 夜雨聆风
夜雨聆风





这个插件装上后,彻底治好了我的 ��AI Agent 的健忘症
导读
在使用 🦞OpenClaw 时,相信大家都遇到过这些问题:
-
• ❌ 问了几个小时前的决策,Agent 说”我不记得了” -
• ❌ memory 文件夹里只有今天的文件,昨天的不见了 -
• ❌ 对话一长,Agent 越来越”傻”,细节全丢 -
• ❌ 每天都要重复”我不是说过用这个格式吗?”
这不是你的问题,是 OpenClaw 的记忆存储机制决定的。
今天要介绍的 Lossless-Claw 插件,彻底解决了这个痛点。装上之后,你就会感觉
“你在和一个永远不会失忆的 AI Agent 聊天”
一、OpenClaw 的”健忘症”痛点
OpenClaw 是目前最丝滑的本地 AI Agent 框架,但长会话用久了,所有人都会吐槽同一个问题。
1.1 三大痛点
|
|
|
|
|---|---|---|
| Compaction 后遗忘 |
|
|
| Daily 文件懒加载 |
|
|
| 预压缩 flush 不稳定 |
|
|
1.2 为什么会这样?
OpenClaw 官方记忆机制的核心设计是这样的:
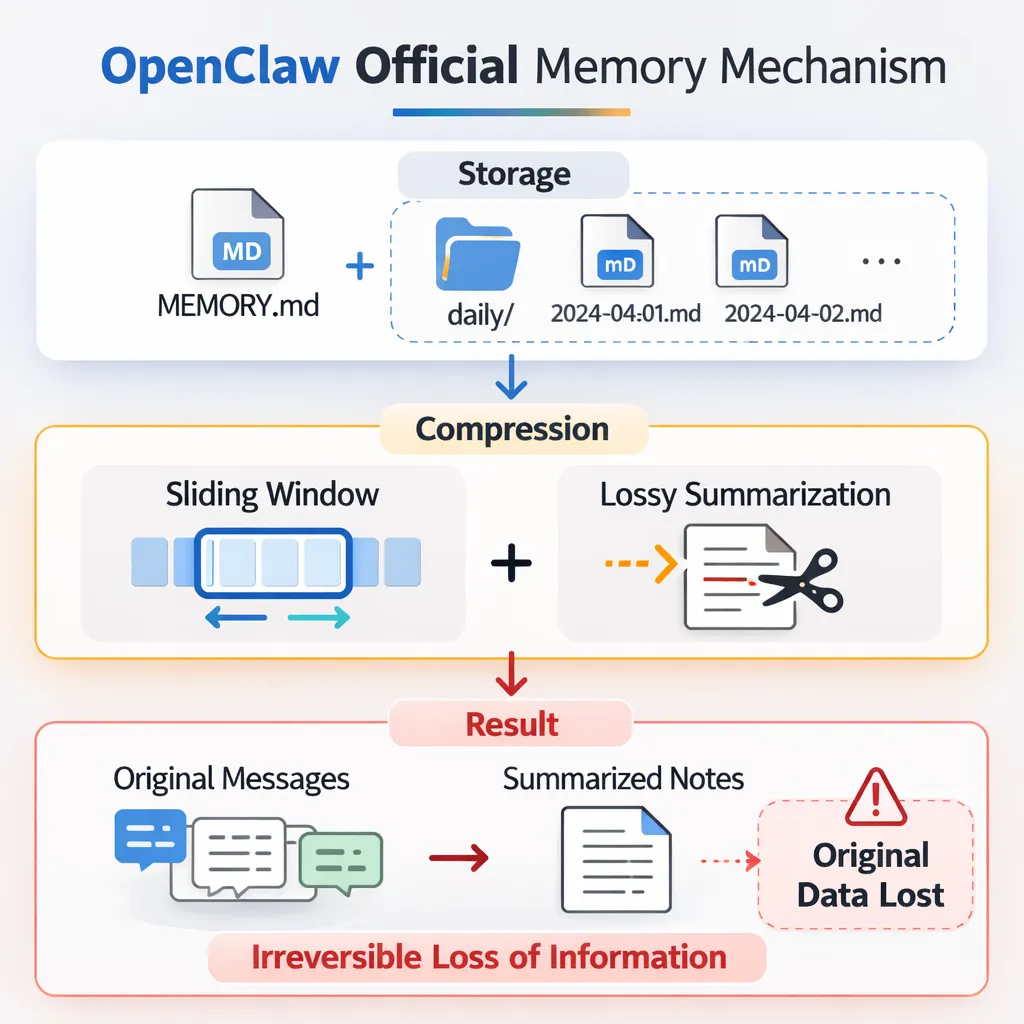
从图中可以看到,OpenClaw 的记忆机制分为三个阶段:
OpenClaw 使用 Markdown 文件作为记忆存储格式,主要包含两类文件:
