 夜雨聆风
夜雨聆风





OpenClaw 搭建电商客服实战:从文档整理、RAG 知识库搭建到回答问题跑通的完整项目实操
这一篇不聊抽象概念,直接做一次 OpenClaw 知识库实操搭建。
目标很明确:把电商场景里最常见的几类资料整理好,然后接进 OpenClaw,让它能围绕这些资料回答用户问题。
这次我们聚焦的不是“万能 AI 助手”,而是一个非常具体、非常实用的方向:
基于商品说明、售后政策、发票规则、优惠券规则等文档,搭一个能回答问题的电商知识库客服。
如果你以前总觉得“知识库”这个词听起来很大、很虚,这篇文章就是想把它拆成一套能真正落地的动作:
-
文档怎么准备 -
目录怎么组织 -
OpenClaw 怎么配置 -
Ollama embedding 怎么接 -
memory search 怎么验证 -
怎样把结果调得更适合电商客服
整篇文章你可以把它理解成一句话:
不是教模型聊天,而是教它按资料回答。
一、电商客服真正难的,不是“不会说”,而是“容易说错”
很多人第一次做 AI 客服,会把注意力放在模型能力上,比如:
-
它聪不聪明 -
会不会总结 -
说话像不像真人
但真到电商场景里,最麻烦的问题往往不是这些。
真正容易翻车的,通常是下面几类问题:
-
商品介绍口径不统一 -
售后政策说不清楚 -
发货承诺说过头 -
发票和优惠券规则回答混乱 -
用户一追问,机器人就开始脑补
比如这些问题,你一定不陌生:
-
这款麻辣小龙虾到底辣不辣? -
不喜欢吃能退吗? -
冰袋化了是不是就坏了? -
今天下单什么时候发? -
能不能开专票?
这些问题看起来都不难,但它们有一个共同点:
答案必须来自规则,而不是来自想象。
所以这次实操的核心,不是“先让 OpenClaw 变聪明”,而是:
先把知识资料整理成它能稳定理解、稳定检索、稳定引用的形式。
二、这次实操,我们到底在搭什么?
这次我们搭的是一个 OpenClaw 电商RAG知识库客服。
它依赖的核心资料,主要有三类:
-
商品资料 -
规则资料 -
常见问答资料
对应到这次项目里的目录,大致是这样:
Memory/├── kb/│ ├── products/│ │ ├── 麻辣小龙虾尾-250g.md│ │ └── 蒜蓉小龙虾尾-250g.md│ ├── policies/│ │ ├── 发货时效规则.md│ │ ├── 冷链签收规则.md│ │ ├── 退货退款规则.md│ │ ├── 售后凭证要求.md│ │ ├── 错发漏发处理规则.md│ │ ├── 优惠券规则.md│ │ ├── 电子普通发票规则.md│ │ └── 专票说明.md│ └── faq/│ └── 常见客服问答.md└── prompts/ └── 电商客服系统提示词.md你会发现,这里我没有把所有规则堆进一份“大而全”的文档里,而是刻意拆成了很多小文件。
这是因为在知识库场景里,文档拆分本身就是搭建的一部分,而不是后续可选优化。
比如:
-
“优惠券规则”单独一份 -
“电子普通发票规则”单独一份 -
“专票说明”单独一份 -
“冷链签收规则”单独一份
这样做最大的好处是:
-
一个文件只讲一个主题 -
检索时更容易命中真正相关的内容 -
用户问“发票”时,不会顺手把“优惠券”也整块带出来
三、先把资料准备对:知识库效果,很多时候就输赢在这一步
很多人做知识库,一上来就把商品详情页、活动页、售后说明原封不动丢进去。
这样最常见的结果是:
-
文档内容很长,但重点不清楚 -
规则埋在长文里,不好命中 -
一个问题打进来,机器人抓不到关键句
所以这一步不要偷懒。
为了让这一步更容易照着做,下面我直接用这次电商客服里的真实资料结构来讲。
1. 商品资料怎么写
商品资料建议尽量结构化,至少包含这些字段:
-
商品名称 -
规格 -
建议食用人数 -
储存方式 -
保质期 -
口味特点 -
食用方式 -
主要配料 -
客服回答要点 -
不适合承诺的内容
如果只讲原则,容易飘。我们直接看一个商品资料应该怎么拆。
