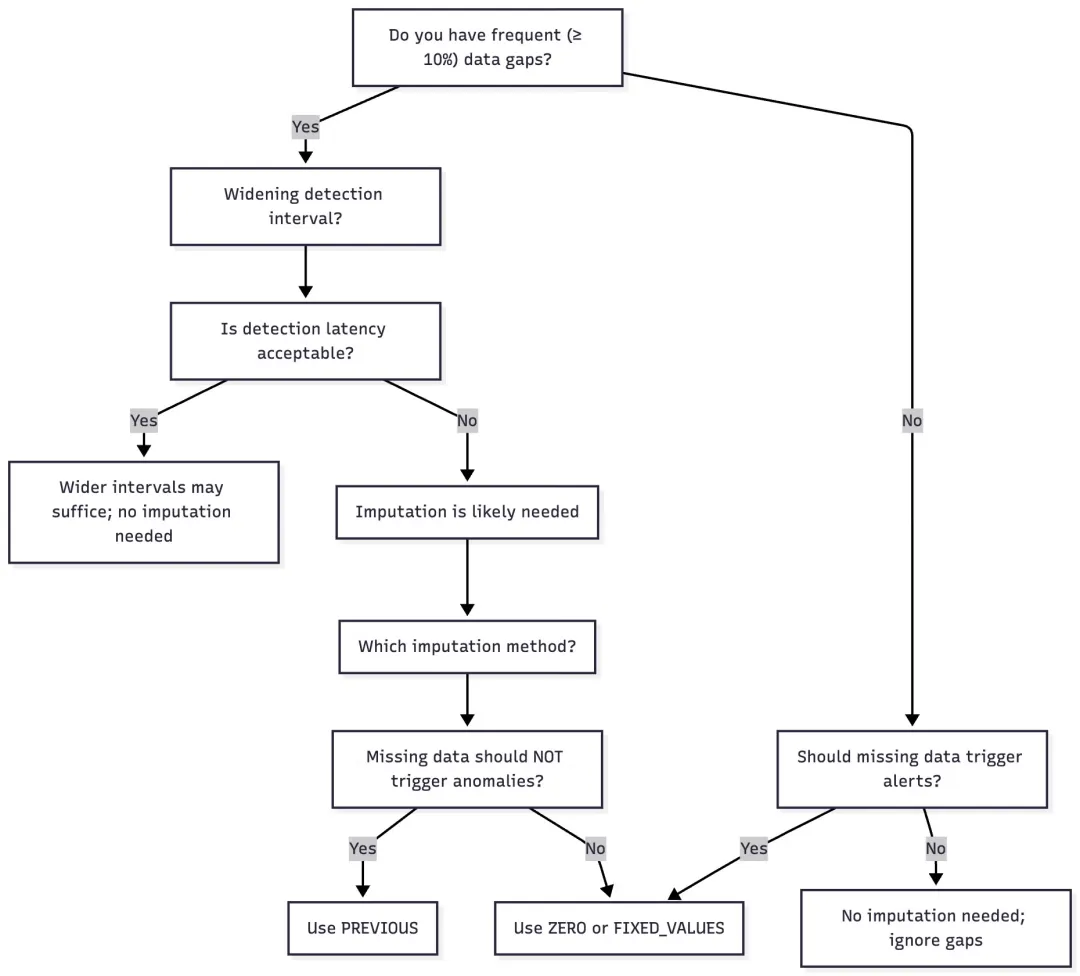
为了帮助您做出这些选择,以下的决策树总结了何时使用插补以及选择哪种方法。
示例场景
对于需要及时警报的 Klarna 来说,解决方案是使用此功能将缺失的 value_count 指标视为零,如下图所示。
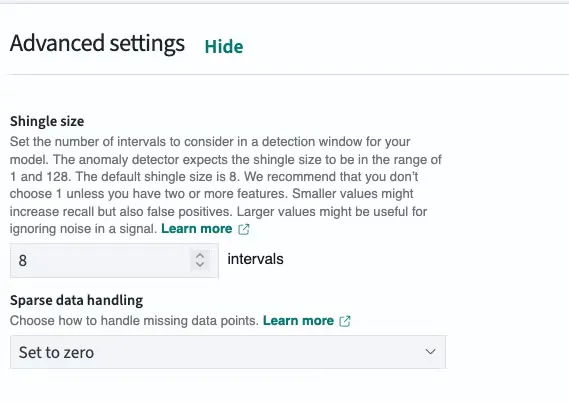
这一改变产生了显著效果。系统不再忽略数据缺口,而是插补零值,从而在指标下降时正确识别异常,如下图所示。
算法概要
-
输入: 当前元组xt 及其缺失索引集 Mt ,最后一个已知的完整元组 xt−n (对于某些 n≥1 ),方法m∈{ZERO,FIXED_VALUES,PREVIOUS}
-
步骤
1. 选择填充向量 f :
– if m =ZERO ,set f:=0
– if m =FIXED\ _VALUES ,set f := user constants;
– else set f := xt−n,where n is the smallest integer ≥1 such that xt−n is available (i.e., the most recent real value prior to t; default n=1).