MEMORY.md:长期记忆文件,用于保存总结后的核心信息
YYYY-MM-DD.md:每日记忆文件,记录当天的原始对话内容
所有新的对话信息会先写入 daily 文件,作为原始记录保存。
随着对话越来越多,模型的上下文窗口有限,无法加载全部历史信息,因此系统会进行压缩:
滑动窗口(Sliding Window):只保留最近的一部分对话在上下文中 有损总结(Lossy Summarization):将较早的对话内容进行总结压缩,写入 MEMORY.md
在这个过程中,大量细节会被删除,只保留关键内容。
当总结完成后:
原始对话记录会被丢弃或覆盖
只保留压缩后的总结内容
被删除的细节无法恢复
因此最终结果是:
原始信息 → 总结压缩 → 原始内容丢失(不可逆)
此外,官方 memory 触发机制是:
-
• Daily log 文件只在”有内容要写“时才创建 -
• 只有 session 接近 token 阈值(~40k)时,才触发 pre-compaction flush -
• 如果你每天用 /new重启,或 session 都很短,几乎不会触发
结果就是:
memory 文件夹里只有一个当天的文件,历史的没有。不是 bug,是设计如此——daily 文件”懒创建”。
因此:
OpenClaw原生是”有损压缩 + 文件记忆”双保险,但压缩是硬伤,记忆是靠手动。