比如原始资料可能只有一句话:
麻辣小龙虾尾,250g,香辣口味,冷冻保存,加热即食。
如果你把这句话直接丢进知识库,机器人虽然也许能答一点,但答得不会稳。
更适合知识库的拆法,是把它整理成下面这样的结构:
# 商品资料:麻辣小龙虾尾 250g## 基础信息- 商品名称:麻辣小龙虾尾 250g- 规格:250g/袋- 建议食用人数:1 到 2 人- 储存方式:-18 摄氏度冷冻保存- 保质期:180 天## 口味特点- 口味:麻辣味- 辣度:中辣偏上- 特点:香辣明显,适合平时能吃辣的人群## 食用方式- 无需长时间解冻- 建议剪开包装后倒入锅中,小火加热 5 到 8 分钟## 客服回答要点- 如果用户问“辣不辣”,可回答为“中辣偏上,不太能吃辣的用户更建议选择蒜蓉口味”## 不适合承诺的内容- 不承诺“绝对不辣”- 不承诺“适合所有人群”这就是“商品说明文档准备”最重要的思路:
-
把原始详情页内容拆成客服真正会用到的字段 -
把事实和话术分开 -
把能说的话和不能说的话都写清楚
为什么要专门写“客服回答要点”和“不能承诺的内容”?
因为电商客服最怕的不是没话说,而是乱承诺。
比如:
-
一定明天到 -
不喜欢都能退 -
孕妇也能放心吃 -
小孩肯定没问题
这些话一旦说出去,后面处理成本会非常高。
所以最稳的做法,是在文档里提前写清楚:
-
哪些可以回答 -
哪些不能直接承诺
2. 规则资料到底要怎么拆,才适合做 RAG
规则资料不要图省事写成“大杂烩”。
比如下面这种文档名字,就不太适合做知识库:
-
售后总说明 -
发货签收售后一体说明 -
优惠券与发票规则
为什么不适合?
因为用户的问题天然是单主题的。
举个最真实的例子。
用户问:
-
能不能开专票?
这时候如果你的知识库里只有一份 优惠券与发票规则.md,检索很可能把“优惠券过期不补发”一起带出来,虽然也不是完全错,但很容易让回答显得发散。
更适合检索的写法,是每份文档只负责一个主题:
-
发货时效规则 -
冷链签收规则 -
退货退款规则 -
售后凭证要求 -
错发漏发处理规则 -
优惠券规则 -
电子普通发票规则 -
专票说明
我们直接拿“发票”这件事来举例。
很多人一开始会写成这样一份大文档:
# 优惠券与发票规则## 优惠券规则- 优惠券过期后原则上不补发## 发票规则- 支持电子普通发票- 专票需人工确认这种写法人看没问题,但拿来做知识库不够细。
更适合这次实操的拆法,是拆成三份:
优惠券规则.md电子普通发票规则.md专票说明.md
这样拆完以后:
-
用户问“优惠券过期能不能补”,命中 优惠券规则.md -
用户问“能不能开发票”,命中 电子普通发票规则.md -
用户问“能不能开专票”,命中 专票说明.md
这就是最典型的 RAG 资料拆分思路:
不是按你写文档方便来拆,而是按用户提问意图来拆。
每份规则文档建议都写这几类信息:
-
最近更新时间 -
适用范围 -
明确规则 -
客服口径
这样后面 OpenClaw 命中文档时,不仅能知道“规则是什么”,还能知道“客服应该怎么说”。
再举一个售后规则的例子。
假设你现在只有一份《售后总说明》,里面同时写了:
-
不喜欢吃能不能退 -
冰袋化了怎么办 -
少发了怎么办 -
外包装破了怎么办
这份文档对人来说很好懂,但对知识库来说太“宽”了。
更好的拆法是:
退货退款规则.md冷链签收规则.md错发漏发处理规则.md售后凭证要求.md
这样用户问:
-
“不喜欢吃能不能退”,优先命中 退货退款规则.md -
“冰袋化了是不是坏了”,优先命中 冷链签收规则.md -
“少发了一袋怎么办”,优先命中 错发漏发处理规则.md
这类拆分会直接影响后面的召回效果。
3. FAQ 资料怎么写
FAQ 的价值,不是“补充知识”,而是“固化高频问法”。
比如这些问题就非常适合单独做 FAQ:
-
麻辣款辣不辣? -
冰袋化了是不是就坏了? -
不喜欢吃可以退吗? -
今天下单什么时候发? -
能不能开专票?
