夜雨聆风
夜雨聆风近年来,深度监督学习取得了巨大的成功。然而,它依赖于手工标签,并且易受攻击的弱点促使学者们探索更好的解决方案。近年来,自监督学习作为一种新的学习方法,在表征学习方面取得了骄人的成绩并吸引了越来越多的注意。自监督表示学习利用输入数据本身作为监督信号,几乎有利于所有不同类型的下游任务。本期前沿解读,我们解读清华大学唐杰老师组发表的Self-supervised Learning: Generative or Contrastive 一探自监督学习最新研究进展。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),也欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

Self-supervised Learning: Generative or Contrastive https://www.zhuanzhi.ai/paper/dc7c6f502891013f8f735c76105d249e
本文主要介绍自监督学习在计算机视觉,自然语言处理,和图学习领域的方法,并对现有的方法进行了全面的回顾,根据不同方法的目标归纳为生成式(generative)、对比式(contrastive)和对比-生成式 / 对抗式(adversarial)三大类。最后,简要讨论了自监督学习的开放问题和未来的发展方向。
Introduction
监督学习在过去取得了巨大的成功,然而监督学习的研究进入了瓶颈期,因其依赖于昂贵的人工标签,却饱受泛化错误(generalization error)、伪相关(spurious correlations)和对抗攻击(adversarial attacks)的困扰。自监督学习以其良好的数据利用效率和泛化能力引起了人们的广泛关注。本文将全面研究最新的自监督学习模型的发展,并讨论其理论上的合理性,包括预训练语言模型(Pretrained Language Model,PTM)、生成对抗网络(GAN)、自动编码器及其拓展、最大化互信息(Deep Infomax,DIM)以及对比编码(Contrastive Coding)。自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。下图展示了两者之间的区别,自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。
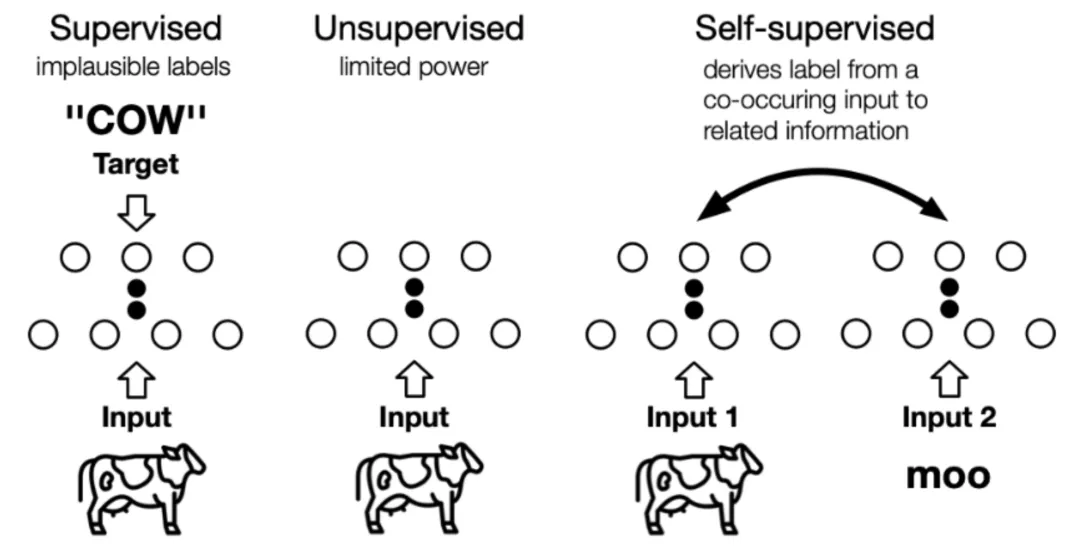
图1:监督、无监督和自监督学习的区别 (Image source:Jie Tang et al.)