二、Lossless-Claw 解决“健忘症”问题
2.1 核心理念
一切永不删除 + DAG 分层总结 + 自动后台处理它不是增强 memory,而是直接替换 OpenClaw 的 contextEngine(上下文引擎)。
官方滑动窗口被彻底干掉,取而代之的是基于 LCM 论文的 Lossless Context Management。
2.2 它做了什么?
当对话超出模型上下文窗口时,OpenClaw(和其他所有 Agent 一样)通常会截断旧消息。
但是,LCM 的做法完全不同:
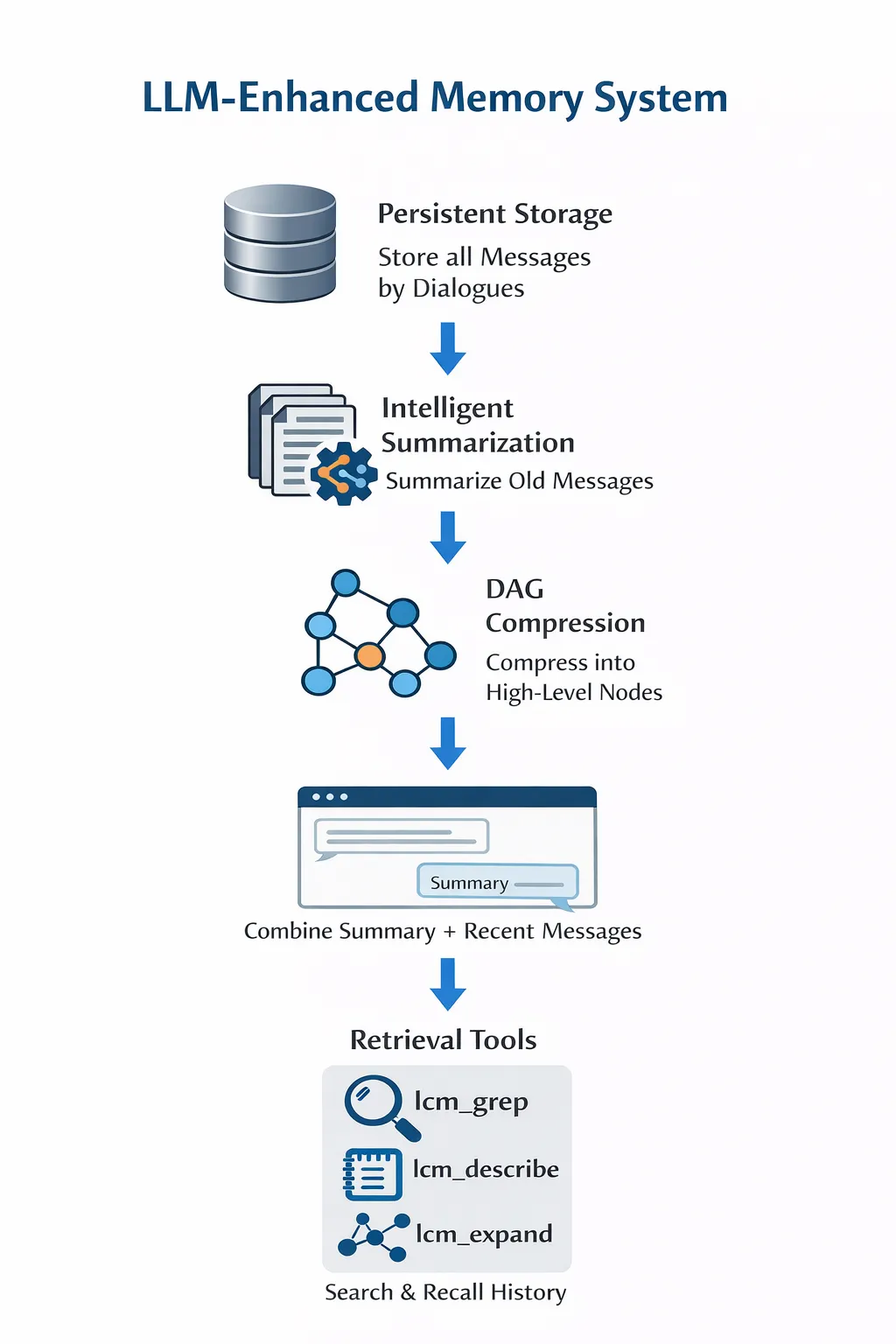
-
1. 持久化存储 – 系统首先将所有消息存入 SQLite 数据库,并按照对话组织。 -
2. 智能摘要 – 随后进入智能摘要阶段,利用配置 LLM 将旧消息分块总结,从而降低上下文长度。 -
3. DAG 压缩 – 在此基础上,系统进一步进行DAG压缩,将已有摘要抽象为更高层级的节点,并构建有向无环图结构,实现多层次信息压缩。 -
4. 动态组装 – 在实际对话中,系统会进行动态组装,将高层摘要与最近的原始消息结合,构建当前轮次所需的上下文。
-
5. 检索工具 – 最后,系统提供 lcm_grep、lcm_describe、lcm_expand等检索工具,让 Agent 可以搜索和召回压缩历史,从而实现对压缩记忆的高效召回。
Nothing is lost.
