 夜雨聆风
夜雨聆风





Claude Code源码里,AI决策逻辑只占1.6%,另外98.4%是什么
98.4%的代码是基础设施,真正的AI决策逻辑只占1.6%。
这个数字来自一篇4月14日刚挂上arXiv的论文——《Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems》。
作者来自MBZUAI,阿联酋的一所AI专业研究大学。很多中文读者可能没听说过这个名字,但在AI学术圈它有点分量——按CSRankings的AI专项排名,全球前10,从Berkeley和CMU挖了一批教授过去。这不是一篇随便写写的博客,是认真做了源码分析的学术论文。
他们做的事情很直接:拿到Claude Code v2.1.88的npm包,解压出将近50万行TypeScript源码,从架构层面逐一拆解。Anthropic从不发布Claude Code的内部架构说明,但这次的源代码泄露,有人真的去认真研究了。
一、 先说这篇论文在讲什么
不是”Claude Code能帮你解决哪些编程问题”。
论文问的是:一个真实上线的AI Agent系统,骨架是什么?为什么要这么搭?
Agent,在AI语境下指的是能够自主执行任务的AI系统——不只是回答问题,而是能主动操作文件、运行命令、调用外部服务来完成目标。Claude Code就是这样一个系统,你告诉它”帮我修复这个bug”,它会自己去读代码、运行测试、修改文件,直到搞定为止。
研究团队识别出Claude Code背后的5个设计价值观,然后追踪这5个价值观怎么变成13个设计原则,最终怎么落地到具体代码。
先说结论:Claude Code是一个用大量确定性基础设施包裹着一个极简AI决策循环的系统。 不是你想象中那种”AI无处不在”的架构,更像是给AI模型建了一个配套完善的工作台——模型只负责想,工作台负责做。
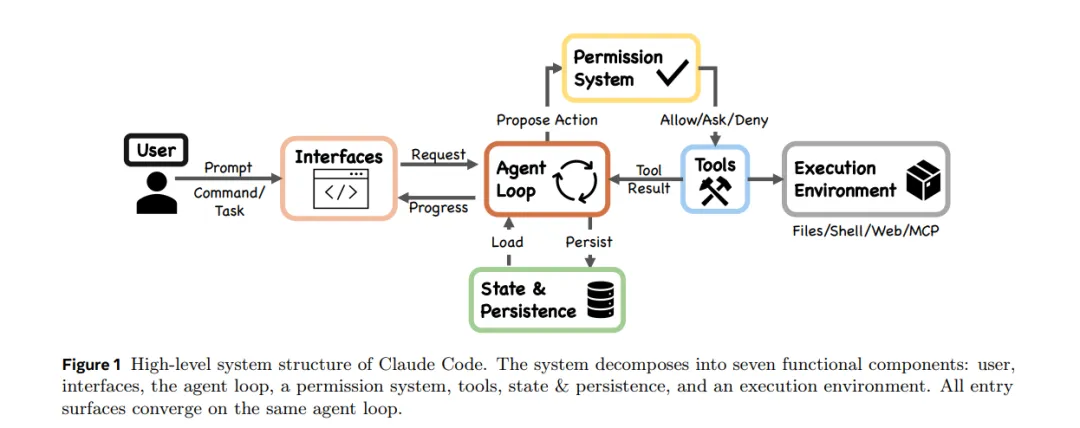
二、 核心发现一:核心Loop简单到让你意外
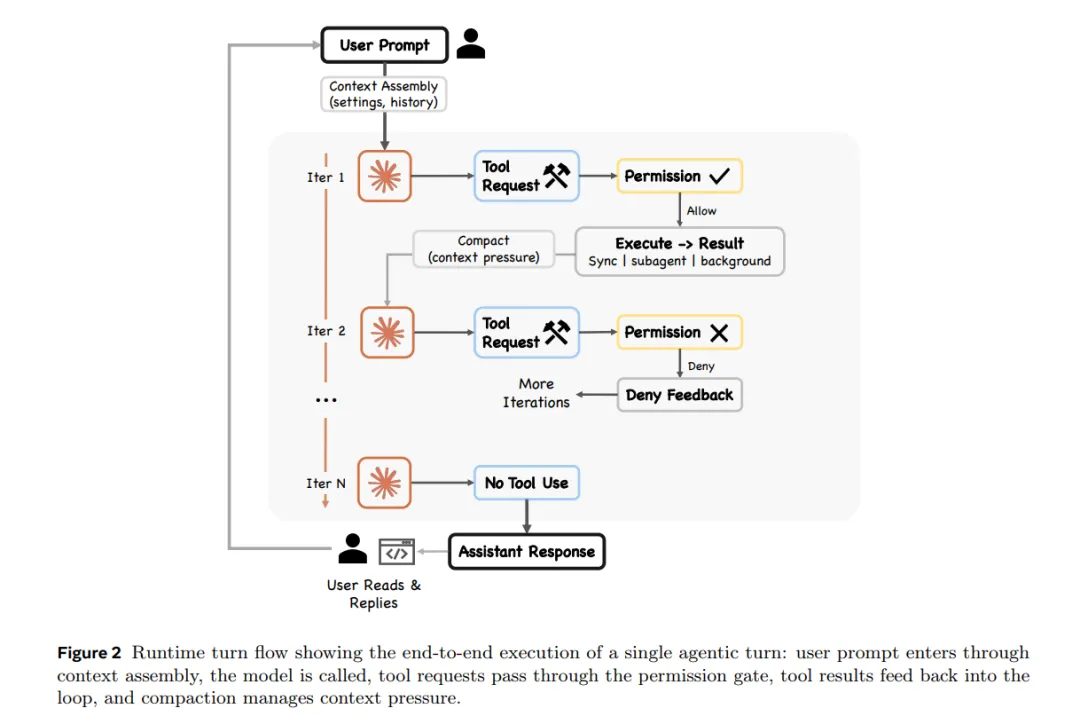
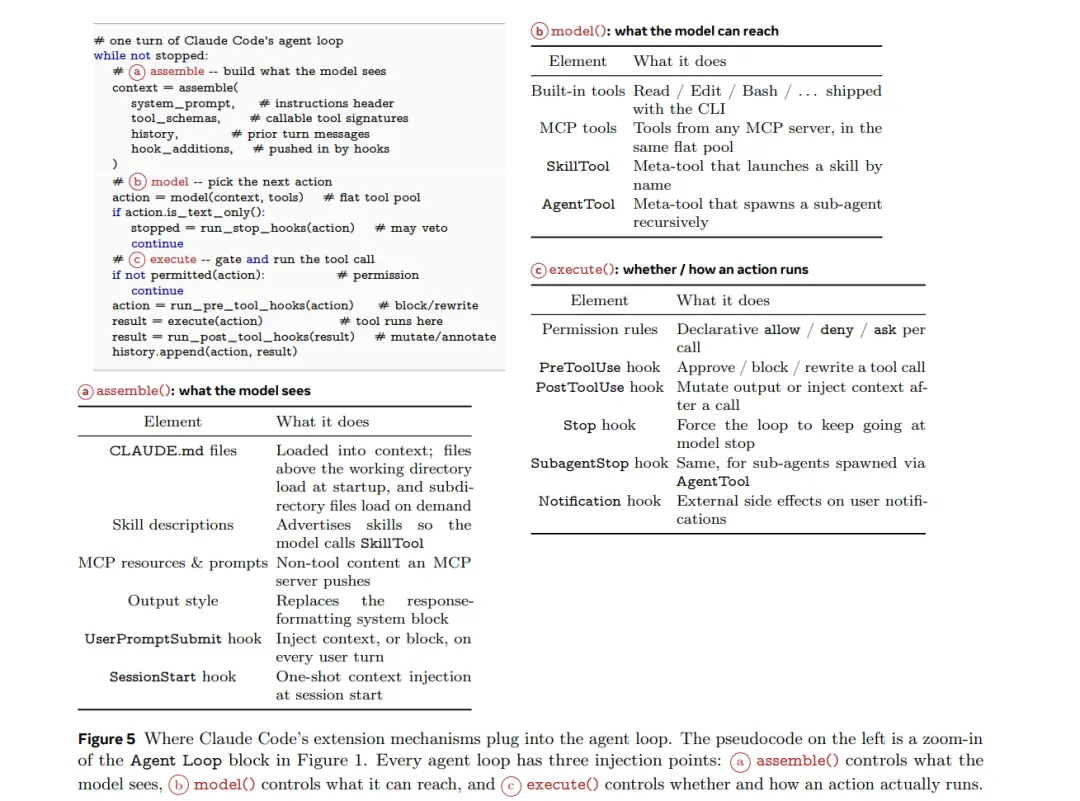
