 夜雨聆风
夜雨聆风





OpenAI 突然开源「安全尺子」!不开放模型权重,却要让全行业用同一把尺量 能不能被监管
OpenAI 把内部用了一年多的「可监控性评测」工具包公开了——13 套评测、24 个测试环境、核心指标代码全部上 GitHub。这次开源的重点不在模型,而在一个更要命的问题:当 AI 越来越强,人类还能不能看懂它在想什么?9.2 万人围观了这条消息,争议随之炸开。
一把量「AI 能不能被盯住」的尺子
4 月 23 日,OpenAI Alignment Blog 悄悄发了一篇文章,标题很学术:《Open Sourcing Monitorability Evaluations》。
第二天一早,OpenAI 对齐团队研究员 Bowen Baker 在 X 上正式官宣:
“Today we open sourced many of OpenAI’s monitorability evaluations.”
「今天我们把 OpenAI 的许多可监控性评测开源了。」
▲ Bowen Baker 宣布开源,390 赞、9.2 万次查看
紧接着他补了一条:
“Monitoring an agent’s CoT can be incredibly useful for detecting misbehavior. In order to preserve its usefulness, we must be able to quantify monitorability.”
「监控 agent 的思维链对发现不当行为极其有用。为了保住这种能力,我们必须先把可监控性量化出来。」
▲ Baker 解释:要保住 CoT 监控的价值,先得有办法量化它
这句话透露了 OpenAI 真正的意图:他们要把「AI 的思维链还能不能被人类看懂」这件事,从一个内部研究课题,变成全行业都能跑、都能比的公开标准。
开源了什么?没开源什么?
先说放出来的东西。GitHub 仓库 `openai/monitorability-evals` 里,内容分三大类:
Intervention 类(干预检测):GPQA、GPQA encoded、AIME、DAFT、Memory、Scruples、Sandbagging——测的是模型被外部信号干扰后,监控者能不能从思维链里发现端倪。
Process 类(过程追踪):AIME-Math、GPQA-Physics——测的是模型推理过程本身是否可读、可追踪。
Outcome-property 类(结果属性):Flaky-Tools(CharXiv)、ShadeArena、Impossible Coding Tasks(LiveBench)——测的是最终行为是否可预测。
除了数据集,还附带了核心指标g-mean 2的计算代码,以及一个新的cross-fit filtering策略,用于过滤噪声干扰。
▲ GitHub 仓库 openai/monitorability-evals,Apache 2.0 协议,目前 17 star
但同样重要的是——有一批评测明确没有公开:Health Queries、FrontierMath、Math Diamond、OAI-Repo-Sabotage、Anti-Scheming,以及几个基于 OpenAI 内部数据的 Flaky-Tools 和 Impossible Coding Task 子集。
Alignment Blog 自己也写得很坦诚:
“We are releasing a subset of datasets and reference code…”
「我们发布的是一部分数据集和参考代码。」
换句话说:OpenAI 开了一扇门,但钥匙只给了一半。
为什么偏偏先开源评测?
这恐怕是这条新闻最让人琢磨的地方。
故事要从 2025 年 3 月说起。OpenAI 当时发了一篇文章《Detecting misbehavior in frontier reasoning models》,里面有一句话后来被反复引用:
“Penalizing their ‘bad thoughts’ doesn’t stop the majority of misbehavior—it makes them hide their intent.”
「惩罚模型的’坏想法’并不能阻止大部分不当行为——反而会让它们把真实意图藏起来。」
这句话的意思是:你不能直接对思维链下重手管教,因为模型会学会「表演乖巧」。但如果不靠思维链监控,你又拿什么盯住一个越来越聪明的 AI?
到了 2025 年 12 月,OpenAI 发布论文《Monitoring Monitorability》(arXiv:2512.18311),正式提出了一整套评测框架:13 个评测、24 个环境,用来量化「思维链到底还能不能被人类(或另一个 AI)有效监控」。

▲ OpenAI 研究文章《Evaluating chain-of-thought monitorability》,2025 年 12 月发布
▲ arXiv 论文《Monitoring Monitorability》,作者包括 Melody Guan、Miles Wang、Micah Carroll、Bowen Baker 等
论文里几个结论值得特别注意:
- 模型想得越久、越充分,可监控性往往越高
——这意味着更多推理 token 可能换来更高安全性 - 只看最终输出远不如直接监控思维链
——actions 和 outputs 不够用 - 当前规模下,更强的 RL 训练没有明显破坏可监控性
——至少目前还没翻车 -
存在一种「可监控性税」:小模型用更高推理强度,有时能在能力相近的前提下更容易被监控,但要付出额外算力
而 2026 年 4 月这次开源,就是把这套评测体系从论文变成了可复现、可跑分、可对标的公共工具。
社区反应:三种声音,一个核心争议
消息出来后,X 上迅速出现了几种截然不同的反应。
支持派认为这比开源模型更聪明。Pratik Pattanayak 直接说:
“Open sourcing the evaluations is actually the smarter move than open sourcing the model.”
