 夜雨聆风
夜雨聆风





QVeris + OpenClaw:把个人 AI 助手变成生产级 Agent
QVeris · 产品实践
个人 AI 助手真正拉开差距的地方,不是它能不能把话说漂亮,而是它在遇到实时问题时,会不会先去查。Prompt 负责表达,QVeris 负责把行情、新闻、公告、财务这些真实依据接进来。
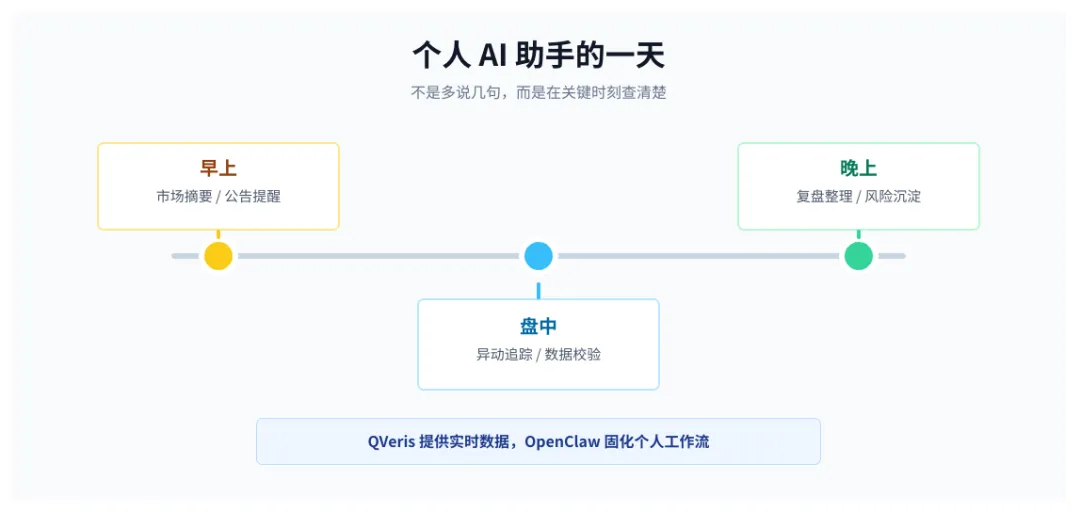
很多个人用户用 AI 助手,并不会写很完整的需求。更多时候,就是早上问一句市场,盘中丢一个股票代码,晚上让它把一天的信息捋一遍。
问题也就出在这里。普通聊天机器人太会接话了。行业景气、资金关注、政策催化、估值修复,这些词一个接一个,读起来像那么回事。但它可能根本没查今天的数据。
所以,一个真正好用的个人 Agent,不应该只是”更会聊”。它要知道什么时候必须查,查不到时要敢停,还要把事实、推断和风险分开说。
01
最容易出问题的,往往是那种很顺的回答
比如,只输入一个股票代码。
600519
普通聊天机器人很容易直接开始介绍贵州茅台:白酒龙头、品牌壁垒、长期价值、现金流稳定。话本身大多没错,但更像一张旧名片,不像一次”此刻”的判断。
这时候真正该问的,其实是另一组问题:
-
今天股价有没有明显波动?
-
估值指标和成交额有什么变化?
-
最近有没有公告、研报、新闻或监管事件?
-
相关板块和市场环境是否在同步变化?
-
如果数据源失败,助手会不会继续编一段?