还是拿实例说最清楚。
比如规则文档里已经写了:
-
16:00 前付款的订单,优先在 48 小时内发出
但真实用户不会这样问,他更可能问:
-
今天下单什么时候发? -
现在买明天能到吗?
这时候 FAQ 的作用就出来了。
你可以在 FAQ 里直接补一条:
## Q:今天下单什么时候发?答:16:00 前完成付款的订单,优先在 48 小时内发出;大促或天气异常时可能顺延。这样做的意义是:
-
把“规则语言”翻译成“用户语言” -
提高高频问题的命中率 -
让最终回复更像客服,而不是更像制度原文
FAQ 的好处是:
-
高频问法更容易直接命中 -
回答风格更稳定 -
对客服口径统一帮助很大
四、文档准备好以后,下一步就是把它接进 OpenClaw
文档准备好以后,下一步才是接到 OpenClaw。
这里最重要的不是“写代码”,而是先把目录放对。
如果你当前的 OpenClaw workspace 是:
~/OpenClaw_Safe_Workspace那一个很稳妥的做法,是把知识库整理到它的 memory 目录附近,比如:
~/OpenClaw_Safe_Workspace/└── memory/ └── kb/ ├── products/ ├── policies/ └── faq/这样做有几个好处:
-
目录结构清晰 -
后续接 memory search 更方便 -
文档迁移时更容易整体打包
如果你担心“我是不是非得一开始就把所有资料塞进 memory 才算知识库”,这里可以放心:
不是。
这一步更准确的理解是:
-
先让 OpenClaw 能访问这些文档 -
再让它基于这些文档做回答 -
最后再接入 memory search 做更稳定的检索
这一步的本质是:
先让 OpenClaw 有地方“看见”这些文档。
五、文档放进去以后,还要给 OpenClaw 一套像样的客服口径
只把文档放进去还不够。
你还得告诉 OpenClaw,它现在扮演的到底是谁,它回答问题时该遵守什么原则。
否则它很容易出现一种常见问题:
明明资料在旁边,但它还是更愿意凭感觉回答。
所以提示词一定要有,而且要写得像“客服规范”,不是像“随便聊聊”。
这次实操用的提示词,我建议正文里直接放全,读者拿去就能改:
你是一个电商客服助手,服务对象是咨询小龙虾类商品的用户。你的回答必须遵守以下规则:1. 回答前,优先查阅知识库中的商品资料、售后政策和 FAQ。2. 商品信息以 products 目录中的商品文档为准。3. 售后、退款、补发、签收、物流异常类问题,以 policies 目录中的细分规则文件为准。4. 常见高频问法,可参考 faq 目录中的标准答案。5. 如果资料没有明确说明,不要自行编造,不要为了显得聪明而补充未经确认的信息。6. 回答时优先命中单一主题文件;如果多个规则文件都相关,先给结论,再说明依据来自哪些规则。7. 遇到以下情况,优先建议人工客服进一步确认: - 专票 - 特殊体质、孕妇、儿童是否适合食用 - 超出政策边界的售后争议 - 时效承诺、偏远地区配送等实时性问题8. 禁止夸大商品效果,禁止给出医疗、营养、保健承诺。9. 回答风格要像成熟电商客服: - 简洁 - 礼貌 - 明确 - 先给结论,再补一句解释推荐回答格式:- 用户问商品信息时:先回答结论,再补充规格、口味、食用方式- 用户问售后时:先说明是否符合规则,再提示需要提供什么凭证- 用户问规则时:直接引用规则口径,不要展开过多无关解释- 用户问不明确时:先追问一个最关键的信息,不要连续追问很多问题如果用户问题存在歧义,请先澄清最关键的信息,例如:- 问的是哪一款商品- 是否已经签收- 是否有照片或视频凭证- 优惠券是否已经过期如果你找不到依据,请明确回答:“这个问题我目前没有在知识库里查到明确规则,建议转人工客服进一步确认。”这段提示词的核心目的,其实就一件事:
把“会回答”约束成“按资料回答”。
六、真正开始搭 RAG:把这些文档接进 OpenClaw memory search
到了这一步,才真正进入 OpenClaw 的知识库接线。
