 夜雨聆风
夜雨聆风





Java 技术栈的 AI Agent:源码级深度拆解 AssistantAgent,企业级Agent设计学习
Java 技术栈的 AI Agent:源码级深度拆解 AssistantAgent,企业级Agent设计学习
最近很多 Java 同学在群里问我:“我们用 LangChain 或者 Spring AI 搓了一个 Agent,跑 Demo 的时候狂拽酷炫,但一接到生产线的真实业务(比如自动化运维、财务结算),要么胡言乱语,要么卡死在某一步,完全不敢上线,怎么破?”
这是一个非常典型的工程痛点。在技术圈的喧嚣中,大家容易被华丽的 Demo 迷了眼,却忽略了一个冷酷的现实:在严肃的生产场景下,如果 Agent 不能“准确、稳定”地完成任务,它的商业价值就是负数。 对于企业级应用,所谓的“智能”只是锦上添花,“确定性”才是生死线。
今天,我要带大家通过源码,深度拆解一个真正为生产级别的“确定性”而生的开源项目 —— Spring AI Alibaba AssistantAgent(github:https://github.com/spring-ai-alibaba/AssistantAgent)
我们将剥开它华丽的外衣,直击底层源码。我会结合大家在开发 Agent 时常遇到的痛点(比如:工具不够用怎么办?复杂意图识别不准怎么办?),告诉你一套高级的工程化解法;最后,也会给大家指出一条 Java 开发者学习和落地该开源项目的最佳路径。
一、 架构师视角:为什么你需要一套复杂的系统架构?
很多同学写 Agent 就是一个大 Prompt 走天下。但在企业级开发中,单一的大模型只是一个“CPU”,它需要周边配套的调度、内存、安全机制才能成为一台计算机。
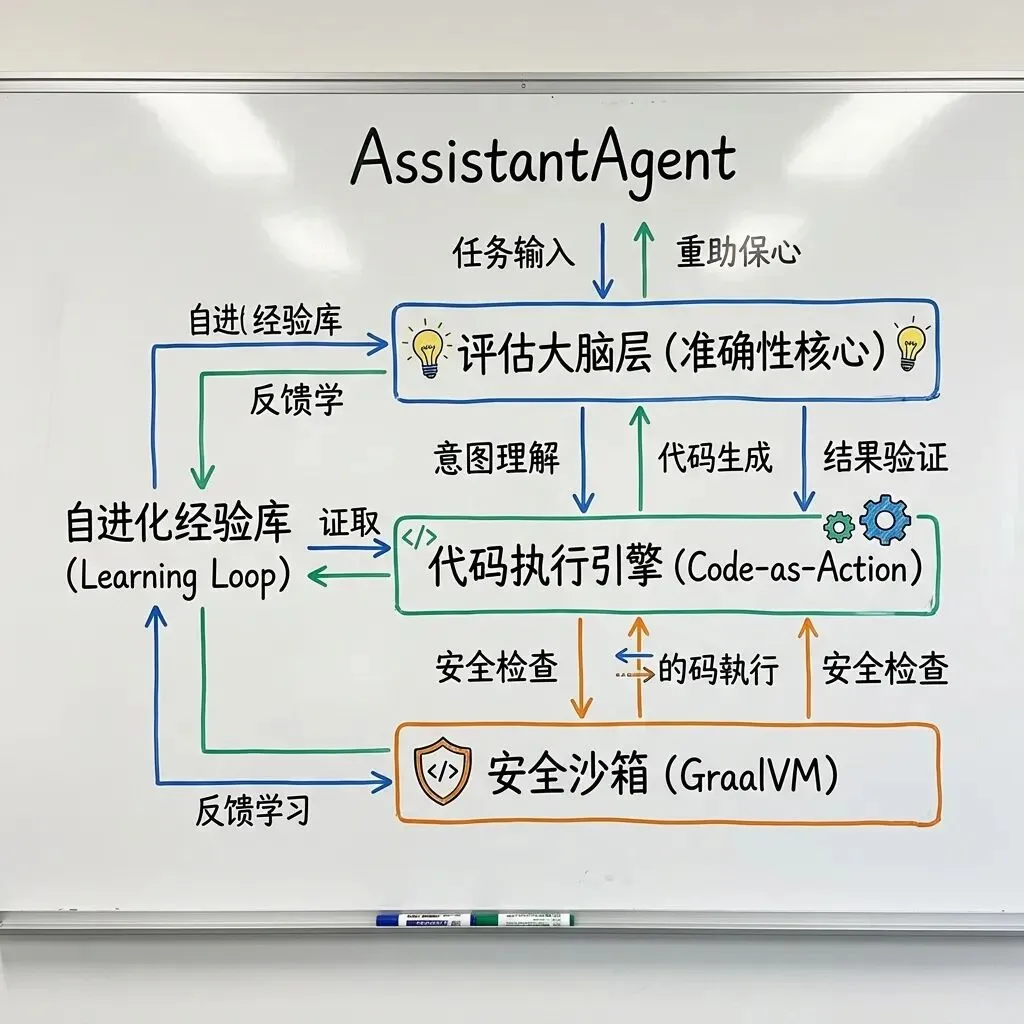
AssistantAgent 在架构上采用了**“逻辑解耦,资产闭环”**的思想。我们先来看它的全景架构:
大家注意看上面的模块划分。执行模块(负责干活)和评估模块(负责监工)是完全剥离的。这种架构从根本上解决了单一 LLM “既当裁判又当运动员”的幻觉问题。接下来,我们逐一击破它的核心源码思想。
二、 痛点直击:工具不够用怎么办?深入 Code-as-Action
行业痛点: 传统的 Tool-calling(工具调用)Agent 极度依赖开发者预设的 API。由于大模型的理解偏差,经常在多步工具调用中产生“意图坍缩”。更要命的是:如果系统中刚好缺少了一个数据处理的 API,Agent 就会当场罢工。工具不够用,怎么办?
