 夜雨聆风
夜雨聆风





CC 源码学习(2):安全设计与安全防范
看到 Claude Code 这类高权限 Agent 工具时,人们关心的除了它能做什么,还有它会不会失控:
- 它居然能执行 Shell,那怎么防止乱跑命令?
- 它能读写文件,那怎么防止误改或越界?
- 它还支持插件、MCP、远程配置,这些不都是风险入口吗?
- 如果模型本身不稳定,项目层到底做了什么来兜底?
这些问题本质上都在问一件事:
一个高权限 Agent 工具,如何在“能力很强”的同时,尽量保持“可控”?
Claude Code 的答案不是靠单点防御,而是用了比较典型的分层防护思路:
- 默认不直接信任输入
- 高风险能力必须通过统一工具层暴露
- 工具执行前进入权限判断与审批链路
- 文件、Shell、网络等关键资源再做专门限制
- 对配置、插件、MCP、受管设置增加额外治理
- 在运行时引入 sandbox、策略、托管配置等“硬边界”
所以这一篇我们不只是看“有没有权限弹窗”,而是看它如何把安全塞进主链路。
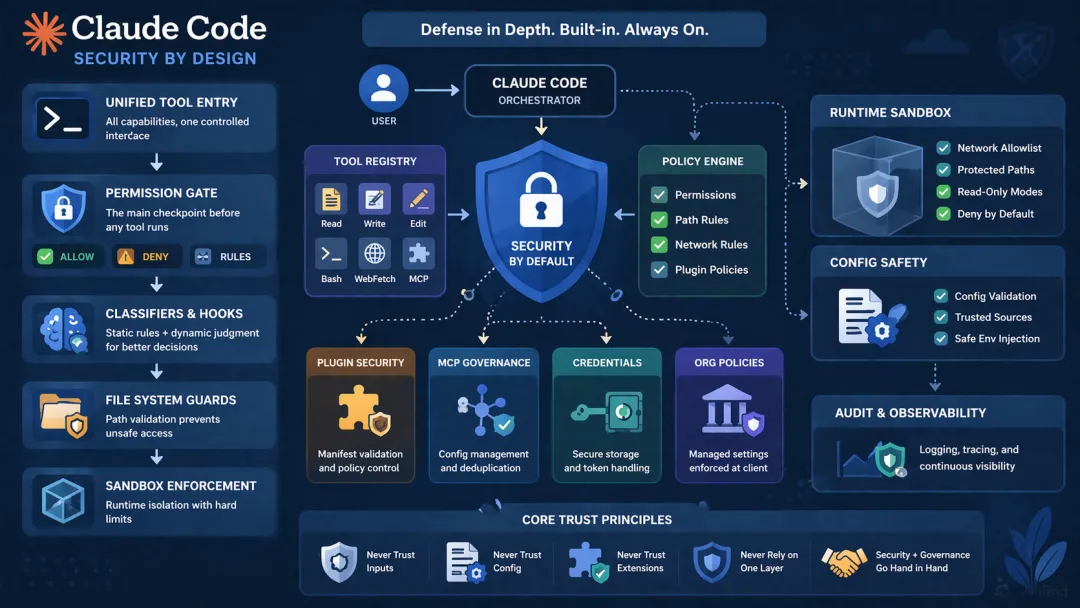
先说结论:Claude Code 的安全不是外挂,而是默认执行路径
在很多 demo 级 Agent 项目里,主链路通常是:
用户输入 -> 模型 -> 工具执行 -> 返回结果但在 Claude Code 里,更接近:
用户输入 -> 命令/提示词处理 -> 模型生成 tool_use -> 权限规则判断 -> 分类器/Hook/策略补充判断 -> 用户审批或自动拒绝 -> 沙箱/路径/网络等运行时限制 -> 工具真正执行 -> 结果回流模型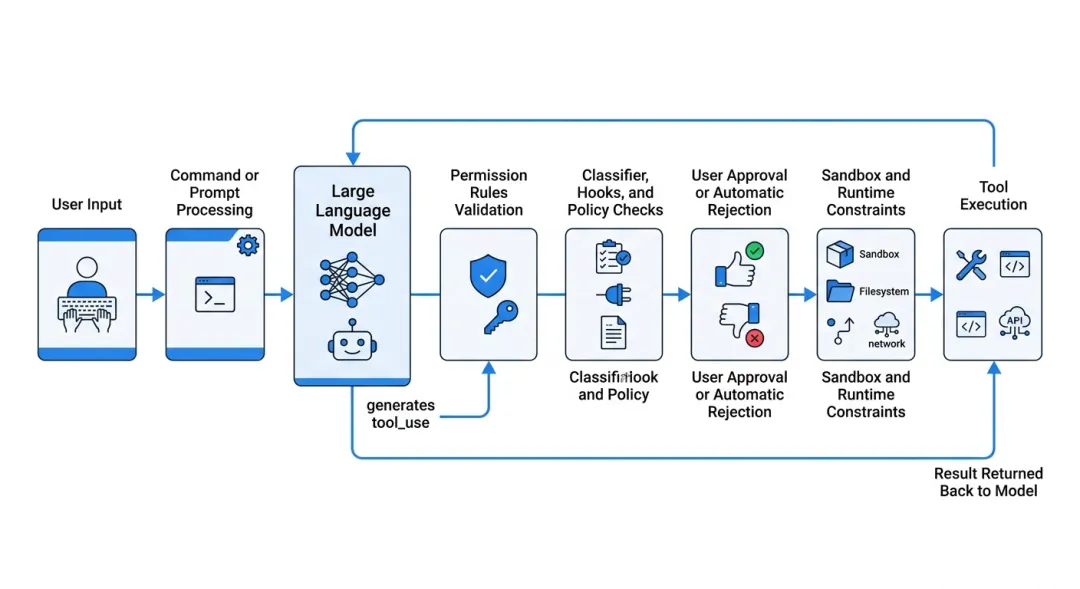
也就是说,安全相关逻辑不是“出问题后再拦”,而是在执行前就进入链路。
这点很重要,因为真正危险的不是“模型会不会犯错”,而是“模型犯错时系统有没有足够多层的刹车”。
第一层:统一工具入口,先把能力收口
Claude Code 的第一个安全前提,不是在 permissions/ 目录里,而是在整个工具架构本身。
前一篇提到过,模型不是直接操作外部世界,而是通过 src/tools.ts 注册出来的工具集合行动。真正的能力暴露要先经过:
- 工具注册
- 工具 schema
- 工具执行上下文
- 工具权限上下文
这部分核心落在:
src/tools.tssrc/Tool.ts
这件事为什么重要?
因为只要能力是“统一工具化”的,系统就可以在同一个拦截点上统一处理:
- 权限审批
- 输入校验
- 执行前说明
- 运行状态展示
- 审计与日志
如果能力是散落的内部函数调用,就很难建立一致的安全边界。
换句话说,Claude Code 的安全能力,首先建立在“架构可治理”这件事上。
第二层:权限系统是工具执行前的总闸门
最关键的权限核心之一在 src/utils/permissions/permissions.ts。
这个文件可以看成是“工具调用决策器”,它会基于上下文决定某个操作到底应该:
allowdenyask
而且它不是简单写死几条规则,而是组合了多种来源:
- 设置文件里的 allow / deny / ask 规则
- policySettings 这类托管策略
- 会话级规则
- 命令或 CLI 注入的规则
- hook 返回结果
- 分类器结果
- 当前 permission mode
这意味着 Claude Code 的权限判断不是“单一 if/else”,而是一套可叠加、可来源分层、可解释的决策系统。
为什么这层设计值得注意
因为真实产品里的权限判断很少只有一种来源。
举个例子,同一个操作可能同时受到:
- 用户个人设置
- 项目级设置
- 企业托管策略
- 当前会话模式
- 自动审批系统
的共同影响。
Claude Code 在 permissions.ts 里做的,就是把这些异构来源收敛成统一决策结果,并且还能生成解释信息,比如:
- 是哪条规则触发的
- 是哪种 mode 导致需要审批
- 是 hook 拦截了
- 还是 classifier 判定有风险
这说明它不仅在“拦”,还在努力把“为什么拦”讲清楚。
一个最小可用版的权限总闸门,大概长这样
