 夜雨聆风
夜雨聆风





Claude Code“50万行源码泄露”,深度分析封号机制、模型偷换真相、揭示四层上下文压缩算法
导语
“Claude Code 50万行源代码泄露”“封号机制”“模型偷换”“四层上下文压缩算法”“三层记忆架构”“18个隐藏功能”……
Claude Code 之所以让很多人觉得比一堆套壳 Agent 更聪明,不一定只是模型更强,而是它在“上下文管理、记忆提取、权限安全、失败恢复、追踪风控”这些脏活累活上,做得非常重。
换句话说,真正拉开差距的,往往不是回答那一瞬间的智商,
而是整个系统怎么处理长对话、长任务、工具调用、记忆沉淀和异常情况。
一、先说清楚:到底有没有“偷换模型”?
这也是很多人用 Claude Code 时最容易起疑心的地方:
我明明选的是 Opus,为什么有时候感觉像在用小模型?是不是后台偷偷给我降级了?
结论很明确:
不存在“偷偷把主对话模型换掉”这件事。
根据他整理的代码逻辑,主对话模型优先级基本是:
-
会话内 /model 指令 -
启动参数、环境变量、配置项 -
默认主模型
也就是说,你显式指定了什么,主对话就按那个走。
真正会在后台出现 Haiku 之类“小模型”的地方,主要是一些辅助任务,比如:
-
配额检查 -
摘要生成 -
某些轻量后台任务
这类调用不会替代你和主模型的核心交互。
唯一真正可能让主模型发生变化的,是连续服务器过载触发的 fallback,而且代码里是会给出明确提示的,不是偷偷摸摸发生。
这点其实特别重要。
因为它说明 Claude Code 的“像变笨了”,很多时候不是主模型被掉包,而更可能是:
-
上下文被压缩了 -
工具结果被裁剪了 -
当前轮预算吃紧 -
任务复杂度和上下文状态变了
也就是说,问题常常不在“模型换了”,而在“系统怎么喂给模型”。
二、比“偷换模型”更值得注意的,是它已经具备了一整套追踪与风控底座
另一个最刺激的说法,是“封号机制”。
更稳妥的说法不是“发现了一个明确的封号按钮”,而是:
Claude Code 已经具备了一整套足够成熟的追踪、归因与风险控制基础设施。
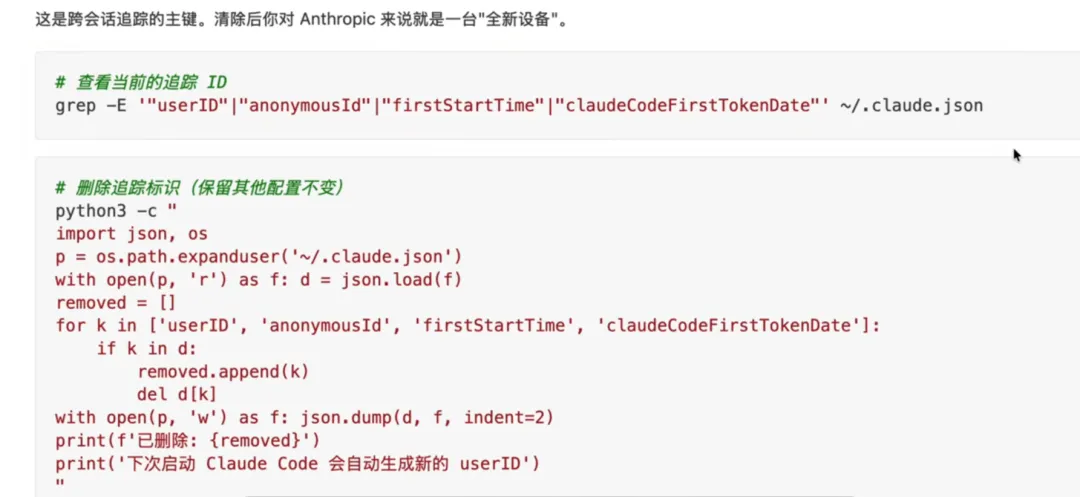
Claude Code 至少涉及这些标识:
- userID
:持久设备级追踪 ID - anonymousId
:备用匿名标识 - accountUuid
与 emailAddress:OAuth 登录后的账号关联 - rh
:仓库 remote URL 的哈希 - Statsig stable ID
:特性开关系统里的稳定设备标识 
这些信息本身不等于“封号”,