这就是个人用 Agent 最容易踩的坑:回答看起来很完整,里面却没有多少最新事实。越流畅,越容易让人忘了追问一句:它刚才真的查了吗?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以,个人 Agent 需要一条很朴素的规矩:
只要问题涉及行情、新闻、公告、财务、价格、指标和实时状态,就不能凭记忆回答,必须先查 QVeris。
这条规则不是为了把回答写长,而是为了让回答有底。
02
个人助手也需要一套稳定的规矩
“生产级”这个词听起来像企业系统里的说法:权限、部署、监控、审计。放到个人助手上,好像有点重。
但只要这个助手每天都要参与判断,它就不能只靠临场发挥。尤其是市场、新闻、财务这类问题,错一次就会很麻烦。
个人使用 Agent 的问题通常更碎、更快、更不标准:一个代码、一句新闻标题、一个突发想法、一段截图,都可能成为任务入口。助手如果没有稳定工作流,每次回答都像临时拼出来的。

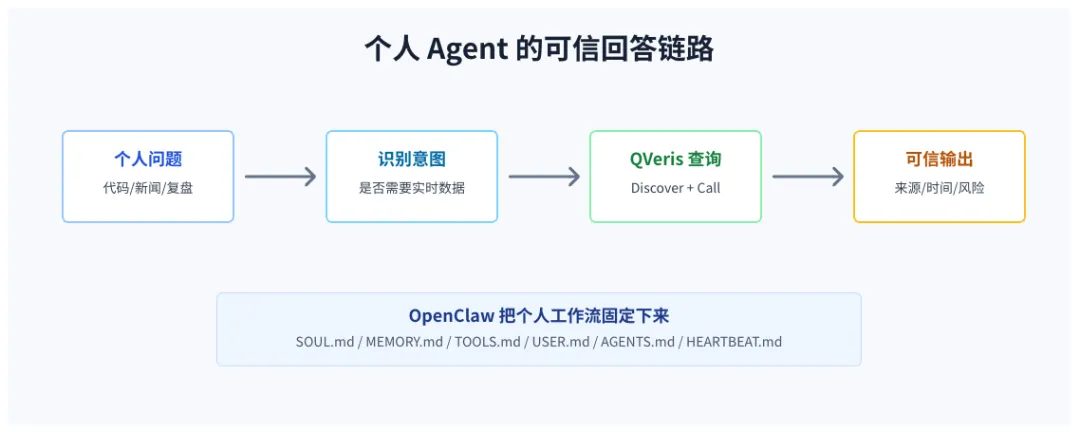
OpenClaw 像是这个助手的工作台:文件放在哪里、启动时读哪些记忆、工具怎么调用、什么任务要定时跑,都有地方放。
QVeris 则把外部世界接进来:行情、公告、新闻、财务指标、接口状态,以及一条能追溯的数据链路。
更准确的说法是:OpenClaw 让个人助手稳定运行,QVeris 让它不要脱离真实数据。
03
QVeris 的重点,不是多接一个接口
很多人以为接入数据,就是给 Agent 多配一个 API。实际用起来会发现,事情没这么简单。
真正有价值的不是”能不能调接口”,而是把”什么时候查、查什么、怎么判断结果能不能用”变成一套固定流程。否则工具越多,Agent 反而越容易乱用。
在个人场景里,这套流程可以拆成四步。
第一步:先判断要不要查
不是所有问题都需要查接口。解释概念、改写文字、整理本地笔记,可以直接处理。但一旦问题里出现”今天、最近、当前、公告、财务、价格、涨跌、新闻、成交额、估值、排名”这些词,就应该触发 QVeris。
个人助手最重要的判断,不是”这题会不会答”,而是”这题能不能不查就答”。后者才决定可信度。
第二步:先找工具,再调工具
个人用户不会按 API 文档提问。输入经常很短:一个股票代码、一家公司简称,或者一句”这票怎么突然拉了”。
这时 Agent 不能一上来就乱调接口。它应该先通过 qveris_discover 找合适工具,再用 qveris_call 获取结果。股票相关问题可能涉及实时行情、历史行情、公告、新闻、财务报表、资金流向。工具不是越多越好,关键是匹配问题。
