 夜雨聆风
夜雨聆风





OpenClaw 72小时狂飙6万星,但科研人最想要的功能它没有
72小时,64000颗星
这是 OpenClaw 在 GitHub 上创造的增长神话。这个由 PSPDFKit 创始人 Peter Steinberger 开发的开源 AI agent,让全球开发者疯狂——它能接管你的电脑,帮你整理文件、回复消息、预订餐厅,甚至自动处理保险索赔。
但如果你是科研人员,你可能会发现一个尴尬的事实:
这玩意儿,跟你的科研工作几乎没关系。
它能帮你订机票,但不能帮你下载 Nature 的付费论文。它能整理桌面文件,但不能帮你解析论文里的图表和公式。它能 7×24 小时工作,但它不知道你在研究什么,更不可能帮你跑实验、验证假设。
于是我开始想:如果有一个专门为科研设计的 agent——暂且叫它 ResearchClaw——它应该长什么样?

30秒了解 OpenClaw
先简单介绍一下 OpenClaw 是什么,方便后面理解为什么它不适合科研。

OpenClaw(原名 Clawdbot,后改名 Moltbot,2026年1月正式更名)是一个本地优先的开源 AI agent。核心特点:
-
• 本地运行:完全跑在你自己的电脑上,数据不外流 -
• 多渠道集成:WhatsApp、Telegram、Discord、Slack、iMessage 都能接入,统一控制 -
• 持久记忆:用 Markdown 文件保存所有对话历史,不像 ChatGPT 每次从零开始 -
• 自主执行:不只是给建议,而是真的帮你干活——预订餐厅、发邮件、执行 shell 命令 -
• 开源免费:MIT 许可证,自带 API key 就能用
说白了,它是一个能操控你电脑的 AI 管家,帮你处理日常杂事。
但科研不是杂事。
为什么科研需要一个专属 agent?
刘震云在新书《咸的玩笑》扉页写道:
“世界各地,不同的街道上,街上走着的每个人,内心都有伤痕。大家都辛苦了。”

我读到这句话时,第一反应想到的是我的硕士和博士过往生涯。
那时候,朝九晚十二、通宵熬夜,每天宿舍和实验室两点一线。跑不出结果的实验,改了又改的论文,遥遥无期的毕业,以及内心还需要承受长时间不出成果而内心快乐不起来的负担。
我也想对曾经的自己和现在的你们说一句:大家真的辛苦了。

而正因为辛苦,效率才更重要。
时间不应该浪费在重复性劳动上——手动下载论文、反复调试环境、一遍遍跑相似的实验。这些事情,应该有工具来帮你分担。我觉得这也正是Ai出现的意义之一。
科研工作流和日常事务有本质区别,我们科研人员的真实痛点:
痛点一:文献获取,AI 的阿喀琉斯之踵
你用 ChatGPT 或 Claude 搜论文,有没有发现一个问题?它们只能看到摘要。为什么?因为大部分论文都在付费墙后面,云端 AI 没有你的机构 IP,下载不了全文。
结果就是:AI 只能基于摘要给你”建议”,但摘要里没有方法细节、没有实验数据、没有图表。你还是得自己下载、自己读。
OpenClaw 虽然跑在本地,但它没有专门的文献检索模块,更没有 PDF 深度解析能力。
痛点二:论文不是文本,是结构化知识
一篇论文里有什么?标题、摘要、正文、图表、公式、表格、参考文献。
普通 AI 看论文 PDF,基本就是”看图说话”——OCR 识别一下文字,图表和公式?看不懂。
但科研人员要的不是”这篇论文讲了什么”,而是:
-
• 图3的实验数据能不能复现? -
• 公式(7)的推导有没有问题? -
• 表2的对比实验用了什么 baseline?