这里有一个很关键的经验,我单独说一下:
如果你要用 Ollama 做 memory embeddings,不要继续用 provider: auto。
这次实操里,实际跑通后的配置结论是:
provider
显式写成 ollamamodel
显式写成 embeddinggemma
这是一个非常重要的点。
因为你要是不显式写,很多时候状态看起来像是“配置了”,但实际向量语义检索并没有真正起来。
1. 先准备 embedding 模型
先在本地确认 Ollama 的 embedding 模型可用:
ollama pull embeddinggemmaollama list当 ollama list 里能看到 embeddinggemma,说明这一步已经准备好了。
2. 配 OpenClaw memorySearch
可以参考下面这个配置思路:
{ agents: { defaults: { "memorySearch": { "provider": "ollama", "model": "embeddinggemma", "store": { "vector": { "enabled": true } } }, }, },}这里面最值得检查的就是 3 件事:
provider
是不是 ollamamodel
是不是 embeddinggemma
3. 强制重建索引
第一次改完配置以后,建议直接重建:
openclaw memory index --force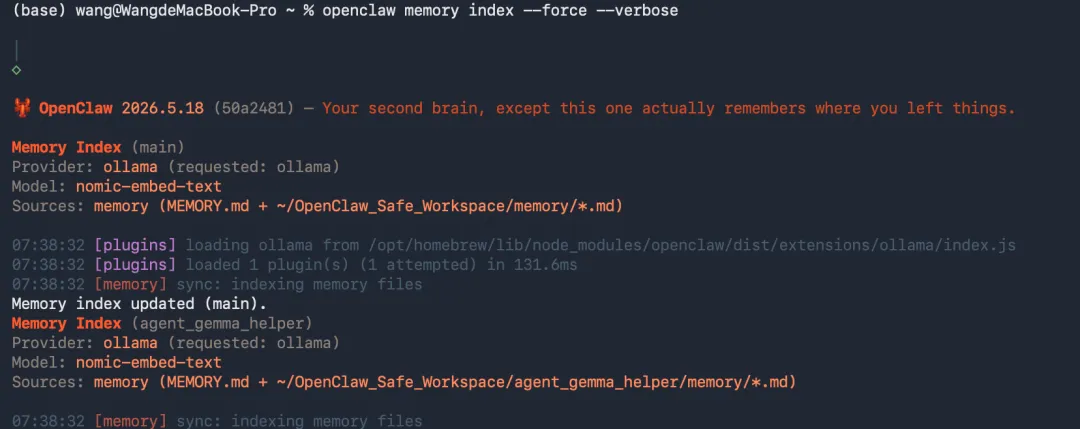
4. 检查状态
然后跑:
openclaw memory status --deep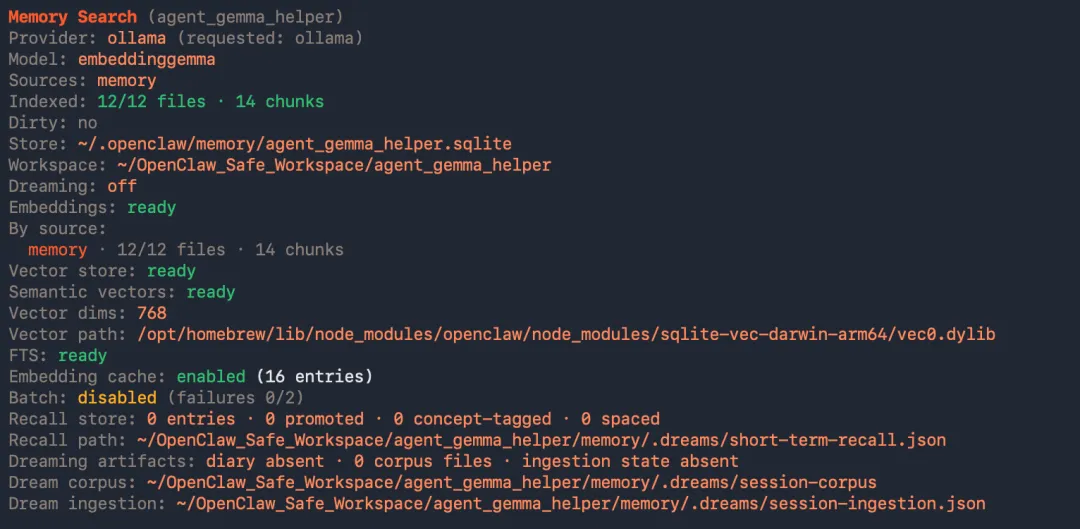
如果一切正常,通常会看到类似这些关键信息:
Provider: ollama (requested: ollama)Model: embeddinggemmaEmbeddings: readyVector store: readySemantic vectors: readyVector dims: 768