2.3 自动触发流程
为了在有限的上下文窗口内持续保留长期记忆,同时避免传统“截断或覆盖历史”的问题,系统设计了一套基于压缩与检索的记忆机制。其整体流程可以分为以下几个过程:
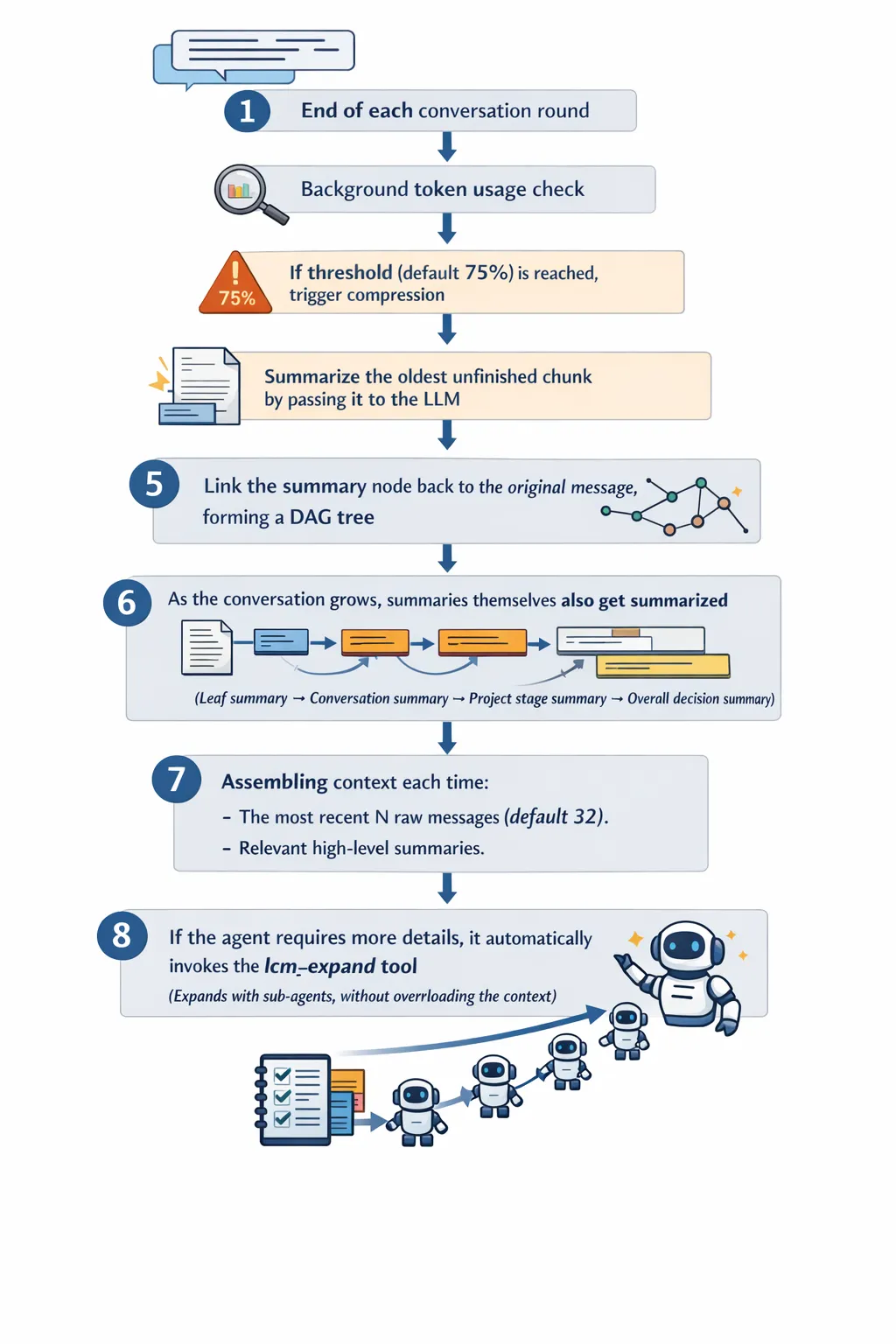
1. 持久化存储
在每次用户与 AI 进行对话结束时,系统会自动识别对话的结束点,并准备进行接下来的处理。此时,AI 会回顾并保存当前对话内容。
2. 后台异步检查 token 使用率
AI 会在后台监控 token(数据单元)的使用情况,确保在任何时候系统资源都能够合理管理。每当用户输入或者 AI 输出时,都会消耗一定数量的 tokens。此时,系统会检测是否已接近设定的使用阈值(例如:75%)。
3. 达到阈值(默认 75%)→ 触发压缩
如果后台检测到 token 使用量已经接近设定的阈值(默认75%),系统会自动触发数据压缩机制,准备对旧的对话内容进行总结,从而释放更多的 token 以继续进行后续对话。
4. 把最老的未总结 chunk 交给 LLM 生成总结
系统会识别出对话中的最老且未被总结的“chunk”(对话块)。这些 chunk 可能是一些用户的提问、AI 的回答,或者是长时间未被总结的对话内容。接着,系统会将这些 chunk 交给大语言模型(LLM)进行处理并生成简洁的总结。
5. 总结节点链接回原始消息,形成 DAG 树
生成的总结会被“节点化”并与原始对话内容关联。通过这种方式,整个对话形成了一个有向无环图(DAG)结构。这种结构允许每个总结节点都能追溯到其原始消息,从而确保了数据的完整性和准确性。
6. 随着对话增长,总结自己也被总结
随着对话的不断推进,AI 会不断对旧的总结进行更新和归纳。比如,原本的叶子总结会被转换成更高层次的总结,最终形成多层次的总结体系:
-
叶子总结 → 逐步形成会话总结
-
会话总结 → 形成项目阶段总结
-
项目阶段总结 → 转化为整体决策总结
-
通过这种方式,每个总结层次都能高度概括对话的精髓。
7. 每次组装上下文
每当系统需要处理新的用户请求时,它会根据当前的需求组装适当的上下文,确保 AI 的响应与对话历史相关。这个过程包括:
-
最近 N 条原始消息:会话上下文会包括最近 N 条原始消息(默认是 32 条),以确保 AI 回应的内容有足够的背景支持。
-
相关高层总结:除了原始消息,还会包括相关的高层次总结,如会话总结、项目阶段总结等,确保系统对话的流畅性和完整性。
8. Agent 需要细节时,自动调用 lcm_expand 工具
当 AI 需要获取更多细节时,它会自动调用 lcm_expand 工具。这是一个扩展工具,通过启动子 Agent 来对某些领域或信息进行深入探索,而不会导致上下文过载。子 Agent 会根据当前需求展开相应的对话和处理。
