 夜雨聆风
夜雨聆风





Claude Code 源码都被翻出来了!11 个企业级 Agent 工程套路,真的太值钱了
这两天 AI 圈有个瓜,真的很大。
Anthropic 的 Claude Code,在 npm 发包的时候,居然把 source map(源码映射文件) 也一起带出去了。
结果是什么?
完整的 TypeScript 源码,直接被社区扒了个底朝天。
很多人看到这个新闻,第一反应是:
“卧槽,源码泄露了!”
但我看完之后,真心觉得更值得关注的,不是“热闹”本身,而是:
这次我们终于有机会,看清一个企业级 AI Coding Agent,到底是怎么做出来的。
说白了,这不是普通八卦。
这是一次非常稀有的“反向拆机”机会。
如果你正在做企业级大模型应用、智能体系统、AI Coding 产品,或者正在想:
-
• Agent 到底该单线程还是多 Agent? -
• 长任务上下文怎么扛? -
• Prompt 写得再好,为什么系统还是不稳? -
• 真正企业级的工程细节,到底体现在哪?
那这篇内容,真的有料。

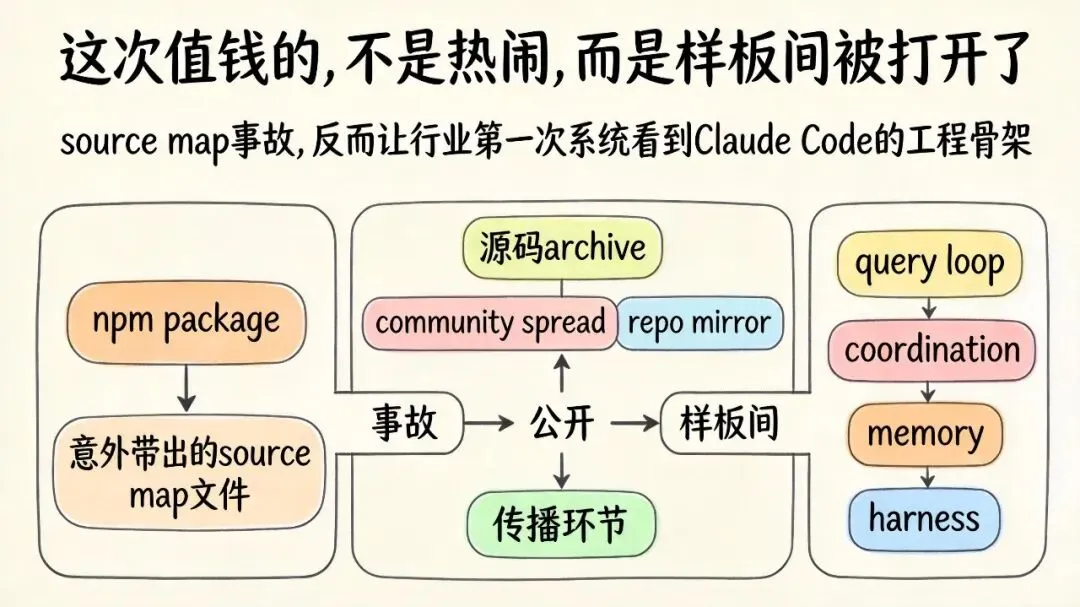
第一招:别先盯着“泄露”两个字,先看它到底暴露了什么💥
先把这个事说清楚。
这次出来的,不是用户数据,不是 API Key,也不是模型权重。
而是 Claude Code 打包时误带出的 source map,顺藤摸瓜之后,社区拿到了大量 TypeScript 源文件。
这意味着什么?