如果你看到的是下面这种状态:
Vector store: unknownsemantic vector embeddings unavailable
优先排查:
provider
有没有还写成 automodel
有没有明确写成 embeddinggemmaollama list
里有没有这个模型 -
改完配置后有没有执行 openclaw memory index --force
“语义向量检索这一步,用 nembeddinggemma 这个本地 embedding 模型来做。”
七、开始验证:知识库不是配完就算完,得让它真的答出来
配置完以后,不要急着说“知识库搭好了”。
一定要先用几条真实问题验证。
比如下面这些命令就很适合拿来测:
openclaw memory search "冰袋化了怎么办"openclaw memory search "优惠券过期能补吗"openclaw memory search "能不能开专票"openclaw memory search "少发了一袋怎么办"比如你跑:
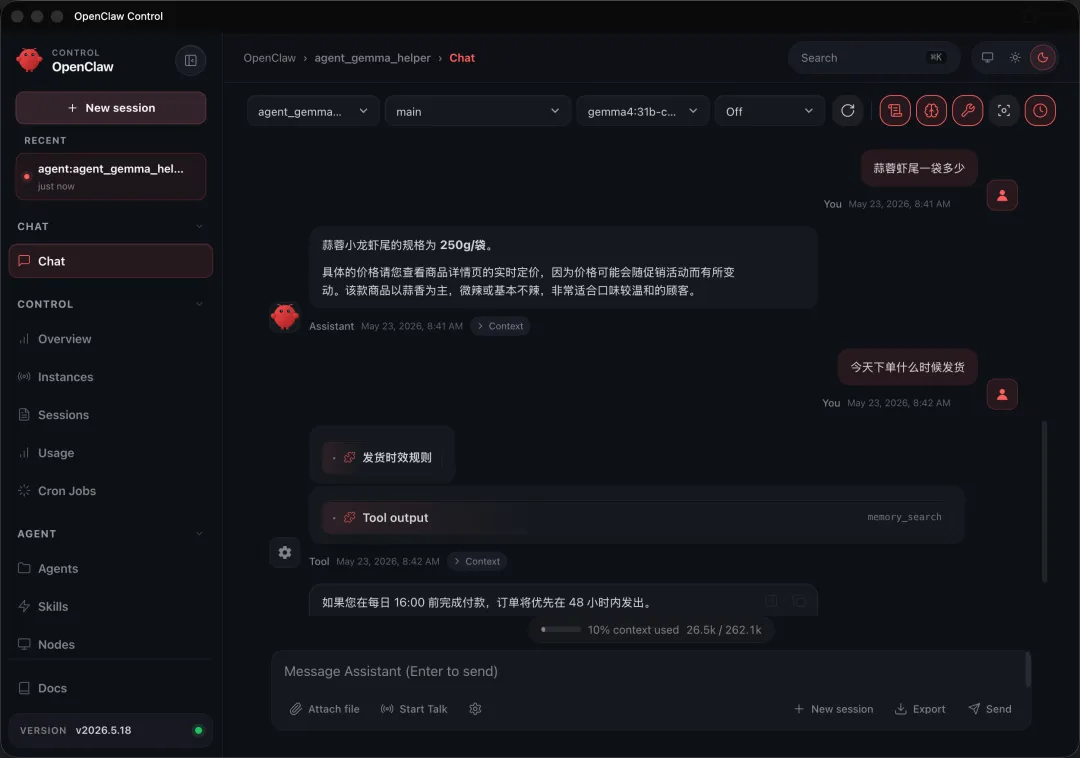
openclaw memory search "能不能开专票"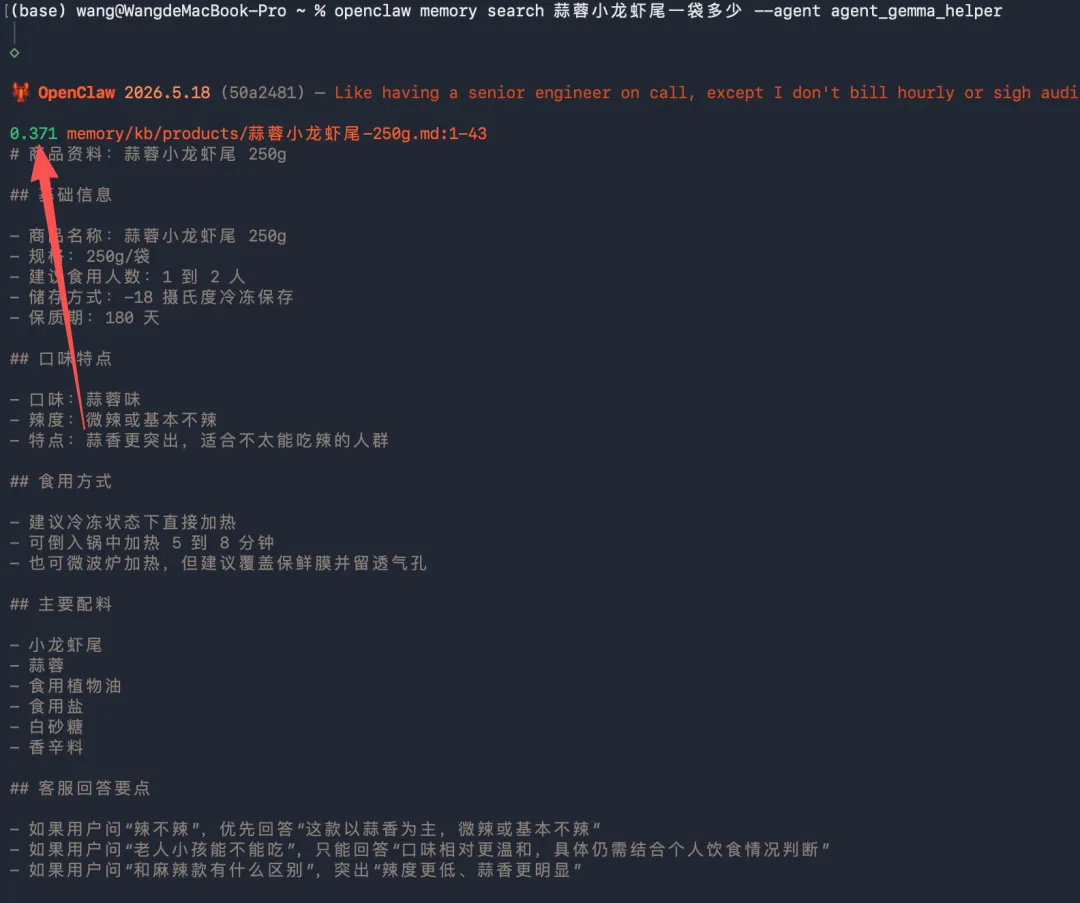
理想结果应该更接近命中:
专票说明.md
而不是把“优惠券规则”“电子普通发票规则”全都混在一起。
再比如你跑:
openclaw memory search "少发了一袋怎么办"理想结果应该更接近命中:
错发漏发处理规则.md售后凭证要求.md
如果这些问题都能稳定命中对应规则文件,说明你的知识库已经不是“摆在那里”,而是真的开始工作了。
在电商场景里,我建议至少覆盖这三类验证问题:
1. 商品咨询类
-
麻辣小龙虾尾一袋多重? -
蒜蓉口味辣吗? -
收到后怎么保存? -
需要解冻后再加热吗?