Claude Code的心脏是一个while-true循环,逻辑大概是这样: 组装上下文 → 调用模型 → 模型说要用什么工具 → 检查能不能用 → 执行 → 把结果塞回去 → 继续下一轮
while not stopped: context = assemble(...) # 组装模型能看到的内容 action = model(context, tools) # 模型决策if not permitted(action): continue# 权限检查 result = execute(action) # 执行工具 history.append(action, result)这个循环在源码里叫queryLoop(),在query.ts文件里。就一个函数。
模型在整个系统里的角色,是根据上下文来决定下一步用哪个工具,仅此而已。它不直接碰文件系统,不直接跑命令,不直接发网络请求。所有实际的执行,都由harness(工具框架)来做。
这个分离有一个很重要的安全含义:即使模型被攻击者注入了恶意指令,它也无法绕过权限检查直接执行危险操作,因为模型根本没有那条通道。
整个决策逻辑加起来大概是代码库的1.6%,剩下的98.4%都是”基础设施”——权限系统、上下文压缩、工具路由、会话存储、错误恢复……
这是一个主动选择,不是偷懒。论文的判断是:给一个越来越强的模型配上越来越好的工作台,比用各种规则框死它的每一步决策,更有价值。
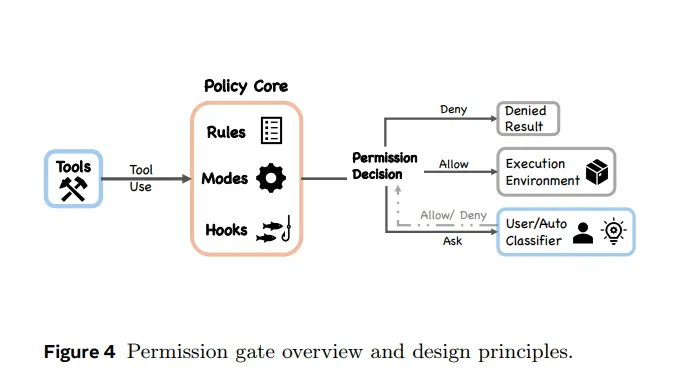
三、 核心发现二:权限系统比你想象的复杂
很多人用Claude Code,感受就是”它要执行某个命令,会弹出来问你同意不同意”。这只是7层权限机制里最表面的一层。
想象成机场安检,不是一道门,是一套层层叠加的系统:
-
第1层(最早):工具列表过滤。 在AI收到可用工具的列表之前,被禁用的工具就已经从列表里删掉了。AI根本不知道那些工具存在,自然不会去调用。 -
第2层:禁止优先规则。 “禁止”的规则永远压倒”允许”的规则,哪怕”允许”的规则写得更具体。你不能用”允许运行npm test这个命令”来绕开”禁止所有命令行操作”的规定。 -