但它们足以回答风控系统最核心的几个问题:
-
这是不是同一个用户 / 同一台设备 -
他在哪些仓库里用了产品 -
他的请求环境和行为模式是否异常 -
某些限制、灰度策略或风险规则是否该继续命中这个对象
更关键的是,笔记还提到数据会流向:
-
Anthropic 自家的事件日志接口 -
Datadog 之类的日志系统 -
Statsig / GrowthBook 这类特性开关系统
这意味着 Claude Code 并不是一个“纯本地、无痕、只在你机器上跑”的工具。
它更像一个典型的现代 SaaS/Agent 产品:本地客户端只是壳,背后有持续的遥测、实验开关、账号绑定和服务端判断。
这里还有一个值得注意的细节。
Claude Code 不收集硬件指纹,也就是没有看到 MAC 地址、CPU 型号、内存、GPU 这些传统硬件指纹级别的信息。
但这不代表它“认不出你”。
因为在很多商业风控场景里,真正高频使用的并不是硬件指纹,而是:
-
账号身份 -
持久 ID -
请求模式 -
仓库关联 -
遥测事件 -
特性开关返回值 -
版本与环境状态 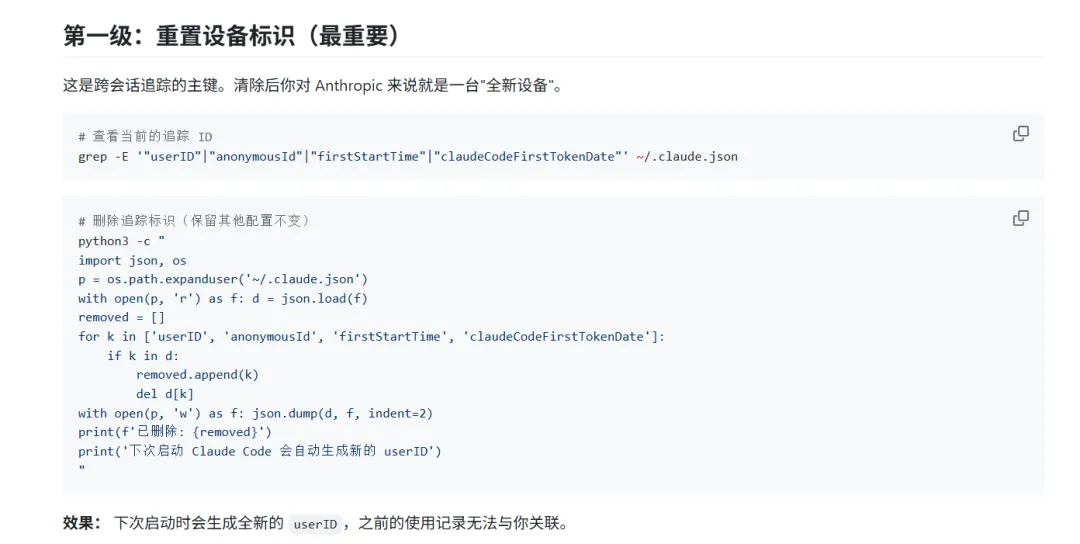
这些拼起来,已经足够做大部分风控判断了。
“封号机制”翻译成更准确是:
Claude Code 不是明晃晃地把“封号规则.txt”摆在你面前,而是已经具备了让封禁、限流、灰度、追踪、归因这些事情可以工程化运行的全部前提。
这对普通用户真正重要的启发有两个。
第一,别把这类 AI 编码工具想象成“离线软件”,它本质上更接近云端服务的前端。
第二,真正决定你体验的,不只是模型能力,还有平台治理能力,而治理能力的另一面,永远就是风控能力。
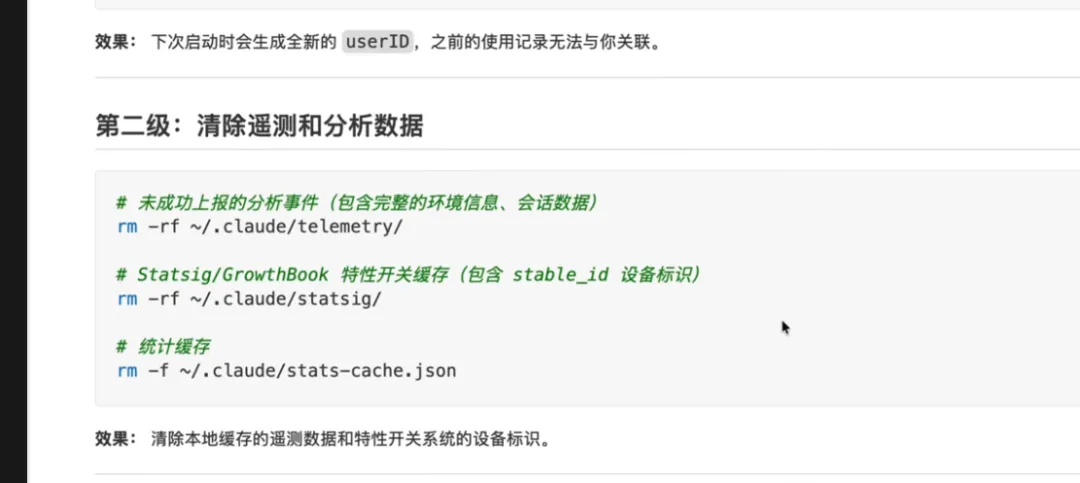
macOS 上清除 Claude Code 追踪数据指南,由AI超元域博主整理。感兴趣的可以自己去搜。

三、真正厉害的不是模型,而是它把“上下文快爆了”当成一个完整工程问题来处理
这是整套分析里最有技术含量的一部分。
Claude Code 对上下文不是简单粗暴地“满了就总结”,而是做成了一个多层防线系统。核心思路非常像大型服务系统的限流与降级:
-
单轮工具结果预算 -
历史裁剪 -
微压缩 -
上下文折叠 -
自动摘要 -
硬限制 -
出错后的紧急压缩恢复
这背后最值得普通人理解的一点是:
优秀的 Agent 不是没有上下文问题,而是它会尽一切办法,尽量晚一点、稳一点、少破坏一点地处理上下文问题。
1. 它优先保护 prompt cache 稳定性
很多人做 Agent,只盯着“能不能塞更多内容”。