这需要专业的 PDF 解析能力——能提取图表、识别公式、结构化表格。OpenClaw 没有集成这类工具。
痛点三:科研是个闭环,不是单点任务
OpenClaw 擅长的是单点任务:订餐厅、发邮件、整理文件。
但科研是一个闭环:
-
1. 提出假设 -
2. 搜索文献验证假设是否有人做过 -
3. 设计实验 -
4. 写代码跑实验 -
5. 分析数据 -
6. 写论文
这 6 个环节是串联的,前一步的输出是后一步的输入。一个科研 agent 需要理解你的研究方向,在整个闭环中持续协助。
OpenClaw 的记忆系统虽然能存对话历史,但它不懂什么是”研究方向”,更不会帮你跟踪领域前沿。
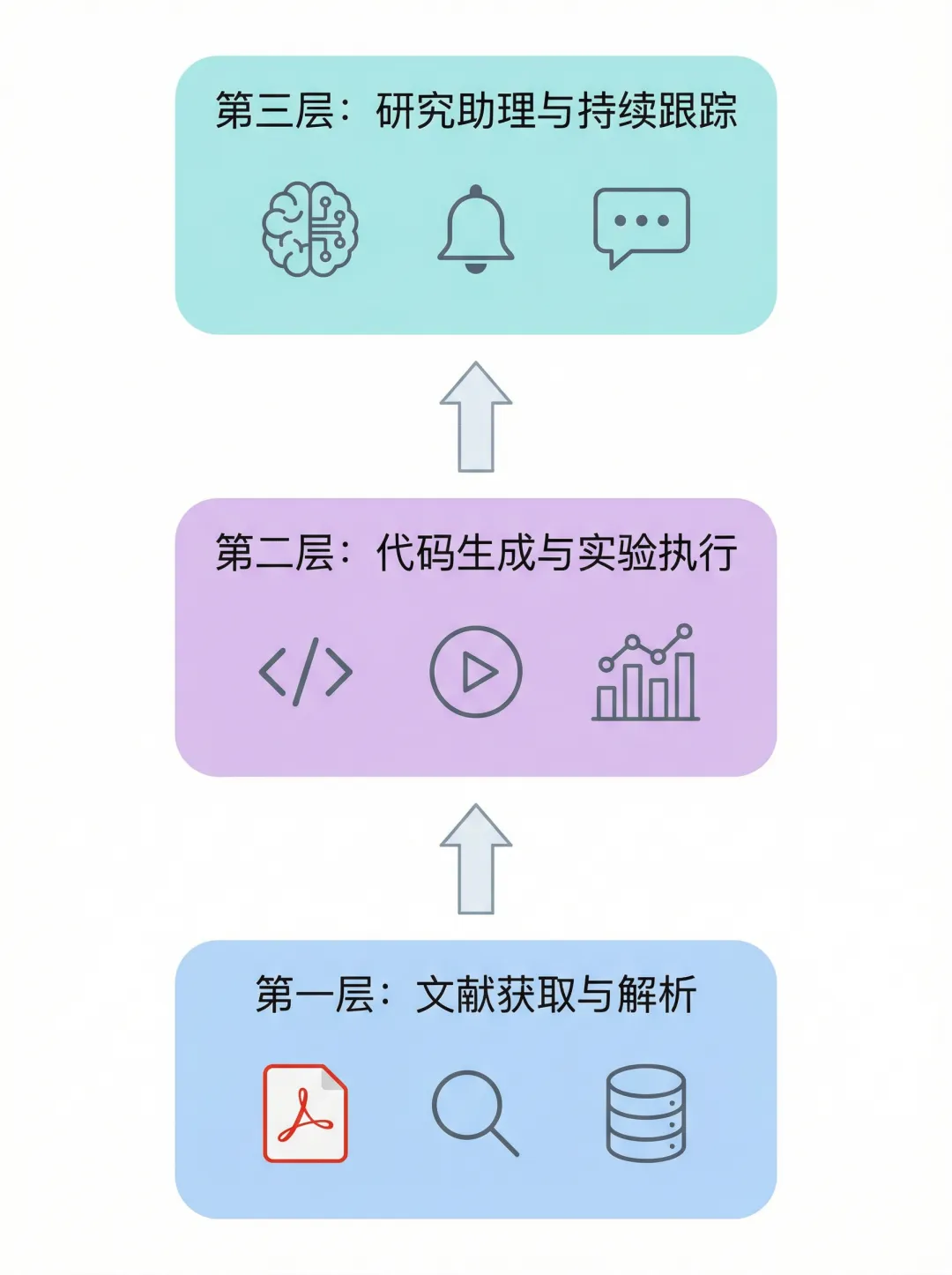
ResearchClaw:我的三层设计思路
基于这些痛点,我设想的 ResearchClaw 应该有三层能力:
第一层:文献全文获取 + 深度解析
这是最基础也是最关键的一层。
核心能力:
-
• 用本地 IP 自动下载付费论文(通过机构 VPN ) -
• 定时任务跟踪 arXiv、bioRxiv 等预印本平台的最新论文 -
• 深度解析 PDF,提取图表、公式、表格 -
• 建立本地知识库,支持语义检索
为什么这一层重要?
云端 AI 只能看摘要,但 ResearchClaw 能看全文。它能告诉你:”这篇论文的图3显示,当学习率设为0.001时,模型在验证集上的 F1 分数是 0.87″——而不是”这篇论文研究了模型性能”。
这是从”泛泛而谈”到”精准分析”的质变。
第二层:代码生成 + 实验执行
