 夜雨聆风
夜雨聆风





Chrome 的偷偷下载 4GB AI 模型,无视平台全中招,教你一招删除
Chrome 往你电脑里放了一个 4GB 的 AI 模型:这不是病毒,但也不是小事
最近,国外隐私博主 That Privacy Guy 的一篇文章在 X 上引发讨论。
文章称,Google Chrome 会在部分用户设备上,后台下载一个接近 4GB 的本地 AI 模型文件,文件名常被用户发现为 weights.bin,目录名则与 OptGuideOnDeviceModel 有关。作者进一步指控,这种行为没有充分告知用户,也没有明确征得同意,因此可能触及隐私、合规和环境成本问题。
这件事听起来像“Chrome 偷装 AI”,但更准确地说,它不是传统意义上的病毒,也不是简单的阴谋论。它反映的是一个更大的趋势:
AI 正在从云端进入浏览器,而浏览器正在把你的电脑当成模型部署平台。
Chrome 到底下载了什么?
Google 现在正在把 Gemini Nano 这类本地 AI 模型集成进 Chrome。
所谓“本地 AI”,意思是模型文件被下载到你的设备上,之后部分 AI 功能可以直接在本机运行,而不是每次都把数据传到云端处理。
按照 Google 官方说明,Chrome 的本地生成式 AI 模型可用于写作改写、诈骗提醒、网页总结、标签页整理等功能。Chrome 也明确表示,它可能会在后台下载这些模型,以便相关功能可以随时使用。

从技术角度看,这有合理的一面。
本地模型的好处是:响应更快、离线能力更强、部分数据不必离开设备。Google 面向开发者的文档也写明,使用 Gemini Nano 相关内置 AI API 时,模型运行在本地,后续使用不需要联网,数据不会发送给 Google 或第三方。
但问题在于:这么大的模型,为什么很多用户是在磁盘空间被占用之后才知道?
争议点不在“本地 AI”,而在“默认和不透明”
这次争议真正刺痛用户的,不是 AI 模型本身,而是几个细节。
第一,文件很大。多家媒体报道,用户发现 Chrome 相关目录下出现了约 4GB 的 weights.bin 文件,用于 Chrome 的 Gemini Nano 本地 AI 功能。对于 1TB 硬盘的用户来说,4GB 可能不算什么;但对于 128GB、256GB 的笔记本,尤其是系统盘紧张的设备,这已经不是可以忽略的小文件。
第二,用户感知弱。普通用户打开 Chrome,是为了浏览网页,不是为了主动安装一个大模型。即使这个模型有安全检测、写作辅助等用途,也应该在下载前给出清晰说明:它是什么、占多大空间、用于哪些功能、是否可以拒绝。
第三,直接删除可能没用。媒体报道和用户反馈显示,如果相关 AI 功能仍然开启,用户手动删除 weights.bin 后,Chrome 可能会重新下载。更正确的关闭方式,是进入 Chrome 设置中的 System / On-device AI 选项关闭,而不是只删除文件。
这就是问题的核心:安装成本很低,删除和理解成本却很高。
一个功能如果真的对用户有价值,应该让用户知道它的存在,而不是等用户查磁盘占用时才发现。
它是不是“间谍软件”?
严格说,不建议直接把它称为“间谍软件”。
目前更准确的判断是:这是 Chrome 的本地 AI 模型组件,用于浏览器内置 AI 功能。Google 官方文档强调,本地模型运行时不会把数据发送给 Google 或第三方。
所以,如果把它简单说成“Chrome 偷偷上传你的隐私”,证据并不充分。
但反过来,也不能因为“数据可能在本地处理”,就认为这件事没有问题。
隐私问题不只包括“有没有上传数据”。它还包括:
-
用户是否被明确告知?
-
用户是否主动选择?
-
用户能否方便关闭?
-
用户删除后,系统是否尊重?
-
是否占用了用户没有预期的磁盘和网络资源?
这些问题都是真实存在的。
也就是说,这件事不是典型的“数据泄露事件”,而是一个关于透明度、同意权和设备控制权的问题。
为什么这件事值得重视?
因为 Chrome 不是一个小众应用。
浏览器是互联网入口。它常驻后台、自动更新、权限较高、用户信任度极强。一个浏览器如果可以在默认状态下,为了未来某些功能提前部署大模型,那么操作系统、办公软件、输入法、网盘、聊天工具是不是也可以这么做?
这才是更大的问题。
过去,软件安装一个功能,通常会让用户知道。现在,AI 功能越来越像“基础设施”:厂商可能认为它是产品的一部分,应该自动进入用户设备。
但用户可能并不这么看。
对厂商来说,这是“提升体验”。
对用户来说,这可能是“我的电脑被你拿去做了部署节点”。
这两种视角之间,正是今天 AI 产品最大的信任裂缝。
本地 AI 本来可以是好事
这件事也不能简单变成“反 AI”。
本地 AI 其实是一个很重要的方向。相比所有请求都发到云端,本地模型有明显优势:
-
它可以减少敏感数据上传;
-
它可以降低网络依赖;
-
它可以提升响应速度;
-
它可以让浏览器、操作系统具备更多离线智能能力。
从长远看,浏览器内置 AI 模型并不奇怪。Chrome、Edge、Safari、Firefox 未来都可能做类似事情。问题不是“应不应该有本地 AI”,而是“应该用什么方式进入用户设备”。
合理的方式应该是:
-
第一次启用前明确提示;
-
告诉用户模型大小;
-
说明它服务哪些功能;
-
提供一键关闭和删除;
-
尊重用户删除行为;
-
不要把开关藏在很深的设置里。
AI 越强,默认行为就越应该透明。
普通用户怎么检查和关闭?