Generative Self-supervised Learning 生成式自监督学习
Auto-regressive (AR) Model
在自回归模型中,联合分布可以被分解为条件的乘积,每个变量概率依赖于之前的变量:
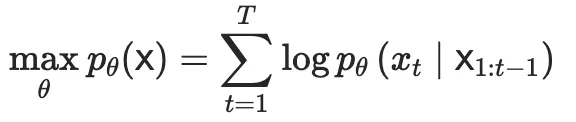
在自然语言处理中,自回归语言模型的目标通常是最大化正向自回归因子分解的似然。例如 GPT、GPT-2 使用 Transformer 解码器结构进行建模;在计算机视觉中,自回归模型用于逐像素建模图像,例如在 PixelRNN 和 PixelCNN 中,下方(右侧)像素是根据上方(左侧)像素生成的;而在图学习中,则可以通过深度自回归模型来生成图,例如 GraphRNN 的目标为最大化观察到的图生成序列的似然。自回归模型的优点是能够很好地建模上下文依赖关系。然而,其缺点是每个位置的 token 只能从一个方向访问它的上下文。
Auto-encoding (AE) Model
自动编码模型的目标是从(损坏的)输入中重构(部分)输入。标准的自动编码器,首先一个编码器 对输入进行编码得到隐表示 ,再通过解码器 重构输入,目标是使得输入 和 尽可能的相近。
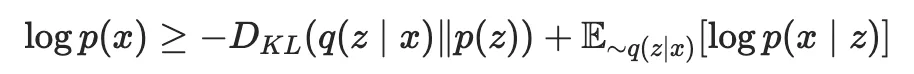
Hybrid model
结合 AR 模型和 AE 模型的各自优点,MADE 模型对 AE 做了一个简单的修改,使得 AE 模型的参数遵循 AR 模型的约束。具体来说,对于原始的 AE,相邻两层之间的神经元通过 MLPs 完全连接。然而,在 MADE 中,相邻层之间的一些连接被 mask 了,以确保输入的每个维度仅从之前的维度来重构。
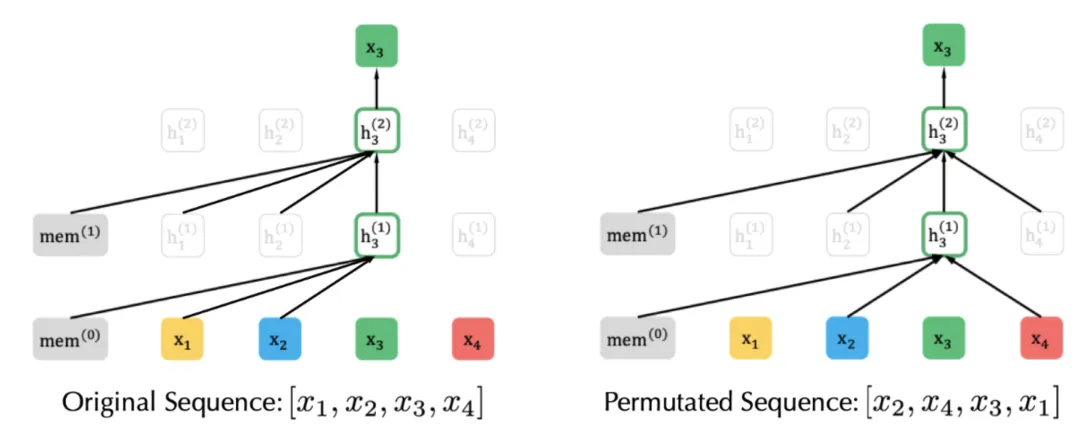
图2:PLM实例示意图. (Image source: Z Yang et al.)