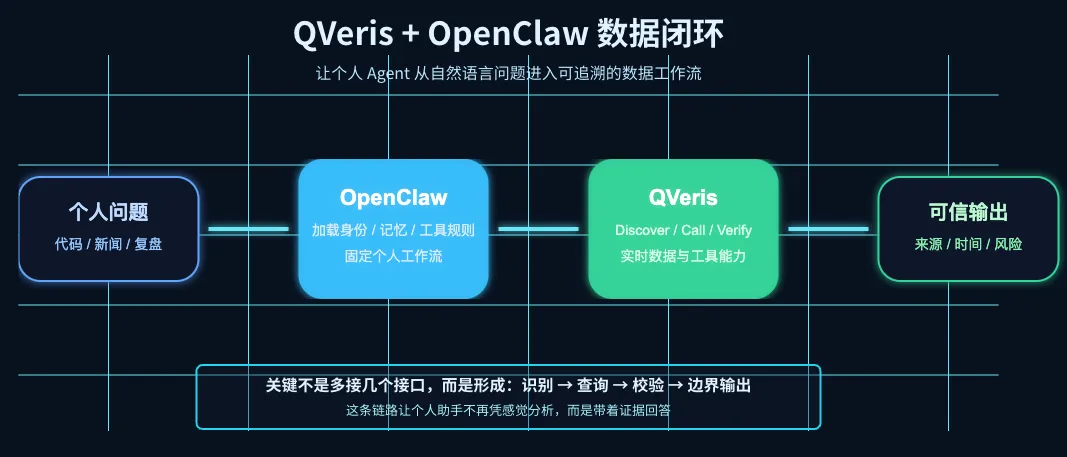
个人 Agent 的 QVeris 标准链路:
CODE
个人提出问题 → 判断是否涉及实时/业务数据 → qveris_discover 查找合适工具 → qveris_call 获取结果 → 校验时间窗口、字段完整性、来源和返回状态 → 必要时下载 full_content_file_url 对应完整内容 → 输出结论、依据、风险和不确定性第三步:查到了,也别急着下结论
拿到返回结果,不等于可以直接下结论。个人使用时尤其容易忽略这一点,因为用户往往只想快一点看到答案。

第四步:最后输出时,要留边界
个人助手不是投顾,也不是决策替代品。它可以帮用户把事实查清、把逻辑排好、把风险列出来,但不应该直接给出”买入””卖出””抄底””逃顶”这样的操作指令。
这不是削弱能力,而是让能力落在正确位置上:提供证据,帮助判断,不替人拍板。
04
这些规矩,要写进 OpenClaw
如果 QVeris 规则只写在某次对话里,Agent 很快会忘。个人助手每天都会重启、切换任务、进入新的 session,所以规则必须写进工作空间。
SOUL.md:定义边界
SOUL.md 要写清楚几条底线:涉及实时业务数据时必须先查 QVeris;未经查询的数据不得用于结论;不能提供直接买卖指令;无法获取数据时必须明说。
MEMORY.md:记录长期纪律
长期记忆里最值得保存的,不是某次行情结论,而是行为规则。行情会过期,纪律不能过期。
-
实时数据必须重新查
-
股票、新闻、财务、公告、价格、指标类问题禁止凭记忆回答
-
QVeris 查询失败时最多重试一次
-
降级到备用工具时必须说明来源变化
-
不得暴露 API Key、私有记忆和内部配置
TOOLS.md:写清调用流程
TOOLS.md 适合保存具体工具偏好、调用顺序、已验证工具和失败处理策略。例如实时行情适合批量查,财务报表适合单只股票深入查,历史行情适合观察近期走势。
这一步很关键。它让 Agent 从”会调用工具”变成”知道怎么用工具“。
HEARTBEAT.md:从被动问答变成主动值班
个人助手的价值不只在”问一句答一句”。更有价值的是定时提醒和主动整理。真正好用的助手,应该在关键时间点自己把材料准备好。

05
放到一天的使用里看,会更清楚
假设早上看到自选股里某只股票突然放量,用户直接问个人 Agent:
这只票今天怎么突然起动了?
