 夜雨聆风
夜雨聆风





Claude Code源码泄露,我扒出了AI智能体的工程化真相
大厂两次犯低级后端错误,给全球程序员送了份AI架构大礼
你好呀,我是恺南,一个正在转型AI应用开发的后端码农。
2026年3月31日,Anthropic又双叒搞砸了——更新Claude Code的npm包时,把60MB的source map调试文件打包发布,导致1902个TypeScript源码全泄露。这是2025年2月后第二次犯同样的错!
众所周知Claude Code是闭源的,由于token太贵和总有bug,大家都自发地想要破解,结果这次直接泄漏了。
作为后端工程师,我第一反应不是”大厂翻车真搞笑”,而是:这哪是泄露,分明是Anthropic把AI智能体的”后端架构图”裸奔给全世界看了!
甚至有些开发者贴脸开大提交源码解析,或者在官方issue评论区打起了广告。
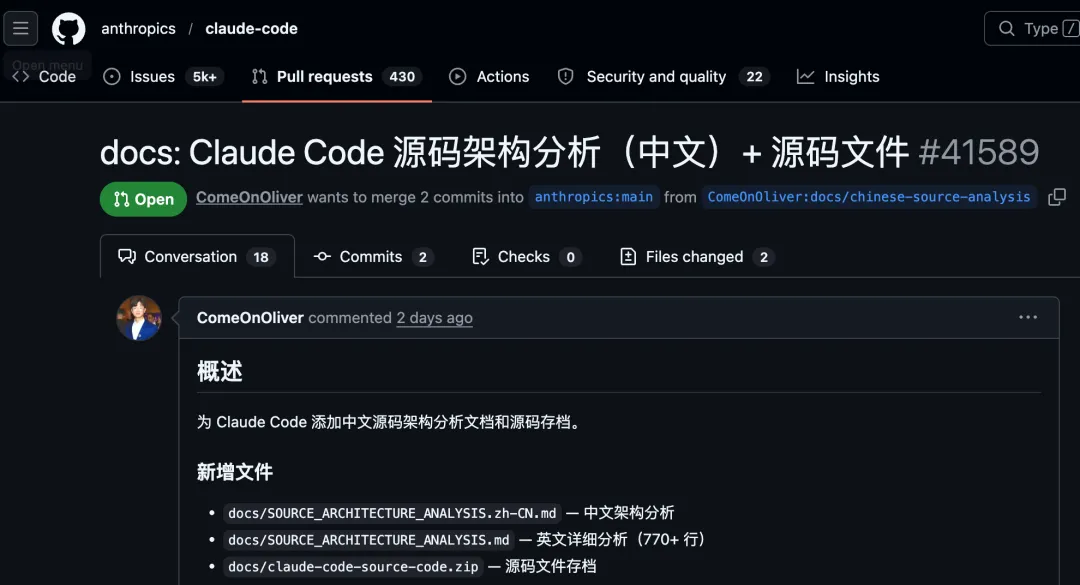
AI圈天天喊”智能体””大模型”,但多数后端工程师觉得”虚”——不懂Prompt、不会调参,难道就只能被AI时代淘汰?直到我翻完这1902个文件,突然顿悟:
Claude Code之所以好用,40%的功劳根本不是Opus模型多牛,而是它背后一套”后端工程师看了直呼眼熟”的工程化架构。所谓的「harness engineering(笼具工程)」,本质就是用后端的”确定性思维”,驯服AI的”不确定性”。
今天,我就用后端视角拆解这份”免费顶级架构师教程”,告诉你:AI智能体的核心,从来都是后端工程能力。
一、先吐槽:Anthropic的CI/CD流水线,该让后端来重构了
作为后端,看到”两次泄露同一问题”,第一反应是:这CI/CD流水线怕不是没做「构建产物校验」?