如果你使用 Chrome,可以这样自查。
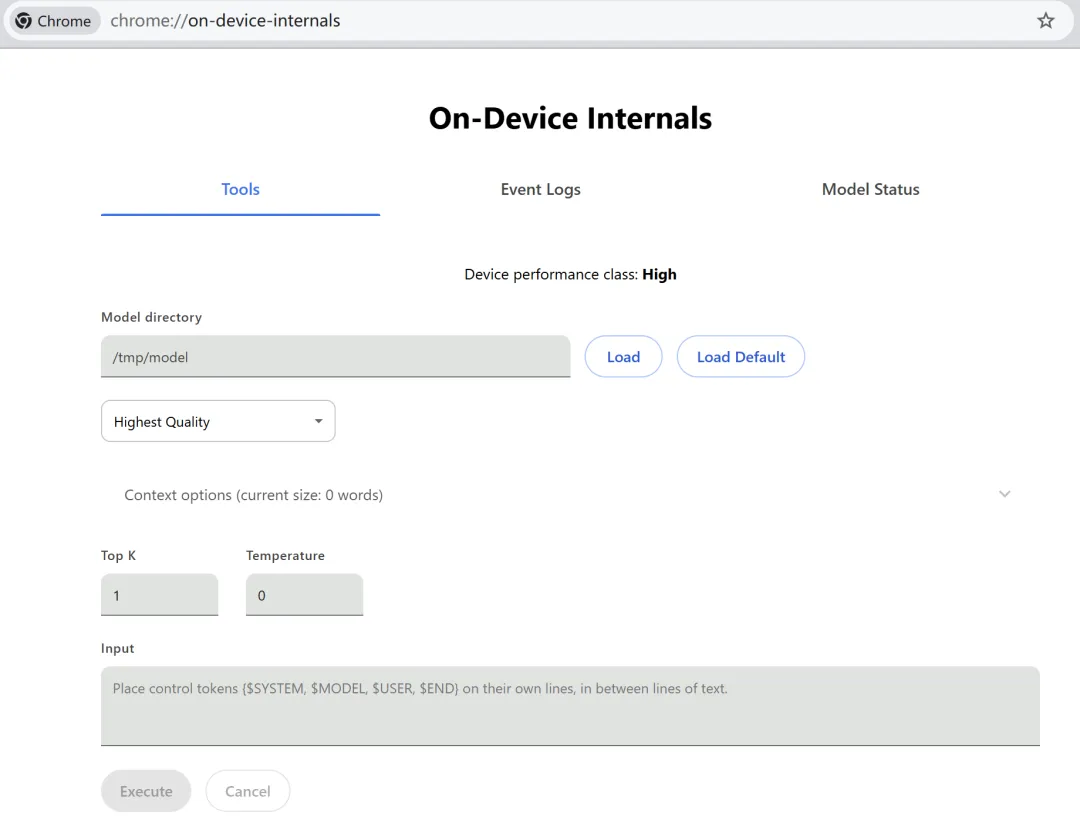
在地址栏输入:chrome://on-device-internals
这个页面可以查看 Chrome 本地 AI 模型状态和相关信息。Google 的开发者文档也建议用户通过这个页面查看当前模型大小。
如果你想关闭,可以进入:Chrome 设置 → System / 系统 → On-device AI
然后关闭本地 AI。Google 官方帮助文档说明,关闭或删除本地生成式 AI 模型后,依赖这些模型的功能会不可用;重新开启后,Chrome 可能再次下载模型。(谷歌帮助)
不建议只去文件夹里手动删除 weights.bin。如果开关还开着,后续可能重新下载。
这件事真正提醒了什么?
这件事最值得警惕的,不是 4GB 本身。
4GB 会越来越小。几年后,电脑里塞几十 GB 的本地模型也许会很常见。
真正的问题是:谁决定你的设备上应该放什么?
是用户决定,还是厂商决定?
AI 时代,软件正在变得越来越主动。它会预测你需要什么,提前下载,提前缓存,提前部署,提前接管一部分工作流。
这当然可以带来效率。但效率不能替代同意。便利不能替代透明。本地 AI 也不能成为“默认占用用户设备”的理由。
Chrome 这次争议给所有 AI 产品提了一个醒:用户不是算力池,用户设备也不是厂商的远程部署机。哪怕功能是好的,也应该让用户知道、选择、拒绝,并且真正能够移除。
否则,AI 越“智能”,用户越会觉得自己失去了控制权。
这件事可以用一句话概括:
Chrome 下载的可能不是恶意软件,但它暴露了 AI 时代一个更隐蔽的问题:大厂越来越习惯替用户做决定。
本地 AI 是未来,但未来不应该以“悄悄塞进来”的方式到来。