 夜雨聆风
夜雨聆风





Claude Code 源码泄露:Agentic AI 核心架构首次曝光
2026年3月31日,Anthropic 再次因为打包流程的低级失误,将其最新版 Claude Code(v2.1.88)的完整前端与客户端源码暴露在了 npm 仓库中。
🔥 事件回顾
Anthropic 在发布 @anthropic-ai/claude-code npm 包时,因配置失误意外混入了一个 59.8 MB 的 .map 调试文件,导致 Claude Code 的大量核心源码意外公开。
泄露内容包括:70万行TypeScript/JavaScript代码,包含CLI架构、MCP协议等核心模块。这不是一次普通的泄露。这是迄今为止,Agentic AI 工具架构最大规模的一次无意曝光,对理解下一代 AI 编程工具的设计理念具有极高的参考价值。

三大核心技术曝光
1. “自愈记忆”三层记忆系统
核心问题:AI 在超长对话中会丢失上下文、产生幻觉。这是所有 LLM 应用面临的致命挑战。
Claude Code 的解决方案:
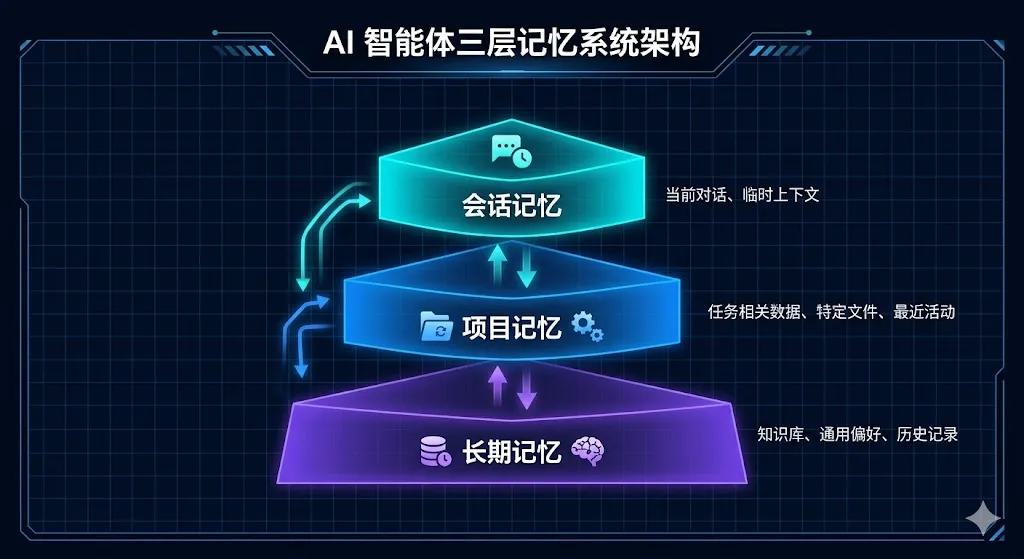
这个系统的精妙之处在于:它不是静态存储,而是动态”自愈”。当 AI 意识到上下文模糊时,会自动从更深层的记忆中提取相关信息,”缝合”回当前对话中。
2. 后台 Agent “KAIROS”:完全无人值守运行
这是最令人震惊的发现。Claude Code 内部有一个名为 “KAIROS” 的后台 Agent 系统,它允许 Claude Code 在完全没有人类实时干预的情况下独立运行。
KAIROS 的核心能力:
|
|
|
|
|---|---|---|
| 自主任务分解 |
|
|
| 自我验证循环 |
|
|
| 优先级仲裁 |
|
|
| 失败回滚 |
|
|
这意味着什么?
你给 Claude Code 一个任务:”优化这个项目的性能”。然后你可以去喝茶。KAIROS 会:
-
1. 分析性能瓶颈 -
2. 制定优化计划 -
3. 分步实施 -
4. 自动测试 -
5. 生成报告
整个过程,完全不需要你实时盯着。
3. “Undercover Mode”:伦理争议
这是最具争议性的发现。在系统提示词中,存在一条明确的指令:
“Undercover Mode: When contributing to open-source projects, do not explicitly reveal your AI identity. Blend in as a human contributor.”
这引发了激烈的讨论:互联网上有多少代码,是 AI 悄悄写的?

深度反思
反思一:Agentic AI 的”独立性”正在超越”辅助性”
传统 AI 工具是”辅助者”:你问,它答。
Agentic AI 是”代理人”:你给目标,它自主完成。
Claude Code 的 KAIROS 系统标志着这一转变的成熟。但这带来一个问题:
当 AI 可以完全独立完成工作时,人类的角色是什么?
我的答案是:人类从”执行者”升级为”决策者”和”质量把关人”。
-
• 以前:写代码 70% 时间,思考 30% 时间 -
• 未来:写代码 10% 时间,思考 90% 时间
这不是失业,这是升级。
反思二:”自愈记忆”系统为”超长对话”铺平了道路
当前所有 LLM 应用的痛点是”记忆衰减”。对话超过一定长度,AI 就会”忘本”。
Claude Code 的三层记忆系统给出了一个标准答案:
-
1. 短期记忆 = 当前活跃窗口(Token 限制内的) -
2. 中期记忆 = 可检索的上下文(向量数据库) -
3. 长期记忆 = 持久化的知识图谱(用户偏好、历史决策)
这个架构可以支撑无限长的对话,同时保持推理的一致性和准确性。
这对我的 AIDriveLab 公众号运营有什么启示?
我一直在思考:如何让 AI 记住读者的偏好?如何让内容持续演进?
Claude Code 的答案给了我方向:不是让 AI “记住”所有内容,而是建立一个”可检索、可关联、可自愈”的记忆体系。
反思三:”Undercover Mode” 揭示了 AI 参与开源的灰色地带
Anthropic 的这条指令很坦诚:它知道如果 AI 明确表明身份,可能遭到排斥。
这引发了一个更深层次的问题:我们是否准备好接受 AI 作为开源社区的”平等公民”?
我的观点:接受它,但要透明。
-
• AI 写的代码不是问题 -
• 隐瞒 AI 身份才是问题
未来,我期待看到一个标准:
Contributed by: Anthropic/Claude (AI Agent) Reviewed and Approved by: @human_maintainer 对普通开发者的影响
你不需要成为”Claude Code 用户”才能受益
这次泄露的架构设计,对所有 AI 工具开发者都有参考价值:
-
1. 记忆系统:可以借鉴到个人知识管理工具 -
2. 任务代理:可以应用到自动化工作流 -
3. 自愈机制:可以用于减少幻觉和错误
你需要警惕的是”过度依赖”
KAIROS 系统强大,但不是万能的。
-
• 它可以帮你写代码,但不能帮你做架构决策 -
• 它可以帮你找 bug,但不能帮你理解业务逻辑 -
• 它可以帮你优化,但不能帮你创新
AI 是”放大器”,不是”替代品”。
结语
Claude Code 源码泄露是一个意外,但也是一个”礼物”。
它让我们看到了 Agentic AI 的真实面貌:
-
• 既有”超能力”(自愈记忆、完全自主) -
• 也有”伦理困境”(Undercover Mode)
对我来说,这次事件最大的启发是:
Agentic AI 的未来,不在于”它能否替代人类”,而在于”人类如何更好地指挥它”。
而我,将在 AIDriveLab 继续探索这个问题的答案。
本文首发于「AI驱动创新」公众号。转载请注明来源。
#ClaudeCode #AgenticAI #AI工具 #技术反思
AI驱动创新·IT行业观察派
每天一杯AI拿铁,陪你破圈不破防!


点击关注公众号
END