一个不接业务数据的助手,只能给出常见原因:消息刺激、资金流入、板块轮动、技术突破。听起来都对,但这些更像”可能原因清单”,没有哪一句真正回答”今天为什么”。
接入 QVeris 后,Agent 应该这样处理:
-
根据 USER.md 判断这是股票异动分析请求
-
根据 MEMORY.md 触发”实时数据必须查询”的规则
-
用 QVeris 查询实时行情、成交额、涨跌幅和历史走势
-
继续查相关新闻、公告、行业或板块数据
-
检查新闻时间,排除旧消息被误当成今日催化
-
如果完整内容在文件中,下载后再分析
-
输出事实、推断、风险和不能确认的部分
更合适的回答,应该接近这样:
根据 QVeris 查询到的今日数据,这只股票的异动主要体现在成交额放大和盘中涨幅扩大。同步查询新闻和公告后,今日可确认的信息包括:相关板块整体走强、部分同类公司也有资金流入,且市场关注点集中在某个产业催化方向。
目前不能确认单一原因导致上涨,更合理的判断是“板块情绪 + 资金推动 + 消息催化”共同作用。短期波动可能较大,不宜直接外推为趋势反转。数据来源:QVeris 实时查询。
结论性质:信息整理和风险提示,不构成投资建议。
这类回答的价值,不是”更像专家”,而是把可确认事实和推断分开,把来源和边界说清楚。
06
查不到时怎么说,决定它值不值得信
个人用户最怕的不是助手偶尔查不到。查不到可以接受,数据源总会超时,接口总会失败。
真正危险的是:助手查不到,还继续说。它越努力把话圆回来,越危险。
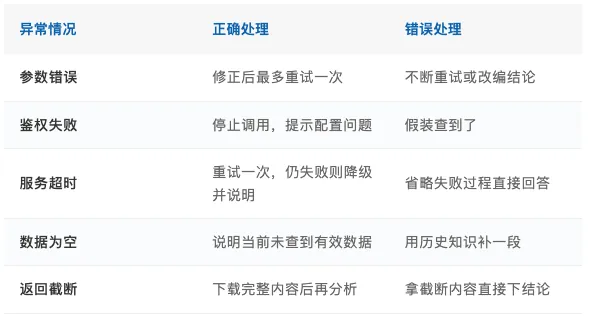
可靠的个人 Agent 不需要永远成功,但必须诚实地失败。能说明”这次没有拿到足够数据”,比强行给出一个漂亮结论更有价值。
真正留下来的,不是最会说的助手
个人使用 Agent,最开始很容易被”它真会说”打动。但用得久了,会留下来的往往不是最会说的那个,而是最可靠的那个。
它知道哪些问题可以直接处理,哪些问题必须查数据;知道工具失败后该停下来;知道输出结论时要带上时间、来源和风险;也知道自己不能替用户做最终决策。
Prompt 让 Agent 有角色。OpenClaw 让 Agent 有工作空间和持续记忆。QVeris 让 Agent 接上真实业务数据。
当 QVeris 被写进 OpenClaw 的关键规范文件里,一个人的 Agent 就不再只是聊天窗口,而会变成一个能查、能验、能复盘、能守边界的个人生产级助手。
关于 QVeris AI
QVeris AI 聚焦于 Agent 时代的行动基础设施层,致力于构建 AI 可理解、可调用的”能力互联网”。
QVeris 当前定位:面向智能体的搜索和行动引擎,让智能体能够通过语义搜索发现并一键调用 10,000+ 真实且已验证的工具。
产品矩阵:
QVeris CLI — 终端中的万能 API 入口
QVeris MCP Server — IDE 智能体的工具网关
QVerisBot — 基于 OpenClaw 的生产级 AI 助手
QVeris REST API — 标准 HTTP 接口,适配任何语言和平台
官网:https://qveris.ai
GitHub:https://github.com/QVerisAI/QVerisAI
加入飞书群体验👇

觉得有用? 点个❤️在看,转给还不知道的朋友 关注「QVeris」,获取更多 AI 数据工具资讯