 夜雨聆风
夜雨聆风





OpenClaw-RL:只需“聊聊天”,就能让你的专属 AI 越用越聪明
相信你一定有过这样的经历:AI 助手给了一个糟糕的回答,你耐心地指正它“这里算错了,应该先算 X”,它连连道歉,但下次换个问题,它可能又犯同样的错。
为什么 AI 这么“健忘”?因为在现有的 AI 系统中,你对它的每一次反馈,一旦聊天结束就被直接丢弃了。
今天要分享的这篇 Gen-Verse 团队发表的最新开源论文,提出了一项颠覆性的技术——OpenClaw-RL。它揭示了一个秘密:你随口说出的每一句纠正、工具的每一次报错,其实都是极其珍贵的“实时训练数据”。通过这套框架,普通用户无需懂任何代码,只需像平时一样与智能体(Agent)正常交流,它就能在后台默默自我进化,变得越来越懂你!
1. 引言
每一个部署在现实世界中的 AI 智能体,其实每天都在产生能够让自己“进化”的数据,但现有的系统却把它们当成垃圾白白扔掉了。
举个例子,在 AI 执行完一个动作之后,它总会收到一个外界的反馈,学术上叫下一状态信号(Next-state signal)。这个信号可能是你的一句追问“你是不是忘记加上邮费了?”,也可能是代码运行后的一行红字报错。现有的系统仅仅把这些信号当成生成下一句话的“聊天记录”。但我们认为,这些信号里藏着两座巨大的金矿:
- 被浪费的金矿 1:评价性信号(Evaluative signals)。
你重新提问代表你“不满意”,程序报错代表“失败”,这些其实都是对 AI 刚才表现的天然打分。这构成了极佳的 过程奖励(Process Reward),有了它,我们就不需要花大价钱请人工去标注数据了。 - 被浪费的金矿 2:指导性信号(Directive signals)。
当你不仅说它错了,还告诉它“你应该先检查那个文件”时,这其实给了 AI 一个极其具体的修改方向。可惜的是,传统的 强化学习(RL)系统只能听懂“+1分”或“-1分”,根本听不懂这么复杂的文字指导。
为了捡回这两座金矿,我们提出了 OpenClaw-RL,它能像“后台静默升级”一样,在不影响你正常使用的情况下,利用你和它的每一次对话来训练模型。
2. 问题设定:把聊天变成闯关游戏
为了让机器能听懂,我们需要把每一次交互流抽象成一个马尔可夫决策过程(MDP)。别被专业词汇吓到,它就像是在玩一个闯关游戏:
- 状态(State):目前为止所有的聊天记录和环境背景(就像游戏当前的关卡进度)。
- 动作(Action):AI 给出的回答或操作(就像玩家按下的技能键)。这是由 AI 的策略(Policy,即 AI 的大脑决策方式)决定的。
- 状态转移(Transition):AI 回答后外界的反应,也就是下一状态信号(比如你紧接着回复的那句话)。
- 奖励(Reward):裁判根据你的反应,给 AI 刚才的“技能”打的分。