第3层:7种权限模式。 从”每一步都要人工审批”到”几乎不问”,用户可以根据场景选择信任程度。做敏感操作用严格模式,做探索性工作用宽松模式。 -
第4层:AI安全分类器(可选)。 系统内置了另一个专门的AI模型,职责是判断某个操作是否安全。这是Claude Code的auto模式——不是靠人审批,而是靠AI审AI。 -
第5层:沙箱隔离。 就算操作通过了前面所有检查,执行时可能还是在一个隔离环境里运行,访问你电脑文件和网络的权限都受限。就像在一个玻璃箱里工作,能看到外面但碰不到。 -
第6层:Resume不恢复权限。 你中断了一个session(即一次完整的工作对话,从打开Claude Code开始到关闭为止),下次重新接续时,之前批准过的所有权限全部清零,需要重新确认。 -
第7层:开发者自定义拦截。 企业或开发者可以在任何工具执行前后插入自己的检查逻辑,进行拦截、修改或记录。
为什么要搞这么复杂?论文引了一个让人有点坐不住的数据:Anthropic的内部研究发现,用户会批准93%的权限弹窗。
也就是说,几乎所有人都不认真看弹窗,看了也直接点同意。
如果安全只靠人工审批这一道门,那其实几乎没有安全。所以系统必须在假设人不看的前提下,自己守住边界。这就是为什么有7层,任何一层都可以独立拦截。
四、 核心发现三:上下文管理才是真正的主工程
很多人以为上下文管理是个优化项——等模型的context window越来越大,这个问题自然就消失了。
论文的判断不同:context window是整个系统的主约束,是成本、稳定性和任务质量的交叉点。 带着错的信息进入工作循环,后面会越跑越偏。
Claude Code为此设计了5层压缩pipeline,在每次调用模型之前按顺序跑一遍:
-
第1层 Budget Reduction(一直在跑): 每个工具的输出都有大小上限。比如你让Claude Code读一个很大的日志文件,返回的内容超过限制,就会被截短,用一个引用替代。这一层永远在运行。 -
第2层 Snip(轻量裁剪): 把最老的对话历史删掉。就像把聊天记录往前翻太多页时,自动删掉最早的几条,保留最近的。 -
第3层 Microcompact(细粒度压缩): 比Snip更聪明,会考虑prompt cache的命中情况来决定怎么压缩,目的是压缩的同时不破坏缓存效率。 -