lossless-claw = 给 AI Agent 一个真正的长期记忆系统。不再失忆,不再重复,不再丢失上下文。
2.4 DAG 结构示意
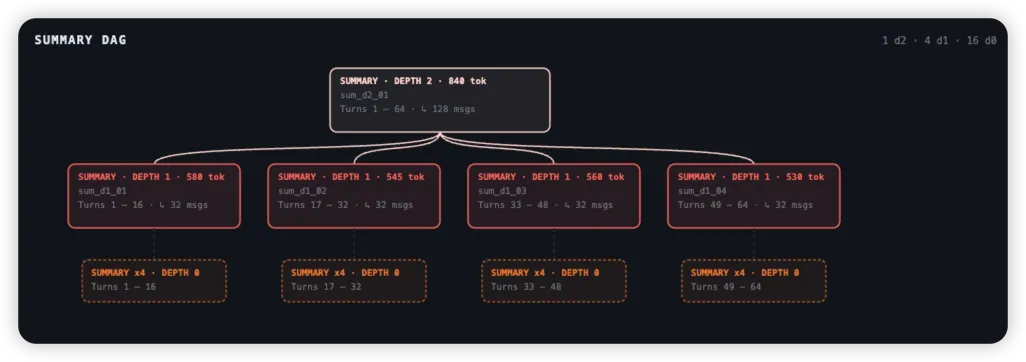
DAG 是一个“可以不断压缩、但随时能还原”的记忆树。上图结构中,分为三层:
Depth 0(基础层):
SUMMARY x4 · DEPTH 0Turns 1–16 / 17–32 / 33–48 / 49–64
-
原始对话被切成 chunk(比如每 16 轮)
-
每个 chunk 被总结一次
关联具体的决定、准确的技术细节。原始消息 → 第一层总结(局部总结),
Depth 1(流程层):
SUMMARY · DEPTH 1 · ~500 tok每一个红色框:
对应一个更大的区间(比如 32 条消息)
是对多个 Depth 0 summary 的再次总结
因此,关联对话的发展脉络、当前状态的简要总结,它是“总结的总结”。
Depth 2(叙事层):
SUMMARY · DEPTH 2 · 840 tokTurns 1–64
它是:
-
把所有 Depth 1 再总结一次
-
得到整个会话的“全局理解”
它是长期的里程碑、核心决策和全局故事线。当同级摘要积累到一定数量时,系统会触发“凝缩(Condensation)”,生成更高级别的抽象节点。相当于,全局压缩后的“脑子里的结论”
因此,这样的 DAG 结构具备以下特性:
✅ 所有原始消息永远在 DB 里,总结只是”索引”
✅ 想看原始,直接展开就行
✅ 在正常操作中,你永远不需要再考虑 compaction
2.5 装上之后的变化
装上这个插件之后,你会发现:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
2.6 社区评价
“连OpenClaw 作者都亲自推荐:如果你被 compaction 搞得头疼,就试试这个”
“连OpenClaw 作者都亲自推荐:如果你被 compaction 搞得头疼,就试试这个”
三、OpenClaw原生机制 VS Lossless-Claw 插件机制
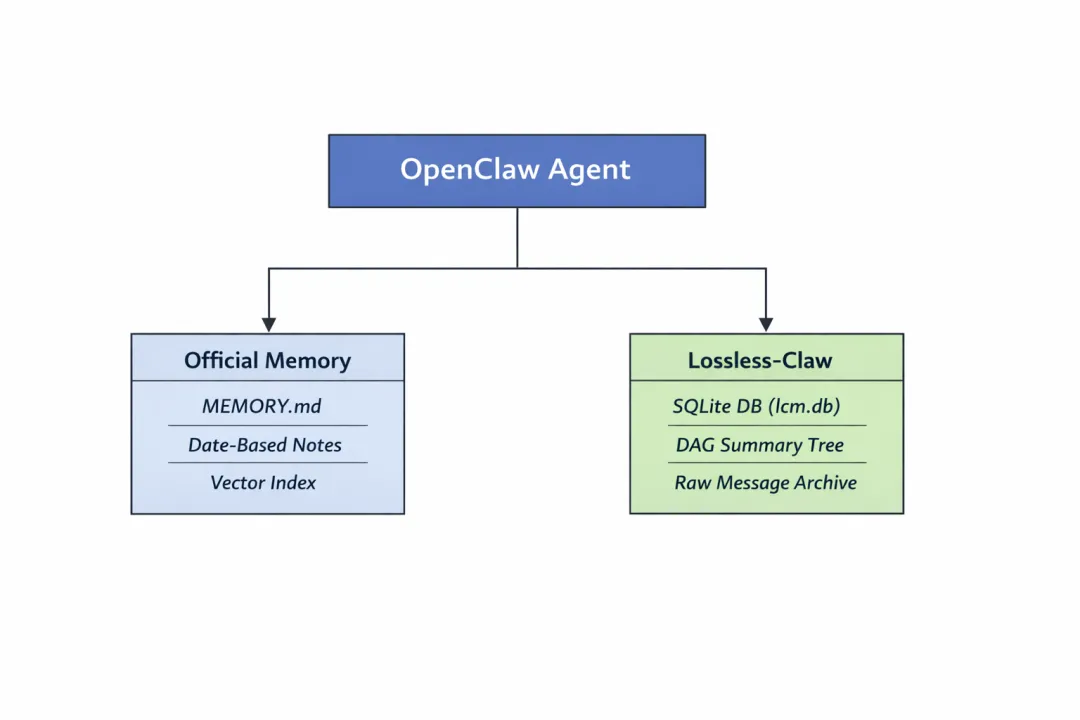
如果觉得前两章 OpenClaw 原生记忆存储机制和 Lossless-Claw 插件记忆存储机制的解析太啰嗦,我们可以看下面的快速对比表,了解它们之间的差异:
|
|
|
|
|
|---|---|---|---|
| 存储方式 |
|
|
|
| 压缩方式 |
|
|
|
| 是否丢失原始数据 |
|
|
|
| 触发时机 |
|
|
|
| 召回细节 |
|
|
|
| 历史保留 |
|
|
|
| Token 控制 |
|
|
|
| 是否需要手动干预 |
|
|
|
如果打个比方来讲,OpenClaw 原生记忆存储机制和 Lossless-Claw 插件记忆存储机制,它们之间的差距就像:
OpenClaw:
像把书撕掉几页,再粘个摘要在上面。
想看原始内容?没了,真没了。
Lossless-Claw:
把整本书扫描进数据库,只在当前阅读时把相关页”智能折叠”给你。
需要翻哪页?随时展开就行。
四、安装与配置
4.1 前置要求
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
4.2 安装命令
# 方式一:Git 安装(推荐)openclaw plugins install \ https://github.com/martian-engineering/lossless-claw# 方式二:npm 包安装(如已发布)openclaw plugins install @martian-engineering/lossless-claw# 方式三:本地开发安装git clone https://github.com/martian-engineering/lossless-clawcd lossless-clawopenclaw plugins install -l .4.3 配置文件
编辑 ~/.openclaw/config.json:
{ "plugins": { "slots": { "contextEngine": "lossless-claw" }, "entries": { "lossless-claw": { "enabled":true, "config": { "contextThreshold": 0.75, "freshTailCount": 32, "incrementalMaxDepth": -1 } } } }}4.4 环境变量
|
|
|
|
|
|---|---|---|---|
LCM_ENABLED |
|
|
|
LCM_DATABASE_PATH |
~/.openclaw/lcm.db |
|
|
LCM_CONTEXT_THRESHOLD |
|
|
|
LCM_FRESH_TAIL_COUNT |
|
|
|
LCM_LEAF_MIN_FANOUT |
|
|
|
LCM_CONDENSED_MIN_FANOUT |
|
|
|
LCM_CONDENSED_MIN_FANOUT_HARD |
|
|
|
LCM_INCREMENTAL_MAX_DEPTH |
|
|
|
LCM_LEAF_CHUNK_TOKENS |
|
|
|
LCM_LEAF_TARGET_TOKENS |
|
|
|
LCM_CONDENSED_TARGET_TOKENS |
|
|
|
LCM_MAX_EXPAND_TOKENS |
|
|
|
LCM_LARGE_FILE_TOKEN_THRESHOLD |
|
|
|
LCM_AUTOCOMPACT_DISABLED |
|
|
|