type PermissionBehavior = "allow" | "deny" | "ask";interface PermissionDecision { behavior: PermissionBehavior; reason: string;}interface ToolCall { toolName: string; input: unknown;}interface PermissionContext { allowRules: string[]; denyRules: string[]; autoMode: boolean; hook?: (call: ToolCall) => Promise<PermissionDecision | null>; classifier?: (call: ToolCall) => Promise<"safe" | "unsafe" | "unknown">;}function matchRule(rule: string, call: ToolCall): boolean { if (rule === "*") return true; if (rule === call.toolName) return true; return false;}export async function decideToolPermission( call: ToolCall, ctx: PermissionContext,): Promise<PermissionDecision> { // deny 优先 for (const rule of ctx.denyRules) { if (matchRule(rule, call)) { return { behavior: "deny", reason: `matched deny rule: ${rule}` }; } } // allow 命中直接放行 for (const rule of ctx.allowRules) { if (matchRule(rule, call)) { return { behavior: "allow", reason: `matched allow rule: ${rule}` }; } } // hook 二次裁决 if (ctx.hook) { const hookDecision = await ctx.hook(call); if (hookDecision) return hookDecision; } // auto mode 下走分类器 if (ctx.autoMode && ctx.classifier) { const result = await ctx.classifier(call); if (result === "unsafe") { return { behavior: "deny", reason: "blocked by classifier" }; } if (result === "unknown") { return { behavior: "ask", reason: "classifier uncertain" }; } return { behavior: "allow", reason: "classifier marked safe" }; } // 默认 ask return { behavior: "ask", reason: "no matching rule" };}这里最重要的不是 allow / deny / ask 这三个返回值,而是:
所有工具能力都必须先经过同一条决策链,而不是各写各的权限判断。
只有这样,hook、classifier、托管策略、会话模式这些安全能力才能叠加。
第三层:不是所有“允许规则”都真的安全
很多系统做到 allow/deny/ask 就停了,但 Claude Code 还多走了一步:它会识别“看起来是允许,实际上过宽”的规则。
src/utils/permissions/dangerousPatterns.ts 就很有代表性。
这个文件维护了一批危险的 Shell 前缀模式,例如:
pythonnodedenobashshevalexecssh
为什么这些模式危险?
因为你如果写出类似:
Bash(python:*)表面上是在“允许 Python 命令”,实际上几乎等于允许任意代码执行。对于自动模式、批量模式、低干预模式来说,这种规则会让权限系统形同虚设。
所以 Claude Code 不是把“用户配了 allow”就盲信,而是会把过于危险的规则识别出来,并在某些模式下剥离或限制。
这个限制写成代码,大概会长这样
const DANGEROUS_EXEC_PREFIXES = [ "python", "python3", "node", "deno", "tsx", "ruby", "perl", "php", "lua", "npx", "bunx", "bash", "sh", "zsh", "pwsh", "powershell", "cmd /c", "eval", "exec", "ssh",];function normalizeRule(rule: string): string { return rule.trim().toLowerCase();}function isDangerousShellAllowRule(rule: string): boolean { const normalized = normalizeRule(rule); const m = normalized.match(/^bash\((.