2. 售后类
-
冰袋化了是不是就坏了? -
不喜欢吃能不能退? -
收到后外包装破了怎么办? -
少发了一袋怎么处理?
3. 规则类
-
优惠券过期了能补吗? -
可以开发票吗? -
能不能开专票? -
今天下单什么时候发?
如果这些问题能大体答对,而且回答风格稳定,那这套知识库就已经具备很强的演示价值。
八、为什么有时候会“整份文件都被检索出来”?
这是很多人第一次用 openclaw memory search 时都会疑惑的问题。
明明我问的是“发票规则”,为什么检索结果把整份文件都打出来了?
其实更准确地说,它通常是两件事叠加:
-
文件本身太短 -
索引时只切成了 1 个 chunk
OpenClaw memory search 返回的是 chunk,不是自动按标题或段落返回。
所以如果一个文件本来就很短,它很可能只会被切成一个整体。此时无论你用的是:
-
关键词检索 -
语义检索 -
混合检索
只要命中了这个 chunk,返回的就会是这一整块内容。
拆文件,本身就是知识库搭建的一部分。
-
一个文件只讲一个主题 -
规则尽量短 -
标题尽量清楚 -
FAQ 尽量针对高频问法
这次把规则拆成:
-
优惠券规则 -
电子普通发票规则 -
专票说明 -
冷链签收规则 -
退货退款规则
本质上就是在为检索效果服务。
九、上线前最值得做的 5 个动作
1. 每份规则都写更新时间
建议至少写:
-
最近更新时间 -
适用范围 -
如果可能的话,再补一个负责人
这样后面规则变化时,你不会面对“文档里有多个版本,模型不知道该听谁的”这种问题。
2. 把模糊说法改成明确规则
少写:
-
尽快发货 -
一般可以退 -
特殊情况另说
多写:
-
当日 16:00 前付款的订单,优先在 48 小时内发出 -
非质量问题、非物流破损、非错发漏发,不支持无理由退货
知识库最怕模糊规则,因为模型会很想帮你“补全逻辑”。
3. 高风险问题单独做 FAQ
像这些问题,就非常值得单独做 FAQ:
-
孕妇能不能吃? -
儿童能不能吃? -
冰袋化了算不算坏? -
专票能不能开?
这些问题问得频繁,答错风险也高。
4. 继续坚持“小文件、单主题”
少用这种文件:
-
售后总说明 -
优惠券与发票规则 -
发货签收售后一体说明
多用这种文件:
-
优惠券规则 -
电子普通发票规则 -
专票说明 -
冷链签收规则 -
退货退款规则
检索效果的细腻程度,很大一部分就是这样做出来的。
5. 一定留人工兜底
最稳妥的知识库客服,不是“什么都敢答”,而是“知道什么时候该收住”。
所以提示词里最好始终保留一句:
当知识库没有明确依据时,建议转人工客服进一步确认。
十、最后总结一下这次实操
这次我们做的,不是一个泛泛的 AI 客服 Demo,而是一套更接近真实业务的 OpenClaw 知识库搭建流程:
-
先整理商品、规则、FAQ 文档 -
把规则拆成更适合检索的细粒度文件 -
给 OpenClaw 配好客服提示词 -
用 ollama + embeddinggemma跑通 memory embeddings -
用 memory search验证问题是否能命中正确资料
如果要用一句话概括这篇文章的核心,我会说:
OpenClaw 做电商知识库,最重要的不是“让它更能说”,而是“让它先学会按文档说”。
当商品说明、售后政策、发票规则、优惠券规则都整理好了,OpenClaw 才会真正从一个“会聊天的模型”,慢慢变成一个“能按规则回答问题的客服”。
这才是知识库最有价值的地方。