# ~/.zshrc 或 ~/.bashrc# 推荐起始配置export LCM_FRESH_TAIL_COUNT=32 # 保护最近 32 条消息export LCM_INCREMENTAL_MAX_DEPTH=-1 # 启用无限自动浓缩export LCM_CONTEXT_THRESHOLD=0.75 # 75% 阈值触发配置说明:
-
• freshTailCount=32保护最近 32 条消息不被压缩,给模型足够的近期上下文保持连续性 -
• incrementalMaxDepth=-1启用每次压缩后的无限自动浓缩——DAG 根据需要深入 -
• contextThreshold=0.75在上下文达到模型窗口 75% 时触发压缩,为模型响应留出空间
4.5 Session 重置设置
LCM 通过压缩保留历史,但不改变 OpenClaw 的核心 session 重置策略。
如果 session 重置得比你期望的早,需要调整 OpenClaw 的 session 设置:
{ "session": { "reset": { "mode": "idle", "idleMinutes": 10080 } }}配置说明:
|
|
|
|
|---|---|---|
session.reset.mode |
|
|
session.reset.idleMinutes |
|
|
常用值参考:
-
• 1440= 1 天 -
• 10080= 7 天 -
• 43200= 30 天 -
• 525600= 365 天
对于大多数长周期 LCM 配置,推荐起点:
{ "session": { "reset": { "mode": "idle", "idleMinutes": 10080 } }}注意: 如果同时使用 daily reset 模式,
idleMinutes作为次要保护,session 会在每日边界或空闲窗口先到期时重置。
4.6 重启生效
# 重启 OpenClawopenclaw restart# 或重启 gatewayopenclaw gateway restart4.7 验证安装
# 查看已安装插件openclaw plugins list# 检查 LCM 特定日志openclaw logs | grep LCM# 验证 context engine 已注册openclaw logs | grep "context engine.*lossless-claw"4.8 Agent 工具
安装后,Agent 会自动获得以下工具:
|
|
|
|
|---|---|---|
lcm_grep |
|
lcm_grep "deployment issue" |
lcm_describe |
|
lcm_describe --stats |
lcm_expand_query |
|
lcm_expand_query "API 配置" |
