 夜雨聆风
夜雨聆风





Redis 8 VectorSet 源码深度拆解:从向量存储到相似检索的全流程解析

你是否在做大模型应用时,被海量向量数据的实时检索速度拖慢了节奏?传统向量数据库与Redis的集成方案总存在性能损耗?Redis 8推出的VectorSet特性,直接将向量检索能力内置到Redis内核中,本文将从源码层面拆解其核心原理与实现流程,帮你彻底搞懂这个性能拉满的向量存储方案。
一、Redis VectorSet:内置向量能力的核心定位
Redis 8作为Redis社区最新的大版本更新,首次将向量存储与相似检索能力原生集成到内核中,替代了以往依赖外部插件(如RedisAI)的方案。VectorSet的出现,让Redis不再只是缓存数据库,而是可以直接支撑大模型时代的向量检索业务,无需额外的向量数据库开销,大幅降低了技术栈复杂度与运维成本。
二、核心流程源码拆解:从插入到检索
Redis VectorSet的核心流程分为向量插入和相似检索两大模块,我们将通过源码片段逐一解析每一步的实现细节。
2.1 向量插入流程:SADD命令的源码实现
当客户端执行VECTOR.SADD key vector命令时,Redis内核会执行完整的向量插入流程,核心步骤如下:
1. 查找或创建对应的VectorSet键
2. 解析传入的向量数据,验证格式与维度合法性
3. 分配内存存储原始向量数据与索引元信息
4. 将向量添加到HNSW索引结构中完成索引构建
5. 返回插入结果给客户端
以下是简化后的Redis内核源码实现:
// Redis 8 VectorSet SADD命令核心处理逻辑
int vectorSetAddCommand(client *c) {
// 1. 获取或创建VectorSet键,确保线程安全
robj *set = lookupKeyWriteOrReply(c, c->argv[1], shared.nullbulk);
if (set == NULL) return C_OK;
// 2. 解析客户端传入的向量参数,验证格式与维度
ssize_t vec_dim;
float *vec_data = parseVectorArg(c->argv[2], &vec_dim);
if (vec_data == NULL) {
addReplyError(c, "ERR invalid vector format, must be float32 array");
return C_ERR;
}
// 3. 分配向量存储节点内存,存储原始向量数据
vector_node *node = zmalloc(sizeof(vector_node) + vec_dim * sizeof(float));
node->dim = vec_dim;
memcpy(node->data, vec_data, vec_dim * sizeof(float));
// 4. 将向量插入到HNSW索引结构中
hnsw_insert(set->ptr, node);
zfree(vec_data);
// 5. 返回插入成功的结果
addReplyLongLong(c, 1);
return C_OK;
}
关键代码解析:
–lookupKeyWriteOrReply负责获取目标键,同时处理键不存在的场景
–parseVectorArg负责将客户端传入的二进制/字符串格式向量转换为内存中的float数组
–hnsw_insert是HNSW索引的核心插入接口,负责构建多层索引结构
2.2 相似检索流程:SEARCH命令的源码实现
当执行VECTOR.SEARCH key topk vector命令时,Redis会执行相似性检索流程,核心逻辑如下:
1. 加载目标VectorSet的HNSW索引实例