2. For each j∈Mt set xt [j]:=f[j]; 其他位置保留原始值。
3. If there is a timestamp gap of g>1: – For k=1,…,g−1, construct intermediate tuples x(k)t: – x(k)t:=f for ZERO/FIXEDVALUES – x(k)t:=xt−n for PREVIOUS – Inject each x(k)t into the shingle before updating deviations.
4. 对完成的元组进行归一化或差分处理,使特征处于可比尺度并强调变化(例如,每个特征的 z-score 或简单的 xt–xt −1); 如果插补比例可接受,则更新forest.
5. 更新数据质量指标,以避免因长期插补而降低置信度。我们在[附录]中对该过程进行了正式描述(#appendix-data-quality-formalization)。
输出: 经过 分片、缩放处理且带有确定性插补坐标的点,进行评分。
系统架构
尽管关于时间序列异常检测的文献很多,但大部分针对的是单变量、规则采样、离线设置。对于多变量、流式、不规则时间戳、异构序列以及缺失数据的支持,尤其是这些情况的组合,在主流工具和许多学术基线中较为薄弱。该系统专为具有不规则时间戳和缺失值的流式、多变量序列这一具有挑战性的现实世界场景而设计。
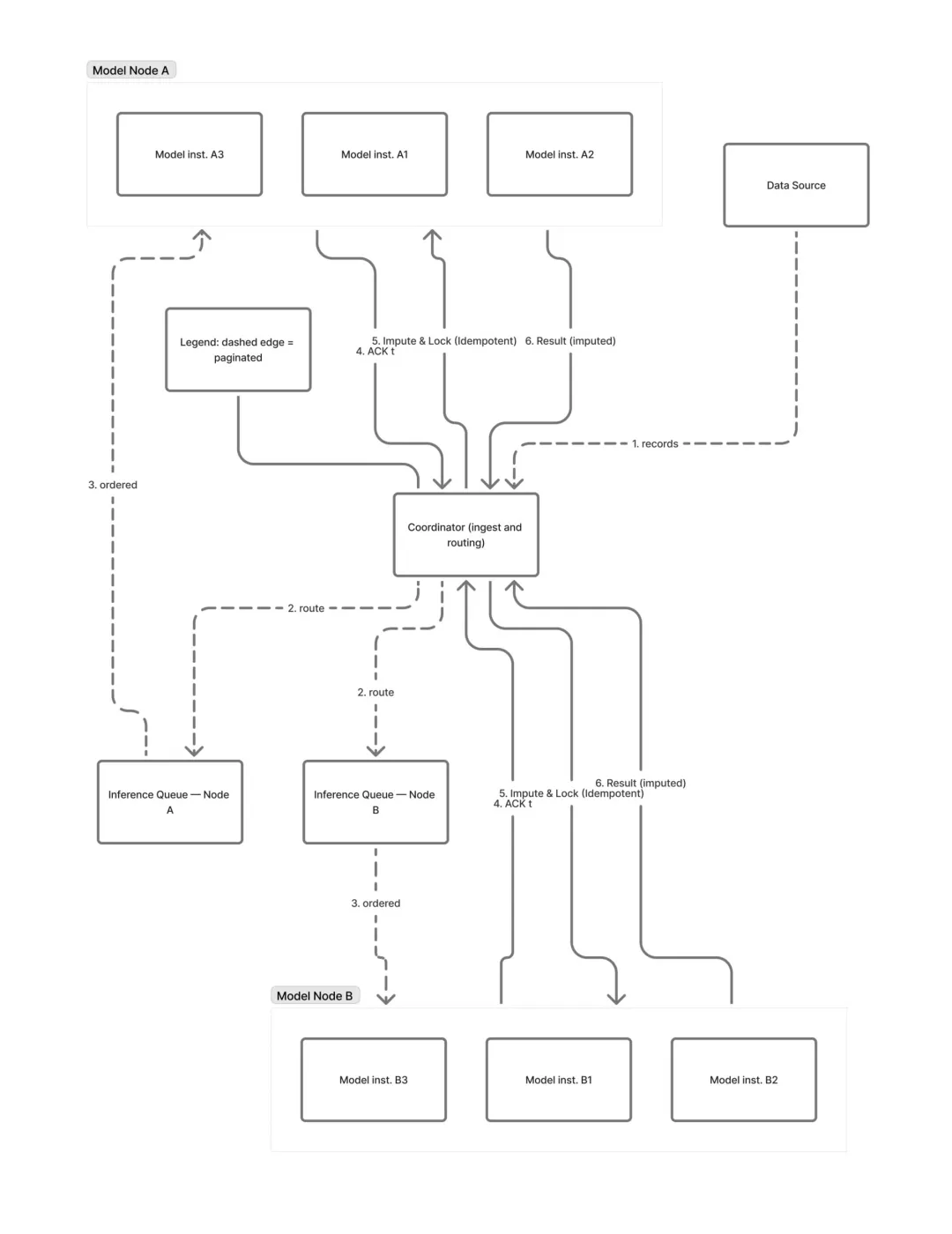
在此背景下,我们现在转向探讨使这些保证得以大规模实现的架构。该系统是一个分布式管道,可在几分钟内处理每个传入的数据点。从宏观层面来看,它由三个主要组件构成:
-
协调节点:该节点负责协调数据流。它从数据源中检索带时间戳的记录,将它们聚合成指标流,并将每个流分配给特定的模型节点。通过使用模型 ID 作为分区键,它确保每个时间序列都有一个确定且稳定的所有者。
-
模型节点:每个模型节点托管数万个独立的模型实例。每个实例专用于单个时间序列并维护其自身状态,从而实现高度并行执行。这种设计使系统既能横向扩展(通过添加更多节点),也能纵向扩展(通过为每个节点添加更多 CPU 和内存)。
-
推理队列:为了保护系统免受数据突发和处理延迟的影响,每个模型节点都有自己的推理队列。协调节点将数据推送到这些队列中,模型实例从中拉取。这将数据摄入与评分解耦,提供背压,并且至关重要的是,保留了每个时间序列数据的数据时间顺序。
使用 Exactly-Once 语义处理缺失数据
流式插补的核心挑战在于知道数据点是真正缺失还是仅仅延迟了。系统通过两阶段的 “先确认后插补”的屏障来解决这一问题:
1. 实时评分:对于任何给定的时间间隔 t ,协调节点分页遍历源数据以获取真实记录,并将它们发送到相应的模型节点进行评分。
2. 同步与插补:协调节点等待来自所有模型节点的确认(ACK),确认它们已处理了间隔t 的真实数据。此 ACK 屏障确保不会过早进行插补。一旦同步,协调节点会发送一条控制消息以触发任何静默序列的插补阶段。