在 NLP 领域中,PLM(Permutation Language Model )模型则是一个代表性的混合方法,XLNet 引入 PLM,是一种生成自回归预训练模型。XLNet 通过最大化因数分解顺序的所有排列的期望似然来实现学习双向上下文关系(见图 )。具体的,假设 是长度为 的所有可能的序列排序,则 PLM 的优化目标为:
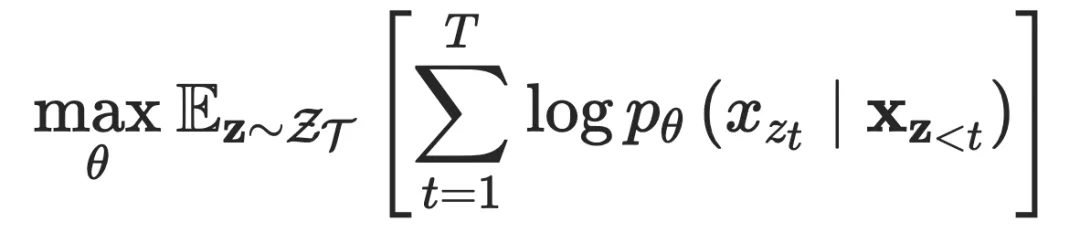
实际上,对于每个文本序列,都采样了不同的分解因子。因此,每个 token 都可以从双向看到它的上下文信息。在此基础上,XLNet 还对模型进行了位置重参数化,使模型知道需要预测的位置,并引入了特殊的双流自注意机制来实现目标感知预测。此外,与 BERT 不同的是,XLNet 受到 AR 模型最新改进的启发,提出了结合片段递归机制和相对位置编码机制的 Transformer-XL 集成到预训练中,比 Transformer 更好地建模了长距离依赖关系。
Contrastive Self-supervised Learning 对比式自监督学习
大多数表示学习任务都希望对样本 之间的关系建模。因此长期以来,人们认为生成模型是表征学习的唯一选择。然而,随着 Deep Infomax、MoCo 和 SimCLR 等模型的提出,对比学习(contrastive learning) 取得了突破性进展,如图 3 所示,在 ImageNet 上,自监督模型的 Top-1 准确率已经接近监督方法(ResNet50),揭示了判别式模型的潜力。
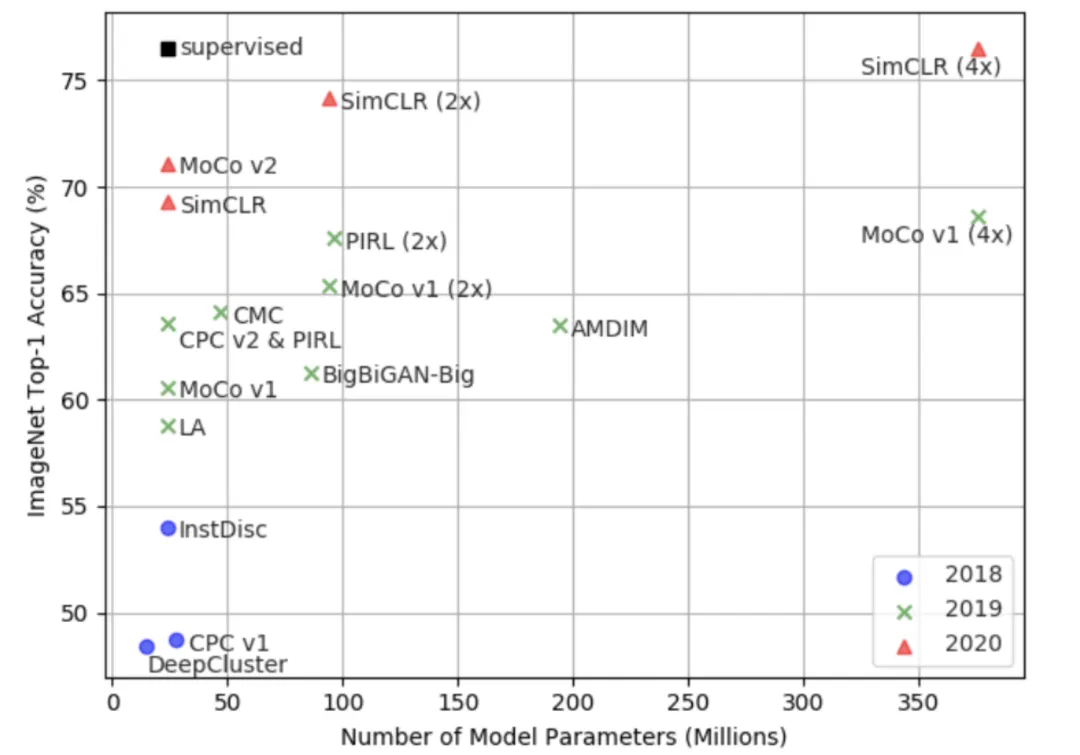
图3:自监督学习模型在 ImageNet 上 Top-1 准确率对比. (Image source: Jie Tang et al.)