第4层 Context Collapse(虚拟视图): 这层有点特别——它不删除历史记录,而是给模型看一个”折叠版本”,完整的历史还在磁盘上,但模型看到的是摘要。相当于把一本书折叠成目录,原书还在。 -
第5层 Auto-compact(最后手段): 前面4层都不够用了,才会启动这一层。系统会调用模型本身,让它把整个对话历史生成一个语义摘要,然后用摘要替代原始历史继续工作。
这5层是有顺序的,便宜的先跑,贵的后跑。论文把这叫做”懒惰降级”——能用轻量手段解决的,不动用重型压缩。
这对使用Claude Code做开发的人有一个实际含义: 如果你发现做着做着,Claude Code开始犯一些莫名其妙的低级错误,或者”忘记”了你之前说过的约定,很可能是某层压缩在悄悄工作,模型能看到的上下文已经和你以为的不一样了。
主动给Claude Code写好CLAUDE.md文件,把项目的关键约定固化进去,比依赖它”记住”对话历史要可靠得多。CLAUDE.md是系统层面加载的,压缩pipeline不会轻易碰它。
五、 核心发现四:扩展机制有成本等级之分
Claude Code的扩展体系用了4种不同机制:MCP服务器、Plugins、Skills、Hooks。
MCP(Model Context Protocol)是一套开放协议,让AI工具可以连接外部服务——只要服务方遵循这个标准,Claude Code就能调用它,比如连接你公司的数据库、内部系统、各种第三方API。
很多人会问:为什么不统一成一个API,要搞这么多种?
论文的解释很清晰:这4种机制消耗的context成本差异很大,如果统一成一种,就等于逼所有扩展都用最贵的那种。
用一个简单的方式来理解:
-
Hooks:不消耗任何context,就是在工具执行前后挂个钩子,做一些拦截或日志记录。适合做监控、审计。 -
Skills:消耗很少的context,把一套操作指令打包成一个技能,调用时才展开。我自己做的cailitan-ai-writer就是这种。 -
MCP服务器:消耗最多context,但能给模型提供全新的工具,比如连接数据库、调用外部API。 -