+)\)$/) || normalized.match(/^powershell\((.+)\)$/); if (!m) return false; const inner = m[1].trim(); if (inner === "*" || inner === "*:*") return true; return DANGEROUS_EXEC_PREFIXES.some((prefix) => { return ( inner === prefix || inner === `${prefix}:*` || inner.startsWith(`${prefix} `) || inner.startsWith(`${prefix}-`) || inner.startsWith(`${prefix}/`) ); });}export function stripDangerousAllowRules( allowRules: string[], mode: "default" | "acceptEdits" | "auto",): string[] { if (mode !== "auto") return allowRules; return allowRules.filter((rule) => !isDangerousShellAllowRule(rule));}这类限制的关键不是“禁止 Bash”,而是防止看似精细的规则,最终退化成“给解释器开了任意代码执行入口”。
这类设计很成熟,因为它承认了一个现实:
配置本身也可能成为风险来源。
第四层:权限判断不只靠静态规则,还结合 Hook 和分类器
在 src/hooks/useCanUseTool.tsx 和 src/utils/permissions/permissions.ts 这条链路里,可以看到 Claude Code 的权限决策不是纯静态的。
它还会结合:
- hook
- classifier
- 不同运行角色下的权限处理器
例如:
- 交互式场景走
interactiveHandler - coordinator / swarm worker 有单独处理逻辑
- 分类器可能把某个命令标成需要审批
这里体现出一个很关键的安全思想:
静态规则适合兜底,动态判断适合补盲区
因为规则擅长处理的是:
- 哪个工具允许
- 哪个路径允许
- 哪个域名允许
但动态行为中的危险,常常来自“具体这次做了什么”。比如同样是 Bash,命令内容完全可能天差地别。
所以 Claude Code 在主链路里给了分类器和 hook 插口,用来处理:
- 特定命令语义风险
- 特定会话态下的补充判断
- 自动模式下的拒绝逻辑
即使在这个外部泄露版本里,bashClassifier.ts 是一个 stub,也依然能看出架构上已经为这类安全增强预留了明确位置。
这一点很重要,因为说明安全能力不是散落补丁,而是被当成一等公民设计的。
第五层:文件系统访问不是“能读写就行”,而是单独做路径安全校验
Claude Code 对文件系统的防护非常像真实工程系统,而不是单纯“提示一下用户”。
关键可以看:
src/utils/permissions/pathValidation.tssrc/utils/permissions/filesystem.ts
在路径校验里,它至少考虑了这些问题:
- 路径是否命中 deny 规则
- 是否属于允许工作目录
- 是否属于内部可编辑/可读取路径
- 是否涉及危险目录或敏感路径
- 是否存在路径穿越风险
- 是否需要结合 sandbox 可写白名单
- Windows / UNC 路径等平台特性是否会带来额外风险
尤其值得注意的是它的处理顺序。
比如在写操作中,它会先检查:
- deny 规则
- 内部允许编辑路径
- 综合安全检查
- 工作目录或 allow 规则
这个顺序说明它不是简单的“只要在工作目录下就能写”,而是先挡掉本不该碰的敏感区域。
一个常见的路径安全校验,可以写成这样
import path from "node:path";type FileOp = "read" | "write";interface PathPolicy { workspaceRoots: string[]; denyPaths: string[]; allowWritePaths: string[];}function isSubPath(target: string, base: string): boolean { const rel = path.relative(base, target); return rel === "" || (!rel.startsWith("..") && !path.isAbsolute(rel));}function