 夜雨聆风
夜雨聆风





OpenClaw 2026.5.12-beta.2更新:龙虾出错没响应,你还以为它在思考

我上周跑了一个批量任务,调的是 OpenClaw Gateway 的 OpenAI 兼容接口。调用里设了 max_completion_tokens=800,想控制输出长度和成本。
跑完看账单——不对。每条都跑满了,压根没被截断。排查了半小时才发现:Gateway 把这个参数直接忽略了,没往上游透传。
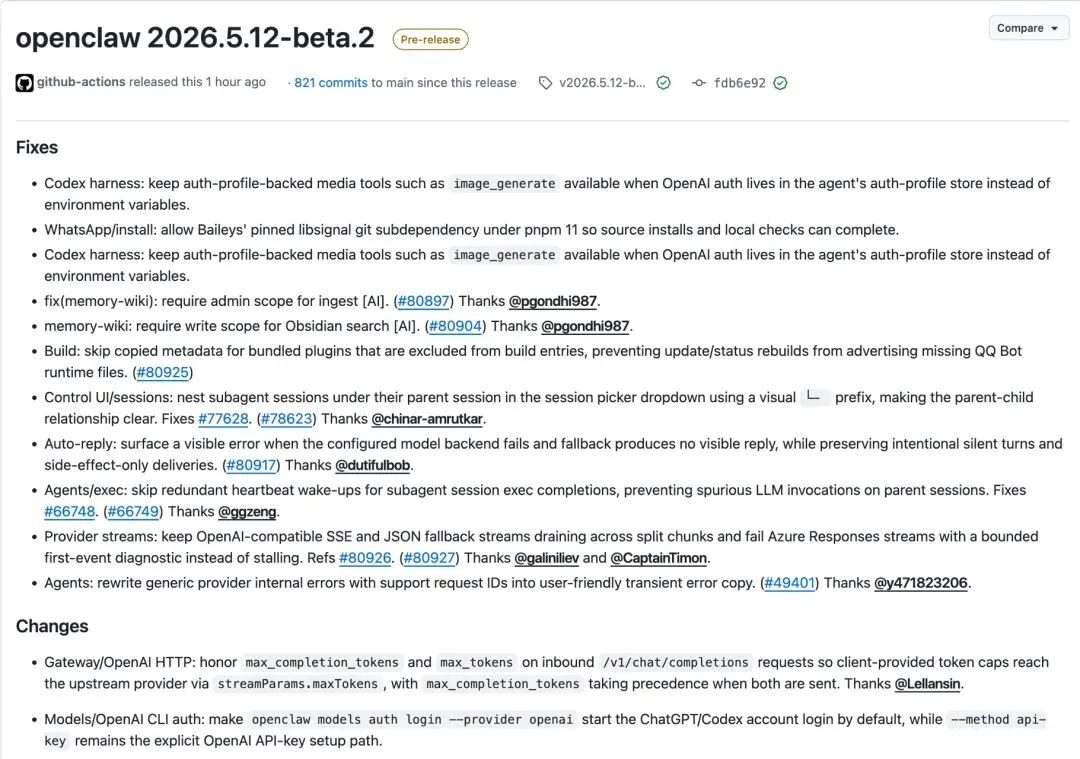
这种问题属于「静默失败」里最隐蔽的一类:它不报错,只是悄悄不执行你的意图。你以为控制了成本,其实没有。2026.5.12-beta.2 修了这件事,以及另外两个同类型的问题。
01 | 你设的 token 上限,终于有人听了
Gateway 现在会把 max_completion_tokens 和 max_tokens 透传给上游模型了,前者优先级更高。
以前你在 API 调用里写了限制,OpenClaw 会无视它;现在会老实传下去,让模型真的按你的要求截断输出。
对跑批量 API 的人来说,这一行 fix 直接影响账单。同样的任务集加了截断限制之后,输出 token 能减少不少。
02 | 模型挂了,现在至少告诉你为什么
以前的场景:你喊了 AI,然后……什么都没有。不是在转圈,是直接没有。你不知道是模型在生成、后端挂了还是网络超时了。只能干等,或者刷新,或者再喊一遍。
模型后端失败的时候,现在会显示一个可见的错误信息,不再用无响应来代替报错。
「无响应」和「失败了告诉我」,排查时间差了一个数量级。前者你只能猜,后者你直接看。
生产环境里,静默失败是最难处理的一类问题——因为你甚至不知道有问题。这个 fix 不是新功能,是把一个一直存在的缺陷补上了。
03 | 子 Agent 跑完,父 session 不再被多余唤醒
以前的逻辑:子任务执行完成 → 触发父 session 心跳唤醒 → 父 session 启动一次 LLM 调用来「确认」完成。这次 LLM 调用通常什么都不做,纯粹是被无谓唤醒的。
修完之后,子任务完成不再触发父 session 的心跳。跑 10 个子任务,省掉了 10 次多余的 LLM 调用。
不是功能更新,是把钱省回来了。多 Agent 跑规模任务的时候,这个隐性成本还挺可观的。
04 | 其他几个修复
WhatsApp 在 pnpm 11 下的安装依赖问题修了,source install 现在能正常完成。Codex harness 修了 auth-profile 模式下媒体工具失效的 bug——如果你用 auth-profile 存 OpenAI 凭证,之前 image_generate 这类工具会不可用,现在正常了。Azure SSE stream 的 stalling 问题也修了。
回头看,beta.2 的 fix 集中在同一件事:把各种「静默失败」变成「可见的反馈」。token 限制被忽略、模型出错没响应、子任务完成多余唤醒——这些都是系统在悄悄不执行你的意图,而且不告诉你。
越是自动化的系统,越需要这类可见性基础设施。不然你不是在管理 AI,你是在猜 AI。
你用 OpenClaw Gateway 做过批量 API 调用吗?有没有遇到过「设了参数但没生效」的情况?
⭐点赞、转发、关注和推荐一键三连⭐