架构师解法:Code-as-Action(代码即行动)
AssistantAgent 抛弃了基于零碎工具编排的传统思路,它要求大模型不再直接返回行动结果,而是生成一段完整的 Python 代码。
大家去看 CodeactAgentBuilder#build() 的源码,里面强制注入了 WriteCodeTool 这个黑魔法:
// 源码解析:强制注入 WriteCodeTool
allTools.add(WriteCodeTool.createWriteCodeToolCallback(this.codeContext, this.environmentManager));一旦有了生成 Python 代码的能力,工具不够用的问题迎刃而解。
举个例子:你需要逆向处理一个复杂的财务数据表,系统里没有现成的工具。在传统框架里 Agent 此刻就死了;而在 AssistantAgent 里,模型会利用其强大的代码生成能力,写一段携带 pandas 或者标准字典遍历逻辑的 Python 脚本,直接在内部动态完成数据清洗,然后再把结果交出来。
执行时序大揭秘:
Python 的图灵完备性,弥补了原子工具的匮乏。这也是为什么它能在复杂场景中保持逻辑保真的根本原因。
三、 痛点直击:意图拆分不准怎么办?透视多维评估图 (MDE)
行业痛点: 用户输入:“帮我把上个月超时未付款的订单作废并给客户发提醒邮件。” 这种复杂意图,传统 Agent 经常漏掉发邮件,或者错误作废了当月订单。意图到底怎么拆分、怎么验证才准确?
架构师解法:评估不再是一根管子,而是一张 DAG 图 (有向无环图)。
不要指望 LLM 一口吃成个胖子。在 AssistantAgent 中,引入了 assistant-agent-evaluation 模块,它的核心是 GraphBasedEvaluationExecutor。
我们来看 EvaluationCriterion 的源码定义:
// 源码解析:构建评估准则的 DAG 依赖
publicclassEvaluationCriterion {
// 依赖前置节点完成,例如:先判断“安全合规”,再判断“意图完整度”
private List<String> dependsOn = newArrayList<>();
private String workingMechanism; // 告知评估模型如何判定
private List<FewShotExample> fewShots; // 少样本注入,对齐标准
}各位同学,这个 dependsOn 就是精髓。它将一个大意图的评估,拆成了相互依赖的流水线图。
-
1. 安全校验节点:先查有没有敏感操作(删库)。 -
2. 意图拆解节点:识别出“作废订单”和“发邮件”两个子任务。 -
3. 参数完整性节点:检查有没有提供邮件模板?如果没有,打回。
关键在于反哺机制:如果某个评估节点给出极低分,这个错误报告会作为 CriterionResult 重新注入到我们下一次请求的 Prompt 中,强制大模型主动跟用户说:“您好,请提供一下发给客户的邮件话术模版。” —— 这就是企业级 Agent 的底线防守。
四、 安全底线:不要相信 LLM,透视 GraalVM 物理沙箱
作为架构师,我们在做威胁建模(Threat Modeling)时有一条铁律:必须假设 AI 生成的代码包含毒药。 如果它生成了 os.system("rm -rf /") 怎么办?
AssistantAgent 并没有使用沉重的 Docker 容器,而是利用 Java 态的高级特性 —— GraalVM Polyglot API,在 JVM 进程内拉起了一个极其轻量、毫秒级启动的沙箱。
我们直击 GraalCodeExecutor.java 中最硬核的安全收口逻辑:
// 源码解析:基于 GraalVM 的物理级防御
try (Contextcontext= Context.newBuilder("python")
// 1. HostAccess.ALL:只允许 Python 访问被我显式注入的 Java 对象
.allowHostAccess(HostAccess.ALL)
// 2. IO 锁定:强行阻断所有文件读写,防数据泄露
.allowIO(false)
// 3. Native 锁定:防止底层 C 语言层面的指针/溢出攻击
.allowNativeAccess(false)
.build()) {
// 4. “送饭入牢房”:只把经过封装的工具桥接对象送进沙箱
context.getBindings("python").putMember("agent_tools", toolBridge);
// 执行 LLM 生成的代码...