Claude Code 这套做法更像是在平衡三件事:
-
塞得下 -
别太贵 -
别破坏缓存命中率
它甚至会宁可保留一些旧内容,也不轻易改动已经进入缓存的部分。
因为一旦你压缩得太激进,虽然省了上下文,却可能让后续请求变得更贵、更慢、更不稳定。
2. 它不是只有“总结”,还有“投影式折叠”
这点非常像数据库里的 CQRS 思路。
不是把原始历史直接删掉,而是维护一套更适合当前轮发送给模型的“投影视图”。
这意味着:
-
UI 层还能保留更完整的历史 -
API 层看到的是更省 token 的版本 -
会话恢复和错误恢复也更容易做
说得直白一点,Claude Code 强的地方,不只是“能说会道”,而是它把“别把自己聊死”这件事做成了系统工程。
四、真正让它越聊越像“熟人”的,不只是记忆,而是三层记忆分工
这套设计大致可以理解成三层:
1. 会话记忆
只服务当前会话,偏短期。
它更像是为了让长任务不中断、让压缩之后还能保留当前目标和关键状态。
2. 持久记忆
跨会话、按项目保存。
这部分会把一些用户偏好、项目背景、参考信息、反馈等沉淀下来,写入本地记忆目录和索引。
3. 团队记忆
跨用户、按仓库共享。
这就不是“我个人和助手的默契”了,而更像是团队知识层。
这套分层最聪明的地方,在于它没有把“记忆”做成一个大杂烩。
因为真正的记忆系统,不是“能存多少”,而是:
-
什么该存 -
什么不该存 -
什么只该当前会话知道 -
什么值得跨会话保留 -
什么可以上升到团队共享
系统会明确排除很多东西不进记忆,比如代码结构、近期 git 变更、临时任务细节等,因为这些本来就可以从别处推导出来。
这点反而很高级。
不是所有信息都值得记住,好的记忆系统首先要学会遗忘。
五、外界总盯着“彩蛋”,但真正体现产品水平的是权限和安全设计
真正能体现 Claude Code 工程水平的,其实是权限与安全系统。
一个重点是:
Bash 权限检查不是一个 if-else,而是一整套分层级联机制,包含:
-
结构化命令解析 -
deny / ask / allow 规则 -
只读命令分类 -
shell 安全分析 -
误解析防护 -
复合命令防护
你可以把它理解成:
Claude Code 不只是“会不会用终端”,它还在认真防自己误用终端。
这点很关键。
因为 Agent 真正走向生产,不是比谁更敢执行命令,而是比谁更少把用户环境搞炸。
很多演示型 Agent 看起来很猛,
但一到真实环境就危险,原因恰恰是少了这层“很烦但必须有”的安全设计。
所以,普通人最该带走的,不是“哇,原来还有这么多隐藏命令”,
而是:
一个能长期用的 Agent,本质上更像操作系统,不像聊天玩具。
六、最值得看的信号,其实是 Anthropic 为什么要把 2.1.88 撤回
有人提到“恢复泄露版本”
从公开记录的排查来看,一个相对明确的事实是:
- @anthropic-ai/claude-code
的 latest 标签曾从 2.1.88 回退 - 2.1.88
在 npm registry 中被撤掉 -
自动更新器会跟随 latest,因此本地出现了“自动切回旧版本”的现象
这里真正值得关注的,不是阴谋论,
而是一个很现实的判断:
Claude Code 迭代速度已经快到,发布、撤回、回滚本身都成了产品能力的一部分。
这背后的含义是:
-
这类 Agent 产品还远没稳定到“几年不大改一次” -
很多内部能力仍在快速实验 -
用户感知到的“变聪明”“变笨”“风格变化”,可能既来自模型变化,也来自系统策略变化
所以未来看这类工具,不能只问“底模是什么”,
还得问:
-
它的上下文策略变了吗 -
它的压缩策略变了吗 -
它的工具执行策略变了吗 -
它的记忆与权限边界变了吗 -
它的遥测与风控策略变了吗
真正决定体验的,越来越是“系统层”,不是单一模型名。
七、对普通用户最有帮助的,不是围观泄露,而是看清 Agent 产品已经在比什么
我觉得最重要的结论不是八卦,而是这个:
下一阶段的 Agent 竞争,已经不只是“谁接了更强模型”,而是“谁更像一个完整的工作系统”。
真正拉开差距的能力,越来越是这些东西:
-
长任务下如何保上下文 -
工具结果如何裁剪又不失真 -
何时压缩、何时保留缓存 -
记忆怎么分层 -
模型回退怎么透明告知 -
权限系统如何避免事故 -
追踪与风控如何平台化运转 -
多代理和后台任务怎么协调
这也是为什么很多人会觉得,Claude Code 不只是“回答更聪明”,而是“整体更稳”。
因为到了这一阶段,
“聪明”已经不只是生成答案那一瞬间的智力,
而是整套系统在几百轮交互之后,还能不能继续像一个可靠工具。
总结
优秀 Agent 的核心竞争力,正在从“模型有多强”,转向“系统有多完整”。
Claude Code 真正强的地方,不只是因为它用了某个模型,而是因为它在做这些事:
-
用多层机制管理上下文 -
用分层架构管理记忆 -
用严格权限系统管理风险 -
用清晰回退逻辑管理模型切换 -
用持续遥测与追踪标识支撑平台治理 -
用大量工程细节,换取“长时间看起来依然聪明而稳定”的体验
所以,真正值得普通人记住的一句话可能不是:
“原来它还有这么多隐藏功能。”
而是:
Agent 的胜负,已经越来越像系统工程的胜负,而不只是提示词工程的胜负。