2. 解析查询向量与topK检索参数
3. 通过HNSW索引快速检索top-K相似向量
4. 从存储层读取完整的向量数据并计算相似度
5. 对结果排序后封装返回客户端
简化后的源码片段如下:
// Redis 8 VectorSet SEARCH命令核心处理逻辑
int vectorSetSearchCommand(client *c) {
// 1. 获取目标VectorSet键
robj *set = lookupKeyReadOrReply(c, c->argv[1], shared.nullbulk);
if (set == NULL) return C_OK;
// 2. 解析查询向量与topK参数
ssize_t query_dim;
float *query_vec = parseVectorArg(c->argv[3], &query_dim);
int topk = atoi(c->argv[2]);
if (query_vec == NULL || topk <=0) {
addReplyError(c, "ERR invalid query parameters");
return C_ERR;
}
// 3. 执行HNSW相似检索,获取topK结果
vector_result *results = hnsw_search(set->ptr, query_vec, topk);
// 4. 封装结果并返回客户端
addReplyArrayLen(c, results->count);
for (int i=0; i<results->count; i++) {
addReplyDouble(c, results->scores[i]);
addReplyString(c, results->nodes[i]->id, sizeof(results->nodes[i]->id));
}
zfree(results);
zfree(query_vec);
return C_OK;
}
三、HNSW索引在Redis内核中的实现细节
VectorSet采用了层次化导航小世界网络(HNSW)作为核心索引结构,这也是当前向量检索领域性能最优的索引方案之一。在Redis的实现中,HNSW索引被直接集成到Redis的对象系统中,每个VectorSet键对应一个独立的HNSW索引实例,实现了键级别的隔离。
3.1 索引构建的核心优化
Redis的HNSW实现针对内存存储做了多重针对性优化:
– 内存预分配:在插入向量时,提前预留索引节点的内存空间,减少内存碎片产生
– 分层索引裁剪:仅在高层索引保留少量核心节点,降低检索时的遍历开销
– 线程安全设计:复用Redis的单线程事件模型,避免了多线程索引更新的锁竞争问题
四、核心流程UML图解
为了更直观地展示VectorSet的完整交互流程,我们绘制了核心UML流程图:
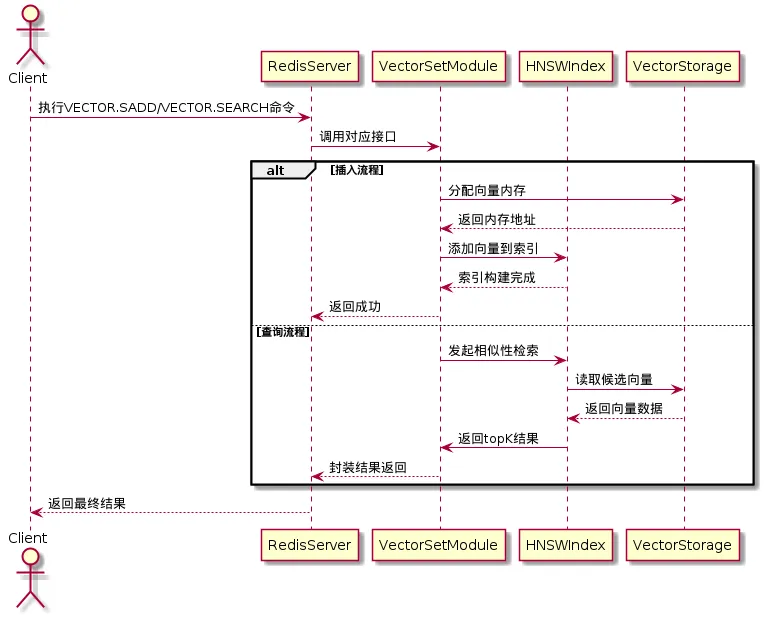
五、性能优势与实战场景
Redis VectorSet相比传统向量数据库的核心优势在于:
1. 零网络开销:向量数据直接存储在Redis内核中,无需通过网络传输,大幅降低延迟
2. 原生集成:可以直接复用Redis的持久化、集群、哨兵等企业级能力
3. 低延迟检索:HNSW索引的O(logN)检索复杂度,配合Redis的内存存储,实现亚毫秒级检索
常见的实战场景包括:
– 大模型应用的实时语义检索
– 推荐系统的用户画像相似性匹配
– 图像检索的特征向量匹配
– 实时风控的异常行为向量检测
结尾
好了,今天的Redis VectorSet源码拆解就到这里啦。不知道你在使用Redis做向量检索的时候有没有遇到过什么坑?或者对这个特性有什么不同的见解?欢迎在评论区留言交流,咱们一起探讨技术细节~