光能读论文不够,还得能跑实验。
核心能力:
-
• 参考论文和开源代码,自动生成实验代码 -
• 接入代码执行环境(比如本地 Python 或云端 GPU) -
• 自动运行实验、收集数据、生成可视化报告 -
• 支持参数调优和多组对比实验
科研 agent 必须能从读到做,形成闭环。接入代码执行环境(比如 Jupyter、本地 Python 或云端 GPU)是关键。
想象一下这个场景:
你跟 ResearchClaw 说:”帮我复现这篇论文的 Table 2 实验”。
它会:
-
1. 解析论文,提取实验配置(数据集、超参数、评估指标) -
2. 搜索 GitHub 找到相关开源实现 -
3. 自动配置环境、下载数据集 -
4. 运行实验,生成对比报告 -
5. 告诉你:复现结果和原论文差了 2.3%,可能原因是…
这个效率提升是数量级的。
省下来的时间,你可以用来思考更本质的问题,或者——早点回去休息。
第三层:研究助理 + 持续跟踪
最高层是成为你的”AI 研究伙伴”。
真正的帮助,不是替你做事,而是理解你在做什么。
核心能力:
-
• 理解你的研究方向和当前进展 -
• 定时监控领域内的新论文,主动推送相关内容 -
• 帮你整理文献笔记、生成综述大纲 -
• 参与研究讨论,提出假设和改进建议
这一层需要深度定制。每个研究者的方向不同,ResearchClaw 需要”了解你”——你在做什么课题、用什么方法、遇到什么瓶颈。
OpenClaw 的记忆系统可以借鉴,但需要针对科研场景重新设计。
我们已经在路上了
你可能会说:想法是挺好,但这不就是画饼吗?