工具说明:
-
• lcm_grep – 在压缩历史中搜索关键词,支持多关键词和限制结果数 -
• lcm_describe – 查看当前 DAG 结构、节点数量、压缩统计 -
• lcm_expand_query – 子代理专用,展开特定主题的完整上下文(不会炸 token)
注意:
lcm_expand工具仅限子代理调用,主 Agent 应使用lcm_expand_query包装器。
4.9 推荐配置组合
# 推荐起始配置(~/.zshrc)export LCM_FRESH_TAIL_COUNT=32 # 保护最近 32 条消息export LCM_INCREMENTAL_MAX_DEPTH=-1 # 启用无限自动浓缩export LCM_CONTEXT_THRESHOLD=0.75 # 75% 阈值触发# Session 重置配置(~/.openclaw/config.json){ "session": { "reset": { "mode": "idle", "idleMinutes": 10080 # 7 天 } }}五、最佳实践
5.1 推荐配置组合
Lossless-Claw + 官方 Memory 系统Lossless-Claw → 会话历史、对话上下文(自动管理)官方 Memory → 长期知识、用户偏好(手动/自动写入)├── MEMORY.md → 项目架构、API Keys、Workflow Rules├── USER.md → 用户偏好、习惯├── SOUL.md → Agent 人格、语气└── lossless-claw → 完整对话历史(SQLite DB)5.2 配置调优建议
|
|
|
|---|---|
| 长对话 | freshTailCount: 64
contextThreshold: 0.8 |
| 短对话 | freshTailCount: 16
contextThreshold: 0.7 |
| 代码审查 | freshTailCount: 48
leafTargetTokens: 2000 |
| 日常聊天 |
|
5.3 定期维护
# 每月检查数据库大小du -sh ~/.openclaw/lcm.db# 备份数据库cp ~/.openclaw/lcm.db ~/backups/lcm-$(date +%Y%m%d).db# 清理过旧的会话(可选,90 天+)sqlite3 ~/.openclaw/lcm.db \ "DELETE FROM messages WHERE created_at < datetime('now', '-90 days');"🔗 相关链接
|
|
|
|---|---|
| GitHub 仓库 |
|
| LCM 论文 |
|
| Loss-less Claw 结构演示 |
|
| OpenClaw 文档 |
|
| ClawHub |
|