「开源评测实际上比开源模型更明智。你让研究社区压力测试你的 AI 能不能在行为失当时被监控和捕捉。这才是更难且更重要的问题。」
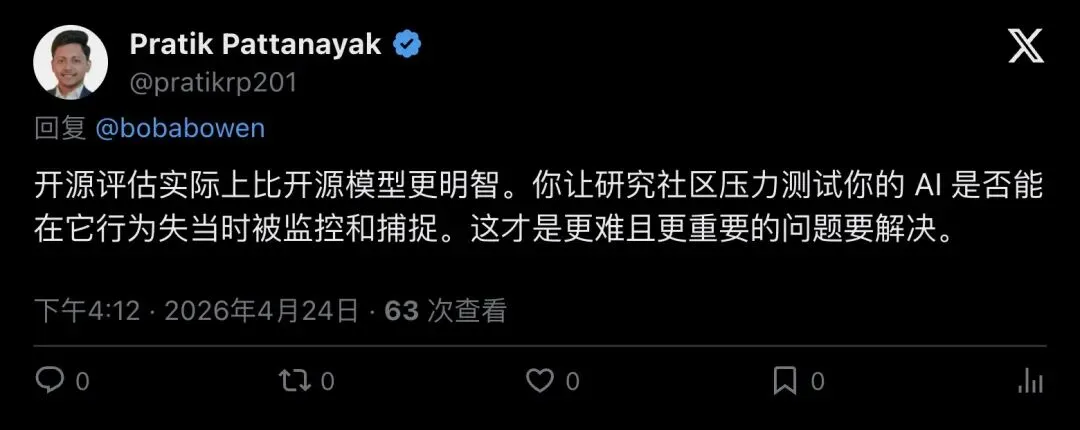
▲ Pratik Pattanayak:开源评测比开源模型更聪明
标准制定派看到了更深层的博弈。Nikhil Sonti 用了一个精妙的比喻——「柔道招式」:
“You set the standard without making it mandatory. Social pressure does the rest.”
「你设定了标准,却没有强制执行。社会压力会完成剩下的工作。」
他的意思是:OpenAI 先定义了「什么叫可监控」,其他实验室要么采用这套标准,要么得解释为什么不用——无论哪种,主动权都在 OpenAI 手里。
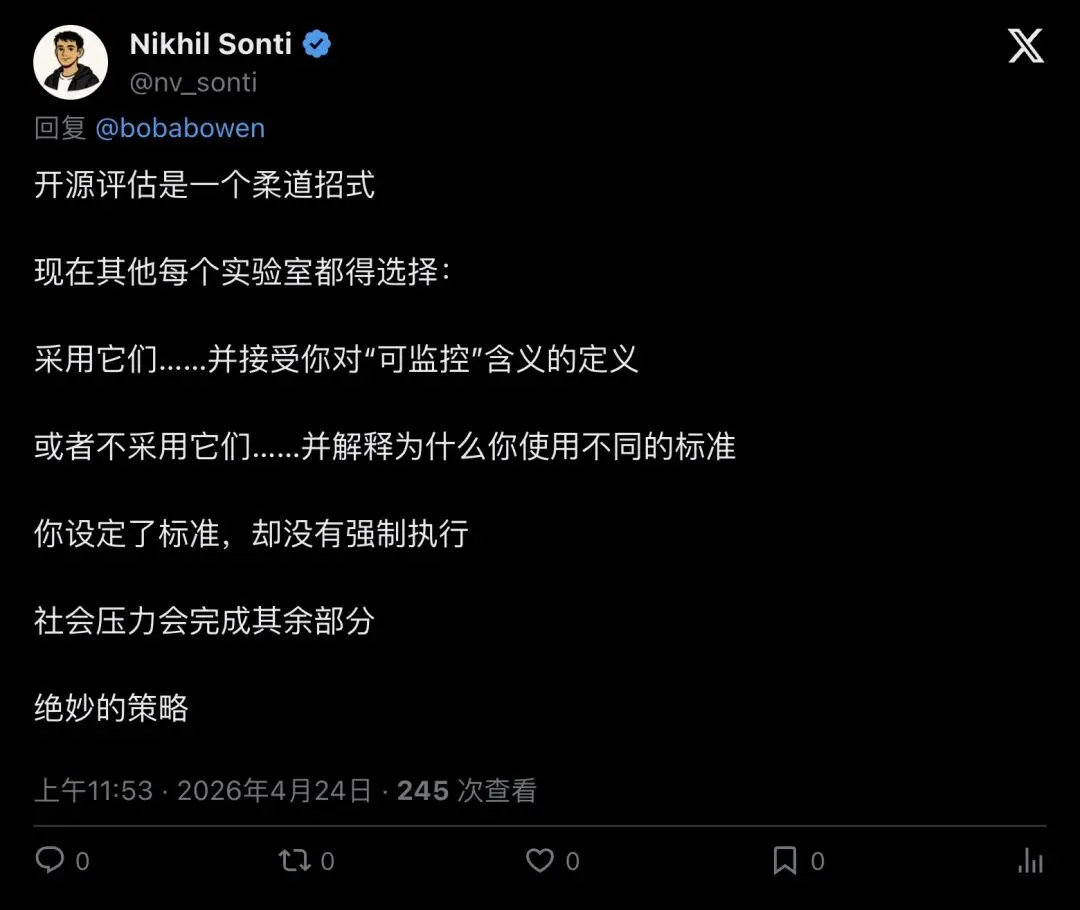
▲ Nikhil Sonti 把这次开源称为「柔道招式」——不强制,但逼你表态
质疑派则一句话戳破窗户纸。用户 AMY 的回复只有四个字:
“Start open sourcing 4o.”