containsPathTraversal(p: string): boolean { return p.split(/[\\/]+/).includes("..");}function containsVulnerableUncPath(p: string): boolean { return /^\\\\[^\\]+\\[^\\]+/.test(p);}export function validatePathAccess( rawPath: string, cwd: string, op: FileOp, policy: PathPolicy,): { allowed: boolean; resolvedPath: string; reason?: string } { const clean = rawPath.replace(/^['"]|['"]$/g, ""); const expanded = clean.startsWith("~") ? clean.replace(/^~(?=$|[\\/])/, process.env.HOME || "") : clean; // 1. 先挡 UNC 路径 if (containsVulnerableUncPath(expanded)) { return { allowed: false, resolvedPath: expanded, reason: "UNC network path requires manual approval", }; } // 2. 再挡路径穿越 if (containsPathTraversal(expanded)) { return { allowed: false, resolvedPath: expanded, reason: "path traversal detected", }; } const resolved = path.resolve(cwd, expanded); // 3. deny 优先 for (const denied of policy.denyPaths) { if (isSubPath(resolved, denied)) { return { allowed: false, resolvedPath: resolved, reason: `matched deny path: ${denied}`, }; } } // 4. 必须在工作区内 const inWorkspace = policy.workspaceRoots.some((root) => isSubPath(resolved, root), ); if (!inWorkspace) { return { allowed: false, resolvedPath: resolved, reason: "path is outside workspace roots", }; } // 5. 写操作额外收紧 if (op === "write") { const canWrite = policy.allowWritePaths.some((root) => isSubPath(resolved, root), ); if (!canWrite) { return { allowed: false, resolvedPath: resolved, reason: "write path is not in write allowlist", }; } } return { allowed: true, resolvedPath: resolved };}这背后体现的是典型的越权防护思路:
- 工作目录不是绝对安全区
- 可编辑不代表所有文件都可编辑
- 平台兼容不能牺牲安全判断
对于 Agent 工具来说,这一点尤其重要,因为文件写入通常是最常见、也最容易造成真实破坏的动作。
第六层:Sandbox 不是点缀,而是运行时硬限制
如果说权限审批是“软决策”,那 sandbox 就更接近“硬限制”。
核心文件之一是 src/utils/sandbox/sandbox-adapter.ts。
这个文件做的事情非常关键:把 Claude Code 自己的设置体系,转换成 sandbox runtime 能真正执行的约束配置。
它会处理的内容包括:
- 文件系统读写限制
- 网络访问限制
- 允许域名/拒绝域名
- 允许写入目录 / 拒绝写入目录
- 配置路径解析和规范化
其中有几个细节非常值得注意。
1)把 WebFetch 权限规则转换成网络白名单
也就是说,权限规则不是只用来“弹窗提示”,还会真正落成沙箱网络策略。
2)默认阻止写入 settings 相关文件
这能避免通过改设置文件完成 sandbox escape 或权限绕过。
3)支持“只允许托管域名”或“只允许托管读路径”
这说明企业/组织策略不是 UI 层建议,而是能下沉到执行边界。