3. OpenClaw-RL 基础设施:让边聊边学成为现实
怎么才能让 AI 一边陪你聊天,一边还能在脑子里复盘学习呢?我们设计了一套精妙的系统。
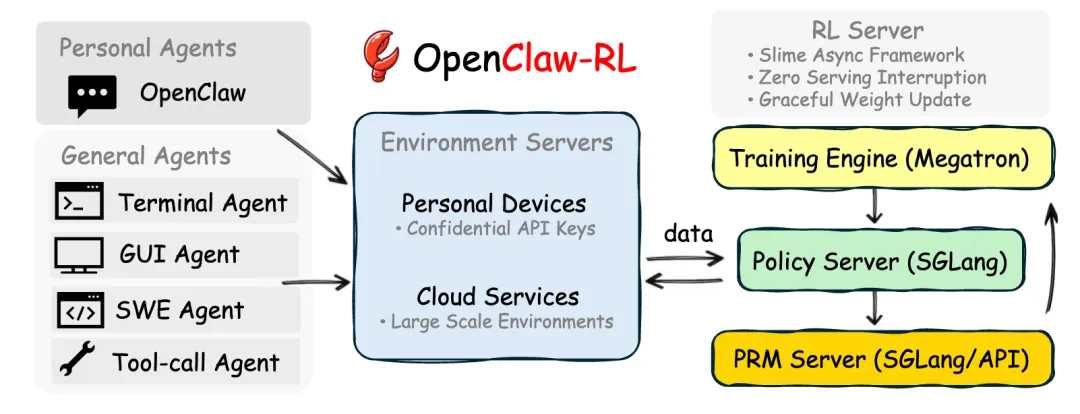
(图 1 | OpenClaw-RL 整体架构图。左侧展示了支持的多种智能体场景,中间是环境服务器,右侧是系统的“四大核心引擎”。)
3.1 互不打扰的“四引擎”异步流水线
如上图所示,这个系统的核心魔法在于完全解耦(Decoupled)。也就是各个部件各司其职,互不等待。我们把系统拆成了四个独立的齿轮:
- 策略推理(SGLang 绿色框)
负责陪你聊天。 - 环境服务(Environment 蓝色框)
连接你的手机电脑(个人设备)或云端沙盒。 - 奖励裁判(PRM Judge 黄色框下)
负责给刚才的聊天打分。 - 策略训练(Megatron 黄色框上)
负责在后台更新 AI 的大脑权重。
这四个齿轮各自转动(也就是所谓的“异步”)。AI 在回答你的新问题时,裁判正在给上一个回答打分,同时训练引擎悄悄更新大脑。这对你来说,聊天体验是完全无缝的,根本感觉不到它在偷偷学习。
3.2 大小通吃:从个人助理到云端打工魂
无论你是只想拥有一个懂自己习惯的个人助理(OpenClaw),还是需要成百上千个在云端写代码、操作电脑界面的通用智能体(Terminal / GUI / SWE 智能体),这套架构都能完美支持。
4. 核心揭秘:AI 是如何从你的回复中学习的?
这是整篇论文的精华所在。对于不同类型的反馈,我们准备了两套绝招。
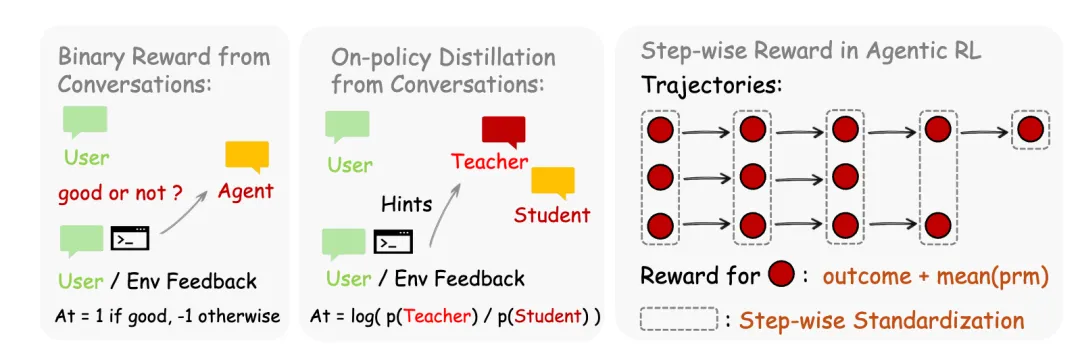
(图 2 | OpenClaw-RL 学习方法概览。左侧是根据对话给好坏打分;中间是提炼你的建议让 AI 开启“上帝视角”;右侧是长任务中的分步打分机制。)
4.1 绝招一:二元强化学习(应对“好评/差评”)
看上图的最左侧(Binary Reward):当你的回复比较简短(比如“不对”、“好的”),系统会把这种反馈转化成分数。 我们会引入一个过程奖励模型(PRM)作为裁判。它会看着 AI 的回答和你的回复,给出一个“好(+1)”或“坏(-1)”的分数。有了分数,后台算法就会“奖惩分明”:被点赞的回答风格会被鼓励,被骂的会被严厉打压。
4.2 绝招二:事后引导的同策略蒸馏 (OPD)
这是应对“具体指导意见”的杀手锏。 看上图的中间部分(On-policy Distillation): 如果只给 AI 打 -1 分,它下次可能还是不知道正确答案。所以我们用了 OPD 技术(俗称“抄学霸笔记”):
- 提取提示(Hint提取)
裁判发现你的回复里不仅有抱怨,还有指导(比如“你应该先备份”),它会把这句话浓缩成一个锦囊(Hint)。 - 制造“强化版教师”
