夜雨聆风
夜雨聆风





Contextualized Word Vectors – CoVe(有上下文的词向量)
Contextualized Word Vectors
我们知道那篇很有名的《Attention Is All You Need》是 2017 年发表的,也是这一年稍微晚了两个月,一篇叫做《Learned in Translation: Contextualized Word Vectors》的论文提出了他们的解决方案。
他们的方法其实受到了在 ImageNet 上训练的 CNN 能够成功迁移到计算机视觉中其他任务的启发,他们也是专注于一个 NLP 任务,即机器翻译(MT),而把机器翻译中的编码器(Encoder)迁移到其他 NLP 任务中,其实也就是拿到中间编码器的输出作为词向量。
其实想到这里是觉得挺有意思的,在视觉领域让模型学到了可迁移通用能力的任务是图片分类任务,而在语言领域让模型学到这个能力的任务是语言翻译任务。其实仔细思考一下也不难发现,这两个任务都在潜移默化的情况下让模型必须要摸清图片或者文字中的含义。对于计算机视觉来说,其任务的本质,是要求模型能够读懂图片中哪些像素是一起的,能够提取到什么特征,代表了什么物体。而文字翻译任务要求模型忠实地在目标语言中重现源语言的句子的含义,而不会丢失源语言句子中的信息 。而这种能力正是图片跟文字领域的 “元能力”,才是这种任务得到的模型可以被迁移到其他任务的本质。
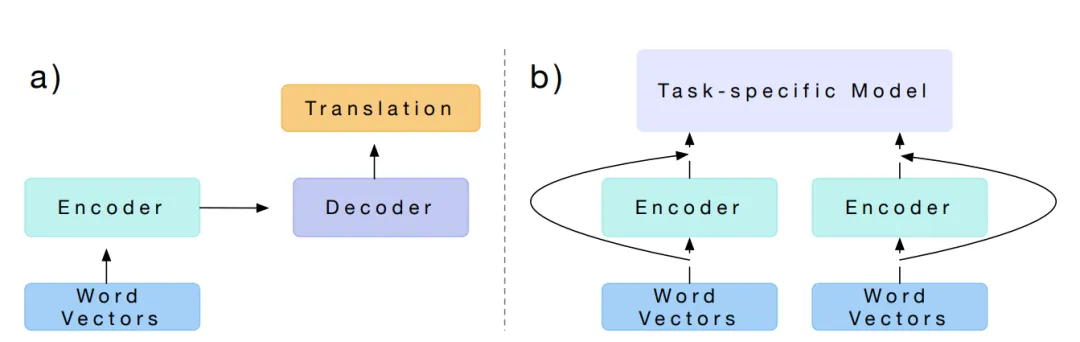
CoVe 论文中的模型使用的是 “英译德” 的翻译任务,输入的英文的初始向量使用的是 GloVe 模型得到的词向量,中间模型使用的是一个双向的双层 BiLSTM 模型,他们称之为 MT-LSTM(机器翻译-LSTM)。
了解模型的结构固然是重要的,但是 LSTM 我在去年已经仔细介绍过了这里就不重复介绍了,我只是想用一个我自己脑子中的案例来类比循环神经网络的运作原理。
这类网络是用来处理连续数据问题的,计算着一个一直基于新数据的隐藏层。我们想象我们有一杯清水,然后有三种颜色红,黄,蓝三种颜色的颜料。
我们先将清水倒入蓝色,此时杯中水变为蓝色,如果再倒入黄色,此时由于搅拌了此前蓝色的信息,此时水变为绿色,如果我们再倒入红色,此时水变为棕色。
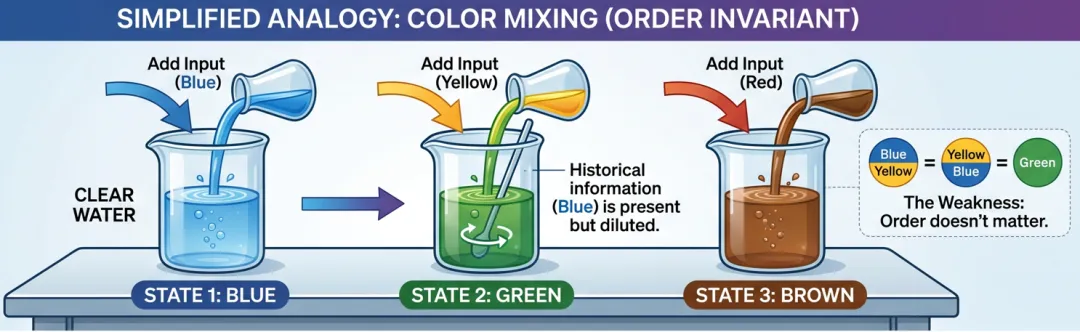
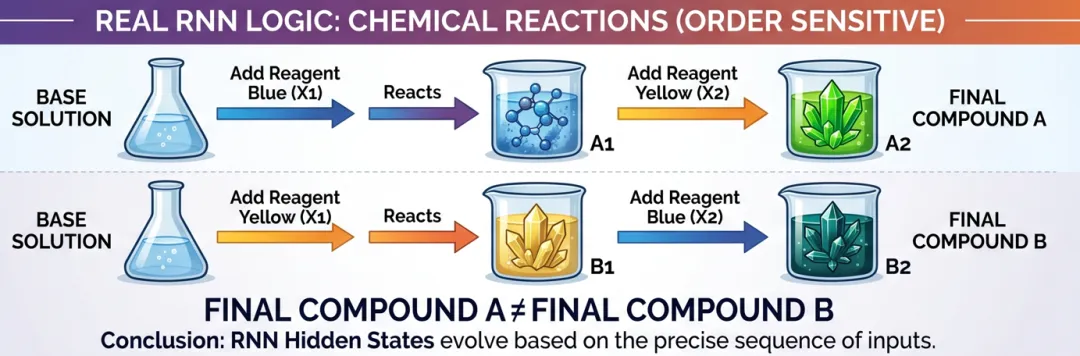
如果我们把这杯水比作循环网络中记录过程中不断积累叠加的信息的中间层,那么我们就可以大致理解这个中间层的作用就是在不断混合记录着历史信息。虽然从理论上讲所有历史信息都会被混在里面,但是时间越久远的信息肯定会被不断稀释掉。
我这里一定要提一句,我上面的例子只是类比,它并不完全等于真实的计算。因为真实的计算顺序也会导致不同的叠加信息。而我们的案例中,先倒入黄色再倒入蓝色,跟先倒入蓝色再倒入黄色都会变成绿色,这在真实的循环网络计算中大概率是不成立的。如果有化学基础的朋友可以想象那是个烧杯,我们加入的反应试剂顺序不同而产生的化合反应不同则可能更准确一点。