source map文件本应在打包时通过.npmignore排除,结果两次遗漏——这是后端最基础的「制品管理」失误。相当于上线时把数据库配置文件一起推到生产环境,低级到离谱。

但反过来想:正是这个后端失误,让我们看清了一个真相:AI应用的落地,最终拼的还是后端工程化能力——哪怕你模型再强,流水线掉链子,照样翻车。
二、核心洞察:Claude Code的”笼具工程”,全是后端熟悉的老套路
翻完源码,我发现Claude Code的8大核心设计,本质都是后端工程师天天打交道的”分布式系统问题”。只不过换了个”AI术语包装”:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
下面挑3个最核心的设计,用后端语言深扒:
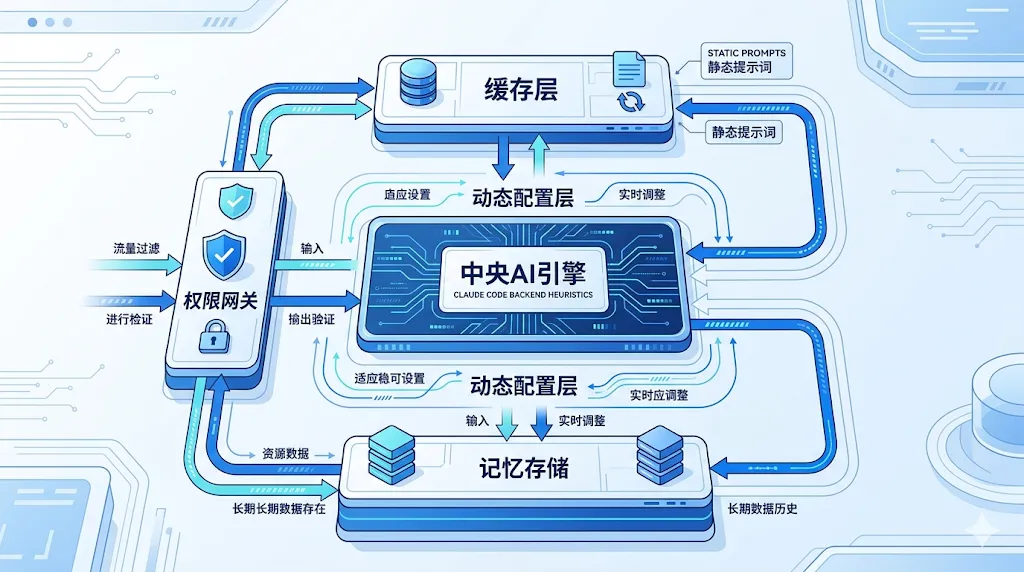
1. 分层System Prompt:后端的”缓存分层+配置中心”玩得明明白白
Claude Code的System Prompt被设计成两种类型:
- 缓存型(systemPromptSection):身份定义、安全准则、工具规则,所有用户共享,一次计算多次复用
- 危险缓存型(DANGEROUS_uncachedSystemPromptSection):用户配置、工作目录、Git状态,每个用户独立,实时重新计算

这简直是后端「缓存分层」的标准操作!
- 静态部分缓存复用:减少重复计算,降低token成本(对应后端的本地缓存+分布式缓存)
- 动态部分实时加载:保证个性化,避免配置不一致(对应后端的配置中心动态推送)
更绝的是,它还考虑了”工具接入的资源成本”——每接入一个MCP服务器,都会增加额外的上下文消耗。这正是后端的「资源权衡思维」:接口不是越多越好,每个接口都有性能成本。
2. AI驱动的操作分类器:后端的”规则引擎+熔断机制”换皮
Claude Code的Auto模式,核心是一个基于AI的操作分类器(Yolo Classifier),本质是「主服务+规则引擎」的架构:
- 主AI:执行用户指令(对应业务服务)
- AI分类器:独立判断操作安全性(对应规则引擎)
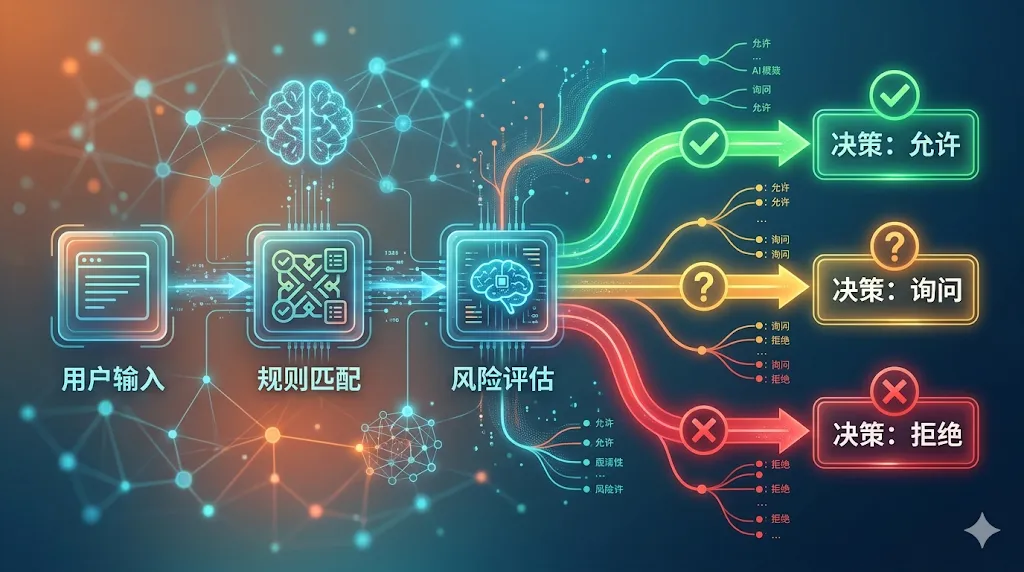
三层分类流水线(而非”四层”),通过规则分组实现自动审批:
-
1. allow:满足条件的操作自动批准(如只读工具、预定义白名单) -
2. soft_deny:高风险操作需要用户确认(如文件写入、系统修改) -
3. environment:环境上下文帮助分类器做判断(如项目类型、工作目录)
这给后端的启示:AI的”安全”,本质是后端的”规则治理”。你不用纠结”怎么让AI变安全”,而是把AI操作当成接口请求,用成熟的规则引擎和权限架构去管控。
3. 多Agent协作:后端的”微服务编排”玩出了新高度