收到此消息后,负责静默序列的每个模型实例会对照延迟阈值(例如,一个检测器间隔)进行检查。如果在此窗口内没有真实数据到达,该实例将锁定时间段并生成插补值。此锁定是 实现恰好一次保证的关键:如果真实数据点延迟到达,系统会看到该锁定并丢弃延迟记录,防止重复并保持时间线的完整性。
下图中的序列图展示了这一流程。
结论
Klarna 的经验强调了一个简单但容易被忽视的真理:在现实世界的监控中,“无数据”有时就是异常。通过将静默间隔视为一级信号而不是要忽略的缺口,我们消除了关键中断可能未被察觉的盲点。
OpenSearch 2.17 的可配置插补功能:提供 PREVIOUS、ZERO 和 FIXED_VALUES 三种策略。赋予用户对缺失值的精细控制。当缺失不应触发警报时,选择 PREVIOUS;当缺失本身就是信号时选择 ZERO 和 FIXED_VALUES。结合数据质量门控和恰好一次语义,这些功能实现了大规模可靠的异常检测。
展望未来,更复杂的插补方法——例如在严重缺失情况下实现更高 AUC 的比例分布和基于 MAP 的技术(https://dl.acm.org/doi/pdf/10.1145/3314344.3332490 ),有望在未来版本中进一步提高检测准确性。就目前而言,原则很明确:定义系统在数据缺失时应如何表现,并在检测器配置中明确体现这一点。当你这样做时,“无数据”将成为你可观测性故事中强大的组成部分,而不是危险的盲点。
附录:数据质量形式化
我们通过一个有界的、单调的数据质量信号来量化缺失数据如何影响学习和决策,并将其暴露出来,以便用户判断应对检测器输出的信心程度。特别是在插补活跃且模型质量可能下降时,并决定数据质量何时高到足以真正满足警报阈值。
设 shingle(窗口)长度为 LL 。Shingle 是最后 LL 个观测值的滑动窗口;在时间 tt ,我们通过连接最后 LL 个元组形成向量 st=[xt−L+1,…,xt]st=[xt−L+1,…,xt] (如果每个 xt∈Rpxt∈Rp ,则 st∈RpLst∈RpL )。每一步都会删除最旧的元组并添加最新的元组,使检测器能够在没有显示状态模型的情况下捕捉短期时间模式。
定义 wt=∑j∈Mtαj∈[0,1]wt=∑j∈Mtαj∈[0,1] ,
因此完全缺失的数据产生权重 wt=1 ,完全观测到的数据产生权重wt=0 。我们维护一个长度为 L 的近期质量环形缓冲区,并将 shingle 中的总插补质量定义为:
St=∑i=0L−1wt−i∈[0,L]St=i=0∑L−1wt−i∈[0,L]
由此,我们定义插补分数及其互补的质量信号为:
ft=StL∈[0,1],qt=1−ft∈[0,1]ft=LSt∈[0,1],qt=1−ft∈[0,1]
在操作上,每个时间步长更新总质量是一个 O(1) 操作:St=St−1+wt−wt−L,这过减去滑出 shingle 的最旧质量wt−L 来实现老化效应。
为简化起见,我们可以通过将任何部分缺失的元组视为完全观测来分析动态。这样缺失值问题就简化为一个二进制值问题:如果元组完全缺失,则 wt=1 ,否则wt=0 。
在这种情况下,总质量 St 仅仅是 shingle 中插补元组的数量,我们记为 nimpt 。该计数的演变遵循封顶更新规则:

当时间戳前进且插补元组滑出 shingle 时,会应用额外的老化递减。上限nimpt≤L 确保ft=nimpt/L≤1 始终成立。
质量更新与控制
系统通过应用指数平滑(exponential smoothing)到瞬时质量信号 qt 来维护标量数据质量统计量 DQt 。这种方法避免了急剧波动,并通过计算当前质量值与其历史平滑值的加权平均来产生更稳定的信号。更新规则为:
DQt=λ⋅qt+(1−λ)⋅DQt−1
其中 λ∈(0,1) 是平滑因子。这里,新的数据质量分数 DQt 是来自 qt 的新信息与存储在 DQt−1 中的历史背景的混合。较小的 λ (例如 0.1)优先考虑历史数据,从而产生一个稳定且缓慢变化的信号。较大的 λ 使分数对最近的变化更敏感。
系统仅在插补负担较小时允许模型更新:
update allowed at time t⟺ft<τ
对于用户可选的阈值 τ (通常 τ≈0.5 )。这种控制机制对于防止模型退化至关重要。通过限制在高插补期间的更新,我们避免了强化对伪造输入的依赖。这确保了模型主要从真实数据模式中学习来保持模型的完整性。
命题(单调下降与恢复)
两种模型的数据质量可以简洁地总结如下:
完全缺失(二进制):跟踪 shingle 中完全插补元组的计数nimpt∈{0,…,L} 。则 ft=nimpt/L 且 qt=1−ft ,具有封顶更新
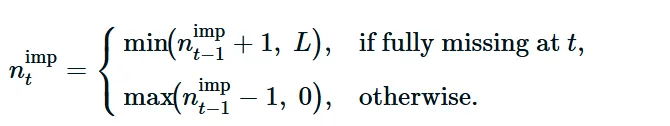
老化由滑动窗口(shingle)处理。
部分缺失(分数缺失):设每个元组的质量wt∈[0,1] 为缺失属性的权重。保持窗口总和和及分数不变
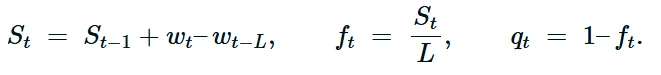
二进制模型是wt∈{0,1} 的特例。
边界
对于所有t我们有 0≤ft≤1 和 0≤qt≤1。
证明:在二进制模型中,根据构造 0≤nimpt≤L ,因此 0≤ft≤1 且 qt=1−ft∈[0,1] 。在分数模型中,窗口和 St 是最后 L 个质量项的总和,每一项都在 [0,1] 之间。因此,$0 \le S_t \le L ,这意味着,这意味着 f_t \in [0,1] 且 q_t \in [0,1] $ 。
单调下降
二进制模型:假设存在 t0 和 K≥1 ,使得输入在每一个t0,…,t0+K−1都完全缺失。则nimpt0+m=min(nimpt0−1+m+1,L)对于 m=0,…,K−1 ,因此 nimpt 是非递减的——在低于 L 时严格递增,达到 L 后保持恒定(如果完全缺失的运行持续存在,它最多在 L 步内达到 L )。因此 ft=nimpt/L 是非递减的——在低于 1 时严格递增(直到窗口完全插补),然后恒定——且 qt=1−ft 是非递增的,下界为 0。
分数模型:分数模型的动态由插补分数的单步变化控制:
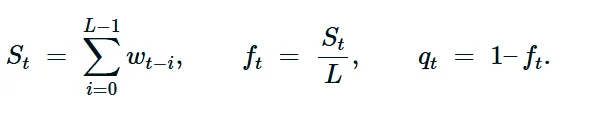
窗口通过以下方式在 O(1) 时间内更新:

由此关系,我们可以推断出:
-
边界:
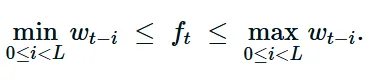