意味着整个行业第一次比较完整地看到:
-
• Claude Code 的全局架构 -
• QueryEngine 的主循环 -
• Coordinator-Worker 的编排逻辑 -
• 三层记忆系统 -
• Prompt Cache 优化 -
• Feature Flag 和后台能力设计
你会发现,这次最值钱的,不是“Anthropic 出了个包事故”。
而是:
一个全球顶级 AI Coding 产品的工程底层,被当成样板间打开了。
这种机会非常少。
因为平时你能看到的,往往都是:
-
• 演示视频 -
• 营销文案 -
• 产品官网截图 -
• 一些零散访谈
但真正决定系统上限的,不是这些表层东西,而是底层工程骨架。
这次骨架,真的被看到了。
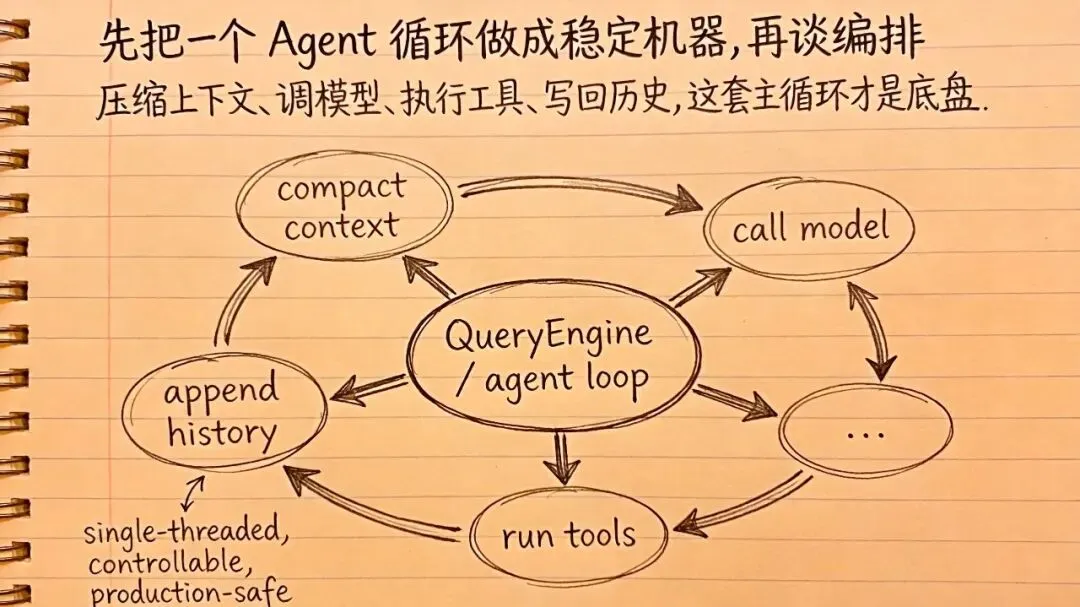
第二招:Claude Code 最强的地方,不是“多 Agent”,而是先把主循环做稳了⚙️
很多人一提 Agent,就很容易陷入一个误区:
觉得越多 Agent 越高级,越像未来。
但 Claude Code 这套源码给人的第一感觉,恰恰相反。
它最底层的核心,不是什么花里胡哨的 Agent 群聊系统,而是一个非常扎实的 单线程主循环。
核心思路很简单:
-
1. 看上下文够不够 -
2. 不够就压缩 -
3. 调模型 -
4. 模型要用工具,就去执行工具 -
5. 把结果写回上下文 -
6. 再跑下一轮
是不是很朴素?
但就是这种朴素,才最能扛生产环境。
因为企业级系统最怕什么?
最怕的是你一上来就堆复杂结构,最后出了问题谁也定位不清。
Claude Code 这里的做法反而很稳:
-
• Tool 调度自己管 -
• Token 预算自己管 -
• 权限检查自己管 -
• 错误恢复自己管
没有把命根子交给第三方 Agent 框架。
这就像什么?