Plugins:本身不是一种新的运行机制,而是打包分发用的格式——可以把上面三种(Hooks、Skills、MCP服务器)捆在一起,做成一个完整的安装包分享给别人用。
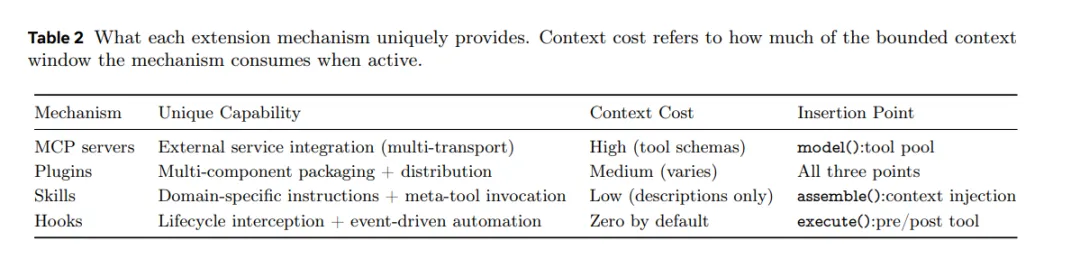
这个成本阶梯是有意设计的。便宜的扩展可以大量使用而不影响模型质量,贵的留给真正需要新能力的场景。
我在实际使用中的体会:Skills在同等功能下,通常比MCP工具更稳定,输出质量也更一致。现在理解了——走的路径更轻,context污染少,模型能更专注地处理任务。
六、 核心发现五:Subagent是独立的context域
当Claude Code判断一个任务需要分工时,它会派出subagent来协作。
这里有一个重要的设计:每个subagent都在自己独立的context window里工作,完成后只把摘要文本返回给主任务,不把完整对话历史返回。
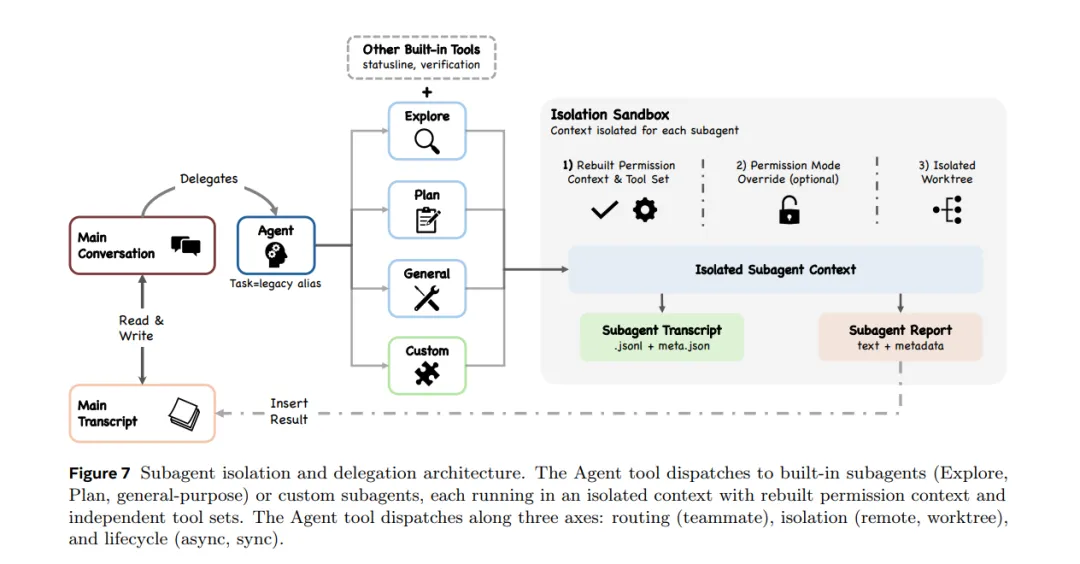
为什么这么设计?因为有个硬数字:在plan模式下,agent teams消耗的token大约是单个session的7倍。如果每个subagent都把完整对话返回给主任务,token消耗会爆炸。只返回摘要,是让系统能正常运转的前提。
隔离模式有三种:
-
默认:共享文件系统,但context独立,互相看不到对方的对话 -
Worktree隔离:在git worktree的临时分支上工作,改了也不影响主工作区 -
Remote隔离(内部用户专属):在远程环境运行
还有一个细节对使用者有影响:Resume或Fork一个session(即接续或分叉一次工作对话)时,之前授权的操作权限不会被继承,必须重新确认。 这是故意的安全设计——不把旧项目的信任状态带到新的工作场景里。有点麻烦,但这个麻烦换来的是你不会无意间在一个新项目里继承了一些本来不该有的权限。
七、 系统能力越强,人的理解越浅?
这是论文最后提出的一个问题。前面讲的那些——权限系统、记忆管理、分身协作——都是在回答”Claude Code怎么运作”。这个问题问的是另一件事:Claude Code在放大人的短期能力,但它有没有在帮人建立长期能力?