-
单步单调性:在任何一步中,
ft increases ⟺wt>wt−L,
ft decreases ⟺wt<wt−L,
ft unchanged ⟺wt=wt−L.
因此, f_t 的变化方向完全由进入的质量 w_t 与离开的质量 w_{t-L} 来确定。
-
区间上的单调性:若对于索引集 T 中的每一步都有 w_t \ge w_{t-L} ,则 \{f_t\}_{t \in T} 是非递减的;若对于所有 t \in T 都有 w_t \le w_{t-L} ,则是非递增的。特别是,若序列 (w_t) 在 t 上是(全局)非递减的,则对于所有 t≥L ,都有 w_t≥w_{t-L} ,因此对于所有 t≥L , f_t 是非递减的(对于非递增运行也有对称陈述)。
单调恢复
-
二进制模型:假设从某个时间点 t1 开始,每个新元组都”不完全缺失“。则对于所有 t≥t1, 更新公式为 nimpt=max(nimpt−1−1,0) ,因此 nimpt 是非递增的,并最多在 L 步内达到 0;因此 ft↓0 而 qt↑1 。
-
分数模型:如前所述,确切的单步变化是 ft−ft−1=Lwt−wt−L 。因此,恢复( ft 向下移动)的充分必要条件是在区间 {t1,…,t2} 上对于每个 t 都有 wt≤wt−L 。在此条件下, {ft} 在该区间上是非递增的。直观地说,每一步都用相等或更小的进入质量 wt 替换离开的质量 wt−L ,因此滑动平均值不能增加。
对平滑数据质量的影响
已建立的插补分数 ft 的单调性直接影响平滑数据质量统计量 DQt 。
通常,任何具有非负系数的线性滤波器都保留其输入序列的单调性(例如,EUSIPCO 2000)。指数移动平均就是这样一种滤波器——它具有脉冲响应权重 {λ(1−λ)k:k=0,1,2,…} ,当 0<λ<1 时均为正。由于 DQt 是瞬时质量 qt=1−ft 的指数平均,它继承了这些单调趋势。
此外,因为 qt 始终在 [0,1] 范围内,平滑统计量 DQt 也保证保持在 [0,1] 内。这直接遵循标准指数平滑递归,其中新值是先前平滑值 DQt−1 和当前观测值 qt 的凸组合(即,具有非负权重且和为 1 的加权平均,因此它位于其输值入之间)——具体为 (1−λ)DQt−1+λqt ,其中 0<λ<1 ,确保它永远不会超出输入信号定义的边界(参见维基百科关于“Convex combination”的文章)。在持续缺失数据期间,随着 ft 上升, qt 下降, DQt 也随之平滑下降。相反,当真实数据返回且 ft 下降时, qt 上升, DQt 可靠地恢复到1。这确保了依赖这些信号的控制机制是稳定的,并对数据质量的持久变化而非短期噪声做出响应。
作者
Kaituo Li
亚马逊OpenSearch工程师。他在亚马逊从事分布式系统、应用机器学习、监控和数据库存储方面的工作。
Patrik Blomberg
Klarna首席工程师,负责设计和开发用于时序异常检测和警报的近实时平台。
#AI#OpenSearch#OpenSearchConChina#开发者社区#开源大会