一个最小版的“规则转沙箱配置”,可以这么写
interface Settings { permissions?: { allow?: string[]; deny?: string[]; }; sandbox?: { filesystem?: { allowRead?: string[]; allowWrite?: string[]; denyWrite?: string[]; }; network?: { allowedDomains?: string[]; deniedDomains?: string[]; }; };}interface SandboxRuntimeConfig { filesystem: { allowRead: string[]; allowWrite: string[]; denyWrite: string[]; }; network: { allowedDomains: string[]; deniedDomains: string[]; };}function parseWebFetchRule(rule: string): { effect: "allow" | "deny"; domain: string } | null { const trimmed = rule.trim(); const deny = trimmed.startsWith("!"); const body = deny ? trimmed.slice(1) : trimmed; const m = body.match(/^WebFetch\(([^)]+)\)$/i); if (!m) return null; return { effect: deny ? "deny" : "allow", domain: m[1].trim().toLowerCase(), };}export function toSandboxRuntimeConfig(settings: Settings): SandboxRuntimeConfig { const allowRead = [...(settings.sandbox?.filesystem?.allowRead ?? [])]; const allowWrite = [...(settings.sandbox?.filesystem?.allowWrite ?? [])]; const denyWrite = [...(settings.sandbox?.filesystem?.denyWrite ?? [])]; const allowedDomains = [...(settings.sandbox?.network?.allowedDomains ?? [])]; const deniedDomains = [...(settings.sandbox?.network?.deniedDomains ?? [])]; for (const rule of settings.permissions?.allow ?? []) { const parsed = parseWebFetchRule(rule); if (parsed?.effect === "allow") { allowedDomains.push(parsed.domain); } } for (const rule of settings.permissions?.deny ?? []) { const parsed = parseWebFetchRule(rule); if (parsed?.effect === "deny") { deniedDomains.push(parsed.domain); } } // 关键:默认禁止改配置文件 denyWrite.push( ".claude/settings.json", ".claude/settings.local.json", ".mcp.json", ); return { filesystem: { allowRead: [...new Set(allowRead)], allowWrite: [...new Set(allowWrite)], denyWrite: [...new Set(denyWrite)], }, network: { allowedDomains: [...new Set(allowedDomains)], deniedDomains: [...new Set(deniedDomains)], }, };}这类设计非常有现实意义,因为很多情况下用户点了允许,并不代表系统就该完全放开。
真正稳的做法,是让审批和沙箱同时存在,让它们变成双保险。
第七层:配置本身也被当成不可信输入
很多系统在安全设计上容易忽略一个点:
配置文件也是输入,而且可能是危险输入。
Claude Code 在这方面处理得比较认真,相关文件包括:
src/utils/settings/validation.tssrc/utils/managedEnv.ts
配置校验
validation.ts 用 Zod 对 settings 做严格校验,并且把错误格式化成更易读的提示。
这里的意义不只是“防止 JSON 写错”,更重要的是:
- 避免无效配置悄悄生效
- 避免非法字段混入系统
- 让配置变更具备更高可预测性
环境变量不是随便从任何设置源都能注入
managedEnv.ts 更值得单独说。
它明确区分了两类来源:
- 可以在 trust dialog 前生效的可信设置源
- 只能在 trust 建立后才能完整生效的设置源
特别是项目级设置不会在一开始就被无条件信任,因为项目目录里的配置可能来自他人提交,存在把请求导向恶意服务、篡改运行环境的风险。
这个限制很适合用代码讲清楚
type SettingSource = | "userSettings" | "flagSettings" | "policySettings" | "projectSettings" | "localSettings";const TRUSTED_SOURCES = new Set<SettingSource>([ "userSettings", "flagSettings", "policySettings",]);const SAFE_PROJECT_ENV_KEYS = new Set([ "HTTP_PROXY", "HTTPS_PROXY", "NO_PROXY", "TERM", "COLORTERM",]);export function applyEnvFromSettings( source: SettingSource, env: Record<string, string> | undefined, trustedEstablished: boolean,) { if (!env) return; // trust 建立前:只有可信来源可以完整注入 if (!trustedEstablished) { if (!TRUSTED_SOURCES.has(source)) return; for (const [k, v] of Object.entries(env)) { process.env[k] = v; } return; } // trust 建立后:项目级来源只允许有限白名单 if (!TRUSTED_SOURCES.has(source)) { for (const [k, v] of Object.entries(env)) { if (SAFE_PROJECT_ENV_KEYS.has(k)) { process.env[k] = v; } } return; } // 可信来源正常应用 for (const [k, v] of Object.entries(env)) { process.env[k] = v; }}这个设计说明项目非常清楚:
“本地文件”不等于“可信文件”,尤其是 project-scoped 配置。
这类意识在普通工程项目里常常会被忽略,但在 Agent 产品里非常关键,因为配置可以直接影响:
- API 请求目的地
- 身份认证方式
- 代理与证书行为
- 子进程环境
第八层:插件系统不是简单“装了就跑”,还做了策略和清单校验
插件和扩展能力天然会放大攻击面,所以 Claude Code 没有把插件当成普通静态资源处理。
相关可以重点看:
src/utils/plugins/validatePlugin.tssrc/utils/plugins/pluginPolicy.ts
1)插件清单校验
validatePlugin.ts 会对 plugin.json、marketplace.json 等内容做解析和校验,重点包括:
- JSON / YAML 结构是否合法
- 是否命中 schema
- 是否存在路径穿越问题
- 某些字段是否出现在错误位置
尤其是对 .. 这类路径穿越模式的显式检查,非常说明问题。
因为插件最危险的地方之一,就是借“声明式配置”把实际加载路径偷偷带出插件目录。
一个最小版的插件清单校验,可以这样写