就像你开工地,不是先弄一堆花活,而是先把地基、承重墙、配电箱都打牢。
所以如果你问我,看这套源码最先该学什么,我会先给一句大白话:
先把一个 Agent 循环做成稳定机器,再谈上层编排。
这是很多团队最容易跳过的一步。
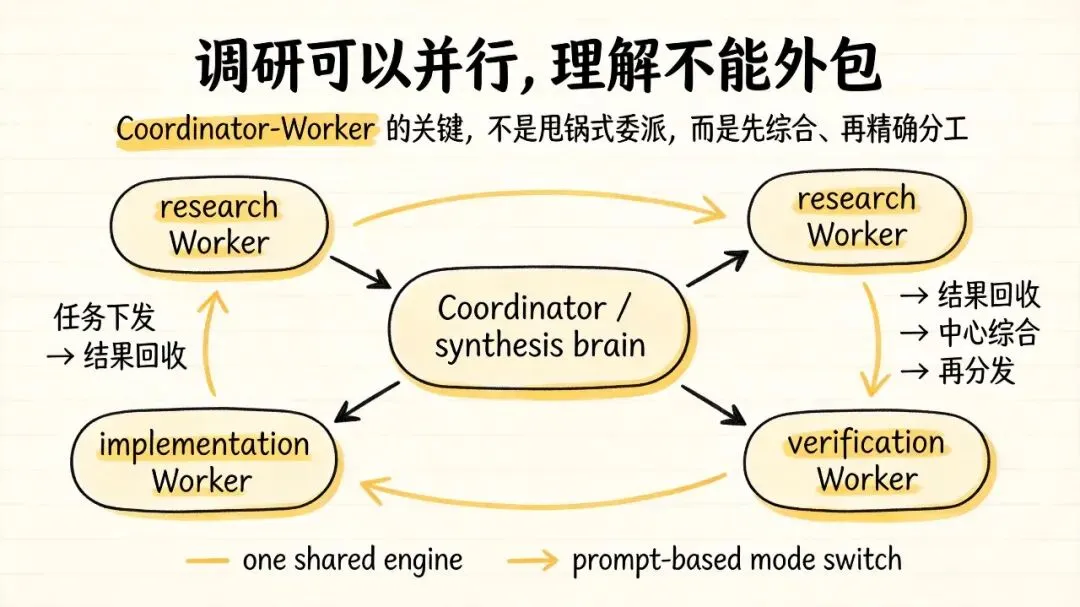
第三招:它不是没有多 Agent,而是“需要时才开”,这才是真工程🧠
Claude Code 当然不是没有多 Agent。
但它的多 Agent 用法,跟很多框架喜欢宣传的那种“大家一起聊、一起推理、一起飞”很不一样。
它更像一个特别懂管理的项目经理:
-
• 平时自己先干 -
• 真有必要时,再派人 -
• 派出去的人干完回来,自己要先读懂结果,再决定下一步
这套设计的核心,就是 Coordinator-Worker。
重点来了:
Coordinator 不是“把活一甩就不管了”,而是必须做综合判断。
源码里对这一点写得非常狠。
大概意思就是:
Worker 调研完把结果交回来之后,Coordinator 不能说一句“根据你的发现去修吧”就完事了。
它必须先自己看懂,自己综合,然后给出一个包含:
-
• 具体文件路径 -
• 具体行号 -
• 具体改法
的精确指令。
这太关键了。
因为现实里很多多 Agent 系统为什么最后越跑越乱?
就是因为“理解责任”没人承担。
每个人都在往下甩锅:
-
• 上层没理解,直接派活 -
• 下层理解偏了,开始乱改 -
• 最后上下文越来越噪,系统越来越飘
Claude Code 这里等于明确规定了一件事:
调研可以并行,理解不能外包。
这才是 Coordinator 真正该干的事。
另外它对子 Agent 也不是一刀切。
它区分了:
-
• Fork:继承上下文,便宜,适合并行读 -
• Fresh Agent:重新开始,适合独立视角,比如代码审查
这说明它的多 Agent 不是为了炫技,而是按任务场景做分工。
这就很企业级。
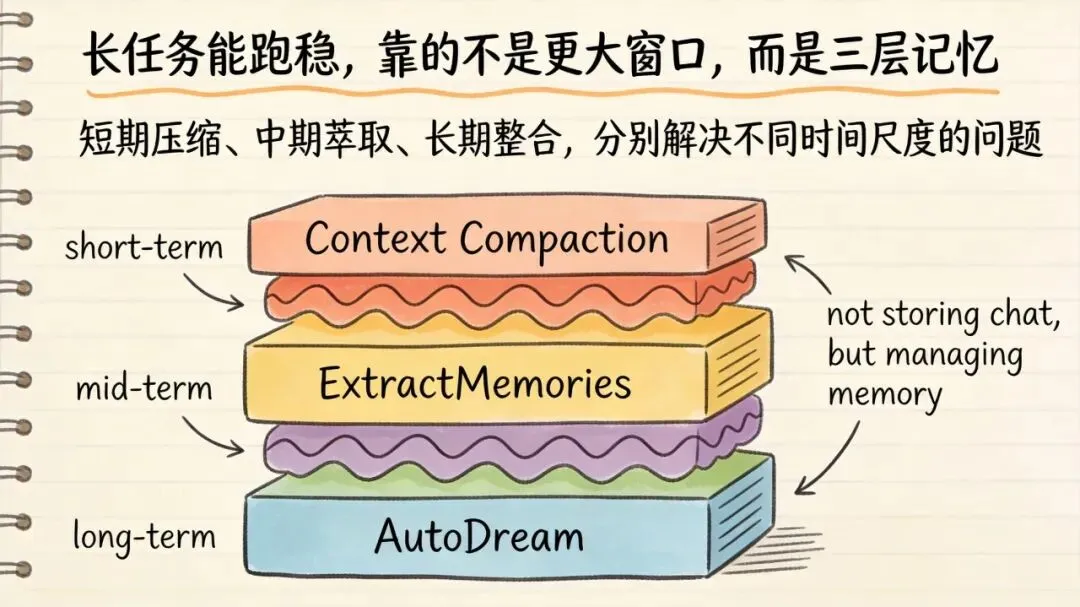
第四招:三层记忆系统,才是 Claude Code 真正的含金量所在🗂️
如果前面几部分让我觉得“工程味很重”,那这一部分我会直接说:
这是这次源码里最值钱的部分之一。
为什么?
因为很多 Agent 系统一旦跑长任务,就会遇到一个老大难问题:
上下文撑不住。
不是忘这,就是忘那。不是 Token 爆掉,就是上下文越来越脏。