Claude Code的多Agent框架,完全是「企业级微服务架构」的翻版:
- Team = 微服务集群
- Team Lead = 服务网关/调度中心
- Teammate = 业务微服务
- 邮箱文件异步通信 = 消息队列(MQ)
- 独立Git Worktree = 服务隔离(容器化)
- 权限冒泡机制 = 多级审批流
后端最头疼的”分布式协作问题”——任务拆分、信息流转、冲突解决、结果合并——Claude Code用微服务治理的思路全解决了。
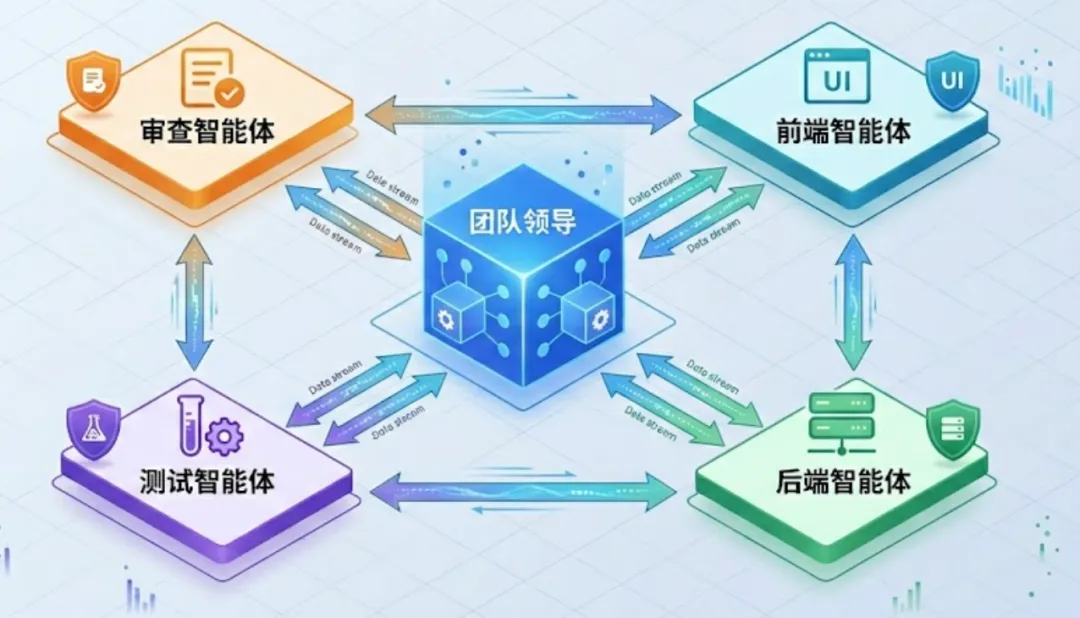
这证明:多智能体协同,根本不是AI的新问题,而是后端玩了十几年的”分布式系统问题”。后端工程师转型AI,这就是你的降维打击点。
三、后端工程师的AI转型启示:别追模型,先练”笼具工程”
翻完1902个文件,我越发坚定一个判断:AI时代,后端工程师的核心竞争力,不是”会用大模型API”,而是”能用后端工程化思维,把AI的不确定性,变成系统的确定性”。
Claude Code的成功,给后端转型AI指了3条明确路径:
1. 思维转型:把AI当”特殊的微服务”
- 不要觉得AI”玄”,它就是一个”输出不确定但能力强”的微服务
- 用后端的”稳定性思维”:给AI加限流、降级、熔断
- 用后端的”可观测性思维”:监控AI的token消耗、响应延迟、输出质量
2. 技能复用:你的核心资产从未过时
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3. 实战落地:从”抄Claude的笼具”开始
不用一开始就搞复杂的AI项目,先把Claude的3个核心设计抄到自己的项目里:
-
1. 实现分层Prompt缓存(静态+动态分离) -
2. 搭建AI操作的安全审查流水线(规则引擎+权限分级) -
3. 设计结构化的上下文压缩与存储
这3件事,用你熟悉的Redis、MQ、数据库就能实现,却能让你的AI应用稳定性、体验感提升一个档次。
结尾:AI时代,后端工程师的第二次机遇来了
Claude Code的源码泄露,像一面镜子:它照出了AI应用的真相——模型是引擎,后端工程化是底盘。没有好的底盘,再强的引擎也跑不稳。
而搭建底盘,正是后端工程师的主场。
你不用羡慕算法工程师懂模型,不用焦虑自己不会调参。你的大厂后端背景、分布式系统经验、工程化思维,都是AI时代最稀缺的核心资产。
就像Claude Code用grep这种朴素工具打赢了向量数据库,后端工程师也能用自己熟悉的技术,在AI时代杀出一条血路。
⚠️ 免责声明:本文基于Claude Code源码泄露事件进行分析,源码基于内部版本,部分特性描述为个人推断,非官方确认。如需深入了解,建议阅读官方文档或等待官方源码开源。
📌 欢迎关注【恺南AI实战派】~
回复关键字【cc源码】获取本文涉及的Claude Code核心模块源码解读