对比学习的宗旨在于“learn to compare”,通过设定噪声对比估计(Noise Contrastive Estimation,NCE)来实现这个目标:
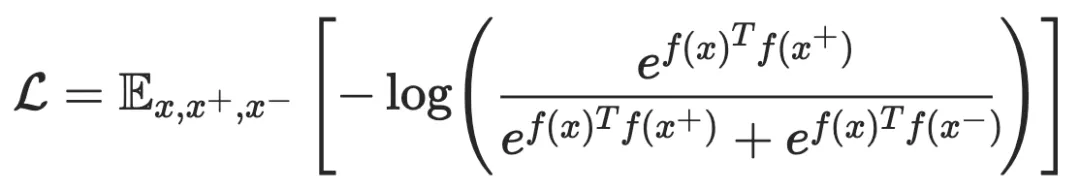
其中, 与 相似,而 与 不相似, 是编码器函数(表示学习方程)。相似度量和编码函数可能会根据具体的任务有所不同,但是整体的框架仍然类似。当有更多的不相似样本对时,我们可以得到 InfoNCE:
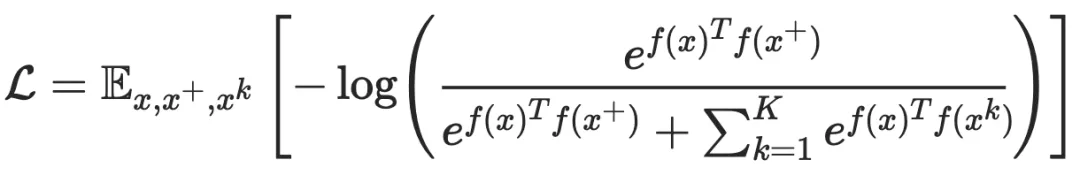
在这里,根据最近的对比学习模型框架,具体可细分为两大类:实例-上下文对比(context-instance contrast)和实例-实例对比(instance-instance contrast)。他们都在下游任务中有不俗的表现,尤其是分类任务。
Context-Instance Contrast
Context-Instance Contrast,又称为 Global-local Contrast,重点建模样本局部特征与全局上下文表示之间的归属关系,其初衷在于当我们学习局部特征的表示时,我们希望它与全局内容的表示相关联,比如条纹与老虎,句子与段落,节点与相邻节点。这一类方法又可以细分为两大类:预测相对位置(Predict Relative Position,PRP)和最大化互信息(Maximize Mutual Information,MI)。两者的区别在于:1)PRP 关注于学习局部组件之间的相对位置。全局上下文是预测这些关系的隐含要求(例如,了解大象的长相对于预测它头和尾巴的相对位置至关重要);2)MI 侧重于学习局部组件和全局上下文之间的明确归属关系。局部之间的相对位置被忽略。
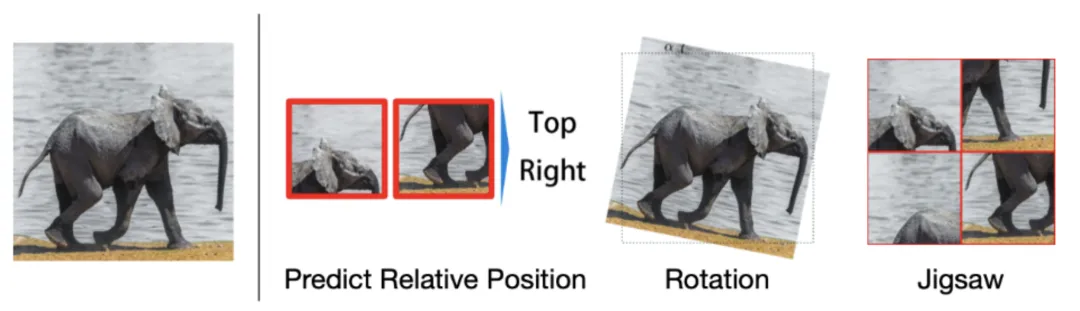