Claude Code 的做法不是简单粗暴地“塞更大窗口”,而是直接上了三层记忆系统:
第一层:短期记忆 —— Context Compaction
上下文快满了怎么办?
Claude Code 不会简单删消息,而是让模型生成一份 结构化摘要。
而且不是随便压缩,是有固定结构的。
包括:
-
• 用户当前需求 -
• 关键技术概念 -
• 涉及文件 -
• 错误和修复 -
• 待办任务 -
• 当前工作状态
这就厉害了。
因为它不是“把旧消息砍掉”,而是“把旧消息提炼成还能继续干活的信息”。
第二层:中期记忆 —— ExtractMemories
每轮对话结束后,系统会后台判断:
-
• 主 Agent 有没有主动写记忆 -
• 如果没有,就自动从对话里提取值得保留的信息
也就是说,很多有价值的信息,不需要用户手动总结,系统自己就开始记。
第三层:长期记忆 —— AutoDream
这块最有意思。
Agent 空闲的时候,它还会去整理旧记忆、合并新信号、清理冲突内容、修剪索引。
说白了,就是:
你不操作的时候,它在后台偷偷复盘。
这三层组合起来,才真正解决了一个企业级问题:
任务长、会话长、项目周期长的时候,系统怎么不失忆。
如果你正在做企业级 Agent,这套思路真的值得抄作业。
第五招:真正拉开差距的,往往不是大架构,而是这些“用户无感、系统狂赚”的细节✨
说真的,看源码最爽的一部分,往往不是那些大词。
而是那些一看就知道:
“这个团队一定在生产环境里挨过打。”
Claude Code 里我特别喜欢几类细节。
细节 1:Agent 列表不再内联,改成 attachment
为什么?
因为 Agent 列表会变。
一变,Prompt Cache 就容易失效。
于是它把这部分动态内容挪到 Cache 边界外,结果直接省下 10.2% 的 cache creation token。
这就是典型的企业级优化:
不是改模型,而是改边界。
细节 2:Cron 调度不撞整点
用户说“每天 9 点提醒我”,系统不一定真的给你定成 9:00。
可能是 8:57,也可能是 9:03。
为啥?
因为全球用户都爱说整点。
你全定在整点,服务端就会瞬间爆峰值。
用户根本不在乎这 3 分钟,但系统很在乎。
这类设计太妙了:
用户无感,系统收益巨大。
细节 3:NO_TOOLS_PREAMBLE
在某些任务里,模型明明不该调工具,但它偏要手痒。
Claude Code 怎么做?