系统偷偷把这个“锦囊”塞进当时的聊天背景里,制造一个“开了上帝视角”(Teacher)的虚拟大脑。 - Token 级精准纠正
Token是 AI 吐出文字的基本单位(比如一个汉字或一个英文单词)。系统会让“上帝视角”的大脑去对比“普通视角”的大脑,看看每个词汇出现的概率。如果某个词有了提示后概率变高了,以后就鼓励多用这个词。这相当于拿着你的建议,手把手教 AI 逐字逐句地改作文。
4.3 绝招三:针对长任务的分步奖励(Step-wise Reward)
看上图的最右侧(Trajectories):像“写代码”这种长线任务,可能要试错十几步。如果我们只看最终结果(Outcome),前面走对的步骤也会被冤枉。所以我们将最终结果和裁判对每一步(每一个红点)的打分结合起来,让 AI 知道自己究竟是哪一步走错了。
5. 实验:真的有这么神吗?
为了验证效果,我们在电脑里模拟了两个极端的日常用户来测试个人智能体:
- 写作业的学生
Ta 用 AI 帮自己写作业,但心里很怕被老师发现这是 AI 写的(极其抗拒“AI 腔”)。 - 批改作业的老师
Ta 用 AI 帮自己看作业,希望 AI 的评语能具体指出学生哪一步做得好,并且充满亲和力。 
(图 2 | 个人智能体优化前后对比。左侧是“学生场景”,右侧是“老师场景”及各项指标得分表。)
看上面的效果对比图,奇迹发生了:
- 在使用前(红色字 Before 部分)
AI 依然是一股浓浓的机器味儿(AI-like / Cold),动不动就“首先…其次…”,语气冰冷,没有感情。 - 使用了短短二三十次后(绿色字 After 部分)
在学生手里,AI 自动改掉了爱用粗体和刻板分步的毛病,语气变得极其自然,就像同班同学在给你讲题。 在老师手里,AI 的评语变成了:“你把 120 个单位减去 90 算得非常准!只有一个拼写小失误…干得漂亮!🌟” - 看右侧的表格
仅仅经过 8 次后台悄悄的更新(Updated 8 steps),学生的满意度得分从可怜的 0.17 飙升到了 0.76,老师的满意度从 0.22 飙升到了 0.90!
而在专业干活的“通用智能体”测试中(如代码运行、终端操作): 实验证明,引入分步的“过程奖励”比只看最终结果,能大幅度提升 AI 的任务成功率(例如在工具调用场景下,成功率几乎翻倍)。
6. 总结与启发
每一次你跟 AI 吐槽它笨,每一次它的代码运行报错,其实都是它蜕变最宝贵的养料。
OpenClaw-RL 的核心理念极具启发性:所有“做完一步后的反馈”,不管它是人话还是机器报错,都是普适的训练信号。
💡 对普通用户的启发: 以前,我们觉得调教 AI 是一件只有高精尖科学家才能干的玄学,常常因为 AI 听不懂人话而气得砸键盘。而现在,随着 OpenClaw-RL 这样开源技术的落地,你只需要正常地使用它,像朋友一样指出它的错误,你的 AI 就会在后台默默复盘。AI 最伟大的进化,其实就藏在你们每天的闲聊里。