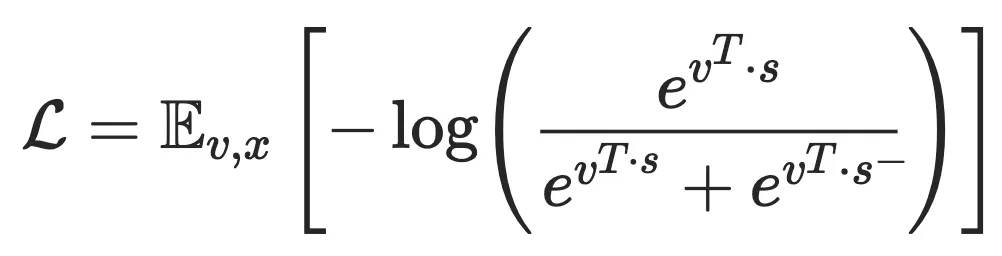
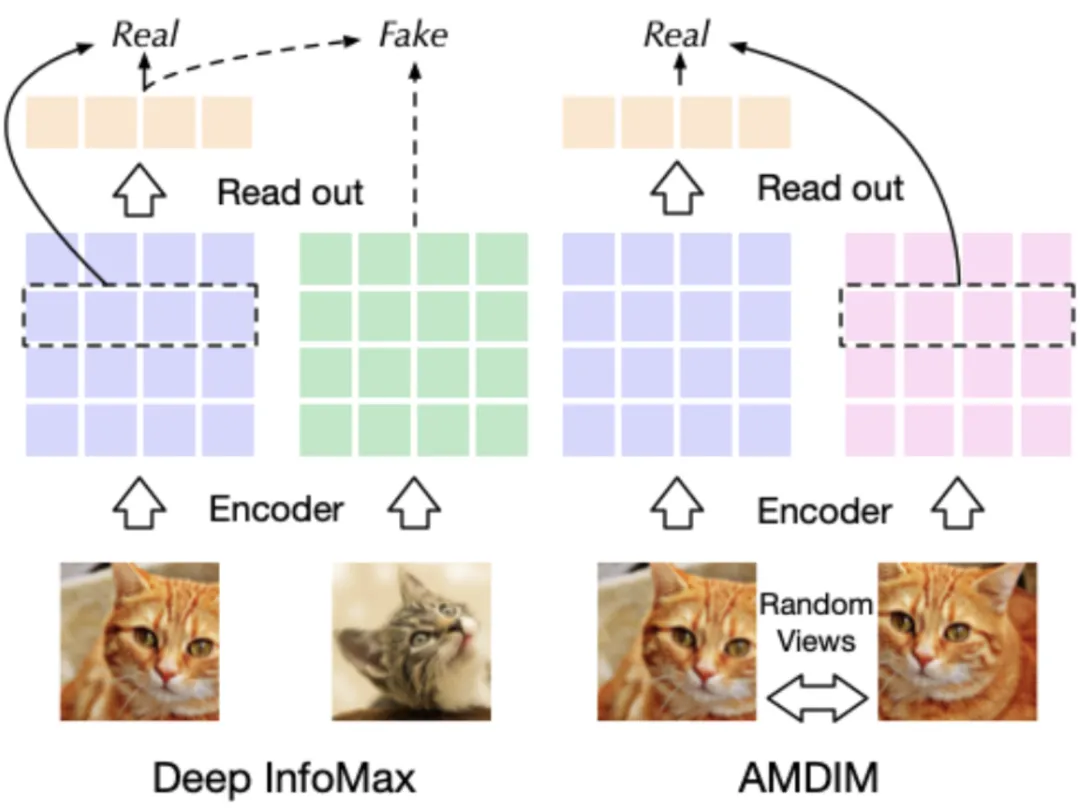
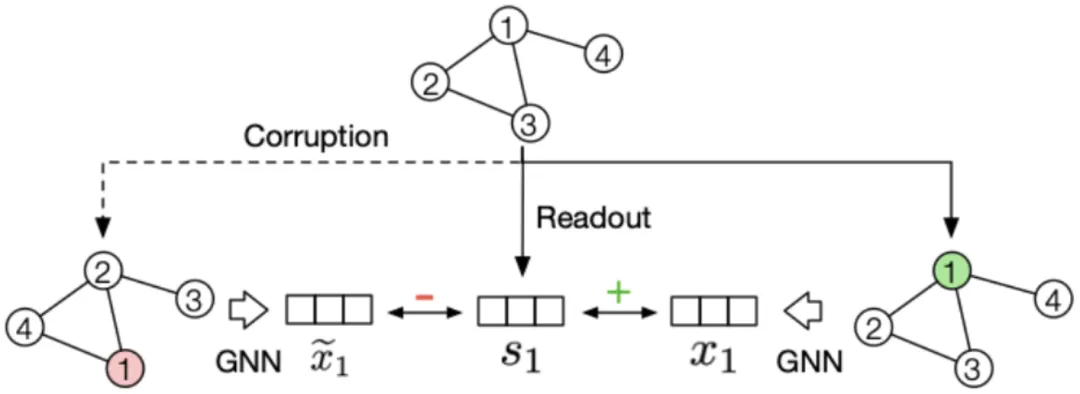
Instance-Instance Contrast
尽管基于最大化互信息的模型取得了成功,但是一些最近的研究对优化 MI 带来的实际增益表示怀疑。M Tschannen et al.证明基于最大化互信息的模型的成功与 MI 本身联系并不大。相反,它们的成功应该更多地归因于编码器架构和以及与度量学习相关的负采样策略。度量学习的一个重点是在提高负采样效率的同时执行困难样本采样(hard positive sampling),而且它们对于基于最大化互信息的模型可能发挥了更关键的作用。而最新的相关研究 MoCo 和 SimCLR 也进一步证实了上述观点,它们的性能优于 context-instance 类方法,并通过 instance-instance 级的直接对比,相比监督方法取得了具有竞争力的结果。
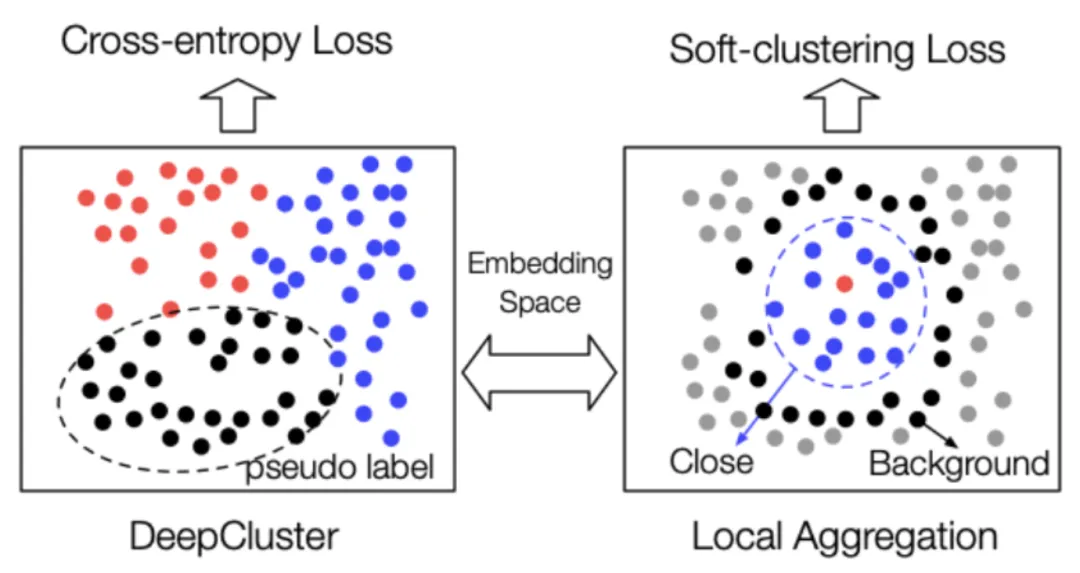
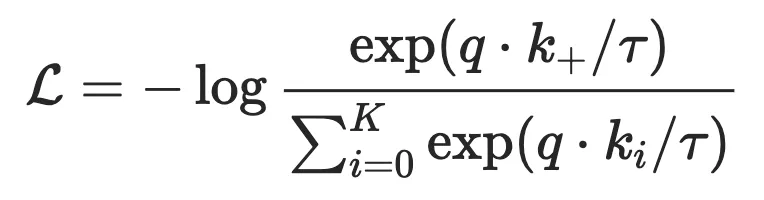
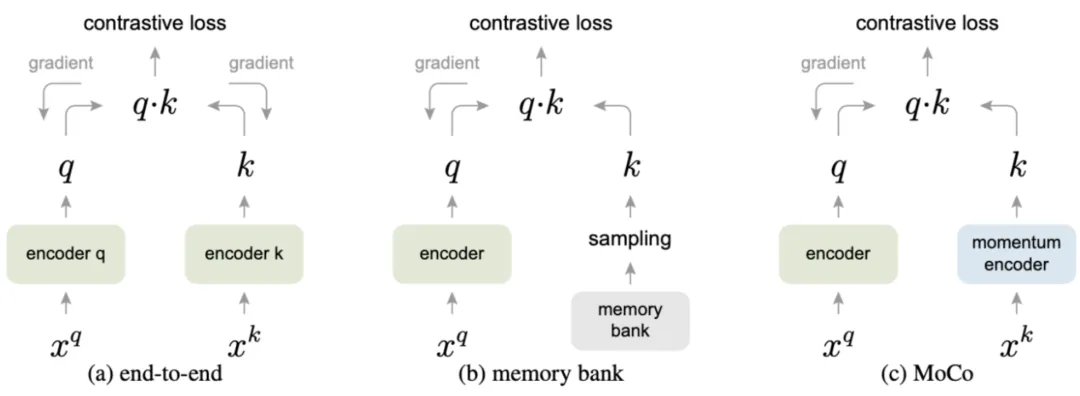

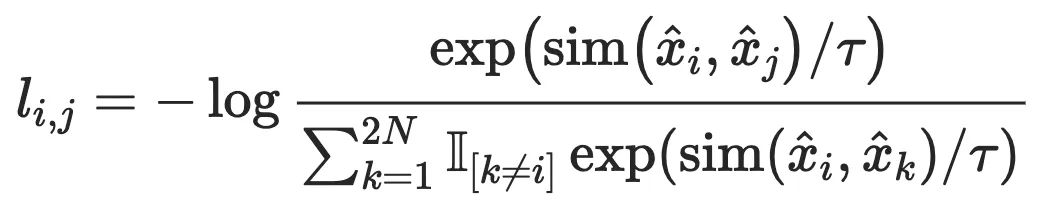
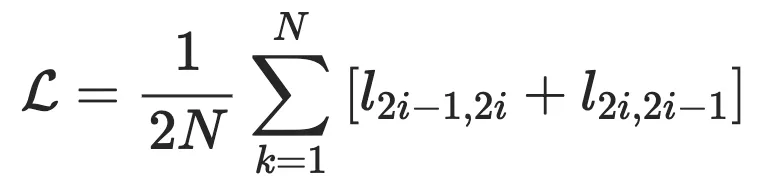
Generative-Contrastive (Adversarial) Self-supervised Learning 对比-生成式(对抗式)自监督学习
Why Generative-Contrastive (Adversarial)?