}技术感悟:很多新手写 Python 环境就是个 ProcessBuilder 调用。而真正的生产级框架,一定是从物理层面切断 IO 和 Native 调用。这种安全意识,是每一位进阶 Javaer 必备的素质。
五、 Token 经济学:抗击上下文溢出的“渐进式披露”
企业落地的另一个坎:当我们构建了一个拥有上千条 SOP(标准作业程序)的经验库时,怎么把它们喂给 LLM?全塞进 Prompt 就会导致 Token 溢出,模型智商断崖式下跌。
AssistantAgent 引入了计算机系统中经典的 “CPU 多级缓存” 思想,首创了 渐进式披露 (Progressive Disclosure)。
翻开 ExperienceDisclosurePromptContributor.java,你会看到严苛的限制常量:
// 每个分类最多只透露 3 个候选卡片
privatestaticfinalintMAX_CARDS_PER_SECTION=3;
// 每张卡片的描述摘要强行截断至 100 字符内
privatestaticfinalintMAX_DESCRIPTION_LENGTH=100; 它的运行机制如下:
-
1. L1 Cache(索引注入):在系统 Prompt 中,我只给你看“经验卡片”的 ID 和一小段摘要。 -
2. L2 Cache(按需加载):大模型读了摘要觉得可能有戏,它会通过主动调用系统提供的 read_exp工具,传入经验 ID,把这篇长达千字的 SOP 全文拉到当前上下文中细读。
这就好比让模型先看目录,感兴趣再翻正文。既保住了长远的记忆,又将每次请求的系统开销压到了最低。
六、 效能飞跃:熟悉路线闭着眼走的 FastPath 机制
Agent 每次回答都要经过 LLM 的漫长推理吗?当然不。
在处理固定场景(比如每天早上的“巡检服务器指标”)时,每次重新生成 Python 代码纯属浪费算力和增加出错概率。
系统中的 FastIntentService 充当了“大模型的短路开关”。
当用户的请求命中缓存的经验意图时,系统直接从资产库提取经过历史验证的 Python 代码并执行。一气呵成,避开大模型的推理,将首字延迟从数秒级压缩到了毫秒级,同时保证 100% 的准确性。 —— 这种将大模型能力“缓存化”、“白盒化”的思想,是提升系统吞吐量的绝招。
七、 实践课:Javaer 如何在这个优秀项目中学习与落地?
既然拆解了源码,作为 Java 开发者,我们该如何把它用到我们自己的业务线,或者从中吸取养分呢?老哥给你们铺三步路:
Step 1: 从测试用例(TestCases)入手读源码
对于复杂的开源框架,最佳的源码入口永远是它的 src/test/java。去运行 CodeactAgentTest,亲自 debug 看一次从 UserMessage -> 评估准则拦截 -> LLM 生成 Python -> GraalVM 执行返回 的完整栈。体会 ToolContext 是如何在上下游链条中传递状态的。
Step 2: 掌握和扩展 SPI (服务发现接口)
Spring 生态的精髓在于扩展。AssistantAgent 留出了极佳的 SPI 接口。
如果在你们公司想用自己的向量数据库做经验存储,你完全不需要改它的源码。你只需要写一个类实现 ExperienceProvider 接口,然后通过 Spring Boot的自动装配将其注入:
@Bean
public ExperienceProvider myCompanyVectorProvider(MyCompanyDbClient client) {
returnnewCustomExperienceProvider(client);
}自己动手实现一套本地化的经验提供者,你会对它的生命周期有更深的理解。
Step 3: 开始“业务资产化”的思维重构
玩 Agent 不要老想着把它做成“问答机器人”。你应该利用 SkillExchangeService,让业务人员不断把处理疑难杂症的沟通记录“提纯”为 SkillPackage(技能包)。
慢慢的,你会发现你构建的不再是一个聊天窗口,而是一个沉淀了全公司顶级销冠、顶级运维老兵经验的企业数字大脑资产库。
架构师的最后嘱咐
Spring AI Alibaba AssistantAgent 为我们展现了真正的企业级工程功底:它用代码约束逻辑,用评估图指引方向,用沙箱保障底线,用缓存压低成本。
不要惧怕 AI 会取代程序员。在这个由大模型带来的新时代里,那些懂业务、懂底层架构、知道如何用工程手段去约束大模型不确定性的**“确定性工程师”(Agent Architect)**,反而会成为各大公司最稀缺的香饽饽。
去拉下源码,祝各位在 AI 浪潮里乘风破浪!