直接在 Prompt 最前面写死强约束:
-
• 只能输出文本 -
• 不准调工具 -
• 你调了也会被拒
而且重点是:这段写在最前面,不是最后面。
这其实是很真实的模型使用经验。
关键约束写在开头,效果往往比你塞在结尾强得多。
细节 4:Feature Flag 直接做编译时消除
很多团队做功能开关,是运行时 if/else。
Claude Code 更狠,关掉的功能在编译时直接没了。
这意味着:
-
• 不占内存 -
• 没有分支判断成本 -
• 同一仓库可以并行开发很多未发布功能
这些点单看都不炸裂,但合在一起就是一句话:
顶级工程团队,拼的是细节质量。
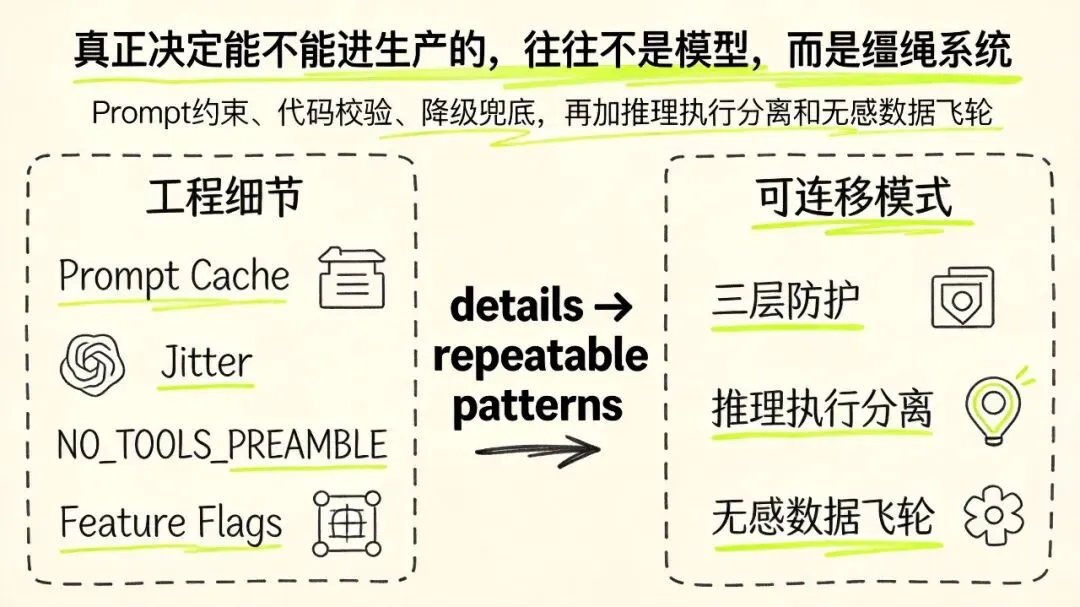
最后一招:如果你做企业级 Agent,真正该学的不是某个技巧,而是这 3 个通用模式🚀
看到最后,如果你还在想:
“那我到底该学什么?”
我直接给你压缩成 3 句话。
模式一:三层防护必须有
别只相信 Prompt。
真正靠谱的链路应该是:
-
• Prompt 先约束 -
• 代码再校验 -
• 最后还有降级兜底
任何关键逻辑,都不能只赌模型会乖。
模式二:推理和执行要分开
让 LLM 负责:
-
• 理解问题 -
• 做判断 -
• 生成方案
让代码负责:
-
• 文件处理 -
• 格式校验 -
• 逻辑约束 -
• 确定性执行
这才是生产系统该有的分工。
模式三:要做无感数据飞轮
最好的反馈收集,不是逼用户点赞点踩,不是要求手动复盘。
而是让系统在用户正常工作过程中,自动把有价值的信息提出来。
Claude Code 的 ExtractMemories,本质上就是这套思路。
所以如果要我给这篇拆解做一个总总结,我会这么说:
Claude Code 这次最值得借鉴的,不是“它有多聪明”,而是“它把 Agent 这件事做得有多工程化”。
这才是真正适合企业级落地的人去研究的地方。
一句话收尾:
别光盯着模型参数了!真正决定企业级 Agent 能不能跑稳、跑久、跑进生产环境的,很多时候不是模型本身,而是你围着模型搭起来的那整套“缰绳系统”。这玩意,Claude Code 已经给你打了个很好的样。🔥