生成式模型往往会优化下面的目标似然方程:
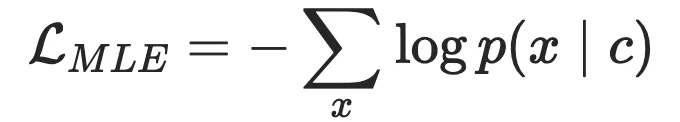
其中, 是我们希望建模的样本, 则是条件约束例如上下文信息,这个方程一般都会使用最大似然估计 MLE 来优化,然而 MLE 存在两个缺陷:
Sensitive and Conservative Distribution(敏感的保守分布):当 时, 会变得非常大,使得模型对于罕见样本会十分敏感,这会导致生成模型拟合的数据分布非常保守,性能受到限制。 Low-level Abstraction Objective(低级抽象目标):在使用 MLE 的过程中,表示分布建模的对象是样本 级别,例如图像中的像素,文本中的单词以及图中的节点。然而,大部分分类任务需要更高层次的抽象表示,例如目标检测、长段落理解以及社区分类。
以上两个缺陷严重的限制了生成式自监督模型的发展,而使用判别式或对比式目标函数可以很好的解决上述问题。以自动编码器和 GAN 为例,自动编码器由于使用了一个 pointwise 的 重构损失,因此可能建模的是样本中的 pixel-level 模式而不是样本分布,而 GAN 利用了对比式目标函数直接对比生成的样本和真实样本,建模的是 semantic-level 从而避免了这个问题。与对比学习不同,对抗学习仍然保留由编码器和解码器组成的生成器结构,而对比学习则放弃了解码器(如下图 10 所示)。这点区别非常重要,因为一方面,生成器将生成式模型所特有的强大的表达能力赋予了对抗学习; 另一方面,这也使得对抗式方法的学习目标相比与对比式方法更具挑战性,也导致了收敛不稳定。在对抗式学习的设置中,解码器的存在要求表示具有“重构性”,换句话说,表示应当包含所有必要的信息来构键输入。而在对比式学习的设置中,我们只需要学习“可区分的”信息就可以区分不同的样本。
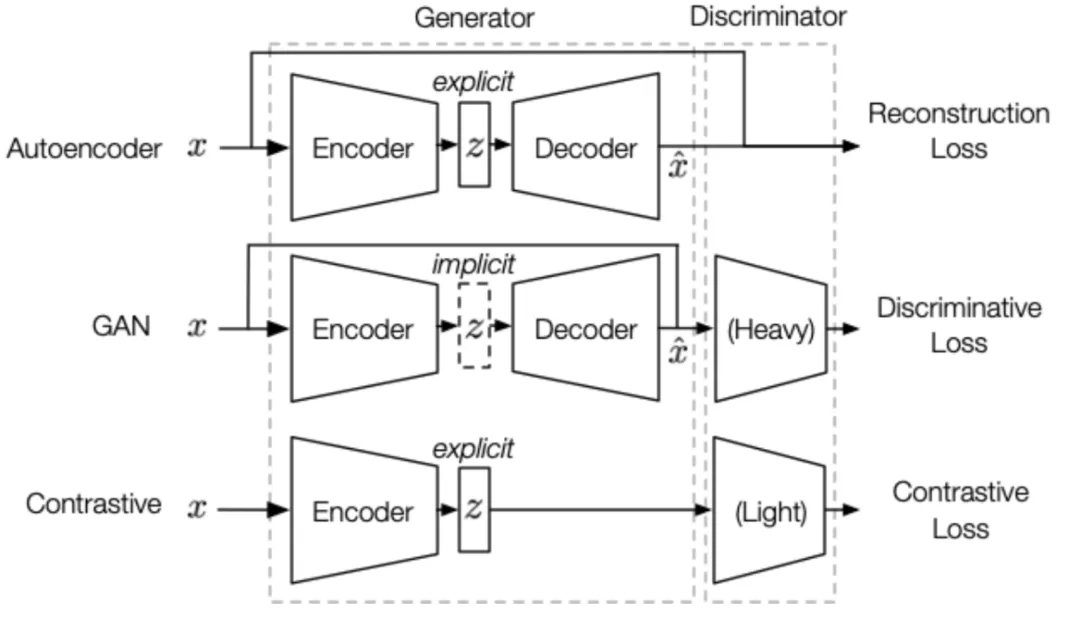
图10:AE、GAN 和 Contrastive 方法的区别,总体上它们都包含两个大的组件—-生成器和判别器。生成器可以进一步分解为编码器和解码器,区别在于:1)隐编码表示 在 AE 和 Contrastive 方法中是显式的;2)AE 没有判别器是纯生成式模型,Contrastive 方法的判别器参数少于 GAN;3)AE 学习目标是生成器,而 GAN 和 Contrastive 方法的学习目标是判别器。(Image source: Jie Tang et al.)