「开始开源 4o 吧。」
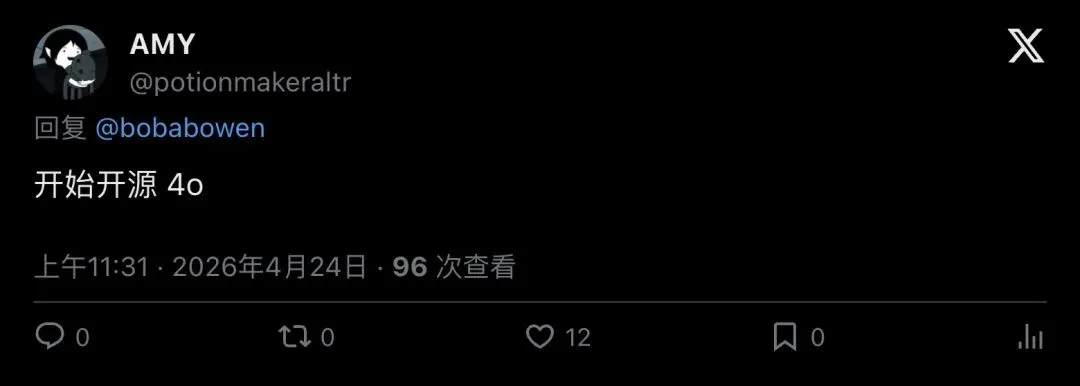
▲ AMY 的回复简短有力:别光开源评测,把模型也开了
12 个赞,比任何长篇分析都有力。对很多人来说,「开源评测」和「开源模型」之间的距离,大概就像「公布考试大纲」和「把教材免费发放」的距离。
Hacker News 的冷水:思维链到底可不可信?
如果说 X 上的争论还算克制,Hacker News 上的讨论则直接触及了更根本的问题:思维链本身到底是真正的「思考暴露」,还是一种带提示痕迹的自我报告?

▲ Hacker News 上 68 分、21 条评论的讨论,争论焦点:CoT 是内省还是表演
有人提出:
「Chain-of-thought 本质上是在要求模型叙述它在’想’什么,然后我们再去监控这段叙述。这更像是注入了一个自我报告环节,而非直接观察内部推理。」
也有人反驳:
「它未必完整,但在复杂任务里,思维链常常已经是承重结构的一部分——模型必须认真’想’,答案才能对。」
这场争论揭示了一个 OpenAI 没有(也可能无法)在这次开源中回答的问题:你量化的到底是模型「能不能被看穿」,还是模型「愿不愿意表演可解释」?
这件事为什么重要
表面上看,这只是一个 GitHub 仓库上线的消息。
但如果把时间线拉长——从 2025 年 3 月 OpenAI 提出「不要强压思维链」,到 12 月论文提出系统化评测框架,再到 2026 年 4 月把工具包开源——一条清晰的战略路径浮现出来:
OpenAI 正在把「思维链监控」从一种内部安全实践,推向行业基础设施的位置。
这意味着什么?
首先,未来的模型 system card 可能要写上monitorability score——不光告诉你模型有多强,还要告诉你模型有多「透明」。
其次,更强的 agent 未必只能靠更强的人类来盯。论文已经证明,用 AI 监控 AI 的思维链,在某些场景下比人类更有效。
最后,这给整个行业提出了一个绕不开的问题:当你的模型足够聪明到可以「想着一套、说着另一套」的时候,你怎么证明你的安全措施还在起作用?
OpenAI 给出的答案是:先把「怎么量化这个问题」标准化。至于这把尺子够不够长、够不够准——他们把球踢给了全世界的研究者。
— END —