论文专门用一个视角(原文称之为”evaluative lens”,即用这把尺子来衡量整个架构)来审视这个问题。
数据是存在的。Anthropic自己的研究记录了一个”监督悖论”——对AI过度依赖,会削弱你监督AI所需要的技能。独立研究发现,在AI辅助条件下工作的开发者,代码理解测试得分低17%。对Cursor(另一款AI编程工具)使用的因果分析,覆盖807个代码库:代码复杂度提升40.7%,速度在第一个月有明显提升,但到第三个月就回归基准了——也就是说,速度的提升是暂时的,代码复杂度的上升是持久的。还有一项脑电波研究,54名参与者,发现使用AI辅助写作的人,停止使用AI工具之后,大脑神经连接强度仍然持续减弱。
这些研究针对的不是Claude Code,但Claude Code面对同样的结构性约束:bounded context(即模型的记忆窗口有上限)意味着模型永远不能同时看到整个代码库;subagent隔离意味着并行工作的agent会独立重新实现对方已经做过的东西。好的本地决策,在缺乏全局视野的情况下,可能累积成糟糕的全局结果。
论文在这里没有给出解法。它的结论是:这是一个可以直接测量的实证问题,但源码层面的分析无法回答它。它只是把这个张力命名了出来:Claude Code在短期内确实放大了人的能力,但它的架构里几乎没有专门针对”帮人保持长期理解”而设计的机制。 这不是批评,是一个开放的问题。论文最后说,未来的系统应该把这个可持续性问题当作一等公民来设计,而不是等到后面再评估。
我的判断是:这个问题没有纯技术解法,必须在工作方式层面解决。工具在变强,但用工具的人需要主动保持理解代码的习惯,不然工具越强,对工具的依赖越深,理解越浅。
八、 这对做开发的人,实际意味着什么
读完这篇论文,我整理了三个对日常使用Claude Code有帮助的结论:
-
第一,好好写CLAUDE.md。 Context压缩是真实发生的,而且你不会知道它什么时候启动、删掉了什么。把项目的关键约定、命名规范、代码风格、禁止事项,都固化进CLAUDE.md,这比依赖对话历史可靠得多。CLAUDE.md是系统层面加载的,压缩pipeline不会轻易碰它。 -
第二,理解权限模式再用auto模式。 很多人直接开auto模式图省事,但如果你不清楚auto模式下ML分类器的判断标准,你实际上是在用一个你不理解的规则在跑任务。至少先在default模式下跑几次,看看它会要求审批哪些操作,再决定要不要全部放行。 -
第三,如果任务质量突然下降,先检查context,不是模型。 尤其是长任务,如果Claude Code突然”忘记”了约定,或者开始做一些之前说好不做的事,大概率是context管理在工作,模型看到的信息已经和你以为的不一样了。可以用/compact手动触发压缩,或者把关键信息重新说一遍,锚定当前状态。
对于在做自己的Agent产品的人,还有一条:harness的质量比planning的复杂度更重要。 当模型能力在趋同,能拉开差距的是基础设施——context管理、权限设计、错误恢复。Claude Code用了98.4%的代码做这件事,不是过度设计,是经验之谈。
九、 结语
最后说一遍这篇论文的局限性:这不是Anthropic写的官方文档,是独立研究团队对公开代码的分析。用来理解设计思路很有价值,但具体细节不能当定论,Anthropic内部的实际实现可能有差异。
但这不影响它最核心的判断成立:Agent架构说到底是在设计一套运行秩序。AI模型是发动机,但能不能上路,靠的是刹车、方向盘、仪表盘和路权规则。
这套运行秩序,值得认真对待。
参考来源
-
Jiacheng Liu et al. “Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems.” arXiv:2604.14228v1, April 14, 2026. https://github.com/VILA-Lab/Dive-into-Claude-Code -
Huang et al. “How AI is Transforming Work at Anthropic.” Anthropic Research Blog, 2025. -
Hughes, John. “Claude Code Auto Mode: A Safer Way to Skip Permissions.” Anthropic Engineering, 2026. -
He et al. “Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity.” arXiv:2511.04427, 2025. -
Kosmyna et al. “Your Brain on ChatGPT.” arXiv:2506.08872, 2025.