综上所述,对抗式方法吸收了生成式方法和对比式方法各自的优点,但同时也有一些缺点。在我们需要拟合隐分布的情况下,使用对抗式方法会是一个更好的选择。下面将具体讨论它在表示学习中的各种应用。
Generate with Complete Input
本小节将介绍 GAN 及其变种如何应用到表示学习中,这些方法关注于捕捉样本的完整信息。GAN 在图像生成中占据主导地位,然而数据的生成与表示还是存在 gap 的,这是因为在 AE 和 Contrastive 方法中,隐编码表示 是显式建模的,而 GAN 是隐式的,因此我们需要提取出 GAN 的隐分布 。AAE 率先尝试弥补这个 gap,AAE 参考 AE 的思想,为了提取隐分布 ,可以将 GAN 中的生成器替换为显式建模的 VAE,回忆一下前文提到的 VAE 损失函数:
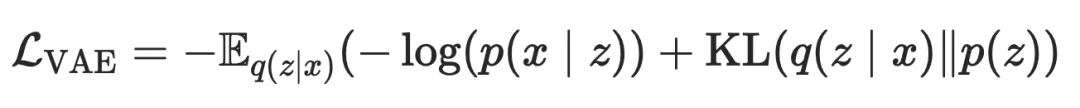
我们说过,AE 由于使用了 损失导致建模对象可能是 pixel-level,而 GAN 使用的对比式损失可以更好地建模 high-level 表示,因此为了缓解这个问题,AAE 将上面的损失函数中的 KL 项替换为了一个判别损失:

它要求判别器区分来自编码器的表示和先验分布。尽管如此,AAE 仍然保留了重构损失与 GAN 的核心思想还是存在矛盾。基于 AAE,BiGAN 和 ALI 模型主张保留对抗性学习,并提出新的框架如下图 11 所示。
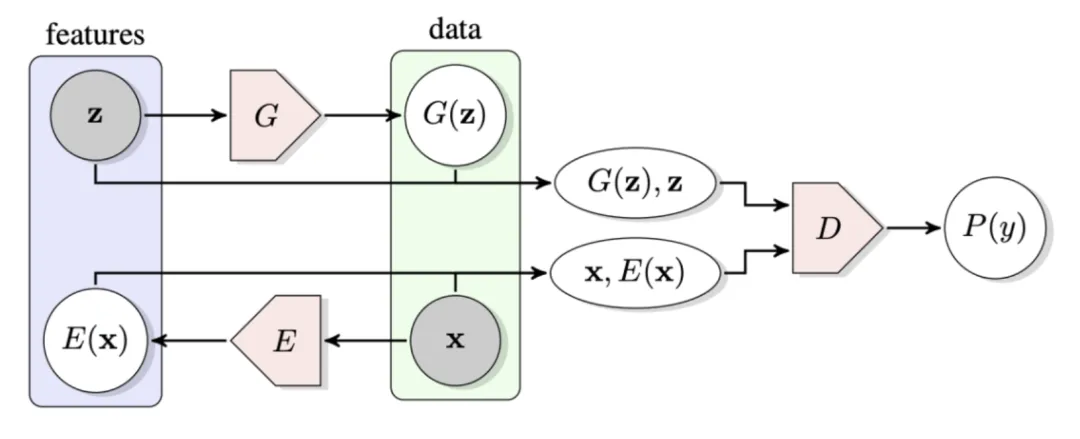
图11:BiGAN 和 ALI 的框架图。(Image source: J Donahue et al.)
给定一个真实样本 :
生成器 :这里生成器实际上扮演解码器的角色,其会根据先验隐分布 生成 fake 样本 编码器 :新引入的单元,其将真实样本 x 映射为表示 ,而这正是我们想要的表示 判别器 :给定输入 和 ,判断哪一个来自真实的样本分布。容易看出,训练的目标是 ,即编码器 应当学会”转换“生成器 。看起来似乎和 AE 很像,但是区别在于编码表示的分布不作任何关于数据的假设,完全由判别器来决定,可以捕捉 semantic-level 的差异。
Pre-trained Language Model
在很长一段时间内,预训练语言模型 PTM 都关注于根据辅助任务来最大化似然估计,因为判别式的目标函数由于语言的生动丰富性被认为是无助的。然而,最近的一些研究显示了 PTM 在对比学习方面的良好性能和潜力。这方面的先驱工作有 ELECTRA,在相同的算力下取得了超越 BERT 的表现。如下图 12 所示,ELECTRA 提出了 RTD(Replaced Token Detection),利用 GAN 的结构构建了一个预训练语言模型,ELECTRA 的生成器可以看作一个小型的 Masked Language Model,将句子中的 masked token 替换为正常的单词,而判别器 预测哪些单词被替换掉,这里的替换的意思是与原始单词不一致。
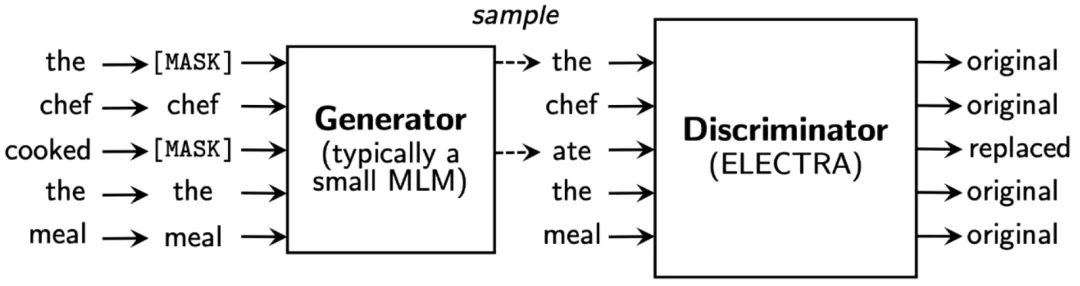
图12:ELECTRA 框架图。(Image source: K Clark et al.)