interface ValidationError { path: string; message: string;}function hasPathTraversal(p: string): boolean { return p.split(/[\\/]+/).includes("..");}function checkPathTraversal( value: unknown, fieldPath: string, errors: ValidationError[],) { if (typeof value !== "string") return; if (hasPathTraversal(value)) { errors.push({ path: fieldPath, message: `Path contains ".." and may be a path traversal attempt: ${value}`, }); }}export function validatePluginManifest(manifest: Record<string, unknown>) { const errors: ValidationError[] = []; for (const key of ["commands", "agents", "skills"]) { const val = manifest[key]; const arr = Array.isArray(val) ? val : val ? [val] : []; arr.forEach((item, i) => { checkPathTraversal(item, `${key}[${i}]`, errors); }); } return { success: errors.length === 0, errors, };}2)插件策略控制
pluginPolicy.ts 则体现了另外一层安全能力:组织策略可以直接禁用某些插件。
这意味着插件是否可安装、可启用,不完全由用户个人决定,还会受托管策略约束。
对于企业场景来说,这是非常必要的,因为插件往往意味着:
- 新命令入口
- 新工具入口
- 新 MCP 服务接入
- 新的外部依赖与执行逻辑
如果没有策略层,插件生态很容易变成安全短板。
第九层:MCP 不是“外接能力越多越好”,而是要做配置治理与去重控制
Claude Code 对 MCP 的处理,也体现出明显的安全与治理意识。
相关入口之一是 src/services/mcp/config.ts。
这个模块里可以看到几类很有代表性的处理:
- 区分不同 scope 的 MCP 配置
- 结合 settings、plugin、enterprise config 做合并
- 写
.mcp.json时采用临时文件 +datasync+ 原子 rename - 对 server config 做 schema 校验
- 对插件注入的 MCP server 做去重
- 支持 enterprise 托管 MCP 配置
为什么这也属于安全设计
因为 MCP 服务本质上是在给系统新增能力和外部连接。
风险主要不在“有没有 MCP”,而在:
- MCP 从哪里来
- 配置是否可靠
- 会不会与已有服务冲突
- 企业是否能强制管理
一个很值得写进文里的细节,是原子写配置
import { open, rename, unlink, chmod, stat } from "node:fs/promises";export async function atomicWriteJson( targetPath: string, data: unknown,): Promise<void> { let mode: number | undefined; try { const s = await stat(targetPath); mode = s.mode; } catch { // 文件不存在时忽略 } const tempPath = `${targetPath}.tmp.${process.pid}.${Date.now()}`; const handle = await open(tempPath, "w", mode ?? 0o644); try { await handle.writeFile(JSON.stringify(data, null, 2), "utf8"); await handle.datasync(); } finally { await handle.close(); } try { if (mode !== undefined) { await chmod(tempPath, mode); } await rename(tempPath, targetPath); } catch (err) { try { await unlink(tempPath); } catch {} throw err; }}原子写 `.mcp.json“ 这种细节也很值得关注,因为它降低了配置写坏、半写入、并发破坏等问题。
这些问题表面上像“健壮性”,但在安全里也同样重要,因为损坏配置往往会造成绕过、降级或异常 fallback。
第十层:认证信息和敏感凭据也做了分层存储
Claude Code 在凭据处理上也有比较清楚的层次。
可以看:
src/utils/secureStorage/index.tssrc/utils/sessionIngressAuth.tssrc/bridge/jwtUtils.ts
1)secure storage 分平台处理