还真不是。我们团队已经在做一些开发工作了。
ResearchClaw 的完整版还在开发中,但很多单点能力,你现在就可以用起来。
我们在扣子(Coze)平台上做了一系列科研工具(扣子Skills上线,科研场景的第一批实践!),覆盖了科研工作流的多个环节:
文献检索
|
|
|
|---|---|
| arXiv 论文搜索 |
|
| bioRxiv 预印本 |
|
| PubMed 文献检索 |
|
| Ai4S 文献搜索 |
|
| Ai4S 全文搜索 |
|
写作辅助
|
|
|
|---|---|
| JCR 影响因子查询(投稿推荐) |
|
| 学术图表绘制 |
|
| 科研统计分析 |
|
这些工具已经帮很多科研人把效率提升了好几倍。(详细介绍见我之前的文章Science第一作者的科研扣子Skills)
打开扣子 App,搜索”arXiv”、”PubMed”、”Ai4S”就能找到。
更多工具整合在 ai4scholar.net 上,欢迎关注(Ai4Scholar 是什么?)。
不能忽视的风险:安全问题
说完了美好愿景,也得泼盆冷水。
OpenClaw 刚爆火没多久,就曝出了严重的安全漏洞:超过 900 个用户的网关暴露在公网上,API 密钥、聊天记录、文件传输记录都可能被窃取。
问题出在反向代理配置。OpenClaw 默认信任本地请求,但如果你用 Nginx 做反向代理,又没有正确配置 trustedProxies,所有外部请求都会被当成”本地可信”。
对于科研场景,这个风险更大。
你的 ResearchClaw 里可能存着:
-
• 未发表的研究数据 -
• 论文草稿 -
• 实验代码 -
• 机构 VPN 凭证
一旦泄露,后果不堪设想。
所以如果你要自己搭建 OpenClaw,务必注意:
-
1. 不要在主力电脑上运行,用隔离的虚拟机或容器 -
2. 启用密码验证( gateway.auth.mode: "password") -
3. 正确配置可信代理列表 -
4. 用 Tailscale 或 Cloudflare Tunnel 替代直接暴露端口 -
5. 定期更换 API 密钥
总结:三个核心要点
1. OpenClaw 很强,但不是为科研设计的
它擅长日常事务自动化,但科研需要的文献获取、PDF 解析、实验执行、研究跟踪,它都不具备。
2. ResearchClaw 的三层架构是可行的
第一层:文献全文获取 + PDF 深度解析
第二层:代码生成 + 实验自动执行
第三层:AI 研究伙伴 + 持续跟踪
技术上,各个模块都有成熟的开源方案,整合是可行的。
3. 安全问题不能忽视
OpenClaw 已经曝出严重漏洞,科研场景的数据更敏感,务必做好隔离和防护。
写在最后
这篇文章是我对 ResearchClaw 的初步设想,刚开始动手实现。
有人说,科研是一场漫长的马拉松,而大多数人在看不到终点的时候就已经筋疲力尽。长期没有成果的焦虑、同行竞争的压力、对未来的迷茫——这些内心的伤痕,只有经历过的人才懂。
工具不能替你思考,但可以帮你节省时间去思考更重要的事。
当 AI 已经能自动生成被顶会录用的论文,当 PDF 解析技术已经能精准提取图表和公式,当 OpenClaw 已经证明了本地 agent 的可行性——把这些能力整合起来,打造一个 7×24 小时帮你做科研的 AI 伙伴,只是时间问题。
科研的本质是探索未知,而不是在已知的重复劳动中消耗生命。
如果 ResearchClaw 能帮你省下哪怕 20% 的时间,让你多睡一小时、多陪一次家人、多一点思考的空间——那它就是值得做的。
如果你也对这个方向感兴趣,评论区聊聊。
我想听听你的想法:
-
1. 你觉得 ResearchClaw 最应该先实现哪个功能? -
2. 你在科研中最痛的点是什么? -
3. 如果真做出来,你愿意尝试吗?
说不定,我们可以一起把它做出来。
科研朋友们,大家都辛苦了。
相关链接:
-
• OpenClaw GitHub: github.com/moltbot/clawdbot -
• Ai4Scholar 官网: ai4scholar.net -
• 扣子技能(在 Coze App 搜索即可使用): -
• arXiv 论文搜索 -
• bioRxiv 预印本 -
• PubMed 文献检索 -
• Ai4S 文献搜索 -
• Ai4S 全文搜索 -
• JCR 影响因子查询 -
• 学术图表绘制 -
• 科研统计分析
Ai4Scholar 团队