其训练过程包含两个阶段:
生成器”热启动“:按照 MLM 的辅助任务 训练 一些步骤以对 的参数进行”预热“。 训练判别器:判别器的参数将会初始化为 的参数,并按照交叉熵判别损失 进行训练,此时生成器的参数将会被冻结。最终的目标函数为: 、
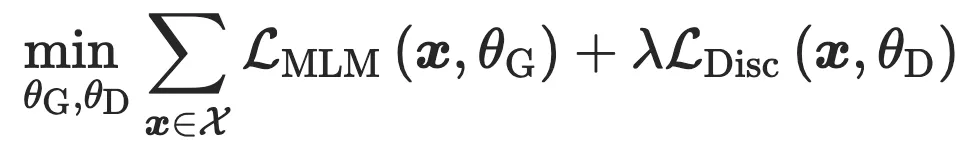
尽管 ELECTRA 的设计是仿照 GAN 的,但是其训练方式不符合 GAN,这是由于图像数据连续的,而文本数据是离散的阻止了梯度的传播。另一方面,ELECTRA 实际上将多分类转化为了二分类,使得其计算量降低,但也可能因此降低性能。
Graph Learning
在图学习领域中,也有利用对抗学习的实例,但是不同模型之间的区别很大。大部分方法都跟随 BiGAN 和 ALI 选择让判别器区分生成的表示和先验分布,例如 ANE 的训练分为两步:1)生成器 将采样的图编码为嵌入表示,并计算 NCE 损失;2)判别器 区分生成的嵌入表示和先验分布。最终的损失是对抗损失加上 NCE 损失,最终 可以返回一个更好的表示。GraphGAN 建模链路预测任务,并且遵循 GAN 的原始形似,直接判别节点而非表示。如下图 13 所示,GraphGAN 表示分类任务中很多的错误都是由于边缘节点造成的,通常情况下同一聚簇内的节点会在嵌入空间内聚集,聚簇之间会存在包含少量节点的 density gap,作者证明如果能够在 density gap 中生成足够多的 fake 节点,就能够改善分类的性能。在训练过程中,GraphGAN 利用生成器在 density gap 中生成节点,并利用判别器判断节点的原始类别和生成的 fake 节点的类别,在测试阶段,fake 节点将会被移除,此时分类的性能应当得到提升。
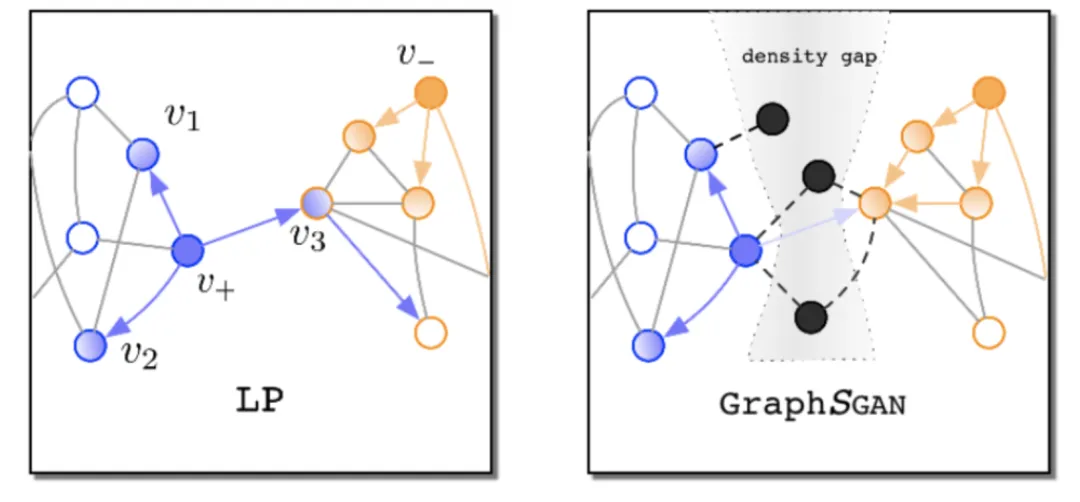
图13:GraphGAN 示意图。(Image source: H Wang et al.)
Discussions and Future Directions
参考
[1] https://zhizhou-yu.github.io/2020/06/26/Self-supervised-Learning-Generative-or-Contrastive.html
[2] J. Donahue and K. Simonyan. Large scale adversarial representation learning
[3] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning. Electra: Pretraining text encoders as discriminators rather than generators.
[4] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick. Momentum contrast for unsupervised visual representation learning.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SSL24” 就可以获取《自监督学习最新研究进展,24页pdf》专知下载链接