在 macOS 上优先使用 keychain,不行再 fallback;其他平台则有单独实现路径。
虽然这里并不代表“所有平台都达到了同样强度”,但至少能看出设计方向是:
- 凭据不应该只是一段普通文本配置
- 应该优先借助平台安全能力保存
2)session ingress token 有明确优先级和回退路径
sessionIngressAuth.ts 里能看到 token 获取顺序:
- 环境变量
- 文件描述符
- well-known file
同时还区分了:
- session key 走 Cookie + Organization Header
- JWT 走 Bearer Token
这说明它不是把所有 token 一股脑拼接出去,而是对不同类型凭据有明确协议处理。
第十一层:组织策略和受管设置可以把安全要求“下压”到客户端
Claude Code 还有一个非常成熟的方向,就是把安全要求放进:
policySettings- remote managed settings
这一类托管配置里。
你从下面这些模块都能看到这种痕迹:
src/entrypoints/init.tssrc/services/policyLimits/index.tssrc/utils/managedEnv.tssrc/utils/plugins/pluginPolicy.tssrc/utils/sandbox/sandbox-adapter.ts
这说明它不只是“给个人开发者一个本地工具”,而是在按企业级工具做设计。
企业环境里,很多限制不能靠用户自觉,例如:
- 哪些插件能用
- 哪些域名能访问
- 哪些路径能读写
- 哪些 env 可以覆盖
- 哪些 MCP 配置允许接入
Claude Code 的做法,是让这些约束能以策略形式从上游下发,并且进入本地运行时真正生效。
这套安全设计的核心思想是什么
如果把上面这些点收束一下,我觉得 Claude Code 的安全设计主要体现了 5 个思想。
1)不信任模型
模型有能力,但不拥有最终执行权。
它想执行工具,必须通过:
- 权限系统
- 规则系统
- 审批系统
- 沙箱系统
2)不信任配置
不是所有本地配置都默认安全,尤其是项目级设置、插件清单、MCP 配置、环境变量注入点。
3)不信任扩展
插件、MCP、远程连接都被当成高风险扩展能力处理,而不是“越多越好”。
4)不只靠一层拦截
权限、分类器、hook、路径校验、sandbox、托管策略,这些是叠加的,不是互相替代的。
5)安全和工程治理是绑在一起的
很多设计看起来像“工程细节”,例如原子写配置、严格 schema、分层设置源、配置优先级控制,但这些恰恰是安全真正落地的基础。
十三、如果你想复用这些思路,可以先学什么
如果你想自己做类似的 Agent / CLI 框架,我建议优先借鉴下面几类做法:
- 所有外部能力统一工具化,不要让模型随意碰系统接口。
- 在工具调用前建立统一权限决策层,不要把审批逻辑散在各工具里。
- 对文件、Shell、网络分别做专项风险校验,不要指望一条总规则解决全部问题。
- 配置、插件、扩展协议都当成潜在攻击面处理。
- 审批和沙箱同时存在,软控制和硬限制都要有。
- 给企业托管策略预留位置,否则产品一旦进入组织环境就很难补救。
总结
Claude Code 的安全设计,不是“加了几个确认框”,而是把安全嵌进了整个运行时:
- 工具能力先统一收口
- 工具调用先过权限总闸门
- 规则之外再加 hook 和分类器
- 文件、Shell、网络分别做专门限制
- 运行时用 sandbox 做硬隔离
- 配置、插件、MCP、环境变量都做治理
- 企业策略还能继续向下压实
所以它真正想解决的,不是“让模型绝对不犯错”,而是:
当模型可能犯错、配置可能被污染、扩展可能带来风险时,系统是否还有足够多层机制把问题挡在执行之前,或者至少把影响范围压小。
如果只从概念上讲,Agent 的安全设计很容易变成空话。真正能落地的安全,通常都长成一些很“不优雅”的代码:
- 识别并剥掉危险 allow 规则
- 所有工具统一走 allow / deny / ask 决策
- 文件路径先做 UNC、穿越、越界校验
- 把 WebFetch 规则真正转换成 sandbox 域名白名单
- 区分哪些配置来源能在 trust 之前生效
- 插件和 MCP 配置先做结构与路径安全检查
- 写关键配置时用原子写而不是直接覆盖
这些代码不华丽,但它们才是“模型可能犯错时,系统还能不能稳住”的关键。
这也是为什么 Claude Code 这类项目值得研究。它给出的不是抽象安全口号,而是一套比较工程化、可落地的 Agent 安全实现路径。
往期推荐
CC 源码学习(1):框架设计与整体架构一个安全、简单的 SSH 管理方式 secssh每次给交换机做配置都像重来一遍?试试这个小工具Markdown 转公众号排版工具:md2wechat